具有智能语音服务功能的电子装置及调整输出声音的方法与流程
本发明系关于一种具有智能语音服务功能的电子装置,特别是一种可依照用户的听力状况,输出答复语音消息的电子装置。
背景技术:
随着科技的不断创新与发展,家庭电器智能化成为家电产品发展的主要趋势,举凡冰箱、冷气、电视等家庭电器,皆逐渐配备有高阶的运算处理功能,可提供智能管理。目前的智能家电可通过简单的语音系统,提醒用户家电的使用状态,甚至能与用户互动。惟此类家电的语音输出通常系为听力正常者所设计,故输出声音的频率可能导致对老年人或听力受损者而言会听不清楚。
因此,实有必要思考一种方法,以改善前述现有技术的缺失。
技术实现要素:
本发明的主要目的在于提供一种可调整输出声音频率的具有智能语音服务功能的电子装置。
为达成上述的目的,本发明具有智能语音服务功能的电子装置包括有喇叭、内存、输入设备及处理单元。输入设备用以获得一用户的辨识特征数据,其中输入设备包含麦克风,麦克风并能接收该用户发出的语音消息。处理单元系与喇叭、内存及输入设备电性连接,处理单元包括有文件建立模块、身份辨识模块、答复信息取得模块及声音调整模块。文件建立模块用以建立一互动者数据库,并储存该互动者数据库于内存中,其中互动者数据库包含多个互动者的识别数据及听力参数数据。身份辨识模块用以分析辨识特征数据,以得到一身份验证数据,并比对该身份验证数据与多个互动者的识别数据,以取得相对应的听力参数数据。答复信息取得模块用以取得对应适于答复语音消息的原始答复语音消息。声音调整模块用以根据听力参数数据调整原始答复语音消息,以产生一调整后答复语音消息,喇叭可择一输出原始答复语音消息或调整后答复语音消息,或者先后输出原始答复语音消息及调整后答复语音消息。
本发明另提供一种调整输出声音的方法,适用于具有智能语音服务功能的电子装置,包括有下列步骤:建立并储存一互动者数据库,其中该互动者数据库包含多个互动者的识别数据及听力参数数据;获取一用户的辨识特征数据及该用户发出的语音消息;分析辨识特征数据,以得到一身份验证数据,并比对该身份验证数据与多个互动者的识别数据,以取得相对应的听力参数数据;取得对应适于答复该语音消息的原始答复语音消息;根据听力参数数据调整原始答复语音消息,以产生一调整后答复语音消息;以及,择一输出原始答复语音消息或调整后答复语音消息,或者先后输出原始答复语音消息及调整后答复语音消息。
附图说明
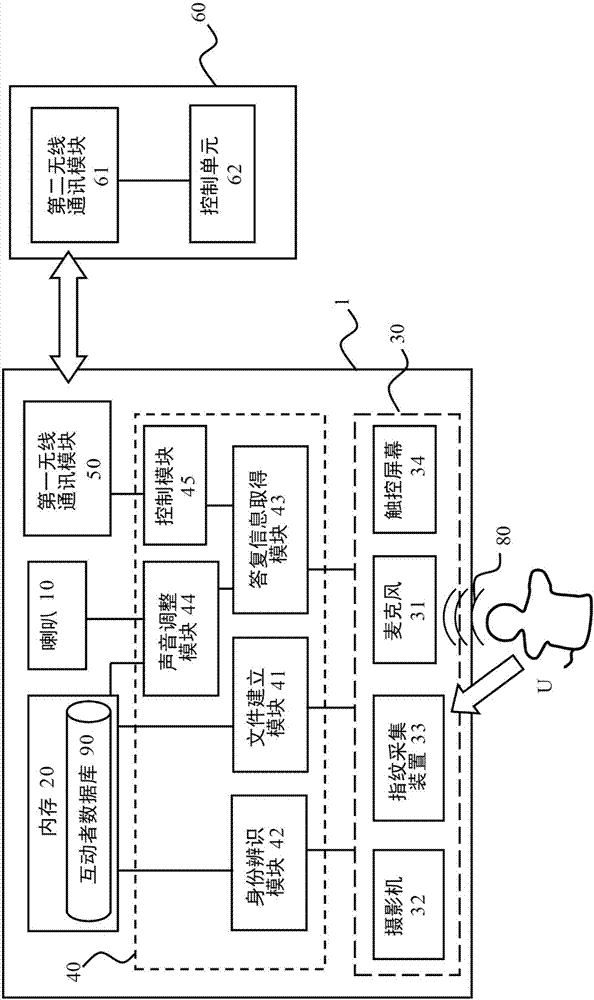
图1为本发明的具语音服务功能的电子装置的装置架构图。
图2为本发明的互动者数据库的一实施示意图。
图3为本发明的调整输出声音的方法的步骤流程图。
其中附图标记为:
电子装置1
喇叭10
内存20
输入设备30
麦克风31
摄影机32
指纹采集设备33
触控屏幕34
处理单元40
文件建立模块41
身份辨识模块42
答复信息取得模块43
声音调整模块44
控制模块45
第一无线通信模块50
受控电子装置60
第二无线通信模块61
控制单元62
语音消息80
互动者数据库90
识别数据91
脸部影像数据911
指纹数据912
声纹数据913
听力参数数据92
年龄数据93
性别数据94
用户u
具体实施方式
为能让贵审查委员能更了解本发明的技术内容,特举较佳具体实施例说明如下。
以下请一并参考图1及图2。其中图1系本发明的具语音服务功能的电子装置的装置架构图;图2系本发明的互动者数据库的一实施示意图。
