用于使用补偿值来对音频信号进行编码的装置和方法与流程
本发明涉及音频编码和解码,并且具体地涉及使用谱增强技术(例如,带宽扩展或谱带复制(sbr)或智能间隙填充(igf))来进行音频编码/解码。
背景技术:
音频信号的存储或发送通常受限于严格的比特率约束。过去,当仅非常低的比特率可用时,编码器被迫大幅减少发送的音频带宽。现在,现代音频编解码器能够通过使用带宽扩展(bwe)方法[1-2]对宽带信号进行编码。这些算法依赖于高频内容(hf)的参数表示,它是借助于转换到hf谱区域(“修补(patching)”)并且应用参数驱动的后处理从解码后的信号的波形编码低频部分(lf)中产生的。然而,例如,如果被复制到某个目标区域的补丁(patch)中的谱精细结构与原始内容的谱精细结构大不相同,则令人烦恼的伪像会使得解码后的音频信号的感知质量降低。
在bwe方案中,在给定的所谓交叉频率之上重建hf谱区域通常基于谱修补。通常,hf区域由多个相邻的补丁组成,并且这些补丁中的每一个补丁源自低于给定的交叉频率的lf谱的带通(bp)区域。现有技术的系统通过将相邻子带系数集合从源复制到目标区域来在滤波器组表示内执行修补。在下一步骤中,调整谱包络,使得它非常类似于在编码器中测量的并在比特流中作为辅助信息发送的原始hf信号的包络。
然而,通常存在谱精细结构失配,这会使得导致感知伪像。众所周知的失配与音调(tonality)相关。如果原始hf包括具有相当主要的能量内容的音调并且要被复制到该音调的谱位置的补丁具有噪声特性,则可以按比例放大该带通噪声,使得其作为令人烦恼的噪声突发变得可听见。
谱带复制(sbr)是众所周知的在当代音频编解码器[1]中采用的bwe。在sbr中,通过插入伪替代正弦曲线(artificialreplacementsinusoids)来解决音调失配的问题。然而,这需要将附加的辅助信息发送到解码器,从而扩大bwe数据的比特需求。此外,如果音调的插入针对后续的块可开/关交替转换,则插入的音调会导致随时间的不稳定性。
智能间隙填充(igf)表示现代编解码器(例如,mpeg-h3d音频或3gppevs编解码器)中的半参数编码技术。由于低比特率约束,igf可以用于填充由编码器中的量化处理引入的谱空洞。通常,如果有限的比特预算不允许用于透明编码,则谱空洞首先出现在信号的高频(hf)区域中,并且越来越多地影响用于最低比特率的整个上部谱范围。在解码器侧,使用从低频(lf)内容以外的以半参数方式产生的合成hf内容经由igf以及通过附加的参数辅助信息控制的后处理来替换这样的谱空洞。
由于igf基本上是基于通过从较低频率复制谱部分(所谓的片(tile))来填充高谱并且通过应用增益因子来调整能量,因此如果在原始信号中,用作为复制处理的源的频率范围在谱精细结构方面与其目的地不同,则其可以证明有问题。
可以产生强烈感知影响的这样一个情况是音调的差异。这种音调失配可以以两种不同的方式发生:将具有强音调的频率范围复制到在结构方面被假设为类噪声的谱区域,另一方式大致为以噪声替代原始信号中的音调分量。在igf中,前一种情况(由于大多数音频信号通常对更高频率变得更加类噪声而更常见)由谱白化的应用处理,其中参数被发送到解码器,解码器发信号通知需要多少白化(如果有的话)。对于后一种情况,可以通过使用核心编码器的全频带编码能力来校正音调,以通过波形编码来保持hf频带中的音调线。可以基于强音调来选择这些所谓的“幸存线(survivingline)”。波形编码在比特率方面要求很高,在低比特率情况下,很可能无法提供波形编码。此外,必须防止逐帧在编码和不编码将会造成令人烦恼的伪像的音调分量之间切换。
附加地,欧洲专利申请ep2830054a1中公开和描述了智能间隙填充技术。igf技术通过在核心解码器操作的相同谱域中执行带宽扩展,一方面解决与带宽扩展的分离相关的问题,另一方面解决与核心解码相关的问题。因此,提供全速率核心编码器/解码器,其对全音频信号范围进行编码和解码。这不要求对在编码器侧上的下采样器和在解码器侧上的上采样器的需要。相反,整个处理在全采样率或全带宽域中执行。为了获得高编码增益,分析音频信号以便找到必须以高分辨率编码的第一组第一谱部分,其中该第一组第一谱部分在一个实施例中可以包括:音频信号的音调部分。另一方面,构成第二组第二谱部分的音频信号中的非音调或噪声分量以低谱分辨率以参数方式编码。然后,编码后的音频信号仅要求以用高谱分辨率以波形保持方式编码的第一组第一谱部分,以及此外,使用源自第一组的频率“片”用低分辨率以参数方式编码的第二组第二谱部分。在解码器侧,作为全频带解码器的核心解码器以波形保持方式重建第一组第一谱部分,即,不存在任何附加频率再生的任何知识。然而,如此产生的谱具有许多谱间隙。这些间隙随后通过一方面使用应用参数数据的频率再生以及另一方面使用源谱范围(即,由全速率音频解码器重建的第一谱部分)来用本发明的智能间隙填充(igf)技术进行填充。
3gppts26.445v13.2.0(2016-06),thirdgenerationpartnershipproject;technicalspecificationgroupservicesandsystemaspect;codecforenhancedvoiceservices(evs);detailedalgorithmicdescription(release13)中也包括并公开了igf技术。特别地,关于解码器侧实现,参考该关于编码器侧的参考文献中的第5.3.3.2.11节“intelligentgapfilling”,附加参考第6节,特别是第6.2.2.3.8节“igfapply”和其它igf相关段落(例如,第6.2.2.2.9节“igfbitstreamreader”或第6.2.2.3.11节“igftemporalflattening”)。
