一种基于网络配音游戏的语音样本收集方法与流程
本发明涉及语音信号处理技术和语音样本收集技术,具体涉及一种基于网络配音游戏的语音样本收集方法。
背景技术:
随着可穿戴设备、智能硬件、智能家居领域的火热,语音识别作为其中最重要的人机交互手段,其市场也是越来越大。传统连续语音识别技术以gmm-hmm为主,现代语音识别技术的发展趋势是神经网络。神经网络模拟人类神经元结构搭建,其深层结构对语音的描述能力比传统方法强,更能适应语音识别这样的复杂模式分类问题。在众多神经网络算法中,深度神经网络(deepneutralnetwork)与长短时记忆单元网络(long-shorttermmemory)凭借训练大量数据的能力及在识别准确率上对传统方法的显著超越,成为近年来学术界工业界的热点。而在dnn与lstm等神经网络语音识别模型的训练过程中,海量的含发音标注的语音样本至关重要,训练语音样本的大小和语音识别系统的性能正相关。
现有的语音样本收集方法一般分为:人工现场录制和人工电话录制。这两种方法费时费力耗资巨大,导致训练语音样本的规模也难以扩大,限制了语音识别系统识别能力的提高。
现有语音样本收集方法的不足之处在于:
(1)人工现场录制语音样本限制了说话人的地域分布,不利于语音识别系统在大范围地域内的泛化能力的提升;
(2)人工现场录制语音样本人力成本、交通成本高昂;
(3)人工现场录制语音样本方案收集语音样本时间长,语音样本库建立耗时也长;
(4)人工录制与收集语音样本枯燥无味,说话人志愿者和收集语音样本工作人员工作积极性都不高;
(5)人工电话录制语音样本包含电话信道噪声,与日常现场语音识别应用场景不一样,其训练出来的语音识别模型在现场应用时效果不佳;
(6)人工现场录制与人工电话录制方案在语音样本筛选阶段人力消耗巨大。
技术实现要素:
本发明的目的在于解决现有人工现场录制语音样本方案录制成本高、时间长,和人工电话录制语音样本方案包含信道噪声的缺点,提供一种基于网络配音游戏的语音样本收集方法:通过配音游戏引导用户录制语音来收集语音样本。
为了达到上述目的,本发明采用以下技术方案:
本发明提供了一种基于网络配音游戏的语音样本收集方法,包括下述步骤:
s1.通过如下游戏过程进行语音样本收集并进行自动质量评价:
s1.1熟悉配音需求:游戏用户在配音游戏客户端点播视频独白节目,客户端通过videoview类第一遍播放含音频与画面的视频,使用户对视频场景和对话过程有较好的认知;
s1.2配音:客户端通过videoview类播放无声视频,画面底部同步显示字幕与进度条,游戏用户根据字幕与画面进行配音,客户端通过audiorecord类按照16khz采样频率,16bit采样深度,单声道,线性pcm编码格式录制用户语音,画面结束,自动通过uploadutil类向服务器上传用户录制原始语音以及用户所处地理位置;
s1.3配音变声处理:客户端提供变声功能,该变声功能通过基于gmm的音色变换算法实现,音色变换算法在客户端对配音进行处理,使用户语音能以视频原声为目标进行粗略音色变换,用户对处理效果满意后将变声音频上传至服务器,使得语音收集过程更具趣味性,本语音收集工具也更易传播;
s1.4配音质量评价:用户原始音频上传到服务器后,服务器端通过算法对语音清晰度与发音准确性进行自动评价,算法由客观语音质量评价和语音识别两部分构成,减少了传统方法在样本筛选阶段大量的人力消耗;
s1.5分享:服务器将前述步骤s1.4生成的分数与前述步骤s1.3生成的变声音频链接下发给游戏用户,用户在社交平台分享分数与变声后的音频链接,本步骤使得本语音收集工具也更具传播性,有利于获取大量的用户,从而得到大量的说话人的语音;
