使用近/远场渲染的距离摇移的制作方法
本申请涉及并要求于2016年6月17日提交的标题为“systemsandmethodsfordistancepanningusingnearandfarfieldrendering”的美国临时申请no.62/351,585的优先权,该申请的全部内容通过引用并入本文。
本专利文件中描述的技术涉及关于在声音再现系统中合成空间音频的方法和装置。
背景技术:
几十年来,空间音频再现引起了音频工程师和消费电子行业的兴趣。空间声音再现需要双声道或多声道电-声系统(例如,扬声器、耳机),其必须根据应用(例如,音乐会表演、电影院、家庭高保真音响设备、计算机显示器、单独的头戴式显示器)的上下文来配置,这在通过引用并入本文的jot,jean-marc的“real-timespatialprocessingofsoundsformusic,multimediaandinteractivehuman-computerinterfaces”ircam,1placeigor-stravinsky1997,(下文称为“jot,1997”)中进一步描述。
用于电影和家庭视频娱乐业的音频记录和再现技术的发展已经导致各种多声道“环绕声”记录格式(最值得注意的是5.1和7.1格式)的标准化。已经开发出了各种音频记录格式用于编码记录中的三维音频线索。这些3-d音频格式包括ambisonics和包括升高的扬声器声道的离散多声道音频格式,诸如nhk22.2格式。
下混被包括在各种多声道数字音频格式的声轨数据流中,诸如来自加利福尼亚州卡拉巴萨斯(calabasas)的dts公司的dts-es和dts-hd。这种下混是向后兼容的,并且可以由遗留解码器解码并在现有回放装备上再现。这种下混包括数据流扩展,其携带被遗留解码器忽略但可以被非遗留解码器使用的附加音频声道。例如,dts-hd解码器可以恢复这些附加声道,减去它们在向后兼容的下混中的贡献,并且以与向后兼容格式不同的目标空间音频格式渲染它们,该目标空间音频格式可以包括升高的扬声器位置。在dts-hd中,在向后兼容的混合中和在目标空间音频格式中附加声道的贡献由混合系数的集合(例如,每个扬声器声道一个)来描述。在编码阶段指定声轨所针对的目标空间音频格式。
这种方法允许以与遗留环绕声解码器兼容的数据流的形式和在编码/生产阶段期间也选择的一个或多个替代目标空间音频格式来编码多声道音频声轨。这些替代目标格式可以包括适合于改进的三维音频线索的再现的格式。但是,这个方案的一个限制是,为另一个目标空间音频格式编码相同的声轨需要返回到生产设施,以便记录和编码为新格式混合的声轨的新版本。
基于对象的音频场景编码提供独立于目标空间音频格式的声轨编码的通用解决方案。基于对象的音频场景编码系统的示例是用于场景的mpeg-4高级音频二进制格式(aabifs)。在这种方法中,每个源信号与渲染线索数据流一起单独发送。这个数据流携带空间音频场景渲染系统的参数的时变值。可以以格式无关的音频场景描述的形式提供这个参数集,使得可以通过根据这种格式设计渲染系统来以任何目标空间音频格式渲染声轨。每个源信号结合其相关联的渲染线索,定义“音频对象”。这种方法使得渲染器能够实现最准确的空间音频合成技术,该技术可用于以在再现端选择的任何目标空间音频格式渲染每个音频对象。基于对象的音频场景编码系统还允许在解码阶段对渲染的音频场景进行交互式修改,包括重新混合、音乐重新解释(例如,卡拉ok)或场景中的虚拟导航(例如,视频游戏)。
对多声道音频信号的低位速率传输或存储的需求促使开发了新的频域空间音频编码(sac)技术,包括双耳线索编码(bcc)和mpeg环绕。在示例性sac技术中,m-声道音频信号以下混音频信号的形式被编码,伴随有描述时频域中原始m-声道信号中存在的声道间关系(声道间相关性和水平(level)差异)的空间线索数据流。因为与音频信号数据速率相比而言下混信号包括少于m个音频声道并且空间线索数据速率小,所以这种编码方法显著降低了数据速率。此外,可以选择下混格式以促进与遗留装备的向后兼容性。
在如美国专利申请no.2007/0269063中描述的称为空间音频场景编码(sasc)的这种方法的变体中,发送到解码器的时频空间线索数据是与格式无关的。这使得能够以任何目标空间音频格式进行空间再现,同时保持在编码的声轨数据流中携带向后兼容的下混信号的能力。但是,在这种方法中,编码的声轨数据不定义可分离的音频对象。在大多数记录中,位于声音场景中的不同位置的多个声源在时频域中是并发的。在这种情况下,空间音频解码器不能在下混音频信号中分离它们的贡献。因此,音频再现的空间保真度可能受到空间定位误差的影响。
mpeg空间音频对象编码(saoc)类似于mpeg环绕,因为编码的声轨数据流包括向后兼容的下混音频信号以及时频线索数据流。saoc是一种多目标编码技术,被设计为以单声道或双声道下混音频信号发送m个音频对象。与saoc下混信号一起发送的saoc线索数据流包括时频对象混合线索,该时频对象混合线索在每个频率子带中描述应用于单声道或双声道下混信号的每个声道中的每个对象输入信号的混合系数。此外,saoc线索数据流包括允许在解码器侧单独地对音频对象进行后处理的频域对象分离线索。saoc解码器中提供的对象后处理功能模仿基于对象的空间音频场景渲染系统的能力并支持多个目标空间音频格式。
saoc提供了一种用于多个音频对象信号的低位速率传输和计算上高效的空间音频渲染以及基于对象的和格式无关的三维音频场景描述的方法。但是,saoc编码流的遗留兼容性限于saoc音频下混信号的双声道立体声再现,因此不适合于扩展现有的多声道环绕声编码格式。此外,应当注意的是,如果在saoc解码器中对音频对象信号应用的渲染操作包括某些类型的后处理效果(诸如人工混响),那么saoc下混信号在感知上不代表被渲染的音频场景(因为这些效果在渲染场景中是可听见的,但不会同时结合在包含未处理的对象信号的下混信号中)。
此外,saoc遭受与sac和sasc技术相同的限制:saoc解码器不能在下混信号中完全分离在时频域中并发的音频对象信号。例如,由saoc解码器对对象的广泛放大或衰减通常产生被渲染场景的音频质量的不可接受的降低。
可以通过两种互补的方法产生空间编码的声轨:(a)利用重合或紧密间隔的麦克风系统(基本上放置在场景内的收听者的虚拟位置处或附近)来记录现有的声音场景或(b)合成虚拟声音场景。
使用传统3d双耳音频记录的第一种方法可以说通过使用“模拟人(dummy)头”麦克风创建尽可能接近“你在那里”的体验。在这种情况下,声音场景被实时捕获,这一般是通过使用将麦克风放置在耳朵处的声学人体模型。然后使用双耳再现(其中所记录的音频在耳朵处通过耳机重放)来重建原始空间感知。传统模拟人头记录的一个限制是它们只能捕获实时事件,而且只能从模拟人的视角和头部方向捕获。
利用第二种方法,已经开发了数字信号处理(dsp)技术,以通过对模拟人头(或者具有插入到耳道中的探头麦克风的人头)周围的头部相关传递函数(hrtf)的选择进行采样并且对那些测量进行插值以近似将对其间的任何位置进行测量的hrtf来模拟双耳监听。最常见的技术是将所有测得的同侧和对侧hrtf转换为最小相位并在它们之间执行线性插值以导出hrtf对。hrtf对与适当的耳间时间延迟(itd)组合表示期望的合成位置的hrtf。这种插值一般在时域中执行,其通常包括时域滤波器的线性组合。插值还可以包括频域分析(例如,对一个或多个频率子带执行的分析),然后是频域分析输出之间的线性插值。时域分析可以提供更加计算高效的结果,而频域分析可以提供更准确的结果。在一些实施例中,插值可以包括时域分析和频域分析的组合,诸如时频分析。可以通过相对于仿真距离减小源的增益来模拟距离线索。
这种方法已被用于仿真远场中的声源,其中耳间hrtf差异随距离的改变可忽略不计。但是,随着源越来越靠近头部(例如,“近场”),头部的尺寸相对于声源的距离变得显著。这种过渡的地点随频率而变化,但惯例指明源超过大约1米(例如,“远场”)。随着声源进一步进入收听者的近场,耳间hrtf改变变得显著,尤其是在较低的频率处。
一些基于hrtf的渲染引擎使用远场hrtf测量的数据库,其包括在距收听者的恒定径向距离处测得的所有数据。因此,对于比远场hrtf数据库内的原始测量近得多的声源,难以准确地仿真变化的频率相关hrtf线索。
许多现代3d音频空间化产品选择忽略近场,因为近场hrtf建模的复杂性传统上过于昂贵并且近场声学事件在典型的交互式音频模拟中传统上并不常见。但是,虚拟现实(vr)和增强现实(ar)应用的出现导致了一些应用,其中虚拟对象常常会更靠近用户的头部而入出现。对这些对象和事件的更准确的音频模拟已成为需要。
先前已知的基于hrtf的3d音频合成模型利用在收听者周围的固定距离处测得的单个hrtf对(即,同侧和对侧)集合。这些测量通常发生在远场,其中hrtf不随距离增加而显著改变。因此,可以通过适当的一对远场hrtf滤波器对源进行滤波并根据仿真随距离的能量损耗(例如,平方反比定律)的与频率无关的增益缩放结果信号来仿真较远距离的声源。
但是,随着声音越来越接近头部,在相同的入射角处,hrtf频率响应可以相对于每只耳朵显著改变,并且不再能用远场测量有效地仿真。模拟对象在接近头部时的声音的这种场景对于诸如虚拟现实之类的较新的应用是特别感兴趣的,在这些应用中,对对象和化身的较仔细的检查和交互将变得更加普遍。
全3d对象(例如,音频和元数据位置)的传输已被用于实现具有6个自由度的头部跟踪和交互,但是这种方法每个源需要多个音频缓冲器并且由于使用较多的源而使得复杂性大大增加。这种方法还可能需要动态源管理。此类方法不能容易地集成到现有的音频格式中。对于固定数量的声道,多声道混合也具有固定的开销,但是通常需要高声道计数来建立足够的空间分辨率。现有的场景编码(诸如矩阵编码或ambisonics)具有较低的声道计数,但不包括指示来自收听者的音频信号的期望深度或距离的机制。
附图说明
图1a-1c是用于示例音频源地点的近场和远场渲染的示意图。
图2a-2c是用于生成具有距离线索的双耳音频的算法流程图。
图3a示出了估计hrtf线索的方法。
图3b示出了头部相关的脉冲响应(hrir)插值的方法。
图3c是hrir插值的方法。
图4是用于两个同时声源的第一示意图。
图5是用于两个同时声源的第二示意图,
图6是用于3d声源的示意图,其中声音是方位角、仰角和半径(θ,φ,r)的函数。
图7是用于将近场和远场渲染应用于3d声源的第一示意图。
图8是用于将近场和远场渲染应用于3d声源的第二示意图。
图9示出了hrir插值的第一时间延迟滤波方法。
图10示出了hrir插值的第二时间延迟滤波方法。
图11示出了firir插值的简化的第二时间延迟滤波方法。
图12示出了简化的近场渲染结构。
图13示出了简化的双源近场渲染结构。
图14是具有头部跟踪的主动解码器的功能框图。
图15是具有深度和头部跟踪的主动解码器的功能框图。
图16是具有利用单个转向声道“d”的深度和头部跟踪的替代主动解码器的功能框图。
图17是具有仅利用元数据深度的深度和头部跟踪的主动解码器的功能框图。
图18示出了用于虚拟现实应用的示例最佳传输场景。
图19示出了用于主动3d音频解码和渲染的通用体系架构。
图20示出了用于三个深度的基于深度的子混合的示例。
图21是音频渲染装置的一部分的功能框图。
图22是音频渲染装置的一部分的示意性框图。
图23是近场和远场音频源地点的示意图。
图24是音频渲染装置的一部分的功能框图。
具体实施方式
本文描述的方法和装置最佳地将全3d音频混合(例如,方位角、仰角和深度)表示为“声音场景”,其中解码处理促进头部跟踪。可以针对收听者的朝向(例如,偏航、俯仰、滚动)和3d位置(例如,x,y,z)来修改声音场景渲染。这提供了将声音场景源位置视为3d位置而不是限制于相对于收听者的位置的能力。本文讨论的系统和方法可以在任何数量的音频声道中完全表示这样的场景,以提供与通过诸如dtshd之类的现有音频编解码器的传输的兼容性,但是基本上携带比7.1声道混合更多的信息(例如,深度、高度)。这些方法可以容易地被解码为任何声道布局或通过dtsheadphone:x,其中头部跟踪特征将特别有利于vr应用。这些方法还可以实时地用于具有vr监视的内容制作工具,诸如由dtsheadphone:x使能的vr监视。当接收遗留2d混合时(例如,仅方位角和仰角),解码器的完整3d头部跟踪也是向后兼容的。
一般定义
以下结合附图阐述的详细描述旨在作为本主题的当前优选实施例的描述,而无意表示其中可以构造或使用本主题的唯一形式。本描述阐述了结合所示实施例开发和操作本主题的功能和步骤顺序。应当理解的是,相同或等同的功能和顺序可以通过也旨在涵盖在本主题的范围内的不同实施例来实现。还应当理解的是,关系术语(例如,第一、第二)的使用仅用于区分一个实体与另一个实体,而不一定要求或暗示这些实体之间的任何实际的这种关系或顺序。
本主题涉及处理音频信号(即,表示物理声音的信号)。这些音频信号由数字电子信号表示,在下面的讨论中,可以示出或讨论模拟波形以说明概念。但是,应当理解的是,本主题的典型实施例将在数字字节或字的时间序列的上下文中操作,其中这些字节或字形成模拟信号或最终物理声音的离散近似。离散的数字信号与周期性采样的音频波形的数字表示对应。对于均匀采样,以足以满足感兴趣频率的nyquist采样定理的速率或高于该速率对波形进行采样。在典型的实施例中,可以使用大约每秒44100个样本(例如,44.1khz)的均匀采样速率,但是可以替代地使用更高的采样速率(例如,96khz、128khz)。根据标准数字信号处理技术,应当选择量化方案和位分辨率以满足特定应用的要求。本主题的技术和装置通常将在多个声道中相互依赖地应用。例如,它可以用在“环绕”音频系统的上下文中(例如,具有多于两个声道)。
如本文所使用的,“数字音频信号”或“音频信号”不仅仅描述数学抽象,而是代替地表示由能够被机器或装置检测的物理介质体现或携带的信息。这些术语包括记录或发送的信号,并且应当被理解为包括通过任何形式的编码的传送,包括脉冲编码调制(pcm)或其它编码。输出、输入或中间音频信号可以通过各种已知方法中的任何一种进行编码或压缩,包括mpeg、atrac、ac3或dts公司的专有方法,如美国专利no.5,974,380;5,978,762;以及6,487,535中所描述的。可能需要对计算进行一些修改以适应特定的压缩或编码方法,这对于本领域技术人员来说是清楚的。
