一种基于深度学习的音频自动化标注方法与流程
本发明涉及一种音频标注方法,特别涉及一种基于深度学习的音频自动化标注方法。
背景技术:
音频的结构化表示是mir(musicinformationretrieval音乐信息检索)中的重要问题,它主要是从音频信号本身提取特征,实现对音频的检索。传统的依靠专家只是提取音色、旋律、节奏的方式不能够完整描绘音频细节,无法实现自动标注,准确率较低。
技术实现要素:
本发明的目的在于克服现有技术中所存在的上述不足,提供一种利用卷积神经网络训练音频深度学习网络,构建深度学习模型,并利用最大投票算法实现音频自动化标注方法。
为了实现上述发明目的,本发明提供了以下技术方案:
一种基于深度学习的音频自动化标注方法,包括以下实现步骤:
s1、输入原始音频文件,通过音频预处理,得到若干个原始语谱图片段;
s2、将所述原始语谱图片段输入卷积神经网络中进行训练,构建深度学习模型;
s3、输入待标注音频文件,通过音频预处理,得到若干个待标注语谱图片段;
s4、基于所述深度学习模型,将所述待标注语谱图片段进行音频标注。
作为本发明实施例的优选,所述原始音频文件为现有曲库音频文件。
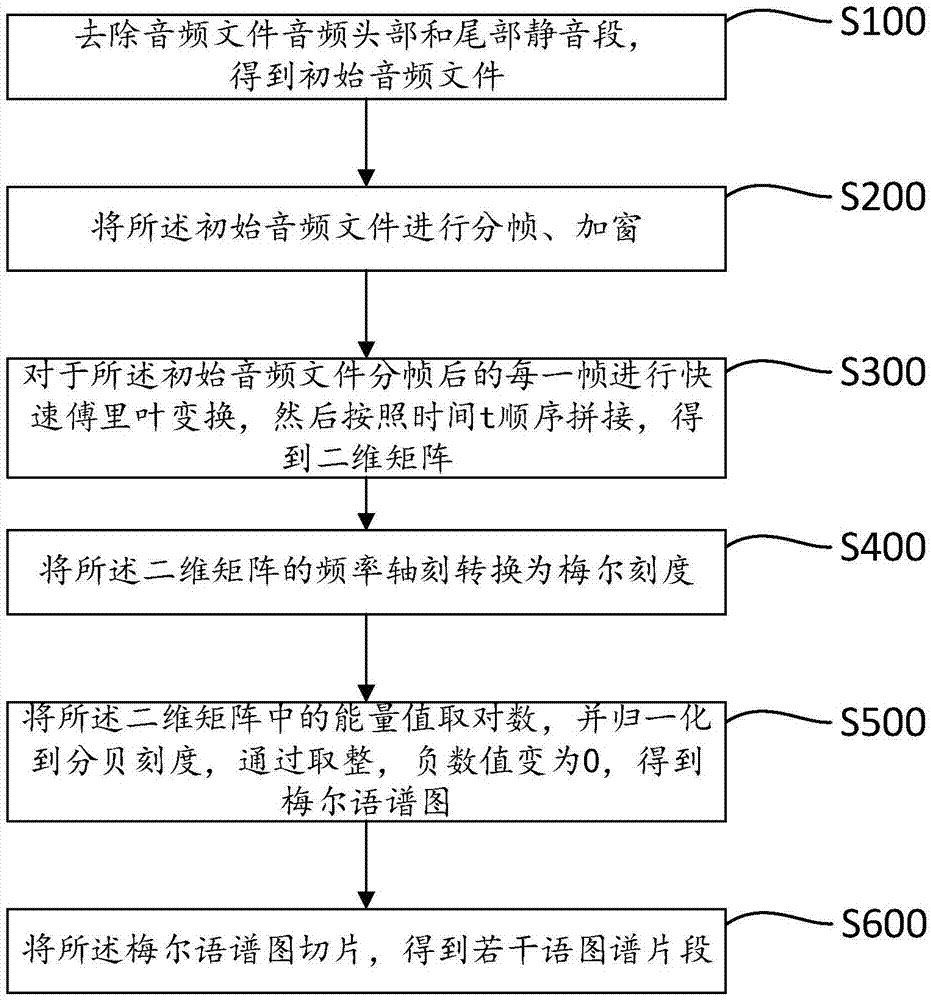
作为本发明实施例的优选,步骤s1和s3所述的音频预处理的实现步骤为:
s100、去除音频文件音频头部和尾部静音段,得到初始音频文件;
s200、将所述初始音频文件进行分帧、加窗;
s300、对于所述初始音频文件分帧后的每一帧进行快速傅里叶变换,然后按照时间t顺序拼接,得到二维矩阵;
s400、将所述二维矩阵的频率轴刻转换为梅尔刻度;
s500、将所述二维矩阵中的能量值取对数,并归一化到分贝刻度,通过取整,负数值变为0,得到梅尔语谱图;
s600、将所述梅尔语谱图切片,得到若干语图谱片段。
作为本发明实施例的优选,步骤s200中,所述初始音频文件进行分帧的过程为:对于采样率khz的所述初始音频文件,设置其帧大小为a,帧移为b,将所述初始音频文件分割为
作为本发明实施例的优选,步骤s600中将所述梅尔语谱图切片,得到若干语图谱片段的过程为:所述梅尔语谱图为长为t,宽为f的二维矩阵,设置切片大小为s,得到在t方向上将二维矩阵切成t/s个矩阵,并舍弃长度小于s的矩阵。
作为本发明实施例的优选,步骤s2的实现步骤为:
s21、将所述原始语谱图片段进行卷积、规则化和最大池化;
s22、在时域上求得全局时域最大值、全局时域均值,并输入全连接层,对卷积神经网络输出值进行汇总;
s23、将输出值输入dropout层,设置参数为0.5;
s24、将所述输出值输入输出层,利用损失函数,输出n个音频标签;所述损失函数为sigmoid交叉熵函数。
作为本发明实施例的优选,所述全连接层层数为2,每层全连接层的神经元个数为2048。
作为本发明实施例的优选,步骤s21的实现步骤为:
s211、将所述语谱图片段输入卷积层在时域方向卷积,得到矩阵a;
s212、将所述矩阵a输入normalization层进行规则化操作,将输出值的均值归一化至为0,方差为1;
s213、将所述输出值输入activation层,利用激活函数relu激活;
s214、通过maxpooling层对输出值进行最大池化操作。
作为本发明实施例的优选,步骤s21中所述卷积、规则化和最大池化的操作依次循环进行3次。
作为本发明实施例的优选,步骤s4的实现过程为:
s41、基于所述深度学习模型,对n个所述待标注语谱图片段进行标注,得到每个所述待标注语谱图片段对应的标注结果c={c1,c2,c3,…,ck};k为标注类别的数量;
s42、设置第i个所述待标注语谱图片段的标注结果为c[i],其最终标注结果为:
s43、选取最终标注结果数值最大的前n个作为音频标注输出。