s1.6奖励:高点击量语音给予积分奖励,鼓励用户分享,高分语音给予积分奖励,鼓励用户录制高质量语音;
s2.对机器打分语音样本抽样进行主观评价。
作为优选的技术方案,步骤s1.3中,音色变换的步骤如下:
音色变换功能通过基于gmm的音色变换算法实现,将用户原始音频的音色向视频演员的音色做粗略转换,声学特征在声学空间内的不同分布造成了说话人之间的音色差异,基于gmm的音色变换算法就是用gmm将空间分布参数化并构造线性映射函数,映射函数参数通过最小二乘法构造:
给定n对对齐的源说话人和目标说话人语音特征矢量(xi,yi),首先利用最大期望算法估计出源说话人连续概率空间的m组参数(αi,μi,σi),每组刻画了一类声学子空间的概率分布,根据贝叶斯准则,特征矢量x属于第i类声学子空间ci的条件概率为
定义映射函数为
f(xi)=f(xi,v1,v2,…,vm,γ1,γ2,…,γm)
变换目标函数为
其中:xt、yt分别表示源矢量和目标矢量,最后通过最小二乘法估计映射函数的参数v、γ,由此,即可通过该映射函数对用户的音色向视频中演员的音色进行粗略转变,增强本语料收集工具的趣味性。
作为优选的技术方案,步骤s1.4中,配音质量评价的具体步骤如下:
s1.4.1客观语音质量评价:运用基于pesq的有参考源客观语音质量评价算法,以示例视频原声为参考源语音,经过电平调整、输入滤波、时间对齐、听觉转换、抖动处理和感知测量步骤计算得到用户语音的pesq得分,生成进行5分制打分;
s1.4.2语音识别:调用现有成熟的商用语音识别api接口,对用户原始语音进行识别,对比评估识别结果与文本吻合度,语音识别吻合度百分比乘以50作为语音识别分数;
s1.4.3最终分数=客观语音质量评价分数*10+语音识别吻合度*50。
作为优选的技术方案,所述步骤s1.4.1中,客观语音质量评价的具体步骤如下:
a)电平调整;
语音信号通过不同系统之后,信号电平会有差异,为了统一,将其调整到pesq设定首选的79dbspl,信号声压级别计算公式:
其中,p是语音信号声压,pr=20μpa是基准声压级;
b)irs滤波;
由于用户是通过手机听到语音的,所以利用irs滤波来模拟手机的发送频率特性,频域滤波过程为:首先对参考源信号和待测信号进行通带为300~3400hz的带通滤波,然后分别计算出平均功率和全局缩放因子,用该平均功率和全局缩放因子分别对两个信号进行能量对齐,然后进行fft变换,在频域内用与irs接收特性相似的分段线性频率响应滤波,最后进做逆fft变换,即可实现irs滤波;
c)时间对齐;
因为参考源语音和待测语音之间存在时间延迟,而pesq计算是按帧进行的,所以要让两者达到帧级别的对齐,时间对齐通过基于包络互相关的粗略延时估计,配合基于加权直方图的帧到帧精细延迟估计算法实现;
d)听觉变换;
听觉转换模拟了人耳接收语音信号的过程,将信号映射为感知响度表示,该过程首先对信号进行时域-频域变换,并对bark谱进行估计,为了补偿滤波效果,对bark谱进行线性频率响应补偿,另一方面,补偿增益的短时变化,即参考源语音和待测语音的“可听功率”之间的比率,该比率是在bark域估计得到,它仅包括在功率计算时大于各频带对听力阈值的bark分量,最后在补偿了滤波效果和短时增益变化以后,通过zwicker算法完成参考源语音和待测语音的响度谱估计;
e)感知测量
pesq方法的感知测量主要有这几个步骤:失真干扰密度的计算,非对称处理和干扰值的计算,在计算出平均对称帧干扰度和平均非对称帧干扰度后,就可以计算得带噪语音的客观质量mos分数。