如图1所示,在本发明的一实施例中,本发明具有智能语音服务功能的电子装置1联机一受控电子装置60,在此受控电子装置60可为具有无线通信功能的冷气机,但不以此为限,其也可为电灯、电视、电风扇或其他具无线通信功能的电子产品。受控电子装置60包括有第二无线通信模块61及控制单元62。
在本发明的一实施例中,本发明的电子装置1包括有喇叭10、内存20、输入设备30、处理单元40以及第一无线通信模块50,其中处理单元40系与喇叭10、内存20、输入设备30及第一无线通信模块50电性连接。电子装置1可通过第一无线通信模块50与第二无线通信模块61间的联机建立,以和受控电子装置60实现无线通信。在本发明的具体实施例中,第一无线通信模块50与第二无线通信模块61为蓝牙装置,但本发明不以此为限。
在本发明的一实施例中,输入设备30用以获得用户u的辨识特征数据,例如用户u的脸部影像、指纹或声音,但不以此为限,也可为是用户u的虹膜影像。在本发明的实施例中,输入设备30包括麦克风31、摄影机32、指纹采集设备33及触控屏幕34。麦克风31用以接收用户u发出的语音消息80(声音),摄影机32用以采集用户u的脸部影像,而指纹采集设备33用以采集用户u的指纹。
在本发明的一实施例中,本发明的处理单元40包括文件建立模块41、身份辨识模块42、答复信息取得模块43、声音调整模块44及控制模块45。需注意的是,上述各个模块除可配置为硬件装置、软件程序、韧体或其组合外,亦可藉电路回路或其他适当型式配置;并且,各个模块除可以单独的型式配置外,亦可以结合的型式配置。一个较佳实施例是各模块皆为软件程序储存于内存上,藉由一处理器(图未示)执行各模块以达成本发明的功能。此外,本实施方式仅例示本发明的较佳实施例,为避免赘述,并未详加记载所有可能的变化组合。然而,本领域的通常知识者应可理解,上述各模块或元件未必皆为必要。且为实施本发明,亦可能包含其他较细节的现有模块或元件。各模块或元件皆可能视需求加以省略或修改,且任两模块间未必不存在其他模块或元件。
在本发明的一实施例中,文件建立模块41用以建立一互动者数据库90,并储存该互动者数据库90于内存20中。该互动者数据库90包含多个互动者的识别数据91及听力参数数据92,其中该听力参数数据92为各互动者对于不同频率的声音可听见的最小音量数据。如图2所示,在本实施例中,识别数据91包含互动者的脸部影像数据911、指纹数据912及声纹数据913,该些数据可由潜在可能的互动者输入,例如某家庭中的各个成员。互动者数据库90的建立可依以下列方式执行,但本发明不以此为现。
首先,多位互动者可通过触控屏幕34的操作,输入设定指令,以启动电子装置1进入设定模式。在设定模式下,电子装置1经由触控屏幕34显示信息,要求互动者输入自己的脸部影像、指纹或声音等辨识特征数据。接着,互动者可选择将脸部朝向摄影机32,由摄影机32采集互动者的脸部影像,之后再由文件建立模块41根据脸部影像特征分析的结果,取得互动者的脸部影像数据911;或/及通过指纹采集设备33输入指纹,并由文件建立模块41根据输入的指纹特征辨识的结果,取得互动者的指纹数据912;或/及对着麦克风31发出声音,由麦克风31接收声音,之后再由文件建立模块41根据该声音特征分析的结果,取得互动者的声纹数据913。完成识别数据91设定后,接着电子装置1经由触控屏幕34显示信息,要求互动者输入自己的年龄及性别。互动者通过触控屏幕34输入自己的年龄数据93及性别数据94后,文件建立模块41会根据互动者输入的年龄数据93及性别数据94查找出对应的听力参数数据92(其间的对应关系会事先记录于内存20中),并将听力参数数据92与脸部影像数据911及/或指纹数据912及/或声纹数据913建立一对应关系,以完成互动者数据库90的建立。最后,并将互动者数据库90储存至内存20中。