在软件中,音频“编解码器”包括根据给定音频文件格式或流传输音频格式来格式化数字音频数据的计算机程序。大多数编解码器都被实现为与一个或多个多媒体播放器(诸如quicktimeplayer、xmms、winamp、windowsmediaplayer、prologic或其它编解码器)接口的库。在硬件中,音频编解码器是指将模拟音频编码为数字信号并将数字解码回模拟信号的单个或多个设备。换句话说,它包含运行在公共时钟上的模数转换器(adc)和数模转换器(dac)。
音频编解码器可以在消费者电子设备(诸如dvd播放器、蓝光播放器、电视调谐器、cd播放器、手持播放器、互联网音频/视频设备、游戏机、移动电话或其它电子设备)中实现。消费者电子设备包括中央处理单元(cpu),其可以表示一种或多种常规类型的此类处理器,诸如ibmpowerpc、intelpentium(x86)处理器或其它处理器。随机存取存储器(ram)临时存储由cpu执行的数据处理操作的结果,并且通常经由专用的存储器通道与其互连。消费者电子设备还可以包括永久存储设备,诸如硬盘驱动器,其也通过输入/输出(i/o)总线与cpu通信。还可以连接其它类型的存储设备,诸如带式驱动器、光盘驱动器或其它存储设备。图形卡也可以经由视频总线连接到cpu,其中图形卡将代表显示数据的信号发送到显示器监视器。诸如键盘或鼠标之类的外部外围数据输入设备可以通过usb端口连接到音频再现系统。usb控制器将数据和指令翻译到cpu并从cpu翻译数据和指令,用于连接到usb端口的外围设备。诸如打印机、麦克风、扬声器或其它设备之类的附加设备可以连接到消费者电子设备。
消费者电子设备可以使用具有图形用户界面(gui)的操作系统,诸如来自华盛顿州雷蒙德市(redmond)的微软公司的windows、来自加利福尼亚州库比蒂诺(cupertino)的苹果公司的macos、为移动操作系统(诸如android或其它操作系统)而设计的各种版本的移动gui。消费者电子设备可以执行一个或多个计算机程序。一般而言,操作系统和计算机程序有形地体现在计算机可读介质中,其中计算机可读介质包括固定或可移动数据存储设备中的一个或多个,包括硬盘驱动器。操作系统和计算机程序两者可以从上面提到的数据存储设备被加载到ram中以供cpu执行。计算机程序可以包括指令,当指令由cpu读取和执行时,使cpu执行步骤以执行本主题的步骤或特征。
音频编解码器可以包括各种配置或体系架构。在不脱离本主题的范围的情况下,可以容易地替换任何此类配置或体系架构。本领域普通技术人员将认识到的是,上述序列是计算机可读介质中最常用的,但是在不脱离本主题的范围的情况下,存在可以被替换的其它现有序列。
音频编解码器的一个实施例的元素可以由硬件、固件、软件或其任意组合来实现。当被实现为硬件时,音频编解码器可以在单个音频信号处理器上被采用或者分布在各种处理部件中。当在软件中实现时,本主题的实施例的元素可以包括执行需要任务的代码片段。软件优选地包括执行在本主题的一个实施例中描述的操作的实际代码,或者包括仿真或模拟操作的代码。程序或代码片段可以存储在处理器或机器可访问介质中,或者由在载波(例如,由载波调制的信号)中体现的计算机数据信号通过传输介质发送。“处理器可读或可访问介质”或“机器可读或可访问介质”可以包括可以存储、发送或传送信息的任何介质。
处理器可读介质的示例包括电子电路、半导体存储器设备、只读存储器(rom)、闪存存储器、可擦除可编程rom(eprom)、软盘、紧凑盘(cd)rom、光盘、硬盘、光纤介质、射频(rf)链路或其它介质。计算机数据信号可以包括可以通过传输介质(诸如电子网络通道、光纤、空气、电磁、rf链路或其它传输介质)传播的任何信号。代码片段可以经由诸如互联网、内联网或其他网络之类的计算机网络下载。机器可访问介质可以体现在制品中。机器可访问介质可以包括当由机器访问时使机器执行下面描述的操作的数据。这里的术语“数据”是指为机器可读目的而编码的任何类型的信息,其可以包括程序、代码、数据、文件或其它信息。
本主题的实施例的全部或部分可以由软件实现。软件可以包括彼此耦合的若干模块。软件模块耦合到另一模块,以生成、发送、接收或处理变量、参数、自变量、指针、结果、更新后的变量、指针或者其它输入或输出。软件模块还可以是与在平台上执行的操作系统交互的软件驱动程序或接口。软件模块还可以是用于配置、设置、初始化、发送数据到硬件设备或者从硬件设备接收数据的硬件驱动器。
本主题的一个实施例可以被描述为通常被描绘为流程图、流程图表、结构图或框图的处理。虽然框图可以将操作描述为顺序处理,但是许多操作可以并行或并发地执行。此外,可以重新布置操作的次序。当操作完成时,处理可以终止。处理可以与方法、程序、过程或其它步骤组对应。
本说明书包括用于合成音频信号的方法和装置,特别是在耳机(例如,头戴式耳机)应用中。虽然在包括头戴式耳机的示例性系统的上下文中呈现了本公开的各方面,但是应当理解的是,所描述的方法和装置不限于这样的系统,并且本文的教导适用于包括合成音频信号的其它方法和装置。如在以下描述中所使用的,音频对象包括3d位置数据。因此,音频对象应当被理解为包括具有3d位置数据的音频源的特定组合表示,其通常在位置上是动态的。相反,“声源”是用于在最终混合或渲染中回放或再现的音频信号,并且它具有预期的静态或动态渲染方法或目的。例如,源可以是信号“前左”,或者源可以播放到低频效果(“lfe”)声道或向右摇移(pan)90度。
本文描述的实施例涉及音频信号的处理。一个实施例包括一种方法,其中使用至少一个近场测量集合来创建近场听觉事件的印象,其中近场模型与远场模型并行运行。通过两个模型之间的交叉渐变来创建要在由指定的近场和远场模型模拟的区域之间的空间区域中模拟的听觉事件。
本文描述的方法和装置利用多个头部相关传递函数(hrtf)集合,其已经在距离参考头部的各种距离处被合成或测量,从近场跨越到远场的边界。附加的合成或测得的传递函数可以用于延伸到头部的内部,即,比近场更近的距离。此外,每个hrtf集合的相对距离相关增益被归一化到远场hrtf增益。
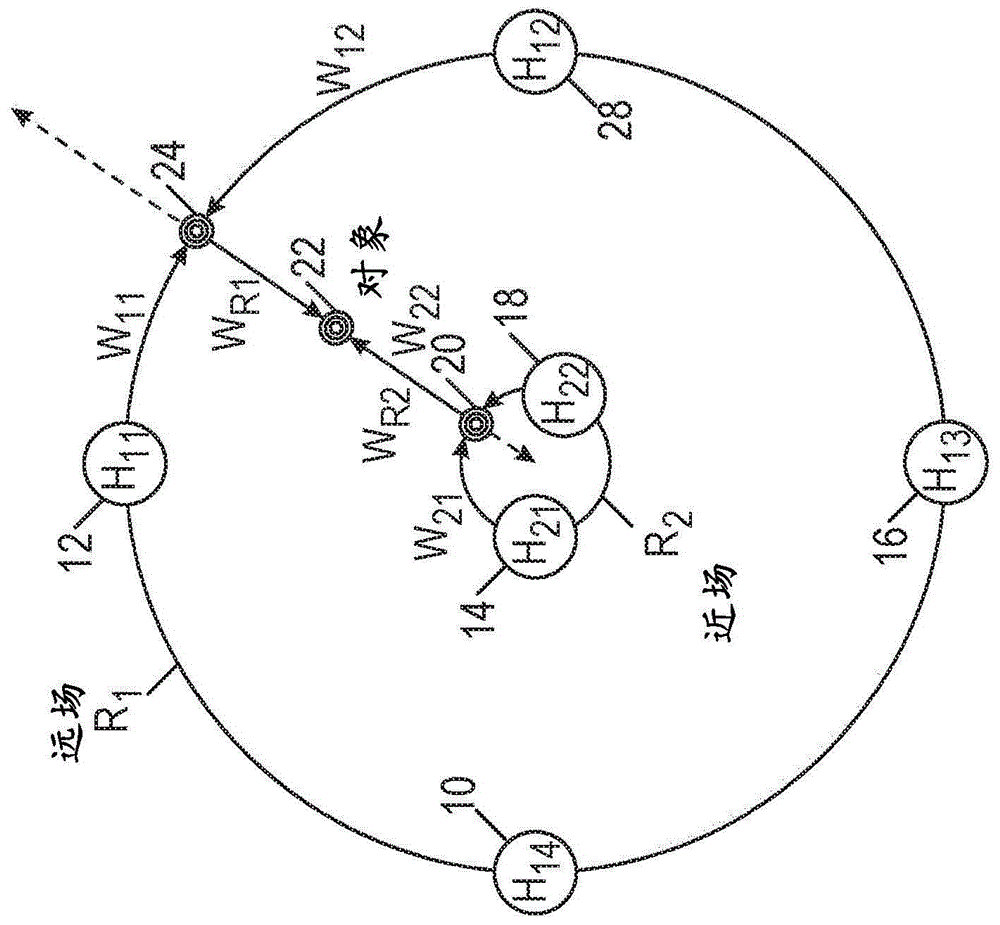
图1a-1c是示例音频源地点的近场和远场渲染的示意图。图1a是相对于收听者在声音空间中定位音频对象的基本示例,包括近场和远场区域。图1a呈现了使用两个半径的示例,但是声音空间可以使用多于两个半径来表示,如图1c中所示。特别地,图1c示出了使用任意数量的重要半径的图1a的扩展的示例。图1b示出了使用球形表示21的图1a的示例球形延伸。特别地,图1c示出了对象22可以具有相关联的高度23,以及到地平面上的相关联的投影25、相关联的仰角27和相关联的方位角29。在这种情况下,可以在半径为rn的全3d球体上对任何适当数量的hrtf进行采样。每个共同半径hrtf集合中的采样不必相同。
如图1a-1b中所示,圆圈r1表示距收听者的远场距离,圆圈r2表示距收听者的近场距离。如图1c中所示,对象可以位于远场位置、近场位置、其间某处、近场内部或远场外。示出了多个hrtf(hxy),以关连到以原点为中心的环r1和r2上的位置,其中x表示环编号,y表示环上的位置。这种集合将被称为“共同半径hrtf集”。使用约定wxy,四个地点权重在图的远场集中示出,两个在近场集中示出,其中x表示环编号,y表示环上的位置。wr1和wr2表示将对象分解为共同半径hrtf集的加权组合的径向权重。
在图1a和图1b所示的示例中,当音频对象通过收听者的近场时,测量到头部中心的径向距离。识别出界定这个径向距离的两个测得的hrtf数据集。对于每个集合,基于声源地点的期望方位角和仰角导出适当的hrtf对(同侧和对侧)。然后通过对每个新hrtf对的频率响应进行插值来创建最终组合的hrtf对。这种插值将有可能基于要渲染的声源的相对距离和每个hrtf集的实际测得的距离。然后,通过导出的hrtf对来对要渲染的声源进行滤波,并且基于到收听者头部的距离来增加或减小所得信号的增益。可以限制这个增益以避免由于声源非常接近收听者的一只耳朵而产生饱和。
每个hrtf集合可以跨越仅在水平的(horizontal)平面中产生的测量或合成hrtf的集合,或者可以表示围绕收听者的hrtf测量的整个范围。此外,每个hrtf集合可以基于径向测得的距离具有更少或更多数量的样本。
图2a-图2c是用于生成具有距离线索的双耳音频的算法流程图。图2a表示根据本主题的各方面的样本流程。在线12上输入音频和音频对象的位置元数据10。这个元数据用于确定径向权重wr1和wr2,如方框13中所示。此外,在方框14处,评估元数据以确定对象是位于远场边界内部还是外部。如果对象在远场区域内,由线16表示,那么下一步17是确定远场hrtf权重,诸如图1a中所示的w11和w12。如果对象不在远场内,如由线18所表示的,那么评估元数据以确定对象是否位于近场边界内,如方框20所示。如果对象位于近场和远场边界之间,如由线22所表示的,那么下一步是确定远场hrtf权重(方框17)和近场hrtf权重,诸如图1a中的w21和w22(方框23)。如果对象位于近场边界内,如由线24所表示的,那么下一步是在方框23处确定近场hrtf权重。一旦适当的径向权重、近场hrtf权重和远场hrtf权重已经计算出来,它们就在26、28处被组合。最后,在方框30中利用组合的权重过滤音频对象,以产生具有距离线索的双耳音频32。以这种方式,径向权重被用于从每个共同半径的hrtf集进一步缩放hrtf权重并创建距离增益/衰减,以重建对象位于期望位置处的感觉。这种相同的方法可以扩展到其中超出远场的值导致由径向权重施加的距离衰减的任何半径。小于近场边界r2的任何半径(称为“内部”)可以通过仅hrtf的近场集合的某种组合来重建。单个hrtf可以被用于表示被感知为位于收听者耳朵之间的单声道“中间声道”的地点。
图3a示出了估计hrtf线索的方法。hl(θ,φ)和hr(θ,φ)表示在单位球(远场)上对于在(方位角=θ,仰角=φ)处的源在左耳和右耳处测得的最小相位头部相关脉冲响应(hrir)。τl和τr表示到每只耳朵的飞行时间(通常去除了过多的共同延迟)。
图3b示出了hrir插值的方法。在这种情况下,存在预先测得的最小相位左耳和右耳hrir的数据库。通过对存储的远场hrir的加权组合求和来导出给定方向上的hrir。加权由增益的阵列确定,增益的阵列被确定为角位置的函数。例如,四个最接近的采样的hrir到期望位置的增益可以具有与到源的角距离成比例的正增益,其它所有增益被设置为零。可替代地,如果在方位角和仰角方向两者上对hrir数据库进行采样,那么可以使用vbap/vbip或类似的3d摇移器将增益应用于三个最接近的测得的hrir。
图3c是hrir插值的方法,图3c是图3b的简化版本。粗线暗示一条多于一个声道(等于我们数据库中存储的hrir的数量)的总线。g(θ,φ)表示hrir加权增益阵列并且可以假设它对于左耳和右耳是相同的。hl(f)、hr(f)表示左耳和右耳hrir的固定数据库。
此外,导出目标hrtf对的方法是基于已知技术(时域或频域)从每个最接近的测量环插值两个最接近的hrtf,然后基于到源的径向距离在那两个测量之间进一步插值。对于位于o1处的对象,通过等式(1)描述这些技术,并且对于位于o2处的对象,通过等式(2)描述这些技术。要注意的是,hxy表示在测得的环y中的位置索引x处测得的hrtf对。hxy是频率相关函数,α、β和δ都是插值加权函数。它们也可以是频率的函数。
o1=δ11(α11h11+α12h12)+δ12(β11h21+β12h22)(1)
o2=δ21(α21h21+α22h22)+δ22(β21h31+β22h32)(2)
在这个示例中,测得的hrtf集合在收听者周围的环中测量(方位角、固定半径)。在其它实施例中,可以围绕球体测量hrtf(方位角和仰角、固定半径)。在这种情况下,如文献中所描述的,hrtf将在两个或更多个测量之间进行插值。径向插值将保持不变。
hrtf建模的另一个要素涉及当声源接近头部时音频响度的指数增加。一般而言,每当到头部的距离减半,声音的响度将加倍。因此,例如,在0.25m处的声源的响度将是在1m处测得的相同声音的响度的大约四倍。类似地,在0.25m处测得的hrtf的增益将是在1m处测量的相同hrtf的增益的四倍。在这个实施例中,所有hrtf数据库的增益被归一化,使得感知的增益不随距离而改变。这意味着可以以最大位分辨率存储hrtf数据库。然后,与距离相关的增益也可以在渲染时应用于导出的近场hrtf近似。这允许实现者使用他们希望的任何距离模型。例如,hrtf增益可以随着它接近头部而被限制到某个最大值,这可以减少或防止信号增益变得过于失真或支配限制器。
图2b表示扩展算法,其包括距收听者的多于两个径向距离。可选地,在这个配置中,可以针对每个感兴趣的半径计算hrtf权重,但是对于与音频对象的地点不相关的距离,一些权重可以为零。在一些情况下,这些计算将导致零权重并且可以有条件地被省略,如图2a中所示。
图2c示出了又一个示例,其包括计算耳间(interaural)时间延迟(itd)。在远场中,典型的是在未通过在测得的hrtf之间进行插值而最初测量的位置导出近似hrtf对。这常常通过将测得的消声hrtf对转换成其最小相位等同物并且以分数时间延迟近似itd来完成。这适用于远场,因为只有一个hrtf集合,并且那个hrtf集合是在某个固定距离处测得的。在一个实施例中,确定声源的径向距离并识别两个最近的hrtf测量集合。如果源超出最远集合,那么实现与仅有一个远场测量集可用时的实现相同。在近场内,为要建模的声源从两个最近的hrtf数据库中的每一个导出两个hrtf对,并且进一步对这些hrtf对进行插值,以基于目标到参考测量距离的相对距离导出目标hrtf对。然后,或者从itd的查找表或者从诸如由woodworth定义的公式中导出目标方位角和仰角所需的itd。要注意的是,对于近场内外的类似方向,itd值没有显著差异。
图4是用于两个同时声源的第一示意图。使用这个方案,要注意点线内的区段如何是角距离的函数而同时hrir保持固定。在这个配置中,相同的左耳和右耳hrir数据库被实现两次。同样,粗体箭头表示等于数据库中的hrir数量的信号的总线。
图5是用于两个同时声源的第二示意图。图5示出没有必要为每个新的3d源对hrir进行插值。因为我们有线性时不变的系统,其输出可以在固定滤波器块之前混合。添加更多这样的源意味着我们只需要一次固定的滤波器开销,无论3d源的数量是多少。