作为优选的技术方案,所述步骤d)中,听觉变换的具体步骤如下:
时域-频域变换:经过时间对齐的两路语音信号xirss[n]、yirss[n]加32ms的汉宁窗,得到xwirss[n]n、ywirss[n]n,然后进行短时fft变换,相邻帧重叠50%,并计算每一帧的频率功率谱密度pxwirss[k]n、pywirss[k]n,其中下标n代表帧序号;
bark谱密度:将hz刻度上的功率谱变换到bark尺度上的谱密度ppxwirss[j]n、
ppywirss[j]n,
其中,sp是bark谱密度校准因子,ii[j]是第j个hz频段上最后一个样点的序号,if[j]是第j个hz频段上第一个样点的序号,δz是第j个频段在临界频率群上的带宽,δfi是第j个频段在hz刻度上的带宽;
线性频率响应补偿:因为待测语音是被评价的目标,所以线性补偿只对参考源语音进行,首先计算两路信号能量超过绝对听觉阈值30db以上的有效话音帧的平均bark谱值,将其比值作为补偿因子sj
参考信号线性频率补偿后的bark谱密度ppx′wirss[j]n=sj·ppxwirss[j]n;
增益补偿:求两路信号的=每一帧中超过30db部分的可听功率和,二者的比值通过一阶低通滤波器平滑处理,其输出即补偿因子sn
待测信号增益补偿后的bark谱密度ppy′wirss[j]n=sn·ppywirss[j]n;
响度变换:将两路信号功率谱密度映射到响度级,由zwicker定律有,两路信号每个时频单元的响度为:
其中,p0[j]是绝对听阈,sl是响度调整因子,sl=240.05,响度高于4bark时γ=0.23,响度低于4bark时,γ缓慢增长。
作为优选的技术方案,步骤e)中,感知测量的具体步骤如下:
失真干扰密度计算:首先计算两路信号响度密度的带符号差draw[j]n,即为原始干扰密度,
draw[j]n=ly[j]n-lx[j]n
计算出每对时频分量的响度密度较小者,乘以0.25,将其结果作为掩蔽阈值,形成掩蔽序列m[j]n;
然后模拟人耳掩蔽效应对每个时频分量做掩蔽处理得到干扰密度d[j]n;
非对称处理:通过给每帧的干扰密度d[j]n乘以一个非对称因子来模拟这种非对称效应,得到非对称干扰密度da[j]n;
其中,括号内及其次幂部分即为非对称因子,若该非对称因子小于3,则定为0;若大于12,则定为12;
干扰度:使用不同的lp范数,对干扰密度d[j]n和非对称干扰密度da[j]n在bark域取平均,得到帧干扰度dn和非对称帧干扰度dan,设m为临界带宽的个数,则:
其中,mn是乘因子,与帧功率有关,wj是一系列和修正bark频带组宽度成比例的常量;
干扰度的时域平均:p阶范数lp加权强调了响度高的干扰度,使得客观分数和主观打分的相关性更好;
其中,n为总帧数,p>1.0;
帧干扰度和非对称帧干扰度的时域平均分两级实现,即求瞬态间隔内的干扰总计和话音持续时间内的干扰总计,瞬态问隔内的干扰总计采用高阶范数,话音持续时间内的干扰总计采用低阶范数,对称干扰度dn和非对称帧干扰度dan分别计算,得到平均对称干扰度dsym和平均非对称帧干扰度dasym;
计算客观得分:pesq算法客观评价分数是平均对称干扰度dsym和平均非对称帧干扰度dasym的线性组合,最高分为5分,代表语音质量最好,最低分为0分,代表语音质量最差;
pesqmos=4.5-0.1·dsym-0.0309·dasym。
作为优选的技术方案,所述步骤s2中,对机器打分语音样本抽样进行主观评价具体包括下述步骤:
s2.1抽样展示:将经步骤s1.5打分后的语音样本按分数排序,抽取前5条语音在游戏首页展示作为示范,随机抽取排名后20%的语音样本中的15条语音样本在游戏首页展示,让用户进行评价;
s2.2用户评价:在语音样本展示页面中提供评价按钮,用户对展示语音样本进行试听评价后,选择“符合原文”按钮或“不符原文”按钮;
s2.3人工试听:对用户点击“不符原文”按钮数量较多的语音样本,后台抽取出来进行人工试听,人工试听后确实与文本不符的语音样本从精选语音样本库中剔除,对机器打分后的样本抽样主观评价,实现语音样本质量闭环控制。
作为优选的技术方案,所述步骤s1.1中的视频是新闻联播视频或热门电影、电视剧、或动画片视频。
作为优选的技术方案,所述步骤1.2中的进度条是用于使得用户语速与视频播放速度相同;
所述步骤s1.2中的“16khz采样频率,16bit采样深度,单声道,线性pcm编码”音频格式满足语音识别开源工具箱kaldi对音频格式的要求,该格式语音样本能直接用于基于kaldi的语音识别系统的声学模型的训练。
作为优选的技术方案,所述步骤s1.4中结合pesq语音质量客观评价和语音识别对录音样本进行自动评估,确保语音样本的质量。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明可以使得语音收集过程更具趣味性,本语音收集工具也更易传播,有利于获取大量的用户,从而得到大量的说话人的语音;
2、本发明可以按照语音样本库的使用效果来方便地调整发布的示例视频,补充发布经过音素平衡设计或者其他设计策略的示例视频,来引导用户配音增加要补充的语音样本;
3、本发明以语音质量客观评价和语音识别相结合的方式对录音样本进行自动评估,确保语音样本的质量,用机器打分的方法减少了传统方法在样本筛选阶段大量的人力消耗;
4、本发明对机器打分后的样本抽样主观评价,实现语音样本质量闭环控制,提高了语音样本库的质量;
5、本发明通过安装本客户端的智能手机方获取了用户的所在地区,方便生成偏向某地口音的语音语料库,如:普通话南方口音语料库、普通话北方口音语料库;
6、本发明容易在客户端发布新的引导功能,比如在普通话配音的主要功能外,增加粤语、上海话等方言的标注选项让用户进行标注,以便生成粤语语音识别语音语料库、上海话语音识别语音语料库等;
7、本发明由于不用雇佣人员去进行采样、筛选等工作,使得拓展语音语料库的边际成本大大降低;
8、本发明由于不用购置语音样本采样录音装置,节省了开支,并且经由用户型号繁多的智能手机终端录制上传的语音样本,其训练出来的声学模型在不同设备上的识别鲁棒性更高。
附图说明
图1是本发明两个主要环节的概略流程图;
图2是本发明的详细流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
图1、图2是根据本发明的一个语音样本收集实施例的概略流程图和详细流程图。
如图1所示,本发明所采用的技术方案包括两个环节:步骤101语音样本收集环节、步骤102语音样本抽样主观评价环节。
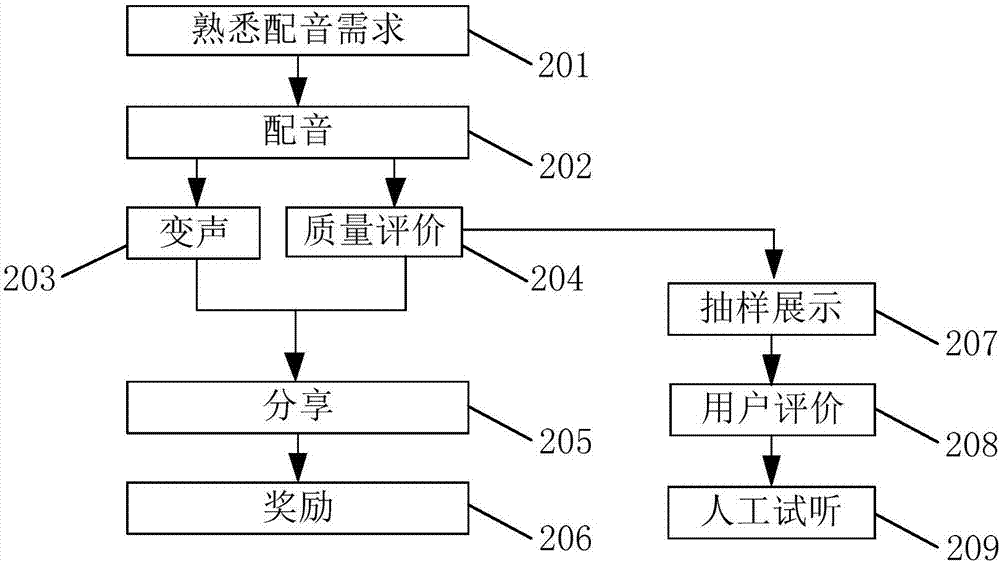
如图2所示,首先在步骤201中,游戏用户在配音游戏客户端点播视频独白节目,客户端通过videoview类第一遍播放含音频与画面的视频,使用户对视频场景和对话过程有较好的认知;
