一种基于VAD和ANN的噪声消除方法与流程
本发明属于噪声消除方法,具体涉及一种基于vad和ann的噪声消除方法,属于信号处理技术领域。
背景技术:
噪声消除是信号处理领域中一个非常重要的问题,也是一个很棘手的问题,噪声的存在对系统的正常运行有着巨大的影响。多年来,广大学者对噪声消除做了广泛和深入的研究。噪声消除总的来说可以分为两大类:被动噪声抑制和主动噪声消除。被动噪声抑制就是用物理的方法,选用新型材料来进行吸音、隔音和消音。这种方法的成本较高,不易于维护,效果也不理想,尤其是对低频噪声的降噪能力很差。主动噪声消除,基于声波相消干涉的原理,利用自适应滤波算法产生一个与原始噪声幅度相同相位相反的次级噪声来抵消噪声。主动噪声消除的优点就在于自适应滤波算法能够使噪声主动控制系统实时地跟踪噪声及物理环境的变化,自动更新滤波器的参数,从而保证最大限度的消除噪声。相比于被动噪声抑制,其成本较低,易于维护,消噪效果也比较理想,尤其是对低频噪声的降噪效果显著。
自适应滤波算法是主动降噪系统的核心,其性能直接决定了降噪的性能。目前,主要有lms算法和rls算法两大类。由于lms算法有计算量小,实时处理能力强,结构简单,所需内存小,易于实现的优点而在噪声消除领域得到了广泛的应用。但是由于lms算法的收敛速度、时变系统跟踪速度比较慢,收敛精度不高的缺点,使得其在实践中的应用受到了一定的限制。虽然rls算法的收敛速度比较快,收敛精度也比较高,但是计算复杂度很高,所需的内存极大,稳定性和实时处理能力都较差。因此,rls算法在很多场合都不适用。
由于基本的lms算法,步长是固定的。较大的步长可以提高收敛速度和时变系统的跟踪速度,但是收敛精度就会比较低。而较小的步长虽然可以提高收敛精度,却牺牲了收敛速度和时变系统跟踪速度。为此,人们做了大量的研究,提出了许多变步长的lms算法,在一定程度上缓和了这个矛盾,但是并未从根本上得到解决。
近年来,随着经济的快速发展,人民生活水平的日益提高,城市噪声泛滥。人们对环境噪声降噪的需求越来越广,要求也越来越高。在很多应用场合,外部环境噪声是随时间不断变化的,是一个时变的系统。那就要求lms算法不仅要有较高的收敛精度,而且要有快速的收敛速度和时变系统跟踪速度。
技术实现要素:
本发明旨在解决现有lms算法在噪声消除领域应用中性能的不足,创造性地提出了一种结合vad和ann技术来提高在噪声消除领域中算法的收敛速度和收敛精度的基于vad和ann的噪声消除方法。
本发明的总体方案:把带噪语音和参考噪声根据同样的方法进行加窗分帧处理,采用对数频谱距离法vad技术把带噪语音分为语音帧和噪声帧,在有用语音开始之前设置一定时间的静音,这段时间的语音都是噪声,根据这段时间的噪声算出vad的初始噪声参数,并设置阈值。根据阈值来判断每帧帯噪语音为语音帧还是噪声帧。根据vad的检测结果,对语音帧和噪声帧采取不同的处理。当带噪语音经过vad检测为噪声帧时用线性神经网络对噪声帧的参考噪声进行批训练,采用高级的bp算法,可以使误差平方和迅速收敛,而且收敛精度很高,这样就把噪声能量迅速降为零。当检测为语音帧时,用该线性神经网络对语音帧的参考噪声进行顺序训练。随着vad技术把带噪语音实时地分为语音帧和噪声帧,神经网络相应地在批训练方式和顺序训练方式中来回切换。线性神经网络不设置阈值,这样的话可以保证训练出来的权值向量刚好就是滤波器的系数向量,线性神经网络工作在顺序训练时相当于lms算法。
本发明是这样实现的:
一种基于vad和ann的噪声消除方法,首先用vad技术将带噪语音分成语音帧和噪声帧,然后通过ann对语音帧和噪声帧进行不同的降噪处理,对语音帧对应的参考噪声采取顺序训练,对噪声帧对应的参考噪声采取批训练。
其中,所述的vad技术,是采用对数频谱距离来实现,包括以下几个步骤:
1)根据采样频率和噪声特性设置合适的帧长,把带噪语音和参考噪声进行加窗分帧处理。
2)根据实际情况设置合适的前导无语音时长,计算出前导无语音帧数,也就是初始噪声帧数nis。
3)算出每帧带噪语音的对数频谱,用前导nis帧带噪语音的对数频谱算出初始噪声的对数频谱。
4)算出每帧带噪语音与初始噪声的对数频谱距离,并与阈值相比较,小于阈值则判定为噪声帧,否则为语音帧。
更具体的:
步骤1)中,设置帧叠为m-1,m为ann输入层神经元的个数。
步骤3)中,对数频谱和对数频谱距离计算方法如下:
ann采用的是线性神经网络的结构,包含1个输入层1个输出层,且不设置阈值。
更进一步的方案是:
对噪声帧对应的参考噪声采取批训练方式,是采用弹性搜索个体变步长算法,包括以下几个步骤:
1)读入一噪声帧数据作为线性神经网络的目标输出ti,其中n为输入层神经元的个数,下标i表示第i帧数据。读入对应的一帧参考噪声,并转化成输入样本集xi。
t1=[d1(1),d1(2),…,d1(m)]t
x1=[x1(1),x1(2),…,x1(m)]
x1(1)=[x1(1),0,…,0]t
x1(2)=[x1(2),x1(1),0,…,0]t
x1(n)=[x1(n),x1(n-1),…,x1(1)]t
x1(m)=[x1(m),x1(m-1),…,x1(m-n+1)]t
ti=[di(n),di(n+1),…,di(m)]t,i=2,3,4,…
xi=[xi(1),xi(2),…,xi(m-n+1)]
xi(1)=[xi(n),xi(n-1),…,xi(1)]t
xi(m-n+1)=[xi(m),xi(m-1),…,xi(m-n+1)]t
2)设置步长增大系数a=1.2,步长减小系数为b=0.5。对每一噪声帧训练时都初始化步长向量ηi(0)=0.01×ones(n,1),对第1噪声帧初始化权值向量w1(0)=0.01×randn(n,1),对第i(i>1)噪声帧初始化权值向量为前一帧训练的结果。
3)设置训练终止条件,根据一帧语音的时长和硬件条件在满足实时处理条件下设置合适的最大迭代次数train_num,根据降噪需要达到的效果设置合适的梯度范数最小值min_grad,均方误差e(k)的最小值error_goal。
4)读入样本集,求出均方误差e(k),然后求解均方误差对各权值的偏导,保留其方向为cj(k)。当cj(k)cj(k-1)<0时前后两次第j个梯度分量的方向相反,则减小对应的步长分量;当cj(k)cj(k-1)>0时前后两次第j个梯度分量的方向相同,则增大对应的步长分量;当cj(k)cj(k-1)=0时前后两次至少有一次第j个梯度分量为零,则保持对应的步长分量不变。
5)根据梯度和步长修正各权值,判断是否满足终止条件。当达到最大迭代次数tain_num,或者达到梯度范数最小值min_grad,或者均方误差e(k)达到最小值error_goal,输出结果,结束这帧数据的处理;否则进行下一次迭代。
更进一步的方案是:
对语音帧的参考噪声采取顺序训练方式,采用变步长的lms算法,步长η调整如下,其中α=1/256,β=-11,yy(0)=0。
yy(p)=αx(p)+(1-α)yy(p-1)
yyl(p)=max{yy(p),0.001}
η(p)=2β/yyl(p)