图6是用于3d声源的示意图,其源是方位角、仰角和半径(θ,φ,r)的函数。在这种情况下,输入根据到源的径向距离而缩放,并且通常基于标准距离滚降曲线。这种方法的一个问题是虽然这种频率无关距离缩放对远场起作用,但它在近场(r<1)中不能很好地运作,因为对于固定的(θ,φ),hrir的频率响应随着源接近头部而开始变化。
图7是用于将近场和远场渲染应用于3d声源的第一示意图。在
图7中,假设存在单个3d源,其被表示为方位角、仰角和半径的函数。标准技术实现单一距离。根据本主题的各个方面,对两个分离的远场和近场hrir数据库进行采样。然后根据径向距离(r<1)的变化在这两个数据库之间应用交叉渐变。近场hrirs是针对远场hrirs归一化的增益,以便减少在测量中看到的任何与频率无关的距离增益。当r<1时,基于由g(r)定义的距离滚降函数将这些增益重新插入输入。要注意的是,当r>1时,gff(r)=1并且gnf(r)=0。要注意的是,当r<1时,gff(r)、gnf(r)是距离的函数,例如,gff(r)=a,gnf(r)=1-a。
图8是用于将近场和远场渲染应用于3d声源的第二示意图。图8类似于图7,但是在距头部不同距离处测得两个近场hrir集合。这将提供随径向距离的近场hrir改变的更好采样覆盖。
图9示出了hrir插值的第一时间延迟滤波方法。图9是图3b的替代方案。与图3b相反,图9提供了hrir时间延迟被存储为固定滤波器结构的一部分。现在,itd基于导出的增益用hrir进行插值。itd未基于3d源角度进行更新。要注意的是,这个示例不必要地将相同的增益网络应用两次。
图10示出了hrir插值的第二时间延迟滤波方法。图10通过对双耳g(θ,φ)和单个较大的固定滤波器结构h(f)应用一个增益集合,克服了图9中增益的两次应用。这个配置的一个优点是它使用一半数量的增益和对应数量的声道,但这是以hrir插值准确度为代价的。
图11示出了hrir插值的简化的第二时间延迟滤波方法。图11是具有两个不同3d源的图10的简化描绘,类似于关于图5所描述的。如图11中所示,实现从图10简化。
图12示出了简化的近场渲染结构。图12使用更简化的结构(对于一个源)实现近场渲染。这个配置类似于图7,但具有更简单的实现。
图13示出了简化的双源近场渲染结构。图3类似于图12,但包括两个近场hrir数据库集合。
前面的实施例假设利用每个源位置更新并针对每个3d声源计算不同的近场hrtf对。照此,处理要求将随着要渲染的3d源的数量而线性缩放。这一般是不期望的特征,因为用于实现3d音频渲染解决方案的处理器可以非常快速且以非确定性方式(可能取决于在任何给定时间要渲染的内容)超出其分配的资源。例如,许多游戏引擎的音频处理预算可能最多占cpu的3%。
图21是音频渲染装置的一部分的功能框图。与可变过滤开销相比,期望具有固定且可预测的过滤开销,并且具有小得多的每源开销。这将允许针对给定的资源预算并且以更确定的方式渲染更大数量的声源。这种系统在图21中描述。这种拓扑背后的理论在“acomparativestudyof3-daudioencodingandrenderingtechniques”中描述。
图21图示了使用固定滤波器网络60、混合器62和每对象增益和延迟的附加网络64的hrtf实现。在这个实施例中,每对象延迟的网络包括三个增益/延迟模块66、68和70,分别具有输入72、74和76。
图22是音频渲染装置的一部分的示意性框图。特别地,图22图示了使用图21中概述的基本拓扑的实施例,包括固定音频滤波器网络80、混合器82和每对象增益延迟网络84。在这个示例中,每源itd模型允许每对象的更准确的延迟控制,如图2c的流程图中所描述的。声源被应用于每对象增益延迟网络84的输入86,其通过应用一对能量保持增益或权重88、90在近场hrtf和远场hrtf之间划分,其中能量保持增益或权重88、90是基于相对于每个测得的集合的径向距离的声音的距离导出的。应用耳间时间延迟(itd)92、94以使左信号相对于右信号延迟。在方框96、98、100和102中进一步调整信号水平。
这个实施例使用单个3d音频对象,表示大于约1m远的四个地点的远场hrtf集和表示比大约1m近的四个地点的近场hrtf集。假设任何基于距离的增益或过滤都已经应用于这个系统的输入上游的音频对象。在这个实施例中,对于位于远场中的所有源,gnear=0。
左耳和右耳信号相对于彼此延迟,以模仿近场和远场信号贡献的itd。左耳和右耳以及近场和远场的每个信号贡献由四个增益的矩阵加权,增益的值由音频对象相对于被采样的hrtf位置的地点来确定。例如在最小相位滤波器网络中,hrtf104、106、108和110被存储,其中耳间延迟被移除。每个滤波器组的贡献被加到左侧112或右侧114输出并发送到耳机以进行双耳收听。
对于受存储器或声道带宽约束的实现,有可能实现提供类似声音结果但不需要基于每个源实现itd的系统。
图23是近场和远场音频源地点的示意图。特别地,图23图示了使用固定滤波器网络120、混合器122和每对象增益的附加网络124的hrtf实现。在这种情况下,不应用每源itd。在被提供给混合器122之前,每对象处理每个共同半径hrtf集136和138以及径向权重130、132应用hrtf权重。
在图23中所示的情况下,固定滤波器网络实现hrtf126、128的集合,其中保留原始hrtf对的itd。因此,该实现仅需要用于近场和远场信号路径的单个增益集合136、138。声源被应用于每对象增益延迟网络124的输入134,其通过应用一对能量或振幅保持增益130、132在近场hrtf和远场hrtf之间划分,其中这对能量或振幅保持增益130、132是基于相对于每个测得的集合的径向距离的声音的距离导出的。在方框136和138中进一步调整信号水平。每个滤波器组的贡献被加到左侧140或右侧142输出并发送到耳机以进行双耳收听。
这个实现具有以下缺点:由于在各自具有不同时间延迟的两个或更多个对侧hrtf之间的插值,所渲染的对象的空间分辨率将不太集中。利用充分采样的hrtf网络,可以最小化相关联伪像的可听度。对于稀疏采样的hrtf集,与对侧滤波器求和相关联的梳状滤波可以是可听见的,尤其是在被采样的hrtf地点之间。
所描述的实施例包括以足够的空间分辨率采样的至少一个远场hrtf集,以便提供有效的交互式3d音频体验以及靠近左耳和右耳采样的一对近场hrtf。虽然在这种情况下稀疏地采样近场hrtf数据空间,但效果仍然非常有说服力。在进一步的简化中,可以使用单个近场或“中间”hrtf。在这种最小的情况下,只有在远场集活动时才能实现方向性。
图24是音频渲染装置的一部分的功能框图。图24是音频渲染装置的一部分的功能框。图24表示上面讨论的附图的简化实现。实际实现将可能具有被采样的远场hrtf位置的更大集合,其也在三维收听空间的周围被采样。而且,在各种实施例中,可以对输出进行附加的处理步骤,诸如串扰消除,以产生适合于扬声器再现的转听(transaural)信号。类似地,要注意的是,跨越共同半径集的距离摇移可以被用于创建子混合(例如,图23中的混合方框122),使得其适合于其它适当配置的网络的存储/传输/转码或其它延迟渲染。
以上描述描述了用于声音空间中音频对象的近场渲染的方法和装置。在近场和远场中渲染音频对象的能力使得能够完全渲染不仅仅是对象的深度,而且还有使用主动转向/摇移解码的任何空间音频混合,诸如ambisonics、矩阵编码等,从而使得能够有超出水平平面中的简单旋转的完全平移(translation)头部跟踪(例如,用户移动)。现在将描述用于将深度信息附加到例如或者通过捕获或者通过ambisonic摇移创建的ambisonic混合的方法和装置。本文描述的技术将使用一阶ambisonics作为示例,但是也可以应用于三阶或更高阶的ambisonics。
ambisonic基础
在多声道混合将捕获声音作为来自多个传入信号的贡献的情况下,ambisonics是一种捕获/编码固定信号集的方式,固定信号集表示声场中来自单个点的所有声音的方向。换句话说,可以使用相同的三维声(ambisonics)信号在任意数量的扬声器上重新渲染声场。在多声道情况下,您被限于再现源自声道的组合的源。如果没有高度,那么不发送高度信息。另一方面,ambisonics总是发送全方向画面,并且仅限于再现点。
考虑一阶(b格式)摇移方程的集合,其可以在很大程度上被认为是感兴趣点处的虚拟麦克风:
w=s*1/√2,其中w=全向分量;
x=s*cos(θ)*cos(φ),其中x=图8指向前方;
y=s*sin(θ)*cos(φ),其中y=图8指向右;
z=s*sin(φ),其中z=图8指向上方;
并且s是被摇移的信号。
从这四个信号中,可以创建指向任何方向的虚拟麦克风。照此,解码器主要负责重新创建指向用于渲染的每个扬声器的虚拟麦克风。虽然这种技术在很大程度上起作用,但它仅与使用真正的麦克风捕获响应一样好。因此,虽然解码的信号将对于每个输出声道具有期望的信号,但是每个声道也将包括一定量的泄漏或“流失”,因此存在某种最能表示解码器布局的设计解码器的技术,尤其是如果它具有不均匀的间距的话。这就是为什么许多三维声再现系统使用对称布局(四边形、六边形等)的原因。
这些种类的解决方案自然地支持头部跟踪,因为通过wxyz方向性转向信号的组合权重来实现解码。为了旋转b格式,可以在解码之前对wxyz信号应用旋转矩阵,并且结果将解码到适当调整的方向。但是,这种解决方案不能实现平移(例如,用户移动或改变收听者位置)。
主动解码扩展
期望抵抗泄漏并提高非均匀布局的性能。诸如harpex或dirac之类的主动解码解决方案不会形成用于解码的虚拟麦克风。相反,它们检查声场的方向、重新创建信号,并专门在它们已经为每个时频确定的方向上渲染信号。虽然这极大地改善了解码的方向性,但它限制方向性,因为每个时频片需要硬判决。在dirac的情况下,它每时频进行单向预测。在harpex的情况下,可以检测到两个方向波前。在任一种系统中,解码器都可以提供对方向性决策应当多软或多硬的控制。这种控制在本文中被称为“焦点”的参数,其可以是有用的元数据参数,以允许软焦点、内摇移或软化方向性断言的其它方法。
即使在主动解码器情况下,距离也是关键缺失功能。虽然方向直接编码在三维声摇移方程中,但是除了基于源距离的水平或混响比的简单改变之外,不能直接编码关于源距离的信息。在ambisonic捕获/解码场景中,可以并且应当对麦克风“靠近”或“麦克风接近”进行频谱补偿,但这不允许主动解码例如2米处的一个源以及4米处的另一个源。这是因为信号仅限于携带方向信息。实际上,被动解码器的性能依赖于如果收听者完全位于甜蜜点并且所有声道等距的情况下泄漏将不再是问题的事实。这些条件最大限化了预期声场的重新创建。
而且,b格式wxyz信号中的旋转的头部跟踪解决方案将不允许具有平移的变换矩阵。虽然坐标可以允许投影向量(例如,齐次坐标),但是在操作之后难以或不可能重新编码(这将导致修改丢失),并且难以或不可能渲染它。期望克服这些限制。
具有平移的头部跟踪
图14是具有头部跟踪的主动解码器的功能框图。如上面所讨论的,没有直接在b格式信号中编码的深度考虑因素。在解码时,渲染器将假设这个声场表示作为在扬声器的距离处渲染的声场的一部分的声源的方向。但是,通过利用主动转向,将形成的信号渲染到特定方向的能力仅受到摇移器的选择的限制。在功能上,这由图14表示,图14示出了具有头部跟踪的主动解码器。
如果所选择的摇移器是使用上述近场渲染技术的“距离摇移器”,那么随着收听者移动,可以通过均匀坐标变换矩阵修改源位置(在这种情况下是每个区间(bin)组的空间分析的结果),其中均匀坐标变换矩阵包括所需的旋转和平移,以便用绝对坐标来完全渲染完全3d空间中的每个信号。例如,图14中所示的主动解码器接收输入信号28并使用fft30将信号转换到时域。空间分析32使用时域信号来确定一个或多个信号的相对地点。例如,空间分析32可以确定第一声源位于用户前方(例如,0°方位角)并且第二声源位于用户的右侧(例如,90°方位角)。信号形成34使用时域信号来生成这些源,这些源作为具有相关联元数据的声音对象输出。主动转向38可以从空间分析32或信号形成34接收输入并旋转(例如,摇移)信号。特别地,主动转向38可以从信号形成34接收源输出并且可以基于空间分析32的输出来摇移源。主动转向38还可以从头部跟踪器36接收旋转或平移输入。基于旋转或平移输入,主动转向旋转或平移声源。例如,如果头部跟踪器36指示90°逆时针旋转,那么第一声源将从用户的前方旋转到左侧,并且第二声源将从用户的右侧旋转到前方。一旦在主动转向38中应用任何旋转或平移输入,就将输出提供给逆fft40并用于生成一个或多个远场声道42或一个或多个近场声道44。源位置的修改还可以包括类似于在3d图形领域中使用的源位置的修改的技术。
主动转向的方法可以使用方向(从空间分析计算的)和摇移算法(诸如vbap)。通过使用方向和摇移算法,为支持平移的计算增加主要在于改变到4x4变换矩阵的成本(与仅旋转所需的3x3相反)、距离摇移(大约是原始摇移方法的两倍),以及近场声道的附加快速逆傅立叶变换(ifft)。要注意的是,在这种情况下,4x4旋转和摇移操作是对数据坐标,而不是对信号,这意味着随着区间分组的增加,计算成本会降低。图14的输出混合可以作为用于类似构造的具有近场支持的固定hrtf滤波器网络的输入,如上面所讨论并在图21中所示的,因此,图14在功能上可以用作用于三维声对象的增益/延迟网络。
深度编码
一旦解码器支持具有平移的头部跟踪并且具有相当准确的渲染(由于主动解码),就期望直接将深度编码到源。换句话说,期望修改传输格式和摇移方程,以支持在内容产生期间添加深度指示符。与应用深度线索(诸如混合中的响度和混响改变)的典型方法不同,这种方法将使得能够恢复混合中的源的距离,以便可以为了最终回放能力而被渲染而不是产生侧的能力。本文讨论了具有不同权衡的三种方法,其中可以取决于可允许的计算成本、复杂性和诸如向后兼容性之类的要求进行权衡。
基于深度的子混合(n混合)