前面步骤201的视频播放结束后,接着步骤202,客户端通过videoview类播放无声视频,画面底部同步播放字幕与进度条,向用户展示需录制语音的文本,用户按照字幕与画面进行配音,客户端通过audiorecord类按照16khz采样频率,16bit采样深度,单声道,线性pcm编码格式录制用户语音,画面结束,通过uploadutil类自动上传用户原始语音以及用户所处地理位置到服务器;
接下来的步骤203,用户在客户端选择自己喜欢的变声效果,在本地对配音进行处理,处理算法基于gmm音色变换算法。基于gmm的音色变换算法就是用gmm将空间分布参数化并构造线性映射函数。
863汉语普通话连续语音识别训练语料库中,60位说话人的录音都是同样的1560句话,故将其作为30对语音进行训练。其中,男性说话人24名,分为12对,女性说话人36名,分为18对。每对中一名相当于源说话人,另一名相当于目标说话人。1560句语音内容的音节覆盖比较完整。本实施例中,gmm模型的高斯混合数使用256个。
映射函数参数通过最小二乘法构造:
给定30对对齐的源说话人和目标说话人语音特征矢量(xi,yi),首先利用最大期望算法估计出源说话人连续概率空间的m组参数(αi,μi,σi),每组刻画了一类声学子空间的概率分布。根据贝叶斯准则,特征矢量x属于第i类声学子空间ci的条件概率为
定义映射函数为
f(xi)=f(xi,v1,v2,…,vm,γ1,γ2,…,γm)
变换目标函数为
其中:xt、yt分别表示源矢量和目标矢量。最后通过最小二乘法估计映射函数的参数v、γ。由此,即可通过该映射函数对用户的音色向视频中演员的音色进行粗略转变;
在步骤204中,服务器端结合基于pesq的有参考源客观语音质量评价算法和讯飞语音识别speechrecognizer接口对步骤203获得的用户原始音频进行机器打分。其中,基于pesq的有参考源客观语音质量评价系统对用户原始音频进行客观语音质量评价,对游戏用户录音质量进行五分制打分,录音质量越高则分数越高。
基于pesq的有参考源客观语音质量评价方法可以概述为:首先将参考源语音和待测语音的电平调整到标准听觉电平,然后用输入滤波器模拟标准电话听筒进行滤波,再将这两个信号进行时间对齐,之后进行听觉转换,转换后这两个信号的差值就是干扰度,然后通过感知测量,最后得到pesq分值。该语音质量评价方法的具体步骤如下:
a)电平调整
语音信号通过不同系统之后,信号电平会有差异,为了统一,将其调整到pesq设定首选的79dbspl。信号声压级别计算公式:
其中,p是语音信号声压,pr=20μpa是基准声压级。
b)irs滤波
因为用户是通过手机听到语音的,所以用irs滤波来模拟手机的发送频率特性,频域滤波过程为:首先对参考源信号和待测信号进行通带为300~3400hz的带通滤波,然后分别计算出平均功率和全局缩放因子,用该因子分别对两个信号进行能量对齐,然后进行fft变换,在频域内用与irs接收特性相似的分段线性频率响应滤波,最后进做逆fft变换,即可实现irs滤波。
c)时间对齐
因为参考源语音和待测语音之间存在时间延迟,而pesq计算是按帧进行的,所以要让两者达到帧级别的对齐。时间对齐通过基于包络互相关的粗略延时估计,配合基于加权直方图的帧到帧精细延迟估计算法实现。
基于包络互相关的粗略延时估计:将经过前述步骤b)滤波的信号进行窄带滤波,滤除占自然语音大部分能量的500hz以下的部分,留下对感知模型最重要的1000~3000hz部分;分别求出两路信号每4ms帧语音的平均能量,该能量序列即为语音信号包络,参考源语音信号包络xes[n],待测信号包络yes[n];这两个包络的最大互相关值的下标即为粗略延时估计,两路信号包络的互相关值c[n]为:
c[n]=corr(xes[n]k,yes[n]k)
对于500ms语音,该粗略延时估计方法的误差范围为±8ms。
基于加权直方图的帧到帧精细延迟估计:前述基于包络互相关的粗略延时估计排除了常量延时或同步较差的时间偏移量,本步骤基于加权直方图的精细延时估计将计算出语句的精细延时。
首先对irs滤波后的两路语音信号分别加汉宁窗,划分帧长64ms,相邻帧重叠75%;然后求出每个64ms帧的互相关绝对值最大时的序号,该序号为每一帧的延时,对绝对值最大互相关做0.125次幂,作为该帧的加权因子;根据帧延时,将加权因子加到相应的直方图中,得到每一语句的加权直方图;归一化加权直方图;用一个宽2ms,峰值为1的三角窗卷积,对归一化加权直方图做平滑,此时平滑后的直方图峰值对应的时域值加上粗略时延值,即为该语句的实际延时值。
依据语句实际延时值对两路信号做时间对齐,对齐后的参考源信号xirss[n],对齐后的待测信号yirss[n]。
d)听觉变换
听觉转换模拟了人耳接收语音信号的过程,将信号映射为感知响度表示。该过程首先对信号进行时域-频域变换,并对bark谱进行估计。为了补偿滤波效果,对bark谱进行线性频率响应补偿。另一方面,补偿增益的短时变化,即参考源语音和待测语音的“可听功率(audiblepower)”之间的比。该比率是在bark域估计得到,它仅包括在功率计算时大于各频带对听力阈值的bark分量。最后在补偿了滤波效果和短时增益变化以后,通过zwicker算法完成参考源语音和待测语音的响度谱估计。下面是听觉变换的详细过程:
时域-频域变换:经过时间对齐的两路语音信号xirss[n]、yirss[n]加32ms的汉宁窗,得到xwirss[n]n、ywirss[n]n,然后进行短时fft变换,相邻帧重叠50%,并计算每一帧的频率功率谱密度pxwirss[k]n、pywirss[k]n,其中下标n代表帧序号。
bark谱密度:将hz刻度上的功率谱变换到bark尺度上的谱密度ppxwirss[j]n、ppywirss[j]n,
其中,sp是bark谱密度校准因子,ii[j]是第j个hz频段上最后一个样点的序号,if[j]是第j个hz频段上第一个样点的序号,δz是第j个频段在临界频率群上的带宽,δfi是第j个频段在hz刻度上的带宽。
线性频率响应补偿:因为待测语音是被评价的目标,所以线性补偿只对参考源语音进行。首先计算两路信号能量超过绝对听觉阈值30db以上的有效话音帧的平均bark谱值,将其比值作为补偿因子sj
参考信号线性频率补偿后的bark谱密度ppx′wirss[j]n=sj·ppxwirss[j]n。
增益补偿:求两路信号的=每一帧中超过30db部分的可听功率和,二者的比值通过一阶低通滤波器平滑处理,其输出即补偿因子sn
待测信号增益补偿后的bark谱密度ppy′wirss[j]n=sn·ppywirss[j]n。
响度变换:将两路信号功率谱密度映射到响度级,由zwicker定律有,两路信号每个时频单元的响度为:
其中,p0[j]是绝对听阈,sl是响度调整因子,sl=240.05,响度高于4bark时γ=0.23,响度低于4bark时,γ缓慢增长。
e)感知测量
pesq方法的感知测量主要有这几个步骤:失真干扰密度的计算,非对称处理和干扰值的计算。在计算出平均对称帧干扰度和平均非对称帧干扰度后,就可以计算得带噪语音的客观质量mos分数。
失真干扰密度计算:首先计算两路信号响度密度的带符号差draw[j]n,即为原始干扰密度。
draw[j]n=ly[j]n-lx[j]n