本发明利用vad技术把带噪语音分为语音帧和噪声帧。借助神经网络批训练的快速收敛性和高收敛精度,对噪声帧进行处理。一方面,使得自适应滤波在一个噪声帧数据内就得到了收敛;另一方面也提高了收敛精度。
附图说明
图1是基于vad和ann的自适应噪声消除示意图:由声源、数据采集、vad和ann四部分组成。
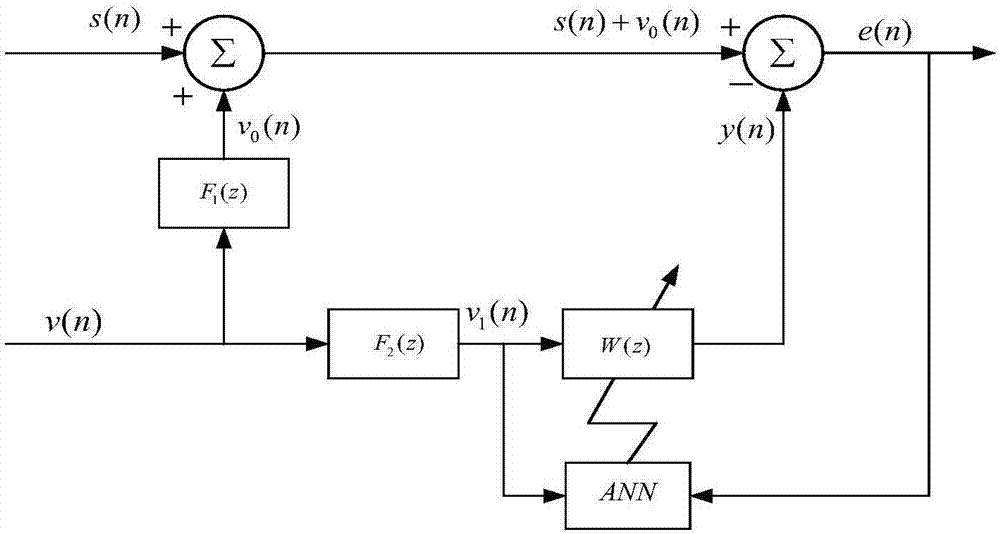
图2是基于vad和ann的噪声消除算法框图:f1(z)主输入噪声通道的建模,f2(z)是参考输入噪声通道的建模。ann采用线性神经网络结构,不设置阈值,所以其权值向量就是滤波器的系数向量。
图3是线性神经网络的结构图:由一个输入层和一个输出层构成,没有隐含层,传递函数为线性函数。
图4是对数频谱距离法vad流程图。
图5是线性神经网络批训练流程图。
图6是线性神经网络顺序训练流程图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
本发明主要包括两大部分,第一部分是用vad技术把带噪语音分为语音帧和噪声帧。第二部分是用线性神经网络进行自适应滤波,对噪声帧对应的参考噪声进行批训练,对语音帧对应的参考噪声进行顺序训练。具体如附图1、2、3所示。
本发明的第一部分是采用对数频谱距离法来实现vad技术把带噪语音分为语音帧和噪声帧。分为以下几个步骤:
步骤1:根据采样频率和噪声特性设置合适的帧长,把带噪语音和参考噪声进行加窗分帧处理。如图2中所示,带噪语音为d(n)=s(n)+v0(n),参考噪声为v1(n),加窗分帧处理后第i帧帯噪语音为di(m),第i帧参考噪声为xi(m)。
式中,
步骤2:根据实际情况设置合适的前导无语音时长,计算出前导无语音帧数,也就是初始噪声帧数nis。
步骤3:对前导nis个噪声帧进行离散傅里叶变换,算出噪声频谱,并对噪声频谱取模再取对数算出对数频谱。
步骤4:对每帧带噪语音进行傅里叶变换,算出它们的频谱,并对它们的频谱取模再取对数算出对数频谱。
步骤5:根据算出的噪声对数频谱和各帧语音的对数频谱,求出对数频谱距离。
步骤6:根据算出的对数频谱距离与阈值th相比较,若小于阈值th则标记为nf=0表示噪声帧,同时更新噪声对数频谱;若大于阈值th则标记为nf=1表示语音帧。
本发明的第二部分是建立线性神经网络,以参考噪声为输入时间序列,以自适应滤波器的系数向量作为线性神经网络输入层到输出层的权值向量,以带噪语音和自适应滤波输出(即线性神经网络输出)之间的均方误差为目标函数进行训练。它有两种训练方式,分别是批训练方式和顺序训练方式。
根据本发明第一部分,带噪语音被检测为噪声帧时,线性神经网络工作在批训练方式,批训练采用弹性搜索个体变步长算法,具体包括以下几个步骤。
步骤1:读入一噪声帧数据作为线性神经网络的目标输出ti,其中n为输入层神经元的个数,下标i表示第i帧数据。读入对应的一帧参考噪声,并转化成输入样本集xi。
t1=[d1(1),d1(2),…,d1(m)]t
x1=[x1(1),x1(2),…,x1(m)]
x1(1)=[x1(1),0,…,0]t
x1(2)=[x1(2),x1(1),0,…,0]t
x1(n)=[x1(n),x1(n-1),…,x1(1)]t
x1(m)=[x1(m),x1(m-1),…,x1(m-n+1)]t
ti=[di(n),di(n+1),…,di(m)]t,i=2,3,4,…
xi=[xi(1),xi(2),…,xi(m-n+1)]
xi(1)=[xi(n),xi(n-1),…,xi(1)]t
xi(m-n+1)=[xi(m),xi(m-1),…,xi(m-n+1)]t