图15是具有深度和头部跟踪的主动解码器的功能框图。最直接的方法是支持“n”个独立b格式混合的并行解码,每个混合具有相关联的元数据(或假设的)深度。例如,图15示出了具有深度和头部跟踪的主动解码器。在这个示例中,近场和远场b格式被渲染为独立混合以及可选的“中间”声道。近场z声道也是可选的,因为大多数实现可能渲染现近场高度声道。当被丢弃时,高度信息被投射在远/中或使用下面讨论的针对近场编码的伪接近性(fauxproximity)(“froximity”)方法。其结果是ambisonic等同于上述“距离摇移器”/“近场渲染器”,因为各种深度混合(近、远、中等)维持分离。但是,在这种情况下,对于任何解码配置,总共只有八或九个声道的传输,并且存在一个完全独立于每个深度的灵活的解码布局。就像距离摇移器一样,它被推广到“n”个混合–但在大多数情况下可以使用两个(一个远场,一个近场),由此远于远场的源在远场中与距离衰减而被混合,并且在近场内部的源被置于近场混合中,有或没有“froximity”样式修改或投影,使得半径0处的源在没有方向的情况下被渲染。
为了概括这个过程,期望将一些元数据与每个混合相关联。在理想情况下,每个混合将用以下来标记:(1)混合的距离,以及(2)混合的焦点(或者混合应当多锐利地被解码-因此头部内的混合不会被过多的主动转向解码)。如果存在具有更多或更少反射的hrir(或可调谐反射引擎)的选择,那么其它实施例可以使用湿/干混合参数来指示使用哪个空间模型。优选地,将对布局进行适当的假设,因此不需要附加的元数据来将其作为8声道混合发送,从而使其与现有的流和工具兼容。
“d”声道(如在wxyzd中)
图16是具有单个转向声道“d”的深度和头部跟踪的替代主动解码器的功能框图。图16是替代方法,其中可能冗余信号集(wxyznear)被一个或多个深度(或距离)声道“d”替换。深度声道被用于编码关于三维声混合的有效深度的时频信息,其可以被解码器用于在每个频率处对声源进行距离渲染。“d”声道将编码为归一化距离,作为一个示例,其可以恢复为值0(位于原点的头部)、0.25(正好在近场中),并且最多为1(对于完全在远场中被渲染的源)。这种编码可以相对于一个或多个其它声道(诸如“w”声道)通过使用绝对值参考(诸如odbfs)或通过使用相对量值和/或相位来实现。由于超出远场而导致的任何实际距离衰减都由混合的b格式部分处理,就像在遗留解决方案中一样。
通过以这种方式处理距离m,通过丢弃(一个或多个)d声道,b格式声道在功能上与正常解码器向后兼容,从而导致假设距离为1或“远场”。但是,我们的解码器将能够利用这(一个或多个)信号来转进和转出近场。由于不需要外部元数据,因此信号可以与遗留的5.1音频编解码器兼容。与“n混合”解决方案一样,(一个或多个)附加声道是信号速率,并且为所有时频定义。这意味着只要与b格式声道保持同步,它就也与任何区间分组或频域平铺兼容。这两个兼容性因素使其成为特别可扩展的解决方案。编码d声道的一种方法是在每个频率处使用w声道的相对量值。如果d声道在特定频率下的量值与那个频率处的w声道的量值完全相同,那么那个频率处的有效距离为1或“远场”。如果d声道在特定频率处的量值为0,那么那个频率处的有效距离为0,这与收听者头部的中间对应。在另一个示例中,如果d声道在特定频率的量值是那个频率处的w声道量值的0.25,那么有效距离是0.25或“近场”,同样的构思可以被用于使用每个频率处的w声道的相对功率对d声道进行编码。
对d声道进行编码的另一种方法是执行与解码器使用的完全相同的方向分析(空间分析),以提取与每个频率相关联的(一个或多个)声源方向。如果在特定频率处仅检测到一个声源,那么编码与该声源相关联的距离。如果在特定频率处检测到多于一个声源,那么编码与这些声源相关联的距离的加权平均。
可替代地,可以通过在特定时间帧处执行每个单独声源的频率分析来编码距离声道。每个频率处的距离可以编码为或者与那个频率处的最主要声源相关联的距离,或者编码为与那个频率处的有效声源相关联的距离的加权平均值。上述技术可以扩展到附加的d声道,诸如扩展到总共n个声道。在解码器可以在每个频率处支持多个声源方向的情况下,可以包括附加的d声道,以支持在这多个方向上扩展距离。需要注意确保源方向和源距离保持与正确的编码/解码次序相关联。
伪接近性或“froximity”编码是用于添加“d”声道以修改“w”声道的替代编码系统,使得w中的信号与xyz中的信号的比率指示期望的距离。但是,这个系统不与标准b格式向后兼容,因为典型的解码器需要固定的声道比率以确保在解码时保持能量。这个系统将需要“信号形成”一节中的主动解码逻辑来补偿这些水平波动,并且编码器将需要方向分析来预补偿xyz信号。另外,当将多个相关源转向到相对侧时,该系统具有局限性。例如,对于xyz编码,左侧/右侧、前/后或顶/底的两个源将减少为0。照此,解码器将被迫为那个频带做出“零方向”假设并将两个源都渲染在中间。在这种情况下,分离的d声道可以允许两个源都被转向以具有“d”的距离。
为了最大化接近性渲染以指示接近性的能力,优选的编码将是随着源变得更近而增加w声道能量。这可以通过xyz声道中的免费(complimentary)减少来平衡。这种风格的接近性通过降低“方向性”同时增加整体归一化能量来编码“接近性”,从而产生更“存在”的源。这可以通过主动解码方法或动态深度增强来进一步增强。
图17是具有仅利用元数据深度的深度和头部跟踪的主动解码器的功能框图。可替代地,使用完整元数据是一个选项。在这个替代方案中,b格式信号仅通过可与其一起发送的任何元数据来增强。这在图17中示出。元数据至少定义了整个三维声信号的深度(诸如将混合标记为近或远),但理想情况下,它将在多个频带处进行采样,以防止一个源修改整个混合的距离。
在示例中,所需的元数据包括渲染混合的深度(或半径)和“焦点”,这是与上面的n混合解决方案相同的参数。优选地,这个元数据是动态的并且可以随内容而改变,并且是每频率或至少在分组值的临界频带中。
在示例中,可选参数可以包括湿/干混合,或者具有更多或更少的早期反射或“室内声音”。然后可以将其作为对早期反射/混响混合水平的控制而给予渲染器。应当注意的是,这可以使用近场或远场双耳房间脉冲响应(brir)来实现,其中brir也近似是干的。
空间信号的最佳传输
在上述方法中,我们描述了扩展三维声b格式的特定情况。对于本文档的其余部分,我们将重点关注在更广泛的上下文中对空间场景编码的扩展,但这有助于突出本主题的关键要素。
图18示出了用于虚拟现实应用的示例最佳传输场景。期望识别复杂声音场景的高效表示(其优化高级空间渲染器的性能),同时保持传输带宽相对低。在理想的解决方案中,可以用与标准纯音频编解码器保持兼容的最少数量的音频声道来完全表示复杂的声音场景(多个声源、床混合,或具有包括高度和深度信息的全3d定位的声场)。换句话说,理想的是不创建新的编解码器或依赖于元数据侧声道,而是在现有传输通路上携带最佳的流,现有的传输通路通常仅是音频。很清楚,“最佳”传输变得有些主观,这取决于诸如高度和深度渲染之类的高级特征的应用优先级。出于本描述的目的,我们将关注需要完整3d以及头部或位置跟踪的系统,诸如虚拟现实。图18中提供了一般化的场景,这是用于虚拟现实的示例最佳传输场景。
期望保持输出格式不可知并且支持对任何布局或渲染方法的解码。应用可以正在尝试编码任何数量的音频对象(带位置的单通道(monostem))、基本/床混合,或其它声场表示(诸如ambisonics)。使用可选的头部/位置跟踪允许恢复源以进行重新分布或者在渲染期间平滑地旋转/平移。而且,因为存在潜在的视频,所以必须以相对高的空间分辨率产生音频,以使其不会与声源的视觉表示分离。应当注意的是,本文描述的实施例不需要视频(如果不包括,那么不需要a/v多路复用和多路分解)。另外,多声道音频编解码器可以像无损pcm波数据一样简单,也可以像低位速率感知编码器一样高级,只要它以容器格式打包音频以供运输即可。
基于对象、声道和场景的表示
通过维持独立对象来实现最完整的音频表示(每个对象由一个或多个音频缓冲器和所需的元数据组合,以使用正确的方法和位置来渲染它们,以实现期望的结果)。这需要大量的音频信号,并且可能更成问题,因为它可能需要动态源管理。
可以将基于声道的解决方案视为将要被呈现的内容的空间采样。最终,声道表示必须与最终渲染扬声器布局或hrtf采样分辨率匹配。虽然通用的上/下混合技术可以允许适应不同的格式,但是从一种格式到另一种格式的每种过渡、对头部/位置跟踪的适应或其它过渡将导致“重新摇移”源。这会增加最终输出声道之间的相关性,并且在hrtf的情况下可以导致外部化减少。另一方面,声道解决方案与现有的混合体系架构非常兼容并且对添加的源是稳健的,其中在任何时间向床混合物添加附加的源不会影响已经在混合中的源的所发送位置。
通过使用音频声道来编码位置音频的描述,基于场景的表示更进一步。这可以包括诸如矩阵编码之类的声道兼容选项,其中最终格式可以作为立体声对被播放,或者“解码”成更接近原始声音场景的更加空间混合。可替代地,像ambisonics(b格式、uhj、hoa等)的解决方案可以用于直接“捕获”声场描述,作为可以或可以不直接播放但可以进行空间解码并以任何输出格式渲染的信号的集合。这种基于场景的方法可以显著减少声道计数,同时为有限数量的源提供类似的空间分辨率;但是,场景级别的多个源的交互基本上将格式精简到感知方向编码,其中各个源丢失。因此,在解码处理期间可以发生源泄漏或模糊,从而降低有效分辨率(可以以声道为代价使用高阶ambisonics或者用频域技术来改善)。
可以使用各种编码技术来实现改进的基于场景的表示。例如,主动解码通过对编码信号执行空间分析或对信号进行部分/被动解码,然后经由离散摇移直接将信号的该部分渲染到检测到的地点来减少基于场景的编码的泄漏。例如,dtsneuralsurround中的矩阵解码处理或dirac中的b格式处理。在一些情况下,可以检测和渲染多个方向,如高角度分辨率平面波扩展(harpex)的情况。
另一种技术可以包括频率编码/解码。大多数系统将从频率相关处理中显著获益。在时频分析和合成的开销成本下,可以在频域中执行空间分析,从而允许非重叠的源独立地转向到它们各自的方向。
附加的方法是使用解码的结果来通知编码。例如,当基于多声道的系统被精简为立体矩阵编码时。相对于与原始多声道渲染,矩阵编码在第一遍中进行,解码,并进行分析。基于检测到的错误,进行第二遍编码,其中校正将更好地将最终解码的输出与原始多声道内容对准。这种类型的反馈系统最适用于已经具有上述频率相关的主动解码的方法。
深度渲染和源平移
本文先前描述的距离渲染技术在双耳渲染中实现了深度/接近性的感觉。该技术使用距离摇移来在两个或更多参考距离上分布声源。例如,渲染远场和近场hrtf的加权平衡以实现目标深度。使用这种距离摇移器来创建不同深度处的子混合也可以对深度信息的编码/传输有用。从根本上说,子混合都表示场景编码的相同方向性,但子混合的组合通过它们的相对能量分布揭示深度信息。这种分布可以是:或者(1)深度的直接量化(或者均匀分布或者分组,以用于诸如“近”和“远”之类的相关性);或者(2)比某个参考距离更近或更远的相对转向,例如,一些信号被理解为比远场混合的其余部分更近。
即使在不发送距离信息的情况下,解码器也可以利用深度摇移来实现包括源的平移的3d头部跟踪。混合中表示的源被假设源自方向和参考距离。当收听者在空间中移动时,可以使用距离摇移器重新摇移源,以引入从收听者到源的绝对距离改变的感觉。如果不使用全3d双耳渲染器,那么可以通过扩展使用其它修改深度感知的方法,例如,如在共同拥有的美国专利no.9,332,373中所描述的,该专利的内容通过引用并入本文。重要的是,音频源的平移需要修改的深度渲染,如本文将描述的。
传输技术
图19示出了用于主动3d音频解码和渲染的通用体系架构。取决于编码器的可接受复杂性或其它要求,可以使用以下技术。假设下面讨论的所有解决方案都受益于如上所述的频率相关的主动解码。还可以看出,它们主要关注于编码深度信息的新方法,其中使用这个层次结构的动机是,除了音频对象之外,深度不是由任何经典音频格式直接编码的。在示例中,深度是需要被重新引入的缺失维度。图19是用于下面讨论的解决方案的、用于主动3d音频解码和渲染的通用体系架构的框图。为清楚起见,信号路径用单箭头示出,但应当理解的是,它们表示任何数量的声道或双耳/转听信号对。
如在图19中可以看出的,经由音频声道发送的音频信号和可选的数据或元数据被用在空间分析中,该空间分析确定渲染每个时频区间的期望方向和深度。经由信号形成重建音频源,其中信号形成可以被视为音频声道、被动矩阵或三维声解码的加权和。然后将“音频源”主动渲染到最终音频格式中的期望位置,包括经由头部或位置跟踪对收听者移动的任何调整,
虽然在时间频率分析/合成方框内示出了这个处理,但是应当理解的是,频率处理不需要基于fft,它可以是任何时频表示。此外,可以在时域中执行全部或部分关键方框(没有频率相关处理)。例如,这个系统可能被用于创建新的基于声道的音频格式,该格式稍后将由hrtf/brtr的集合在时域和/或频域处理的进一步混合中渲染。
所示的头部跟踪器被理解为应当为其调整3d音频的旋转和/或平移的任何指示。通常,调整将是偏航/俯仰/滚动、四元数或旋转矩阵,以及用于调整相对放置的收听者的位置。执行调整,使得音频维持与预期的声音场景或视觉分量的绝对对准。应当理解的是,虽然主动转向是应用的最可能的地方,但是这个信息也可以被用于通知诸如源信号形成之类的其它处理中的决策。提供旋转和/或平移指示的头部跟踪器可以包括头戴式虚拟现实或增强现实头戴式耳机,具有惯性或地点传感器的便携式电子设备,或来自另一个旋转和/或平移跟踪电子设备的输入。头部跟踪器旋转和/或平移也可以作为用户输入(诸如来自电子控制器的用户输入)提供。
提供三个级别的解决方案并在下面详细讨论。每个级别必须至少具有主要音频信号。这个信号可以是任何空间格式或场景编码,并且通常将是多声道音频混合、矩阵/相位编码的立体声对或三维声混合的某种组合。由于每个都基于传统表示,因此预期每个子混合表示用于特定距离或距离组合的左/右、前/后及理想地上/下(高度)。
不表示音频样本流的附加可选音频数据信号可以作为元数据提供或者被编码为音频信号。它们可以被用于通知空间分析或转向;但是,因为假设数据是对完全表示音频信号的主要音频混合的辅助,所以它们通常不需要形成音频信号以供最终渲染。如果元数据可用,那么预计解决方案也不会使用“音频数据”,但混合数据解决方案是可能的。类似地,假设最简单且最向后兼容的系统将仅依靠真正的音频信号。
深度-声道编码
深度-声道编码或“d”声道的概念是其中给定子混合的每个时频区间的主要深度/距离针对每个区间,通过量值和/或相位被编码成音频信号的概念。例如,相对于最大/参考距离的源距离由相对于odbfs的每引脚(pin)的量值编码,使得-infdb是没有距离的源,并且满标度是参考/最大距离处的源。假设超出参考距离或最大距离,考虑仅通过减少遗留混合格式中已经可能的距离的级别或其它混合级别指示来改变源。换句话说,最大/参考距离是通常在没有深度编码的情况下渲染源的传统距离,在上面被称为远场。