ep2301027b1公开了一种用于产生带宽扩展输出数据的装置和方法。在浊音语音信号中,与原始计算的噪声基底相比,降低所计算的噪声基底产生感知上更高的质量。因此,在这种情况下,语音听起来不那么混响。在音频信号包括咝(si)音的情况下,噪声基底的伪增加(artificialincrease)可以掩盖与咝音相关的修补方法中的缺点。因此,该参考文献公开了提供减少针对诸如浊音语音之类的信号的噪声基底和增加针对包括例如咝信号在内的信号的噪声基底。为了区分不同的信号,实施例使用能量分布数据(例如,咝声参数),该能量分布数据测量能量是否主要位于较高频率处,或换句话说,音频信号的谱表示是否显示向更高频率的倾斜增加或减少。另外的实现还使用第一lpc系数(lpc等于线性预测编码)来产生咝声参数。
技术实现要素:
本发明的目的是提供一种用于音频编码或音频处理的改进的构思。
该目的通过根据权利要求1的用于对音频信号进行编码的装置、根据权利要求23的对音频信号进行编码的方法、根据权利要求24的用于处理音频信号的系统、根据权利要求25的用于处理音频信号的方法、或根据权利要求26的计算机程序来实现。
一种用于对音频信号进行编码的装置包括:核心编码器,用于对第一谱带中的第一音频数据进行核心编码;以及参数编码器,用于对与第一谱带不同的第二谱带中的第二音频数据进行参数编码。特别地,参数编码器包括分析器,用于分析第一谱带中的第一音频数据,以获得第一分析结果,并分析第二谱带中的第二音频数据,以获得第二分析结果。补偿器使用第一分析结果和第二分析结果来计算补偿值。此外,参数计算器然后使用由补偿器确定的补偿值根据第二谱带中的第二音频数据来计算参数。
因此,本发明基于以下发现:为了找出在解码器侧使用某一参数的重建是否解决了音频信号所需的某个特性,第一谱带(通常是源频带)被分析以获得第一分析结果。类似地,分析器附加地分析第二谱带(其通常是目标频带,并且在解码器侧使用第一谱带(即源频带)重建)以获得第二分析结果。因此,对于源频带以及目标频带,计算单独的分析结果。
然后,基于这两个分析结果,补偿器计算用于改变某个参数(将会在没有对修改值进行任何补偿的情况下获得)的补偿值。换句话说,本发明背离了针对第二谱带的参数根据原始音频信号来计算并被发送到解码器以使得使用所计算的参数来重建第二谱带的典型的过程,而是产生一方面根据目标频带、另一方面根据取决于第一分析结果和第二分析结果的补偿值计算得到的补偿参数。
可以通过首先计算非补偿参数来计算补偿参数,然后可以将该非补偿参数与补偿值进行组合以获得补偿后的参数,或者可以一次计算补偿后的参数,而不将未补偿参数计算为中间结果。然后,可以从编码器向解码器发送补偿后的参数,然后解码器使用补偿后的参数值来应用某种带宽增强技术(例如,谱带复制或智能间隙填充或任何其它过程)。因此,除了参数计算之外,通过执行源频带和目标频带中的信号分析,以及后续基于来自源频带的结果和来自目标频带的结果(即,分别来自第一谱带和第二谱带)计算补偿值,来灵活地克服对某个参数计算算法的强服从,而不管参数是否产生期望的谱带增强结果。
优选地,分析器和/或补偿器应用一种确定心理声学失配的心理声学模型。因此,在实施例中,补偿值的计算基于检测某些信号参数(例如,音调)的心理声学失配,并且应用补偿策略以通过修改诸如谱带增益因子之类的其它信号参数来最小化整体感知烦恼。因此,通过权衡不同类型的伪像,获得感知上良好平衡的结果。
与现有技术方法“尝试不惜任何代价固定音调”相反,实施例教导宁愿通过对谱中的检测到音调失配的有问题部分应用抑制来修补伪像,从而权衡了谱能量包络失配与音调失配。
在输入若干个信号参数时,包含感知烦恼模型在内的补偿策略可以决定用于获得最佳感知拟合而不仅仅是信号参数拟合的策略。
该策略包括加权潜在伪像的感知重要性,并选择参数组合以最小化整体损害。
该方法主要旨在应用于基于诸如mdct之类的变换的bwe。然而,本发明的教导是普遍适用的,例如,类似地,在基于正交镜像滤波器组(qmf)的系统中。
可以应用该技术的一种可能情景是在智能间隙填充(igf)的上下文中检测噪声频带并随后抑制噪声频带。
实施例通过检测其发生并通过衰减对应的缩放因子来减小其影响来处理可能的音调失配。这可以一方面导致偏离原始谱能量包络,另一方面导致hf噪声的减少,这有助于感知质量的整体提高。
因此,实施例通过新颖的参数补偿技术改善感知质量,新颖的参数补偿技术通常由感知烦恼模型操纵,特别是在例如源或第一谱带与目标或第二谱带之间的谱精细结构失配的情况下。
附图说明
随后,在附图的上下文下描述了优选实施例,附图中:
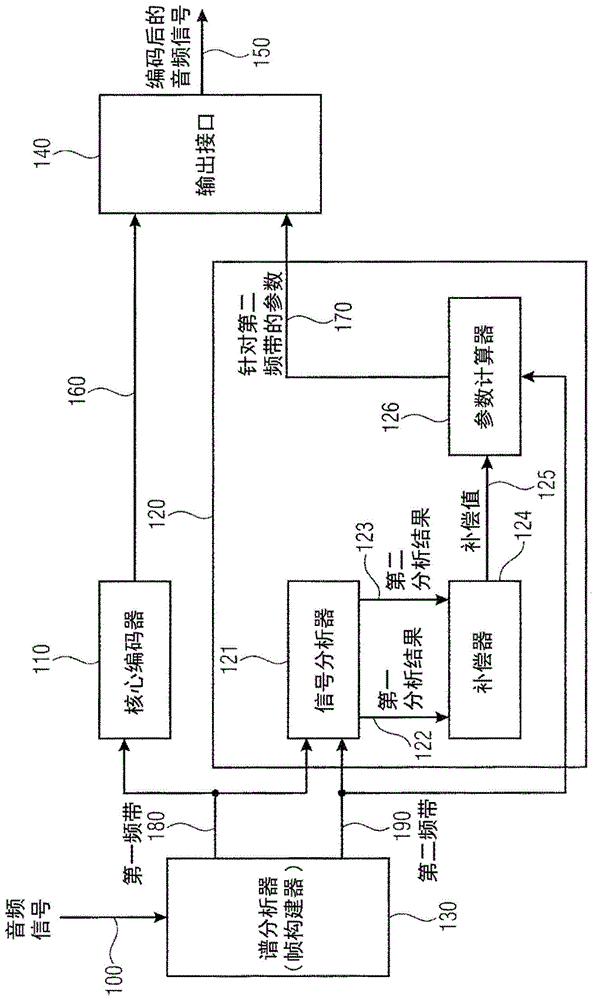
图1示出了根据实施例的用于对音频信号进行编码的装置的框图;
图2示出了用于以补偿检测器的焦点进行编码的装置的框图;
图3a示出了具有源范围和igf或带宽扩展范围的音频谱的示意表示以及源频带和目标频带之间的关联映射;
图3b示出了音频信号的谱,其中核心编码器应用igf技术并且在第二谱带中存在幸存线;
图3c示出了用于计算第一分析结果的第一谱带中的模拟第一音频数据的表示;
图4示出了补偿器的更详细的表示;
图5示出了参数计算器的更详细的表示;
图6示出了实施例中的用于说明补偿检测器功能的流程图;
图7示出了用于计算非补偿增益因子的参数计算器的功能;
图8a示出了具有核心解码器的编码器实现,该核心解码器用于根据编码后的和解码后的第一谱带来计算第一分析结果;
图8b示出了实施例中的编码器的框图,其中补丁模拟器用于产生从第二谱带位移的第一谱带宽线,以获得第一分析结果;
图9示出了音调失配在智能间隙填充实现中的影响;
图10示出了实施例中的参数编码器的实现;以及
图11a至图11c示出了使用补偿参数值对音频数据进行编码而获得的监听测试结果。
具体实施方式