步骤2:初始化权值向量w(0)和步长向量η(0),并设置步长增大系数a和步长减小系数b。其中,w(k)=[w1(k),w2(k),…,wn(k)]t,k表示迭代次数,k=0,1,2,…。
步骤3:设置训练终止条件,包括最大迭代次数train_num,梯度范数最小值min_grad和误差精度error_goal。
步骤4:信号正向传播,求出均方误差e(k),e(k)表示第k次迭代的均方误差。若e(k)≤error_goal,则输出结果,结束训练。
步骤5:求解均方误差e(k)对各权值的偏导,并保存各偏导的方向为cj(k),j=1,2,…n。
步骤6:判断前后两次的偏导方向。若cj(k)cj(k-1)<0则表示前后两次偏导方向相反,此时步长乘以增大系数增大步长;若cj(k)cj(k-1)>0则表示前后两次偏导方向相同,此时步长乘以减小系数减小步长;若cj(k)cj(k-1)=0则表示前后至少有一次偏导为零,此时步长不变。
步骤7:根据求出的步长向量和梯度向量修正各权值。
步骤8:信号正向传播,求出均方误差e(k+1)。
步骤9:判断是否满足终止条件,如果满足终止条件则输出结果,训练结束;如果不满足终止条件则令k=k+1,跳到步骤5进行下一次迭代。
根据本发明第一部分,带噪语音被检测为语音帧时,线性神经网络工作在顺序训练方式,此时相当于lms算法。具体包括以下几个步骤:
步骤1:读入一噪声帧数据作为线性神经网络的目标输出ti,其中n为输入层神经元的个数,下标i表示第i帧数据。读入对应的一帧参考噪声,并转化成输入样本集xi。
t1=[d1(1),d1(2),…,d1(m)]t
x1=[x1(1),x1(2),…,x1(m)]
x1(1)=[x1(1),0,…,0]t
x1(2)=[x1(2),x1(1),0,…,0]t
x1(n)=[x1(n),x1(n-1),…,x1(1)]t
x1(m)=[x1(m),x1(m-1),…,x1(m-n+1)]t
ti=[di(n),di(n+1),…,di(m)]t,i=2,3,4,…
xi=[xi(1),xi(2),…,xi(m-n+1)]
xi(1)=[xi(n),xi(n-1),…,xi(1)]t
xi(m-n+1)=[xi(m),xi(m-1),…,xi(m-n+1)]t
步骤2:初始化权值向量w(0),设置步长调节系数α,β,令p=0。其中w(p)=[w1(p),w2(p),…,wn(p)]t,p表示迭代次数,p=0,1,2,…,m-n。
步骤3:读入第p个样本,信号正向传播,算出其误差e(p)。
步骤4:求出误差平方对权值向量的梯度。
步骤5:根据输入信号对步长进行调整。
步骤6:根据梯度和步长对权值向量进行修正。
步骤7:p=p+1,若p<m-n则未训练完所有样本,转到步骤3,进行下一次训练;否则,输出结果结束训练。
下面以一个具体实施例对vad的实现进行详细阐述。
如附图4所示,包括如下步骤:
1)以采样频率fs=48khz,线性神经网络输入层神经元个数n=64为例。设置前导无语音时长tr=30ms,一帧数据的时长tm=5ms,对数频谱距离的阈值为thd=2.5。则有:
m=trfs=5×10-3×48×103=240
o=n-1=63
t=m-o=240-63=177
nis=tr/tm=6
其中m为帧长,o为帧叠,t为帧移,nis为前导无语音段的帧数。
2)选择矩形窗对带噪语音d(n)和参考噪声v1(n)进行加窗分帧处理。第i帧带噪语音用di(m)表示,第i帧参考噪声用xi(m)表示,则有:
3)对各帧帯噪语音分别进行离散傅里叶变换,求出各帧噪声的频谱di(k),对前导nis帧带噪语音的频谱求平均值,其结果作为初始噪声的频谱xnoise(k)。分别对各帧带噪语音和初始噪声的频谱取模再取对数算出对数频谱
4)比较对数频谱距离th(i)和阈值thd的大小。若th(i)≥thd则该帧为语音帧;若th(i)<thd则该帧为噪声帧,然后根据公式(6)更新初始噪声对数频谱。
下面以另一个具体实施例对弹性搜索个体变步长算法实现线性神经网络批训练进行描述。
如附图5所示,包括:
5)读入一噪声帧数据作为线性神经网络的目标输出ti,其中n为输入层神经元的个数,下标i表示第i帧数据。读入对应的一帧参考噪声,并转化成输入样本集xi。
t1=[d1(1),d1(2),…,d1(m)]t
x1=[x1(1),x1(2),…,x1(m)]
x1(1)=[x1(1),0,…,0]t
x1(2)=[x1(2),x1(1),0,…,0]t
x1(n)=[x1(n),x1(n-1),…,x1(1)]t
x1(m)=[x1(m),x1(m-1),…,x1(m-n+1)]t
ti=[di(n),di(n+1),…,di(m)]t,i=2,3,4,…
xi=[xi(1),xi(2),…,xi(m-n+1)]
xi(1)=[xi(n),xi(n-1),…,xi(1)]t
xi(m-n+1)=[xi(m),xi(m-1),…,xi(m-n+1)]t
6)设置步长增大系数a=1.2,步长减小系数为b=0.5。对每一噪声帧训练时都初始化步长向量ηi(0)=0.01×ones(n,1),对第1噪声帧初始化权值向量w1(0)=0.01×randn(n,1),对第i(i>1)噪声帧初始化权值向量为前一帧训练的结果。
7)设置训练终止条件,根据一帧语音的时长和硬件条件在满足实时处理条件下设置合适的最大迭代次数train_num,根据降噪需要达到的效果设置合适的梯度范数最小值min_grad,均方误差e(k)的最小值error_goal。
8)读入样本集,求出均方误差e(k),然后求解均方误差对各权值的偏导,保留其方向为cj(k)。当cj(k)cj(k-1)<0时前后两次第j个梯度分量的方向相反,则减小对应的步长分量;当cj(k)cj(k-1)>0时前后两次第j个梯度分量的方向相同,则增大对应的步长分量;当cj(k)cj(k-1)=0时前后两次至少有一次第j个梯度分量为零,则保持对应的步长分量不变。
9)根据梯度和步长修正各权值,判断是否满足终止条件。当达到最大迭代次数tain_num,或者达到梯度范数最小值min_grad,或者均方误差e(k)达到最小值error_goal,输出结果,结束这帧数据的处理;否则进行下一次迭代。
下面以再一个具体实施例对线性神经网络顺序训练的实现进行详细阐述。
如附图6所示,包括:
10)初始化权值向量为前一帧数据的权值向量训练结果,设置α=1/256,β=-11。读入第1个样本,信号正向传播输出这个样本的训练误差e(p)。
11)求出误差平方对权值向量的梯度,根据式(7),(8)和(9)对步长进行调整。
yy(p)=αx(p)+(1-α)yy(p-1)(7)
yyl(p)=max{yy(p),0.001}(8)
12)根据算出的梯度和调整的步长对权值向量进行修正。判断样本是否训练完,如果所有样本已经训练完则输出结果,结束这帧数据的处理;如果所有样本未训练完则继续下一个样本的训练。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 还没有人留言评论。精彩留言会获得点赞!