可替代地,“d”声道可以是转向信号,使得深度被编码为“d”声道与一个或多个其它主声道中的量值和/或相位的比率。例如,在ambisonics中可以将深度编码为“d”与全向“w”声道的比率。通过使其相对于其它信号而不是odbfs或某个其它绝对级别,编码对于音频编解码器的编码或诸如级别调整之类的其它音频处理可以更加稳健。
如果解码器意识到针对这个音频数据声道的编码假设,那么即使解码器时频分析或感知分组与在编码过程中使用的不同,它也能够恢复所需信息。这种系统的主要困难是必须为给定的子混合编码单个深度值。意味着如果必须表示多个重叠源,那么必须在分离的混合中发送它们,或者必须选择主导距离。虽然有可能将这个系统与多声道床混合一起使用,但更可能的是这种声道将被用于增强三维声或矩阵编码的场景,其中时频转向已经在解码器中进行了分析并且声道计数保持在最低限度。
基于ambisonic的编码
关于所提出的ambisonic解决方案的更详细描述,参见上文的“具有深度编码的ambisonics”一节。此类方法将导致用于发送b格式+深度的最小5声道混合w、x、y、z和d。还讨论了伪接近性或“froximity”方法,其中深度编码必须借助于w(全向声道)与x、y、z方向声道的能量比结合到现有的b格式中。这只允许四个声道的传输,它还有其它缺点,可能最好由其它4声道编码方案解决。
基于矩阵的编码
矩阵系统可以采用d声道将深度信息添加到已经发送的信息。在一个示例中,单个立体声对被增益-相位编码,以表示在每个子带处的源的方位角和仰角航向(heading)。因此,3个声道(matrixl、matrixr、d)将足以发送完整的3d信息,并且matrixl、matrixr提供向后兼容的立体声下混。
可替代地,高度信息可以作为用于高度声道的分离矩阵编码(matrixl、matrixr、heightmatrixl、heightmatrixr、d)发送。但是,在那种情况下,类似于“d”声道编码“高度”可以是有利的。这将提供(matrixl、matrixr、h、d),其中matrixl和matrixr表示向后兼容的立体声下混,而h和d是可选的仅用于位置转向的音频数据声道。
在特殊情况下,“h”声道在本质上可以与b格式混合的“z”或高度声道类似。使用正信号进行向上转向并使用负信号进行向下转向(“h”与矩阵声道之间的能量比的关系)将指示向上或向下转向多远。很像b格式混合中“z”与“w”声道的能量比。
基于深度的子混合
基于深度的子混合涉及在诸如远(典型的渲染距离)和近(接近性)之类的不同关键深度处创建两个或更多个混合。虽然可以通过深度零或“中间”声道和远(最大距离声道)实现完整描述,但是发送的深度越多,最终渲染器可以越准确/灵活。换句话说,子混合的数量充当每个单独源的深度的量化。确切地落在被量化的深度处的源以最高准确度被直接编码,因此让子混合与用于渲染器的相关深度对应也是有利的。例如,在双耳系统中,近场混合深度应当与近场hrtf的深度对应,并且远场应当与我们的远场hrtf对应。这种方法相对于深度编码的主要优点是混合是加性的,并且不需要其它源的高级或先前知识。从某种意义上说,它是“完整”3d混合的传输。
图20示出了针对三个深度的、基于深度的子混合的示例。如图20中所示,三个深度可以包括中间(意味着头部的中心)、近场(意味着在收听者头部的周边)和远场(意味着我们典型的远场混合距离)。可以使用任意数量的深度,但是图20(如图1a)与双耳系统对应,其中hrtf已经非常靠近头部(近场)以及在大于1m并且通常为2-3米的典型远场距离处被采样。当源“s”确切地是远场的深度时,它将仅包括在远场混合中。当声源超出远场时,它的水平将降低,并且可选地将变得更具混响或更少“直接”的声音。换句话说,远场混合确切地是它在标准3d遗留应用中被处理的方式。当源朝着近场过渡时,源在远场和近场混合的相同方向上被编码,直到它确切地处于近场的点,从此它将不再对远场混合作出贡献。在混合之间的这种交叉渐变期间,整体源增益可能增加并且渲染变得更直接/干燥以产生“接近性”感觉。如果允许源继续进入头部的中间(“m”),那么最终将在多个近场hrtf或一个代表性中间hrtf上渲染,使得收听者不会感知到方向,而是好像它是来自头里面。虽然有可能在编码侧进行内部摇移,但是发送中间信号允许最终渲染器在头部跟踪操作中更好地操纵源,以及基于最终渲染器的能力选择用于“被中间摇移的”源的最终渲染方法。
因为这种方法依赖于两个或更多个独立混合之间的交叉渐变,所以沿着深度方向存在源的更加分离。例如,具有相似时频内容的源s1和s2可以具有相同或不同的方向、不同的深度并且保持完全独立。在解码器侧,远场将被视为全都具有某个参考距离d1的距离的源的混合,并且近场将被视为全都具有某个参考距离d2的源的混合。但是,必须对最终渲染假设进行补偿。以d1=1(源水平为0db的参考最大距离)和d2=0.25(假设源水平为+12db的接近参考距离)为例。由于渲染器使用将对其在d2处渲染的源施加12db增益并且对其在d1处渲染的源施加0db增益的距离摇移器,因此应当针对目标距离增益补偿所发送的混合。
在示例中,如果混合器将源s1放置在d1和d2之间半途的距离d处(近50%和远50%),那么理想情况下将具有6db的源增益,其应当在远场中被编码为“s1远”6db并且在近场中被编码为“s1近”-6db(6db-12db)。当被解码和重新渲染时,系统将在+6db(或6db-12db+12db)处播放s1近,并且在+6db(6db+0db+0db)处播放s1远。
类似地,如果混合器将源s1放置在相同方向上的距离d=d1处,那么它将仅在远场中以0db的源增益进行编码。于是,如果在渲染期间收听者在s1的方向上移动使得d再次等于d1和d2之间的半途,那么渲染侧上的距离摇移器将再次应用6db源增益并在近和远hrtf之间重新分布s1。这导致与上面相同的最终渲染。应当理解的是,这仅仅是说明性的,并且可以在传输格式中容纳其它值,包括不使用距离增益的情况。
基于ambisonic的编码
在三维声场景的情况下,最小3d表示由4声道b格式(w、x、y、z)+中间声道组成。附加的深度将通常以每个四个声道的附加b格式混合呈现。完整的远-近-中编码将需要九个声道。但是,由于近场常常在没有高度的情况下被渲染,因此有可能将近场简化为仅是水平的。然后可以在八个声道(w、x、y、z远场,w、x、y近场,中间)中实现相对有效的配置。在这种情况下,摇移到近场的源将其高度投射到远场和/或中间声道的组合中。这可以随着源仰角在给定距离处增加而使用sin/cos淡入淡出(或类似的简单方法)来实现。
如果音频编解码器需要七个或更少的声道,发送(w、x、y、z远场,w、x、y近场)而不是(wxyz中间)的最小3d表示仍然可以是优选的。权衡是用于多个源的深度准确性与对头部的完全控制。如果源位置被限制为大于或等于近场是可以接受的,那么附加的方向声道将在最终渲染的空间分析期间改善源分离。
基于矩阵的编码
通过类似的扩展,可以使用多个矩阵或增益/相位编码的立体对。例如,matrixfarl、matrixfarr、matrixnearl、matrixnearr、middle、lfe的5.1传输可以为完整的3d声场提供所有需要的信息。如果矩阵对不能对高度进行完全编码(例如,如果我们希望它们与dtsneural向后兼容),那么可以使用附加的matrixfarheight对。可以添加使用高度转向声道的混合系统,类似于d声道编码中所讨论的。但是,对于7声道混合,预计上述三维声方法是优选的。
另一方面,如果可以从矩阵对中解码完整的方位角和仰角方向,那么针对这种方法的最小配置是3个声道(matrixl、matrixr、mid),这已经是所需传输带宽的显著节省,甚至在任何低位速率编码之前。
元数据/编解码器
上述方法(诸如“d”声道编码)可以由元数据辅助,作为确保在音频编解码器的另一侧上准确地恢复数据的更简单方式。但是,此类方法不再与遗留音频编解码器兼容。
混合解决方案
虽然上面单独讨论过了,但是很好理解的是,每个深度或子混合的最佳编码可以取决于应用要求而不同。如上所述,有可能使用矩阵编码与三维声转向的混合将高度信息添加到矩阵编码的信号。类似地,有可能对基于深度的子混合系统中的一个、任何或全部子混合使用d声道编码或元数据。
基于深度的子混合也有可能用作中间分段(staging)格式,然后,一旦混合完成,就可以使用“d”声道编码来进一步减少声道计数。基本上将多个深度混合编码为单个混合+深度。
事实上,这里的主要建议是我们从根本上使用所有三个。混合首先用距离摇移器分解成基于深度的子混合,由此每个子混合的深度是恒定的,从而允许隐含的深度声道不被发送。在这种系统中,深度编码被用于增加我们的深度控制,而子混合被用于维持比通过单向混合所实现的更好的源方向分离。然后可以基于诸如音频编解码器、最大可允许带宽和渲染要求之类的应用特定来选择最终折衷。还应当理解的是,这些选择对于传输格式中的每个子混合可以是不同的,并且最终解码布局可以仍然不同并且仅取决于渲染器能力以渲染特定声道。
已经参考本发明的示例性实施例详细描述了本公开,对于本领域技术人员来说清楚的是,在不脱离实施例的范围的情况下,可以在其中进行各种改变和修改。因此,本公开旨在覆盖本公开的修改和变化,只要它们落入所附权利要求及其等同物的范围内。
为了更好地说明本文公开的方法和装置,这里提供了实施例的非限制性列表。
示例1是一种近场双耳渲染方法,包括:接收音频对象,该音频对象包括声源和音频对象位置;基于音频对象位置和位置元数据确定径向权重的集合,该位置元数据指示收听者位置和收听者朝向;基于音频对象位置、收听者位置和收听者朝向来确定源方向;基于用于至少一个hrtf径向边界的源方向来确定头部相关传递函数(hrtf)权重的集合,至少一个hrtf径向边界包括近场hrtf音频边界半径和远场hrtf音频边界半径中的至少一个;基于径向权重的集合和hrtf权重的集合生成3d双耳音频对象输出,该3d双耳音频对象输出包括音频对象方向和音频对象距离;以及基于3d双耳音频对象输出转换(transduce)双耳音频输出信号。
在示例2中,示例1的主题可选地包括从头部跟踪器和用户输入中的至少一个接收位置元数据。
在示例3中,示例1-2中的任何一个或多个的主题可选地包括其中:确定hrtf权重的集合包括确定音频对象位置超出远场hrtf音频边界半径;以及确定hrtf权重的集合还基于水平(level)滚降和直接混响比中的至少一个。
在示例4中,示例1-3中的任何一个或多个的主题可选地包括其中hrtf径向边界包括hrtf音频边界重要半径,hrtf音频边界重要半径限定近场hrtf音频边界半径与远场hrtf音频边界半径之间的间隙半径。
在示例5中,示例4的主题可选地包括将音频对象半径与近场hrtf音频边界半径和远场hrtf音频边界半径进行比较,其中确定hrtf权重的集合包括基于音频对象半径比较来确定近场hrtf权重和远场hrtf权重的组合。
在示例6中,示例1-5中的任何一个或多个的主题可选地包括d双耳音频对象输出还基于所确定的itd并且基于所述至少一个hrtf径向边界。
在示例7中,示例6的主题可选地包括确定音频对象位置超出近场hrtf音频边界半径,其中确定itd包括基于所确定的源方向确定分数时间延迟。
在示例8中,示例6-7中的任何一个或多个的主题可选地包括确定音频对象位置在近场hrtf音频边界半径上或之内,其中确定itd包括基于所确定的源方向确定近场时间耳间延迟。
在示例9中,示例1-8中的任何一个或多个的主题可选地包括d双耳音频对象输出基于时频分析。
示例10是一种六自由度声源跟踪方法,包括:接收空间音频信号,该空间音频信号表示至少一个声源,该空间音频信号包括参考朝向;接收3-d运动输入,该3-d运动输入表示收听者相对于所述至少一个空间音频信号参考朝向的物理移动;基于空间音频信号生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;基于信号形成输出、空间分析输出和3-d运动输入生成主动转向输出,该主动转向输出表示由收听者相对于空间音频信号参考朝向的物理移动造成的所述至少一个声源的距离和更新后的表观方向;以及基于主动转向输出转换音频输出信号。
在示例11中,示例10的主题可选地包括其中收听者的物理移动包括旋转和平移中的至少一个。
在示例12中,示例11的主题可选地包括来自头部跟踪设备和用户输入设备中的至少一个的-d运动输入。
在示例13中,示例10-12中的任何一个或多个的主题可选地包括基于主动转向输出而生成多个量化声道,所述多个量化声道中的每一个与预定的量化深度对应。
在示例14中,示例13的主题可选地包括从所述多个量化声道生成适合于耳机再现的双耳音频信号。
在示例15中,示例14的主题可选地包括通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例16中,示例10-15中的任何一个或多个的主题可选地包括从所形成的音频信号和更新后的表观方向生成适合于耳机再现的双耳音频信号。
在示例17中,示例16的主题可选地包括通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例18中,示例10-17中的任何一个或多个的主题可选地包括其中运动输入包括在三个正交运动轴中的至少一个中的移动。
在示例19中,示例18的主题可选地包括其中运动输入包括围绕三个正交旋转轴中的至少一个的旋转。
在示例20中,示例10-19中的任何一个或多个的主题可选地包括其中运动输入包括头部跟踪器运动。
在示例21中,示例10-20中的任何一个或多个的主题可选地包括其中空间音频信号包括至少一个ambisonic声场。
在示例22中,示例21的主题可选地包括其中所述至少一个ambisonic声场包括一阶声场、高阶声场和混合声场中的至少一个。
在示例23中,示例21-22中的任何一个或多个的主题可选地包括其中:应用空间声场解码包括基于时频声场分析来分析所述至少一个ambisonic声场;并且其中所述至少一个声源的更新后的表观方向基于时频声场分析。
在示例24中,示例10-23中的任何一个或多个的主题可选地包括其中空间音频信号包括矩阵编码的信号。