图1示出了根据本发明实施例的用于对音频信号100进行编码的装置。该装置包括核心编码器110和参数编码器120。此外,核心编码器110和参数编码器120在其输入侧连接到谱分析器130,并且在其输出侧连接到输出接口140。输出接口140产生编码后的音频信号150。一方面,输出接口140接收编码后的核心信号160和至少针对第二谱带的参数、以及通常包括输入线170处的针对第二谱带的参数在内的全参数表示。此外,谱分析器130将音频信号100分离为第一谱带180和第二谱带190。特别地,参数计算器包括分析器121(被示为图1中的信号分析器),其用于分析第一谱带180中的第一音频数据以获得第一分析结果122,并分析第二谱带190中的第二音频数据以获得第二分析结果123。第一分析结果122和第二分析结果123都被提供给补偿器124,用于计算补偿值125。因此,补偿器124被配置为使用第一分析结果122和第二分析结果123来计算补偿值。然后,一方面,补偿值125和至少来自第二谱带190的第二音频数据(也可以使用来自第一谱带的第一谱数据)都被提供给参数计算器126,以使用补偿值125根据第二谱带中的第二音频数据计算参数170。
图1中的谱分析器130可以是例如直接的时间/频率转换器,以获得单独的谱带或mdct线。因此,在该实现中,谱分析器130实现修改的离散余弦变换(mdct)以获得谱数据。然后,进一步分析该谱数据,以便分离一方面用于核心编码器110的数据和另一方面用于参数编码器120的数据。用于核心编码器110的数据至少包括第一谱带。此外,当核心编码器要编码多于一个源频带时,核心数据可以附加地包括另外的源数据。
因此,在谱带复制技术的情况下,核心编码器可以接收低于交叉频率的整个带宽来作为要被核心编码的输入数据,而参数编码器然后接收高于该交叉频率的所有音频数据。
然而,在智能间隙填充框架的情况下,核心编码器110可以附加地接收高于igf开始频率的谱线,该谱线也由谱分析器130分析,使得谱分析器130附加地确定甚至高于igf开始频率的数据,其中该高于igf开始频率的数据附加地由核心编码器编码。为此,谱分析器130还可以被实现为“音调掩模(tonalmask)”,“音调掩模”例如也在如3gppts26.445v13.0.0(12)中公开的第5.3.3.2.11.5节“igftonalmask(igf音调掩模)”中被讨论。因此,为了确定哪个谱分量应该用核心编码器发送,通过谱分析器130来计算音调掩模。因此,所有重要的谱内容被识别,而非常适合用于通过igf进行参数编码的内容通过音调掩模被量化为0。然而,谱分析器130将非常适合于进行参数编码的谱内容转发到参数编码器120,并且该数据可以例如是通过音调掩模处理被设置为0的数据。
在实施例中,如图2所示,附加地,参数编码器120被配置为对第三谱带中的第三音频数据进行参数编码,以获得另外的针对该第三谱带的参数200。在这种情况下,分析器121被配置为分析第三谱带202中的第三音频数据,以除了获得第一分析结果122和第二分析结果123之外,还获得第三分析结果204。
此外,附加地,来自图1的参数编码器120包括补偿检测器210,用于至少使用第三分析结果204来检测是否要补偿第三谱带。该检测的结果由控制线212输出,控制线212指示针对第三谱带是否进行补偿的情况。参数计算器126被配置为当补偿检测器检测到将不对第三谱带进行补偿(由控制线212提供)时,不使用任何补偿值来计算另外的针对该第三谱带的参数200。然而,如果补偿检测器检测到要对第三谱带进行补偿,则参数计算器被配置为根据第三分析结果200,利用由补偿器124计算的附加补偿值来计算另外的针对第三谱带的参数。
在应用数量补偿的优选实施例中,分析器121被配置为计算第一数量值122作为第一分析结果以及计算第二数量值123作为第二分析结果。然后,补偿器124被配置为根据第一数量值和第二数量值计算数量补偿值125。最后,参数计算器被配置为使用数量补偿值来计算数量参数。
然而,当仅获得质量分析结果时,本发明也适用。在这种情况下,计算质量补偿(qualitativecompensation)值,然后质量补偿值控制参数计算器将某个非补偿参数降低或增加一定程度。因此,两个分析结果一起可以导致参数的一定增加或减少,这些增加或减少是固定的,因此不依赖于任何数量结果。然而,数量结果优于固定的增加/减少增量,尽管后者计算的计算量较小。
优选地,信号分析器121分析音频数据的第一特性以获得第一分析结果,并且附加地分析第二谱带中的第二音频数据的相同第一特性,以获得第二分析结果。与此相反,参数计算器被配置为通过评估与第一特性不同的第二特性,根据第二谱带中的第二音频数据来计算参数。
示例性地,图2示出了第一特性是某个频带(例如,第一频带、第二频带或任何其它频带)内的谱精细结构或能量分布的情况。与此相反,由参数计算器应用或由参数计算器确定的第二特性是谱包络测量、能量测量或功率测量、或通常是给出频带中的功率/能量的绝对或相对测量的幅度相关测量(例如,增益因子)。然而,也可以通过参数计算器来计算测量与增益因子特性不同的特性的其它参数。此外,分析器121可以应用和分析一方面用于单独源频带和另一方面用于目的地频带(即,第一谱带和第二谱带)的其它特性。
此外,分析器121被配置为:在不使用第二谱带190中的第二音频数据的情况下计算第一分析结果122,以及附加地,在不使用第一谱带180中的第一音频数据的情况下计算第二分析结果123,其中,在本实施例中,第一谱带和第二谱带彼此互不包含(exclusive)(即彼此不重叠)。
此外,谱分析器130还被配置为构建音频信号的帧或对输入的音频样本流进行加窗以获得音频样本的帧,其中相邻帧中的音频样本彼此重叠。例如,在50%重叠的情况下,较早帧的第二部分具有根据随后帧的前半部分中包括的相同原始音频样本导出的音频样本,其中帧内的音频样本是通过加窗根据原始音频样本而导出的。
在这种情况下,当音频信号包括帧的时间序列(例如,如附加地由图1中的附加地具有帧构建器功能的块130提供的)时,补偿器124被配置为使用针对先前帧的先前补偿帧值来计算针对当前帧的当前补偿值。这通常形成一种平滑操作。