此处需注意的是,在其他实施例中,完成识别数据91设定后,互动者也可直接输入自己的听力参数数据92,或者由电子装置1提供测试程序,经由对互动者测试后取得其听力参数数据92。
在本发明的一实施例中,身份辨识模块42用以分析用户u的辨识特征数据,以得到一身份验证数据,并比对该身份验证数据与多个互动者的识别数据91,以取得相对应的该听力参数数据92。更具体地来说,由输入设备30接收到的辨识特征数据会被传送到处理单元40,由身份辨识模块42先分析该辨识特征数据,以得到一身份验证数据;举例而言,假设接收到的辨识特征数据70为用户u的脸部影像时,则身份辨识模块42可辨识分析该脸部影像的特征,并根据分析结果,取得用户u的脸部影像数据,在此该脸部影像数据即为所述的身份验证数据;又假设接收到的辨识特征数据70为用户u的指纹时,则身份辨识模块42可辨识分析该指纹的特征,并依据分析结果,取得用户u的指纹数据,在此该指纹数据即为所述的身份验证数据;此外,如果接收到的辨识特征数据70为用户u发出的语音消息80(声音),则身份辨识模块42可辨识分析用户u声音的声纹特征,并根据分析结果,取得用户u的声纹数据,在此该声纹数据即为所述的身份验证数据。
分析取得身份验证数据后,身份辨识模块42接着会将该身份验证数据与储存在内存20中的多个互动者的识别数据91进行比对,一旦比对出身份验证数据有符合其中一互动者的识别数据91时,即通过查表方式,取得相对应的听力参数数据92。以图2所示对应关系图表为例,假设取得身份验证数据为“10101bf051”,则身份辨识模块42即可通过查表,判断出用户为互动者u2,并查找出对应的听力参数数据92为“1010101010102020”。
在本发明的一实施例中,答复信息取得模块43用以取得对应适于答复语音消息80的原始答复语音消息,其中原始答复语音消息和语音消息80间的对应关系是事先预设的。在本实施例中,答复信息取得模块43会分析语音消息80的语意,并根据分析的结果,以查找取得相对应的原始答复语音消息。举例而言,假设用户u发出的语音消息80内容为“开冷气”,则对此内容的语音消息80,原始答复语音消息的内容可设定为“现在温度x℃,请设定目标温度”(x视实际温度而定),因此,当答复信息取得模块43分析出语音消息80的内容为“开冷气”或类似语意时,答复信息取得模块43即会对应查找出“现在温度x℃,请设定目标温度”作为原始答复语音消息的内容。
需注意的是,原始答复语音消息除可由答复信息取得模块43根据语意分析的结果查找取得外,在其他实施例中,亦可自一服务器系统(图未示)中取得;详言之,其他实施例中,电子装置1可联机一具有智能语音服务功能的服务器系统,答复信息取得模块43先将语音消息80发送至服务器系统,由服务器系统对该语音消息80进行语意分析,并依照分析结果,取得对应适于答复该语音消息80的原始答复语音消息;之后答复信息取得模块43再由服务器系统接收取得该原始答复语音消息。关于人类说话的语意分析,并根据分析结果响应适切的答复,乃现有的技术(例如:苹果计算机公司出产的siri软件,并可参考文字转语音(tts)相关技术文献),为声音处理技术领域中具有通常知识者所熟知,故在此不再多做赘述。