在示例25中,示例24的主题可选地包括其中:应用空间矩阵解码基于时频矩阵分析;并且其中所述至少一个声源的更新后的表观方向基于时频矩阵分析。
在示例26中,示例25的主题可选地包括其中应用空间矩阵解码保留高度信息。
示例27是一种深度解码方法,包括:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;基于空间音频信号和声源深度生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;基于信号形成输出和空间分析输出生成主动转向输出,该主动转向输出表示所述至少一个声源的更新后的表观方向;以及基于主动转向输出转换音频输出信号。
在示例28中,示例27的主题可选地包括其中所述至少一个声源的更新后的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例29中,示例27-28中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例30中,示例29的主题可选地包括其中ambisonic声场编码的音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例31中,示例27-30中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例32中,示例31的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中生成空间分析输出包括:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中所述至少一个声源的净深度感知。
在示例33中,示例32的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例34中,示例32-33中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例35中,示例32-34中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例36中,示例35的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例37中,示例32-36中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例38中,示例37的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例39中,示例31-38中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例40中,示例39的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例41中,示例39-40中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例42中,示例40-41中的任何一个或多个的主题可选地包括对在相关联的参考音频深度处形成的音频信号进行解码,该解码包括:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例43中,示例39-42中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例44中,示例43的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例45中,示例39-44中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例46中,示例45的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例47中,示例31-46中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例48中,示例47的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例49中,示例47-48中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例50中,示例49的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例51中,示例47-50中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例52中,示例51的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例53中,示例27-52中的任何一个或多个的主题可选地包括使用频带分割和时频表示中的至少一个在一个或多个频率处独立地执行音频输出。
示例54是一种深度解码方法,包括:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;基于空间音频信号生成音频,音频输出表示所述至少一个声源的表观净深度和方向;以及基于主动转向输出转换音频输出信号。
在示例55中,示例54的主题可选地包括其中所述至少一个声源的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例56中,示例54-55中的任何一个或多个的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例57中,示例54-56中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例58中,示例57的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中生成信号形成输出包括:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中的至少一个声源的净深度感知。
在示例59中,示例58的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例60中,示例58-59中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例61中,示例58-60中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例62中,示例61的主题可选地包括其中空间音频信号包括一阶三维声音频信号,高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例63中,示例58-62中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例64中,示例63的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例65中,示例57-64中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例66中,示例65的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例67中,示例65-66中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例68中,示例66-67中的任何一个或多个的主题可选地包括对在相关联的参考音频深度处形成的音频信号进行解码,该解码包括:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例69中,示例65-68中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例70中,示例69的主题可选地包括其中空间音频信号包括一阶三维声音频信号,高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例71中,示例65-70中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例72中,示例71的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例73中,示例57-72中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例74中,示例73的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例75中,示例73-74中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例76中,示例75的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例77中,示例73-76中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例78中,示例77的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例79中,示例54-78中的任何一个或多个的主题可选地包括其中生成信号形成输出还基于时频转向分析。
示例80是一种近场双耳渲染系统,包括:处理器,被配置为;接收音频对象,该音频对象包括声源和音频对象位置;基于音频对象位置和位置元数据确定径向权重的集合,该位置元数据指示收听者位置和收听者朝向;基于音频对象位置、收听者位置和收听者朝向来确定源方向;基于用于至少一个hrtf径向边界的源方向来确定头部相关传递函数(hrtf)权重的集合,所述至少一个hrtf径向边界包括近场hrtf音频边界半径和远场hrtf音频边界半径中的至少一个;以及基于径向权重的集合和hrtf权重的集合生成3d双耳音频对象输出,该3d双耳音频对象输出包括音频对象方向和音频对象距离;以及换能器,基于3d双耳音频对象输出将双耳音频输出信号转换成可听的双耳输出。
在示例81中,示例80的主题可选地包括处理器,该处理器还被配置为从头部跟踪器和用户输入中的至少一个接收位置元数据。
在示例82中,示例80-81中的任何一个或多个的主题可选地包括其中:确定hrtf权重的集合包括确定音频对象位置超出远场hrtf音频边界半径;以及确定hrtf权重的集合还基于水平滚降和直接混响比中的至少一个。
在示例83中,示例80-82中的任何一个或多个的主题可选地包括其中hrtf径向边界包括hrtf音频边界重要半径,hrtf音频边界重要半径限定近场hrtf音频边界半径与远场hrtf音频边界半径之间的间隙半径。
在示例84中,示例83的主题可选地包括处理器,该处理器还被配置为将音频对象半径与近场hrtf音频边界半径和远场hrtf音频边界半径进行比较,其中确定hrtf权重的集合包括基于音频对象半径比较来确定近场hrtf权重和远场hrtf权重的组合。
在示例85中,示例80-84中的任何一个或多个的主题可选地包括d双耳音频对象输出还基于所确定的itd并且基于所述至少一个hrtf径向边界。
在示例86中,示例85的主题可选地包括处理器,该处理器还被配置为确定音频对象位置超出近场hrtf音频边界半径,其中确定itd包括基于所确定的源方向确定分数时间延迟。
在示例87中,示例85-86中的任何一个或多个的主题可选地包括处理器,该处理器还被配置为确定音频对象位置在近场hrtf音频边界半径上或之内,其中确定itd包括基于所确定的源方向确定近场时间耳间延迟。
在示例88中,示例80-87中的任何一个或多个的主题可选地包括d双耳音频对象输出基于时频分析。
示例89是一种六自由度声源跟踪系统,包括:处理器,被配置为:接收空间音频信号,该空间音频信号表示至少一个声源,该空间音频信号包括参考朝向;从运动输入设备接收3-d运动输入,该3-d运动输入表示收听者相对于所述至少一个空间音频信号参考朝向的物理移动;基于空间音频信号生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;以及基于信号形成输出、空间分析输出和3-d运动输入生成主动转向输出,该主动转向输出表示由收听者相对于空间音频信号参考朝向的物理移动造成的更新后的表观方向和所述至少一个声源的距离;以及换能器,基于主动转向输出将音频输出信号转换成可听的双耳输出。
在示例90中,示例89的主题可选地包括其中收听者的物理移动包括旋转和平移中的至少一个。
在示例91中,示例89-90中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例92中,示例91的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例93中,示例91-92中的任何一个或多个的主题可选地包括其中运动输入设备包括头部跟踪设备和用户输入设备中的至少一个。
在示例94中,示例89-93中的任何一个或多个的主题可选地包括处理器,该处理器还被配置为基于主动转向输出生成多个量化的声道,所述多个量化的声道中的每一个与预定的量化深度对应。
在示例95中,示例94的主题可选地包括其中换能器包括耳机,其中处理器还被配置为生成适合于从所述多个量化的声道进行耳机再现的双耳音频信号。
在示例96中,示例95的主题可选地包括其中换能器包括扬声器,其中处理器还被配置为通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例97中,示例89-96中的任何一个或多个的主题可选地包括其中换能器包括耳机,其中处理器还被配置为从形成的音频信号和更新后的表观方向生成适合于耳机再现的双耳音频信号。
在示例98中,示例97的主题可选地包括其中换能器包括扬声器,其中处理器还被配置为通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例99中,示例89-98中的任何一个或多个的主题可选地包括其中运动输入包括在三个正交运动轴中的至少一个中的移动。