计算出每对时频分量的响度密度较小者,乘以0.25,将其结果作为掩蔽阈值,形成掩蔽序列m[j]n。
然后模拟人耳掩蔽效应对每个时频分量做掩蔽处理得到干扰密度d[j]n。
非对称处理:非对称是指损失和引入一个时频分量所导致的失真后果相差很大。主观测试表明,当信号中引入一个新的时频分量时,这个新的分量和输入信号混为一体,使输出信号分解为两个不同的部分,即输入信号和失真,这将导致明显的能听到失真。然而,当损失一个时频分量时,输出信号不能按同样方式分解,失真也变得不太明显。通过给每帧的干扰密度d[j]n乘以一个非对称因子来模拟这种非对称效应,得到非对称干扰密度da[j]n。
其中,括号内及其次幂部分即为非对称因子,若该非对称因子小于3,则定为0;若大于12,则定为12。
干扰度:使用不同的lp范数,对干扰密度d[j]n和非对称干扰密度da[j]n在bark域取平均,得到帧干扰度dn和非对称帧干扰度dan,设m为临界带宽的个数,则:
其中,mn是乘因子,与帧功率有关,wj是一系列和修正bark频带组宽度成比例的常量。
干扰度的时域平均:p阶范数lp加权强调了响度高的干扰度,使得客观分数和主观打分的相关性更好。
其中,n为总帧数,p>1.0。
帧干扰度和非对称帧干扰度的时域平均分两级实现,即求瞬态间隔内的干扰总计和话音持续时间内的干扰总计。瞬态问隔内的干扰总计采用高阶范数,话音持续时间内的干扰总计采用低阶范数。对称干扰度dn和非对称帧干扰度dan分别计算,得到平均对称干扰度dsym和平均非对称帧干扰度dasym。
计算客观得分:pesq算法客观评价分数是平均对称干扰度dsym和平均非对称帧干扰度dasym的线性组合,最高分为5分,代表语音质量最好,最低分为0分,代表语音质量最差。
pesqmos=4.5-0.1·dsym-0.0309·dasym
语音识别:调用现有成熟的商用语音识别api接口例如科大讯飞的speechrecognizer接口,对用户原始语音进行识别,对比评估识别结果与文本吻合度,吻合度定义为:识别正确字数除以总字数,语音识别吻合度百分比乘以50作为语音识别分数;
最终分数=客观语音质量评价分数*10+语音识别吻合度*50。
其中,客观语音质量评价分数满分为5分,语音识别吻合度满分为1,分别乘以10和50后,两者之和为100分制分数,以这个经过pesq得分和语音识别得分融合的分数为最终分数。
步骤205,服务器将生成的分数与前述步骤204变声音频链接下发给游戏用户,用户在社交平台分享分数与原声或变声的音频链接;
步骤206,对于分享环节中的高点击量语音,游戏运营方给予该用户积分奖励,鼓励用户分享;高分语音给予积分奖励,鼓励用户录制高质量语音,积分累积到一定数量可兑换礼品等。
至此游戏环节结束,服务器端也获得了用户的原始语音样本。下面进行语音样本抽样主观评价,利用庞大的游戏用户对精选语音样本进行检查。
步骤207,将经步骤204打分后的语音样本按分数排序,抽取前5条语音在游戏首页展示作为示范,随机抽取排名后20%的语音样本中的15条语音样本在游戏首页展示,让用户进行评价;
步骤208,在语音样本展示页面中提供评价按钮,用户对展示语音样本进行试听评价后,选择“符合原文”按钮或“不符原文”按钮;
步骤209,对用户点击“不符原文”按钮数量较多的语音样本,后台抽取出来进行人工试听,人工试听后确实与文本不符的语音样本从语音样本库中剔除。
至此,一个经过机器评价与人工筛选的语音样本库就制作完成了。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!