在本发明的一实施例中,声音调整模块44用以根据身份辨识模块42分析取得的听力参数数据92,调整原始答复语音消息的声音频率,以产生一调整后答复语音消息。调整后答复语音消息产生后,喇叭10可择一输出原始答复语音消息或调整后答复语音消息,或者先后输出原始答复语音消息及调整后答复语音消息。由于调整后答复语音消息的声音频率是依照用户u的听力状况而调整,故喇叭10输出调整后答复语音消息时播放的声音,可符合用户u的听力状况。而原始答复语音消息的声音频率未被调整,因此,喇叭10输出原始答复语音消息时播放的声音则能符合一般人的听力状况,以便于用户u身旁的其他人也可听清楚电子装置1答复的语音。
在本发明的一实施例中,控制模块45用以根据一控制信号控制受控电子装置60功能的执行,其中该控制信号系根据分析语音消息80的结果而产生。举例而言,在此假设受控电子装置60为冷气机,当答复信息取得模块43分析出语音消息80的内容为“开冷气”时,答复信息取得模块43便会产生一控制信号,并将该控制信号传送到控制模块45;控制模块45接收该控制信号后,即会根据该控制信号控制冷气机开启。此外,在其他实施例中,如果语意分析由服务器系统执行,则服务器系统可依照语意分析的结果产生控制信号,并发送至答复信息取得模块43,再由答复信息取得模块43传送到控制模块45。
接着,请一并参考图1至图3,其中图3为本发明的调整输出声音的方法的步骤流程图。以下将一并参考图1及图2,以依序说明图3中所示的各步骤。
首先,执行步骤s1:建立并储存一互动者数据库。
本发明的调整输出声音的方法适用于例如图1所示,具有智能语音服务功能的电子装置1,用以依据用户的听力状况,调整该电子装置1输出声音的频率。为要能辨识正在使用电子装置1的用户,并得知其听力状况,方法执行的第一步,即是要建立一互动者数据库,其中互动者数据库90包含多个互动者(可能的潜在用户)的识别数据91及听力参数数据92,该听力参数数据为各互动者对于不同频率的声音可听见的最小音量数据。如图2所示,在本实施例中,识别数据91包含互动者的脸部影像数据911、指纹数据912及声纹数据913,该些数据可由潜在可能的互动者输入。互动者数据库90的建立可参考前揭说明,在此不再重复赘述。
执行步骤s2:获取一用户的辨识特征数据及该用户发出的语音消息。
在本发明的实施例中,用户u要利用电子装置1提供的智能语音服务前,电子装置1可经由输入设备30获取用户u的辨识特征数据,其中辨识特征数据可为用户u的脸部影像、指纹或声纹,但不以此为限。更具体地来说,电子装置1的输入设备30包含有麦克风31、摄影机32、指纹采集设备33及触控屏幕34。麦克风31可接收用户u发出的语音消息80(声音),摄影机32用以采集用户u的脸部影像,而指纹采集设备33用以采集用户u的指纹。
执行步骤s3:分析辨识特征数据,以得到一身份验证数据,并比对该身份验证数据与多个互动者的识别数据,以取得相对应的听力参数数据。