在示例100中,示例99的主题可选地包括其中运动输入包括围绕三个正交旋转轴中的至少一个的旋转。
在示例101中,示例89-100中的任何一个或多个的主题可选地包括其中运动输入包括头部跟踪器运动。
在示例102中,示例89-101中的任何一个或多个的主题可选地包括其中空间音频信号包括至少一个ambisonic声场。
在示例103中,示例102的主题可选地包括其中所述至少一个ambisonic声场包括一阶声场、高阶声场和混合声场中的至少一个。
在示例104中,示例102-103中的任何一个或多个的主题可选地包括其中:应用空间声场解码包括基于时频声场分析来分析所述至少一个ambisonic声场;以及其中所述至少一个声源的更新后的表观方向基于时频声场分析。
在示例105中,示例89-104中的任何一个或多个的主题可选地包括其中空间音频信号包括矩阵编码的信号。
在示例106中,示例105的主题可选地包括其中:应用空间矩阵解码是基于时频矩阵分析;以及其中所述至少一个声源的更新后的表观方向是基于时频矩阵分析。
在示例107中,示例106的主题可选地包括其中应用空间矩阵解码保留高度信息。
示例108是一种深度解码系统,包括:处理器,被配置为:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;基于空间音频信号和声源深度生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;以及基于信号形成输出和空间分析输出生成主动转向输出,该主动转向输出表示所述至少一个声源的更新后的表观方向;以及换能器,基于主动转向输出将音频输出信号转换成可听的双耳输出。
在示例109中,示例108的主题可选地包括其中所述至少一个声源的更新后的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例110中,示例108-109中的任何一个或多个的主题可选地包括其中空间音频信号包括一阶三维声音频信号、更高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例111中,示例108-110中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例112中,示例111的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中生成空间分析输出包括:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中所述至少一个声源的净深度感知。
在示例113中,示例112的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例114中,示例112-113中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例115中,示例112-114中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例116中,示例115的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例117中,示例112-116中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例118中,示例117的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例119中,示例111-118中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例120中,示例119的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例121中,示例119-120中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例122中,示例120-121中的任何一个或多个的主题可选地包括处理器,该处理器还被配置为对在相关联的参考音频深度处形成的音频信号进行解码,该解码包括:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例123中,示例119-122中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例124中,示例123的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例125中,示例119-124中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例126中,示例125的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例127中,示例111-126中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例128中,示例127的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例129中,示例127-128中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例130中,示例129的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例131中,示例127-130中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例132中,示例131的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例133中,示例108-132中的任何一个或多个的主题可选地包括使用频带分割和时频表示中的至少一个在一个或多个频率处独立地执行音频输出。
示例134是一种深度解码系统,包括:处理器,被配置为:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;以及基于空间音频信号生成音频,音频输出表示所述至少一个声源的表观净深度和方向;以及换能器,基于主动转向输出将音频输出信号转换成可听的双耳输出。
在示例135中,示例134的主题可选地包括其中所述至少一个声源的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例136中,示例134-135中的任何一个或多个的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例137中,示例134-136中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例138中,示例137的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中生成信号形成输出包括:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中的至少一个声源的净深度感知。
在示例139中,示例138的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例140中,示例138-139中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例141中,示例138-140中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例142中,示例141的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例143中,示例138-142中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例144中,示例143的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息,
在示例145中,示例137-144中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例146中,示例145的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例147中,示例145-146中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例148中,示例146-147中的任何一个或多个的主题可选地包括处理器,该处理器还被配置为对在相关联的参考音频深度处形成的音频信号进行解码,该解码包括:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例149中,示例145-148中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例150中,示例149的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例151中,示例145-150中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例152中,示例151的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例153中,示例137-152中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例154中,示例153的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例155中,示例153-154中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例156中,示例155的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例157中,示例153-156中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例158中,示例157的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息,
在示例159中,示例134-158中的任何一个或多个的主题可选地包括其中生成信号形成输出还基于时频转向分析。
示例160是至少一个机器可读存储介质,包括多条指令,响应于利用计算机控制的近场双耳渲染设备的处理器电路系统被执行,使得该设备:接收音频对象,该音频对象包括声源和音频对象位置;基于音频对象位置和位置元数据确定径向权重的集合,该位置元数据指示收听者位置和收听者朝向;基于音频对象位置、收听者位置和收听者朝向来确定源方向;基于用于至少一个hrtf径向边界的源方向来确定头部相关传递函数(hrtf)权重的集合,所述至少一个hrtf径向边界包括近场hrtf音频边界半径和远场hrtf音频边界半径中的至少一个;基于径向权重的集合和hrtf权重的集合生成3d双耳音频对象输出,该3d双耳音频对象输出包括音频对象方向和音频对象距离;以及基于3d双耳音频对象输出转换双耳音频输出信号。
在示例161中,示例160的主题可选地包括指令,该指令还使得设备从头部跟踪器和用户输入中的至少一个接收位置元数据。
在示例162中,示例160-161中的任何一个或多个的主题可选地包括其中:确定hrtf权重的集合包括确定音频对象位置超出远场hrtf音频边界半径;以及确定hrtf权重的集合还基于水平滚降和直接混响比中的至少一个。
在示例163中,示例160-162中的任何一个或多个的主题可选地包括其中hrtf径向边界包括hrtf音频边界重要半径,hrtf音频边界重要半径限定近场hrtf音频边界半径与远场hrtf音频边界半径之间的间隙半径。
在示例164中,示例163的主题可选地包括指令,该指令还使得设备将音频对象半径与近场hrtf音频边界半径和远场hrtf音频边界半径进行比较,其中确定hrtf权重的集合包括基于音频对象半径比较来确定近场hrtf权重和远场hrtf权重的组合。
在示例165中,示例160-164中的任何一个或多个的主题可选地包括d双耳音频对象输出还基于所确定的itd并且基于所述至少一个hrtf径向边界。
在示例166中,示例165的主题可选地包括还使得设备确定音频对象位置超出近场hrtf音频边界半径,其中确定itd包括基于所确定的源方向确定分数时间延迟。
在示例167中,示例165-166中的任何一个或多个的主题可选地包括指令,该指令还使得设备确定音频对象位置在近场hrtf音频边界半径上或之内,其中确定itd包括基于所确定的源方向确定近场时间耳间延迟。
在示例168中,示例160-167中的任何一个或多个的主题可选地包括d双耳音频对象输出基于时频分析。
示例169是至少一个机器可读存储介质,包括多条指令,响应于利用计算机控制的六自由度声源跟踪设备的处理器电路系统被执行,使得该设备:接收空间音频信号,该空间音频信号表示至少一个声源,该空间音频信号包括参考朝向;接收3-d运动输入,该3-d运动输入表示收听者相对于所述至少一个空间音频信号参考朝向的物理移动;基于空间音频信号生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;基于信号形成输出、空间分析输出和3-d运动输入生成主动转向输出,该主动转向输出表示由收听者相对于空间音频信号参考朝向的物理移动造成的更新后的表观方向和所述至少一个声源的距离;以及基于主动转向输出转换音频输出信号。
在示例170中,示例169的主题可选地包括其中收听者的物理移动包括旋转和平移中的至少一个。
在示例171中,示例169-170中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例172中,示例171的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例173中,示例171-172中的任何一个或多个的主题可选地包括来自头部跟踪设备和用户输入设备中的至少一个的-d运动输入。