如稍后所述,附加地或备选地,图2中所示的补偿检测器210可以包括来自图2中的其它特征的分别在221、223处示出的功率谱输入和瞬态输入。
特别地,补偿检测器210被配置为当图1的原始音频信号100的功率谱可用时,仅指示将由参数计算器126使用补偿。这个事实(即,功率谱是否可用)由某个数据元素或标志发信号通知。
此外,补偿检测器210被配置为当瞬态信息线223发信号通知针对当前帧不存在瞬态时,仅允许经由控制线212的补偿操作。因此,当线223发信号通知存在瞬态时,无论任何分析结果如何,都禁用整个补偿操作。当然,当针对第二谱带已经发信号通知补偿时,这适用于第三谱带。然而,当针对某一帧检测到诸如瞬态情况之类的情况时,这也适用于该帧中的第二谱带。然后,该情况可能发生,并且将发生在针对某个时间帧根本不发生任何参数补偿的情况。
图3a示出了幅度为a(f)或幅度平方为a2(f)的振幅的表示。特别地,示出了xover或igf开始频率。
此外,示出了重叠的源频带集合,其中源频带包括第一谱带180、另外的源频带302和甚至另外的源频带303。附加地,例如,高于igf或xover频率的目的地频带是第二谱带190、另外的目的地频带305、又一另外的目的地频带307和第三谱带202。
通常,igf或带宽扩展框架内的映射功能定义各个源频带180、302、303与各个目的带305、190、307、202之间的映射。该映射可以如3gppts26.445中的情况那样是固定的,或可以由某个igf编码器算法自适应地确定。在任何情况下,图3a中的靠下的表中示出了针对非重叠的目的地频带和重叠源频带的情况的目的地频带和源频带之间的映射,而不管该映射是固定的还是自适应地确定的并且实际上已经针对某一帧自适应地确定的,该谱在图3a的靠上部分中示出。
图4示出了补偿器124的更详细的实现。在该实现中,补偿器124除了接收第一分析结果122(其可以是谱平坦度测量、波峰因子、谱倾斜值或针对第一谱带的任何其它种类的参数数据)之外,还接收针对第二谱带的分析结果123。该分析结果可以再次是针对第二谱带的谱平坦度测量、针对第二谱带的波峰因子或倾斜值(即,限于第二谱带的谱倾斜值),而针对第一谱带的倾斜值或谱倾斜值也受限用于第一谱带。附加地,补偿器124接收与第二谱带有关的谱信息(例如,第二谱带的停止线)。因此,在图2的参数计算器126被配置为对第三谱带202中的第三音频数据进行参数编码的情况下,第三谱带包括比第二谱带更高的频率。这也在图3a的示例中示出,其中第三谱带处于比第二谱带更高的频率处,即,频带202具有比频带190更高的频率。在这种情况下,补偿器124被配置为在计算针对第三谱带的补偿值时使用加权值,其中该第三加权值与用于计算针对第二谱带的补偿值的加权值不同。因此,通常,补偿器124影响补偿值125的计算,使得对于相同的其它输入值,频率越高补偿值越小。
加权值例如可以是在基于第一分析结果和第二分析结果计算补偿值时应用的指数(例如,如稍后描述的指数α),或例如可以是乘法值或甚至要被加上或减去的值,以便与在将针对较低频率计算参数时的影响相比,获得针对较高频率的不同影响。
附加地,如图4所示,补偿器接收针对第二谱带的音调噪声比,以便根据第二谱带中的第二音频数据的音调噪声比来计算补偿值。因此,针对第一音调噪声比获得第一补偿值或针对第二音调噪声比获得第二补偿值,其中当第一音调噪声比大于第二音调噪声比时,第一补偿值大于第二补偿值。
如上所述,补偿器124被配置为通常通过应用心理声学模型来确定补偿值,其中心理声学模型被配置为使用第一分析结果和第二分析结果来评估第一音频数据和第二音频数据之间的心理声学失配,从而获得补偿值。评估心理声学失配的这种心理声学模型可以被实现为前馈计算(如稍后在下面的sfm计算的上下文下讨论的),或可以是反馈计算模块,其应用一种通过合成过程的分析。此外,心理声学模型还可以被实现为神经网络或类似结构,其由某些训练数据自动排出以决定在何种情况下补偿是必要的并且在何种情况下不是必要的。
随后,示出了图2中所示的补偿检测器210或通常包括在参数计算器120中的检测器的功能。
补偿检测器功能被配置为当第一分析结果和第二分析结果之间的差具有预定特性(例如,如图6中的600和602处所示的)时,检测补偿情况。块600被配置为计算第一分析结果和第二分析结果之间的差,然后块602确定差是否具有预定特性或预定值。如果确定不存在预定特性,则由块602确定不执行补偿(如603处所示)。然而,如果确定存在预定特性,则控制经由线604行进。此外,备选地或附加地,检测器被配置为确定第二分析结果是否具有某个预定值或某个预定特性。如果确定该特性不存在,则线605发信号通知不执行补偿。然而,如果确定存在预定值,则控制经由线606行进。在实施例中,线604和606可足以确定是否存在补偿。然而,在图6所示的实施例中,如后面所述,基于针对图1中的第二谱带190的第二音频数据的谱倾斜进行进一步确定。
在实施例中,分析器被配置为计算针对第一谱带的谱平坦度测量、波峰因子或谱平坦度测量与波峰因子的商作为第一分析结果,并且计算第二音频数据的谱平坦度测量或波峰因子或谱平坦度测量和波峰因子的商作为第二分析结果。
在这样的实施例中,参数计算器126还被配置为根据第二音频数据计算谱包络信息或增益因子。
此外,在这样的实施例中,补偿器124被配置为计算补偿值125,使得针对第一分析结果和第二分析结果之间的第一差,获得第一补偿值,并针对第一分析结果和第二分析结果之间的差,计算第二补偿值,其中当第一补偿值大于第二补偿值时第一差大于第二差。
在下文中,将通过说明是否要检测补偿情况的可选附加确定来继续图6的描述。