步骤s2完成后,处理单元40的身份辨识模块42可辨识分析取得的辨识特征数据,以得到一身份验证数据。假设摄影机32采集到用户u的脸部影像,则身份辨识模块42可辨识该脸部影像的特征,并根据辨识分析结果,取得用户u的脸部影像数据,在此该脸部影像数据即为所述的身份验证数据。又假设用户u利用指纹采集设备33输入自己的指纹,则身份辨识模块42即会辨识该指纹的特征,并根据辨识分析结果,取得用户u的指纹数据,在此该指纹数据即为所述的身份验证数据。此外,如用户u仅是对着麦克风31发出语音消息80(声音),则身份辨识模块42会分析用户u声音的声纹特征,并依据分析结果,取得用户u的声纹数据,在此该声纹数据即为所述的身份验证数据。
分析取得身份验证数据后,身份辨识模块42接着会比对身份验证数据与多个互动者的识别数据91,以取得相对应的听力参数数据92。更具体地来说,身份辨识模块42经由上述方式取得身份验证数据后,接着便会将身份验证数据与储存内存20中的多个互动者的识别数据91进行比对;一旦比对出身份验证数据有符合其中一互动者的识别数据91时,即依据相符的识别数据91,通过查表方式,取得相对应的听力参数数据92。
执行步骤s4:取得对应适于答复该语音消息的原始答复语音消息,并根据一控制信号,控制受控电子装置功能的执行。
在本发明的实施例中,当麦克风31接收用户u发出的语音消息80后,处理单元40的答复信息取得模块43会对语音消息80进行语意分析,并根据分析的结果,查找取得对应适于答复该语音消息80的原始答复语音消息,其中语音消息80和原始答复语音消息间的对应关系是预设的,例如语音消息80内容如果为“开冷气”,则对此内容的语音消息80,原始答复语音消息的内容可设定为“现在温度x℃,请设定目标温度”(x视实际温度而定)。此处需注意的是,原始答复语音消息除可由答复信息取得模块43根据语意分析的结果查找取得外,在其他实施例中,亦可自一服务器系统(图未示)中取得;详言之,其他实施例中,电子装置1可联机一具有智能语音服务功能的服务器系统,答复信息取得模块43先将语音消息80发送至服务器系统,由服务器系统对该语音消息80进行语意分析,并依照分析结果,取得对应适于答复该语音消息80的原始答复语音消息;之后答复信息取得模块43再由服务器系统接收取得该原始答复语音消息。
此外,答复信息取得模块43亦会依据语意分析的结果,产生一控制信号,并传送该控制信号至控制模块45。控制模块45根据控制信号,可控制受控电子装置60功能的执行,例如开启、关闭或执行特定功能。
执行步骤s5:根据听力参数数据调整原始答复语音消息,以产生一调整后答复语音消息。
在答复信息取得模块43取得原始答复语音消息后,接着处理单元40的声音调整模块44会根据身份辨识模块42取得的听力参数数据92,调整该原始答复语音消息的声音频率,以产生一调整后答复语音消息。
最后,执行步骤s6:择一输出原始答复语音消息或调整后答复语音消息,或者先后输出原始答复语音消息及调整后答复语音消息。
步骤s5完成后,电子装置1的喇叭10可择一输出原始答复语音消息或调整后答复语音消息,又或者先后输出原始答复语音消息及调整后答复语音消息,其中在择一输出方式下,可由用户u自行选择。
经由前揭说明可知,本发明的具有智能语音服务功能的电子装置可辨识当前正在利用语音服务的用户,并依照该用户的听力状况,调整答复时输出声音的频率,以让该用户能清楚听到答复语音消息。
综上所陈,本发明无论就目的、手段及功效,在在均显示其迥异于现有技术的特征,恳请贵审查委员明察,早日赐准专利,俾嘉惠社会,实感德便。惟应注意的是,上述诸多实施例仅为为了便于说明而举例而已,本发明所主张的权利范围自应以权利要求所述为准,而非仅限于上述实施例。
- 还没有人留言评论。精彩留言会获得点赞!