在示例174中,示例169-173中的任何一个或多个的主题可选地包括指令,该指令还使得设备基于主动转向输出生成多个量化的声道,所述多个量化的声道中的每一个与预定的量化深度对应。
在示例175中,示例174的主题可选地包括指令,该指令还使得设备生成适合于从所述多个量化的声道进行耳机再现的双耳音频信号。
在示例176中,示例175的主题可选地包括指令,该指令还使得设备通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例177中,示例169-176中的任何一个或多个的主题可选地包括指令,该指令还使得设备从形成的音频信号和更新后的表观方向生成适合于耳机再现的双耳音频信号。
在示例178中,示例177的主题可选地包括指令,该指令还使得设备通过应用串扰消除来生成适合于扬声器再现的转听音频信号。
在示例179中,示例169-178中的任何一个或多个的主题可选地包括其中运动输入包括在三个正交运动轴中的至少一个中的移动。
在示例180中,示例179的主题可选地包括其中运动输入包括围绕三个正交旋转轴中的至少一个的旋转。
在示例181中,示例169-180中的任何一个或多个的主题可选地包括其中运动输入包括头部跟踪器运动。
在示例182中,示例169-181中的任何一个或多个的主题可选地包括其中空间音频信号包括至少一个ambisonic声场。
在示例183中,示例182的主题可选地包括其中所述至少一个ambisonic声场包括一阶声场、高阶声场和混合声场中的至少一个。
在示例184中,示例182-183中的任何一个或多个的主题可选地包括其中:应用空间声场解码包括基于时频声场分析来分析所述至少一个ambisonic声场;以及其中所述至少一个声源的更新后的表观方向基于时频声场分析。
在示例185中,示例169-184中的任何一个或多个的主题可选地包括其中空间音频信号包括矩阵编码的信号。
在示例186中,示例185的主题可选地包括其中:应用空间矩阵解码是基于时频矩阵分析;以及其中所述至少一个声源的更新后的表观方向是基于时频矩阵分析。
在示例187中,示例186的主题可选地包括其中应用空间矩阵解码保留高度信息。
示例188是至少一个机器可读存储介质,包括多条指令,响应于利用计算机控制的深度解码设备的处理器电路系统被执行,使得该设备:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;基于空间音频信号和声源深度生成空间分析输出;基于空间音频信号和空间分析输出生成信号形成输出;基于信号形成输出和空间分析输出生成主动转向输出,该主动转向输出表示所述至少一个声源的更新后的表观方向;以及基于主动转向输出转换音频输出信号。
在示例189中,示例188的主题可选地包括其中所述至少一个声源的更新后的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例190中,示例188-189中的任何一个或多个的主题可选地包括其中空间音频信号包括一阶三维声音频信号、更高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例191中,示例188-190中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例192中,示例191的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中使得设备生成空间分析输出的指令包括使得设备执行以下操作的指令:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中所述至少一个声源的净深度感知。
在示例193中,示例192的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例194中,示例192-193中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例195中,示例192-194中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例196中,示例195的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例197中,示例192-196中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例198中,示例197的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例199中,示例191-198中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例200中,示例199的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例201中,示例199-200中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例202中,示例200-201中的任何一个或多个的主题可选地包括指令,该指令还使得设备对在相关联的参考音频深度处形成的音频信号进行解码,使得设备解码所形成的音频信号的指令包括使设备执行以下操作的指令:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例203中,示例199-202中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例204中,示例203的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例205中,示例199-204中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例206中,示例205的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例207中,示例191-206中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例208中,示例207的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例209中,示例207-208中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例210中,示例209的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例211中,示例207-210中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例212中,示例211的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例213中,示例188-212中的任何一个或多个的主题可选地包括使用频带分割和时频表示中的至少一个在一个或多个频率处独立地执行音频输出。
示例214是至少一个机器可读存储介质,包括多条指令,响应于利用计算机控制的深度解码设备的处理器电路系统被执行,使得该设备:接收空间音频信号,该空间音频信号表示声源深度处的至少一个声源;基于空间音频信号生成音频,音频输出表示所述至少一个声源的表观净深度和方向;以及基于主动转向输出转换音频输出信号。
在示例215中,示例214的主题可选地包括其中所述至少一个声源的表观方向基于收听者相对于所述至少一个声源的物理移动。
在示例216中,示例214-215中的任何一个或多个的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例217中,示例214-216中的任何一个或多个的主题可选地包括其中空间音频信号包括多个空间音频信号子集。
在示例218中,示例217的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的子集深度,并且其中使得设备生成信号形成输出的指令包括使得设备执行以下操作的指令:在每个相关联的子集深度处解码所述多个空间音频信号子集中的每一个,以生成多个解码的子集深度输出;以及组合所述多个解码的子集深度输出,以生成空间音频信号中的至少一个声源的净深度感知。
在示例219中,示例218的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括固定位置声道。
在示例220中,示例218-219中的任何一个或多个的主题可选地包括其中固定位置声道包括左耳声道、右耳声道和中间声道中的至少一个,中间声道提供位于左耳声道和右耳声道之间的声道的感知。
在示例221中,示例218-220中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例222中,示例221的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例223中,示例218-222中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例224中,示例223的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例225中,示例217-224中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括相关联的可变深度音频信号。
在示例226中,示例225的主题可选地包括其中每个相关联的可变深度音频信号包括相关联的参考音频深度和相关联的可变音频深度。
在示例227中,示例225-226中的任何一个或多个的主题可选地包括其中每个相关联的可变深度音频信号包括关于所述多个空间音频信号子集中的每一个的有效深度的时频信息。
在示例228中,示例226-227中的任何一个或多个的主题可选地包括指令,该指令还使得设备对在相关联的参考音频深度处形成的音频信号进行解码,使得设备解码所形成的音频信号的指令包括使设备执行以下操作的指令:以相关联的可变音频深度进行丢弃;以及用相关联的参考音频深度解码所述多个空间音频信号子集中的每一个。
在示例229中,示例225-228中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例230中,示例229的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例231中,示例225-230中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例232中,示例231的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例233中,示例217-232中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的每一个包括相关联的深度元数据信号,该深度元数据信号包括声源物理地点信息。
在示例234中,示例233的主题可选地包括其中:声源物理地点信息包括相对于参考位置和参考朝向的地点信息;以及声源物理地点信息包括物理地点深度和物理地点方向中的至少一个。
在示例235中,示例233-234中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括ambisonic声场编码的音频信号。
在示例236中,示例235的主题可选地包括其中空间音频信号包括一阶三维声音频信号、高阶三维声音频信号和混合三维声音频信号中的至少一个。
在示例237中,示例233-236中的任何一个或多个的主题可选地包括其中所述多个空间音频信号子集中的至少一个包括矩阵编码的音频信号。
在示例238中,示例237的主题可选地包括其中矩阵编码的音频信号包括保留的高度信息。
在示例239中,示例214-238中的任何一个或多个的主题可选地包括其中生成信号形成输出还基于时频转向分析。
以上详细描述包括对附图的参考,附图构成详细描述的一部分。附图通过图示的方式示出了具体实施例。这些实施例在本文中也称为“示例”。这些示例可以包括除了示出或描述的要素之外的要素。而且,主题可以包括或者关于特定示例(或其一个或多个方面)或者关于本文示出或描述的其它示例(或其一个或多个方面)示出或描述的那些要素的任意组合或置换。
在本文中,使用术语“一”或“一个”,如在专利文献中常见的,其包括一个或多于一个,独立于“至少一个”或“一个或多个”的任何其它实例或用法。在本文中,术语“或”用于指非排他性的或,使得“a或b”包括“a但不是b”、“b但不是a”和“a和b”,除非另有说明。在本文中,术语“包括”和“其中”用作相应术语“包含”和“在其中”的普通英语等同物。而且,在以下权利要求中,术语“包括”和“包含”是开放式的,即,权利要求中包括除了在该术语之后列出的要素之外的要素的系统、设备、物品、组合物、制剂或处理仍被视为属于那个权利要求的范围。而且,在所附权利要求中,术语“第一”、“第二”和“第三”等仅用作标记,并不旨在对其对象施加数字要求。
以上描述旨在是说明性而非限制性的。例如,上述示例(或其一个或多个方面)可以彼此组合使用。在审阅以上描述之后,可以诸如由本领域普通技术人员之一使用其它实施例。提供说明书摘要以允许读者快速确定技术公开的本质。它是在不会用于解释或限制权利要求的范围或含义的理解之下提交的。在以上详细描述中,各种特征可以组合在一起以简化本公开。这不应当被解释为意图未要求保护的公开特征对于任何权利要求是必不可少的。更确切地说,本主题可以在于少于特定公开的实施例的所有特征。因此,以下权利要求在此并入具体实施方式中,每项权利要求自身作为单独的实施例,并且预期这些实施例可以以各种组合或置换彼此组合。范围应当参考所附权利要求以及这些权利要求所赋予的等同物的完全范围来确定。
- 还没有人留言评论。精彩留言会获得点赞!