在块608中,根据第二音频数据计算谱倾斜。当确定该谱倾斜低于阈值时(如610中所示),则补偿情况被肯定地确认(如612处所示)。然而,当确定谱倾斜不低于预定阈值而是高于阈值时,则由线614发信号通知这种情况。在块616中,确定音调分量是否靠近第二谱带190的边界。当确定存在靠近边界的音调分量时(如由项目618所示),则补偿情况被再次肯定确认。然而,当确定不存在靠近边界的音调分量时,则取消任何补偿,即,如线620所示的切断。在任何实施例中,通过执行位移的sfm计算来进行块616中的确定,即确定音调分量是否靠近边界。当如由块608确定的斜率强烈下降时,则计算sfm的频率区域将下移对应缩放因子频带(sfb)或第二谱带的宽度的一半。对于强烈倾斜,计算sfm的频率区域向上位移第二谱带的宽度的一半。以这种方式,由于较低的sfm,仍然可以正确地检测应被抑制的音调分量,而对于较高的sfm值,将不施加抑制。
随后,更详细地讨论图5。特别地,参数计算器126可以包括计算器501,其用于根据针对第二谱带(即,目的地频带)的音频数据来计算非补偿参数,并且附加地,参数计算器126包括用于将非补偿参数502与补偿值125进行组合的组合器503。例如,当非补偿参数502是增益值并且补偿值105是数量补偿值时,该组合可以是乘法。然而,备选地,组合器503执行的组合也可以是使用补偿值作为指数的加权操作或补偿值用作加法或减法值的加性修改。
此外,应注意,图5中所示的计算非补偿值然后执行随后组合以获得组合值的实施例仅是实施例。在备选实施例中,补偿值可以已经被引入到针对补偿参数的计算中,使得不发生利用明确的非补偿参数而得到的任何中间结果。相反,仅执行这样的单个运算,在其中,当补偿值125将不被引入这样的计算中时,使用补偿值并且使用将产生非补偿参数的计算算法来计算补偿参数,以作为该“单个运算的结果”。
图7示出了要由计算器501应用的用于计算非补偿参数的过程。图7中的表示“igf缩放因子计算”大致与3gppts26.445v13.3.3(2015/12)的第5.3.3.2.11.4节相对应。当“复合(complex)”tcx功率谱p(其中评估谱线的实部和虚部的谱)可用时,图5中的用于计算非补偿参数的计算器501执行根据功率谱p计算针对第二谱带的幅度相关测量(如700处所示)。此外,如702所示,计算器501根据复合谱p计算针对第一谱带的幅度相关测量。附加地,计算器501根据第一谱带(即,源频带)的实部计算幅度相关测量(如704处所示),使得获得三个幅度相关测量ecplx,target、ecplx,source、ereal,source,并且这三个幅度相关测量被输入到另外的增益因子计算功能706中,以最终获得作为ereal,source和ecplx,source之间的商乘以ecplx,target的函数的增益因子。
备选地,当复合tcx功率谱不可用时,则仅根据实第二谱带计算幅度相关测量(如图7的底部处所示)。
此外,请注意,例如基于以下等式计算tcx功率谱p(例如,如第5.3.3.2.11.1.2子条款中所示):
p(sb)=r2(sb)+i2(sb),sb=0,1,2,...,n-1。
这里,n是实际tcx窗口长度,r是包含当前tcx谱的实值部分(cos变换后的)在内的向量,并且i是包含当前tcx谱的虚部(sin变换后的)在内的向量。特别地,术语“tcx”与3gpp术语相关,但是通常提到如图1中的由谱分析器130向核心编码器110或参数编码器120提供的第一谱带或第二谱带中的谱值。
图8a示出了优选实施例,其中信号分析器121还包括核心解码器800,其用于计算编码后的和再次解码后的第一谱带并自然地计算编码后/解码后的第一谱带中的音频数据。
然后,核心解码器800将编码后/解码后的第一谱带馈送到信号分析器821中包括的分析结果计算器801,以计算第一分析结果122。此外,信号分析器包括图1中的信号分析器121中包括的第二分析结果计算器802,用于计算所计算的第二分析结果123。因此,信号分析器121以这样的方式配置:使用编码后的和再次解码后的第一谱带来计算实际的第一分析结果122,同时根据原始的第二谱带来计算第二分析结果。因此,解码器侧的情况在编码器侧被更好地模拟,因为进入到分析结果计算器801内的输入已经具有针对在解码器处可用的第一谱带的解码后的第一音频数据中包括的所有量化误差。
图8b示出了信号分析器的另外的优选实现,作为对图8a过程的备选或附加于图8a的过程,该优选实现具有补丁模拟器804。具体地,补丁模拟器804确认(acknowledge)igf编码器的功能,即,在第二目的地频带内可以存在实际上由核心编码器编码的多个线或至少一个线。
特别地,图3b中示出了该情况。
类似于图3a,图3b中的靠上的部分示出了第一谱带180和第二谱带190。然而,除了在图3a中讨论的内容之外,第二谱带包括第二谱带内包括的特定线351、352,特定线351、352已经由谱分析器130确定为除了第一第一谱带180之外附加地由核心编码器110编码的线。
这种对高于igf开始频率310的某些线的特定编码反映核心编码器110是具有大于igf开始频率、高达fmax354的奈奎斯特频率的全频带编码器的情况。这与sbr技术相关的实现形成对比,交叉频率也是最大频率,因此也是核心编码器110的奈奎斯特频率。
测试模拟器804从核心解码器800接收第一谱带180或解码后的第一谱带,并且附加地从谱分析器130或核心编码器110接收信息,该信息实际上是核心编码器输出信号中包括的第二谱带中的线。这由谱分析器130经由线806发信号通知,或由核心编码器经由线808发信号通知。补丁模拟器804现在通过使用针对四个谱带的直接的第一音频数据并且通过将来自第二谱带的线351、352位移到第一谱带来将线351、352插入到第一谱带中,来模拟针对第一谱带的第一音频数据。因此,线351’和352’表示通过将图3b中的线351、352从第二谱带位移到第一谱带而获得的谱线。优选地,针对第一谱带以频带边界内的这些线的位置在两个频带中相同(即,对于第二谱带190和第一谱带180,线和频带边界之间的差是相同的)的方式来产生谱线351、352。
因此,补丁模拟器输出模拟数据808,如图3c所示,其具有直接的第一谱带数据,并且附加地具有从第二谱带位移到第一谱带的线。现在,分析结果计算器801使用特定数据808来计算第一分析结果102,而分析结果计算器802根据第二谱带中的原始第二音频数据(即,包括图3b中所示的线351、352在内的原始音频数据)来计算第二分析结果123。
具有补丁模拟器804的该过程具有以下优点:不必对附加线351、352设置某些条件,例如高音调或其它任何东西。相反,完全由谱分析器130或核心编码器110决定第二谱带中的某些线是否要由核心编码器编码。然而,对于通过使用这些线作为附加输入来计算第一分析结果122(如图8b所示),自动考虑该操作的结果。
随后,示出了智能间隙填充框架内的音调失配的影响。
为了检测噪声带伪像,必须确定源和目标缩放因子频带(sfb)之间的音调的差异。对于音调计算,可以使用谱平坦度测量(sfm)。如果发现音调失配(源频带比目标频带更嘈杂),则应该施加一定量的抑制。在图9中描绘了没有应用本发明的处理的情况。
将一些平滑施加于抑制因子以避免工具的突然开/关行为也是明智的。下面给出了在正确位置施加抑制的必要步骤的详细描述。(请注意,仅在tcx功率谱p是可用的并且帧是非瞬态的(标志istransient不活动)这两者都满足的情况下,施加抑制。)
音调失配检测:参数
在第一步骤中,必须识别音调失配可能造成噪声带伪像的那些sfb。为此,必须确定igf范围的每个sfb中的音调以及用于复制的对应频带。用于计算音调的一种合适的测量是谱平坦度测量(sfm),其基于谱的几何平均值除以其算术平均值并且范围在0和1之间。靠近0的值指示强音调,而接近1的值表示非常嘈杂的谱。该公式被给出为
其中p是tcx功率谱,b是开始线,e是当前sfb的停止线,而p被定义为
除了sfm之外,还计算波峰因子,波峰因子还通过将最大能量除以谱中所有频率窗(frequencybin)的平均能量来指示能量如何在谱内分布。将sfm除以波峰因子产生针对当前帧的sfb的音调测量。波峰因子通过下式计算
其中p是tcx功率谱,b是开始线,e是当前sfb的停止线,而emax被定义为
然而,使用先前帧的结果来实现平滑的音调估计也是明智的。因此,音调估计使用以下公式来完成:
其中,sfm表示实际谱平坦度计算的结果,而变量sfm包括除以波峰因子以及平滑。
现在计算源和目的地之间的音调的差异:
sfmdiff=sfmsrc-sfmdest
针对该差异的正值,满足比目标谱更嘈杂的某个谱用于复制的条件。这样的sfb成为用于抑制的可能候选项。
然而,较低的sfm值不一定指示强烈的音调,而是也可能是由于sfb中的能量急剧下降或倾斜。这尤其适用于在sfb中间某处存在频带限制的项目。这可以导致不想要的抑制,从而产生略微低通滤波信号的印象。
为了在这样的情况下避免抑制,通过用正sfmdiff来计算所有频带中的能量的谱倾斜来确定可能受影响的sfb,其中沿一个方向的强烈倾斜可以指示造成低sfm值的急剧下降。通过sfb中的所有谱窗将谱倾斜计算为线性回归,回归线的斜率由下式给出:
其中,x作为窗号,p指示tcx功率谱,b是开始线,并且e是当前sfb的停止线。
然而,靠近sfb边界的音调分量也可能导致陡峭的倾斜,但仍应受到抑制。为了分离这两种情况,应对具有陡峭倾斜的频带执行另一位移的sfm计算。
针对斜率值的阈值被定义为
其中,除以sfb宽度以归一化。
如果存在强烈的下降斜率slope<-threshtilt,计算sfm的频率区域将下移sfb宽度的一半;针对强烈倾斜斜率slope>threshtilt其上移。以这种方式,由于较低的sfm,仍然可以正确地检测应该被抑制的音调分量,而对于较高的sfm值,将不施加抑制。此处的阈值被定义为值0.04,其中仅在位移的sfm低于阈值时施加抑制。
感知烦恼模型
针对任何正sfmdiff施加不应施加抑制,而是仅在目标sfb确实是非常有音调性(tonal)的情况下才有意义。如果在特定sfb中原始信号与嘈杂的背景信号叠加,则对于甚至更嘈杂的频带的感知差异将是小的,并且由于通过抑制而造成的能量损失而带来的钝化可能超过益处。
为了确保在合理范围界线内施加抑制,仅在目标sfb确实非常有音调性的情况下才应使用抑制。因此,只有
sfmdiff>0
以及
5fmdest<0.1
两者均保持时,才应施加抑制。
应该考虑的另一问题是igf谱中的音调分量的背景。每当在原始音调分量周围几乎没有类噪声的背景时,由噪声频带伪像引起的感知降低可能是最明显的。在这种情况下,当将原始的与igf创建的hf谱进行比较时,引入的噪声频带将被视为全新的东西,因此非常突出。另一方面,如果已经存在相当大量的背景噪声,则附加噪声与背景混合,造成不怎么刺耳的感知差异。因此,施加的抑制量还应取决于受影响的sfb中的音调噪声比。
对于该音调噪声比的计算,sfb中的所有窗i的平方的tcx功率谱值p加起来,并且除以sfb的宽度(由开始线b和停止线e给出),以获得频带的平均能量。该平均值随后用于归一化频带中的所有能量。
然后,将归一化后的能量pnorm,k低于1的所有窗加起来,并被计数为噪声部分pnoise,而高于1+adap的阈值的每个窗(其中
抑制取决于源和目的地之间的sfm的差异以及目标sfb的sfm,其中较高的差异和较小的目标sfm都应造成较强的抑制。合理的是,对于更大的音调差异,应施加更强的抑制。此外,如果目标sfm较低(即,目标sfb更加音调),则抑制量也应该更快地增加。这意味着对于极端音调的sfb,将施加比sfm落在抑制范围内的sfb更强的抑制。
附加地,对于更高的频率,抑制也应该更加谨慎地施加,因为在最高频带中消耗能量容易导致频带限制的感知印象,而sfb的精细结构由于人类听觉系统的灵敏度朝向更高的频率降低而变得不那么重要。
音调失配补偿:抑制因子的计算
为了将所有这些考虑因素并入到单个抑制公式中,将目标和源sfm之比作为公式的基础。通过这种方式,sfm的较大绝对差和较小的目标sfm值这两者将导致更强的抑制,这使得它比仅仅采用差更合适。为了还增加对频率和音调噪声比的依赖性,对所述比应用调整参数。因此,抑制公式可以写成
其中,d是将与缩放因子相乘的抑制因子,α和β是被计算为下式的抑制调整参数:
其中,e是当前sfb的停止线,并且
其中,adap依赖于通过下式计算的sfb宽度:
参数α随频率减小,以便针对较高频率施加较小的抑制,而如果要被抑制的sfb的音调噪声比降至低于阈值,则β用于进一步降低抑制的强度。它低于该阈值的程度越大,抑制减少的越多。
由于抑制仅在某些约束内被激活,因此必须应用平滑以防止突然的开/关转换。为了实现这一点,若干种平滑机制是活动的。
紧接在瞬态之后,只有强制地逐渐施加到tcx的核心开关或无抑制的先前帧抑制,才能在高能瞬态之后避免极端的能量下降。此外,利用iir滤波器形式的遗忘因子也考虑先前帧的结果。
所有平滑技术包含在以下公式中:
其中,dprev是先前帧的抑制因子。如果在先前帧中抑制是活动的,则dprev被dcurr复写,但限于0.1的最小值。可变的平滑是附加的平滑因子,其在瞬态帧期间(标志是瞬态活动)或在核心开关之后(标志iscelptotcxactive)被设置为2,并且在先前帧抑制是不活动的情况下被设置为1。在每个帧中,利用抑制将变量减少1,但可以不降低至低于0。
在最后的步骤中,抑制因子d与缩放增益g相乘:
gdammped=g*d
图10示出了本发明的优选实现。
例如,由谱分析器130输出的音频信号可用作mdct谱或甚至是复合谱(如图10左侧的(c)所示)。
信号分析器121由图10中的音调检测器801和802实现,用于通过块802检测目标内容的音调,并且用于在项目801处检测(模拟的)源内容的音调。
然后,执行抑制因子计算124以获得补偿值,然后,补偿器503使用从项目501、700至706获得的数据进行操作。项目501和项目700至706反映来自目标内容的包络估计和来自模拟的源内容和随后的缩放因子计算(例如,如图7中的项目700至706所示)的包络估计。
因此,类似于在图5的上下文中讨论的内容,将非补偿缩放向量作为值502输入到块503中。此外,噪声模型1000在图10中被示出为单独的构建块,尽管其也可以直接包括在抑制因子计算器124内(如在图4的上下文中所讨论的)。
此外,附加地,图10中的参数igf编码器包括白化估计器,其被配置为计算白化水平(例如,如在条款5.3.3.2.11.6.4““codingofigfwhiteninglevels”中所讨论的)。特别地,计算igf白化水平,并且使用每片一个或两个比特来发送所计算的igf白化水平。该数据也被引入比特流复用器140中,以便最终获得完整的igf参数数据。
此外,附加地提供可以与关于要由核心编码器110编码的谱线的确定的块130相对应的块“稀疏化谱”,并且将其示出为图10中的单独块1020。该信息优选地由补偿器503使用,以便反映特定的igf情况。
此外,图80左侧的术语“模拟”和图10中的“包络估计”块指代图8a所示的情况,其中“模拟的源内容”是第一谱带中的编码后的并且再次解码后的音频数据。
备选地,“模拟的”源内容是由补丁模拟器804根据第一谱带(如线180所示)中的原始第一音频数据而获得的数据,或是如由核心解码器800获得的、带有从第二谱带位移到第一谱带的线的解码后的第一谱带。
随后,示出了构成3gppts26.445编解码器的修正版本的本发明的另外的实施例。以下提供了指定本发明处理的新添加的文本。在此,明确参考已经包含在3gppts26.445规范中的某些子条款。
5.3.3.2.11.1.9谱倾斜函数slope
令p∈pn是如根据子条款5.3.3.2.11.1.2计算的tcx功率谱,并且b是开始线,e是谱倾斜测量范围的停止线。
与igf一起应用的slope函数被定义为:
slope:pn×n×n→p,
其中,n是实际tcx窗口长度,并且x是窗号。
5.3.3.2.11.1.10.音调噪声比函数tnr
令p∈pn是如根据子条款5.3.3.2.11.1.2计算的tcx功率谱,并且b是开始线,e是音调噪声比测量范围的停止线。
与igf一起应用的tnr函数被定义为:
tnr:pn×n×n→p,
其中,n是实际tcx窗口长度,pnorm(sb)被定义为:
并且adap被定义为:
抑制:
对于igf抑制因子计算6静态阵列(prevtargetfir、prevsrcfir、在目标和源范围中用于sfm计算的prevtargetiir和prevsrciir,以及prevdamp和dampsmooth),需要全部大小nb以在帧上保持过滤器状态。附加地,需要静态标志wastransient以节省来自先前帧的输入标志istransient的信息。
r重置过滤器状态
向量prevtargetfir、prevsrcfir、prevtargetiir、prevsrciir、以及prevdamp和dampsmooth是igf模型中的大小nb的全部静态阵列,并且被初始化为以下:
对于
应在以下情况下完成该初始化
·编解码器开始运转
·任何比特率切换
·任何编解码器类型切换
·从celp转换到tcx,例如iscelptotcx=true
·如果当前帧具有瞬态性质,例如istransient=true
·如果tcx功率谱p不是可用的
抑制因子的计算
如果tcx功率谱p是可用的并且istransient为假,则计算
以及
其中,t(0),t(1),...,t(nb)应该已经与函数tf相映射(参见子条款5.3.3.2.11.1.1),m:n→n是将igf目标范围映射到igf源范围中的映射函数(如子条款5.3.3.2.11.1.8中所述),并且nb是缩放因子频带的数量(参见表94)。sfm是谱平坦度测量函数(如子条款5.3.3.2.11.1.3中所述),并且crest是波峰因子函数(如子条款5.3.3.2.11.1.4中所述)。
如果iscelptotcx为真,或wastransient为真,则设置
对于
计算:
以及
利用这些向量计算:
diffsfm(k):=ssrc(k)-starget(k),k=0,1,...,nb-1.
如果对于k=0,1,...,nb-1
diffsfm(k)≤0,
或
starget(k)>0.1,
设置
prevdamp(k):=-1
dampsmooth(k):=1
否则利用函数slope来计算谱倾斜(如子条款5.3.3.2.11.1.9中所述):
tilt(k):=slope(p,t(k),t(k+1)),k=0,1,...,nb-1.
如果对于k=0,1,...,nb-1
tilt(k)<-threshtilt
否则如果
tilt(k)>threshtilt且k<nb-1,
其中threshtilt被定义为
在位移的谱上计算sfm:
其中位移(shift)被定义为:
如果
-threshtilt≤tilt(k)≤threshtilt
设置
sshift(k):=0.
如果对于k=0,1,...,nb-1
sshift(k)>0.04
在频带k中,将当前帧的抑制因子dampcurr设置为0:
dampcurr(k):=0.
否则,将dampcurr(k)计算为如下:
其中alpha被定义为:
以及beta被定义为:
其中,tnr是如子条款5.3.3.2.11.1.10中所述的音调噪声比函数,并且adap被定义为:
如果对于k=0,1,...,nb-1
prevdamp(k)=-1,
设置
prevdamp(k):=max(currdamp(k),0.1).
计算大小nb的抑制因子d的向量:
最后,如果istransient为假且功率谱p是可用的,则更新过滤器对于
前面部分中的值/索引/参数的名称类似于在整个说明书中讨论的对应的参数/索引/值。随后,在图11a至图11c的上下文中讨论了来自监听测试的若干结果。
这些监听测试通过将利用启用抑制编码的项目与未编码的项目进行比较来显示抑制的好处。
图11a所示的第一结果是比特率为13.2kbps的a-b比较测试和使用单项的32khz的采样率。图11a中示出了结果,其显示了a-b测试抑制与13.2kbps下的无抑制。
图11b中所示的第二结果是24.4kbps下的mushra测试和使用单项的32khz的采样率。这里,没有抑制的两个版本与带抑制的新版本进行了比较。结果显示在图11b(绝对分数)和图11c(差异分数)中。
新颖编码后的音频信号可以存储在数字存储介质或非暂时性存储介质上,或可以在诸如无线传输介质或有线传输介质(例如,互联网)之类的传输介质上传输。
尽管已经在装置的上下文中描述了一些方面,但是将清楚的是,这些方面还表示对应方法的描述,其中,块或设备对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中描述的方面也表示对对应块或对应装置的项或特征的描述。
取决于某些实现要求,可以在硬件中或在软件中实现本发明的实施例。可以使用其上存储有电子可读控制信号的数字存储介质(例如,软盘、dvd、cd、rom、prom、eprom、eeprom或闪存)来执行该实现,该电子可读控制信号与可编程计算机系统协作(或能够与之协作)从而执行相应方法。
根据本发明的一些实施例包括具有电子可读控制信号的数据载体,该电子可读控制信号能够与可编程计算机系统协作从而执行本文所述的方法之一。
通常,本发明的实施例可以被实现为具有程序代码的计算机程序产品,程序代码可操作用于在计算机程序产品在计算机上运行时执行方法之一。程序代码可以例如存储在机器可读载体上。
其他实施例包括用于执行本文所述的方法之一的计算机程序,其中将所述计算机程序存储在机器可读的载体或非暂时性存储介质上。
换言之,本发明方法的实施例因此是具有程序代码的计算机程序,该程序代码用于在计算机程序在计算机上运行时执行本文所述的方法之一。
因此,本发明方法的另一实施例是其上记录有计算机程序的数据载体(或数字存储介质或计算机可读介质),该计算机程序用于执行本文所述的方法之一。
因此,本发明方法的另一实施例是表示计算机程序的数据流或信号序列,所述计算机程序用于执行本文所述的方法之一。数据流或信号序列可以例如被配置为经由数据通信连接(例如,经由互联网)传送。
另一实施例包括被配置为或适用于执行本文所述的方法之一的处理装置(例如,计算机或可编程逻辑器件)。
另一实施例包括其上安装有计算机程序的计算机,该计算机程序用于执行本文所述的方法之一。
在一些实施例中,可编程逻辑器件(例如,现场可编程门阵列)可以用于执行本文所述的方法的功能中的一些或全部。在一些实施例中,现场可编程门阵列可以与微处理器协作以执行本文所述的方法之一。通常,方法优选地由任意硬件装置来执行。
上述实施例对于本发明的原理仅是说明性的。应当理解的是:本文所述的布置和细节的修改和变形对于本领域其他技术人员将是显而易见的。因此,旨在仅由所附专利权利要求的范围来限制而不是由借助对本文实施例的描述和解释所给出的具体细节来限制。
- 还没有人留言评论。精彩留言会获得点赞!