与现有技术相比,本发明的有益效果:本发明基于深度学习技术,利用卷积神经网络训练音频深度学习网络,构建深度学习模型,并利用最大投票算法实现音频自动化标注,相比于传统的人工标注方式,提高了标注准确率,提升了音频标注效率。
附图说明:
图1为本发明的原理框图。
图2为本发明的音频预处理的流程框图。
图3为构建深度学习模型的流程框图。
图4为本发明梅尔语谱图片段进行卷积、规则化、最大池化的流程框图。
图5为本发明进行音频标注的流程框图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
参见图1,一种基于深度学习的音频自动化标注方法,包括以下实现步骤:
s1、输入原始音频文件,通过音频预处理,得到若干个原始语谱图片段;
s2、将所述原始语谱图片段输入卷积神经网络中进行训练,构建深度学习模型;
s3、输入待标注音频文件,通过音频预处理,得到若干个待标注语谱图片段;
s4、基于所述深度学习模型,将所述待标注语谱图片段进行音频标注。
优选地,步骤s1中所述原始音频文件为现有曲库中的音频文件。
参见图2,具体地,步骤s1和s3所述的音频预处理的实现步骤为:
s100、去除音频文件音频头部和尾部静音段,得到初始音频文件;
s200、将所述初始音频文件进行分帧、加窗;通过此操作,可以减少在非整数个周期上进行快速傅里叶变换(fft)产生的误差,优选加窗为汉明窗;
具体地,所述初始音频文件进行分帧的过程为:对于采样率khz的所述初始音频文件,设置其帧大小为a,帧移为b,将所述初始音频文件分割为
优选地,本发明实施例中,所述帧大小a=2048,帧移b=512。
s300、对于所述初始音频文件分帧后的每一帧进行快速傅里叶变换(fft),然后按照时间t顺序拼接,得到二维矩阵;所述二维矩阵中的每一个值表示时间为t及频率为f的对应的能量值;
s400、将所述二维矩阵的频率轴刻度转换为梅尔刻度(梅尔刻度是一种基于人耳对等距的音高(pitch)变化的感官判断而定的非线性频率刻度);具体地,将原始频率通过梅尔滤波器(即,三角重叠窗口)从而得到梅尔刻度,变换后的梅尔刻度频率轴取值为0-128,通过将频率轴刻度缩小,减少了计算量;
s500、将所述二维矩阵中的能量值取对数,并归一化到分贝(db)刻度,通过取整,负数值变为0,得到梅尔语谱图;
s600、将所述梅尔语谱图切片,得到若干语图谱片段;具体地,所述梅尔语谱图为长为t,宽为f的二维矩阵,设置切片大小为s,得到在t方向上将二维矩阵切成t/s个矩阵,并舍弃长度小于s的矩阵;
参见图3,具体地,步骤s2的实现步骤为:
s21、将所述原始语谱图片段进行卷积、规则化和最大池化操作;
优选地,所述卷积、规则化和最大池化依次循环进行3次,可以有效识别音频类别并且具有较小的计算量。
s22、在时域上求得全局时域最大值、全局时域均值,并输入全连接层,对卷积神经网络输出值进行汇总;
优选地,本发明实施例的所述全连接层层数为2,每层全连接层的神经元个数为2048。
s23、将输出值输入dropout层,设置参数为0.5;所述参数0.5表示每个神经元节点以50%的概率停止激活;
s24、将所述输出值输入输出层,利用损失函数,输出n个音频标签;所述损失函数为sigmoid交叉熵函数。
参见图4,具体地,步骤s21的实现步骤为:
s211、将所述语谱图片段输入卷积层在时域方向卷积,得到矩阵a;
梅尔语谱图时间长度为t,频率长度为f,深度为h。梅尔语谱图表示为x,其中x[i,j]表示语谱图中第i行、第j列的元素值,对于卷积filter的每个权重进行编号,w[m,n]表示第m行、第n列的权重,wb表示权重的偏置项,卷积结果featuremap表示为矩阵a,a[i,j]表示矩阵a中第i行、第j列的元素值,则有:
s212、将所述矩阵a输入normalization层进行规则化操作,将输出值的均值归一化至为0,方差为1,提高训练速度。
具体计算方式如下:
其中,xi表示第i个输出值,μ表示所有输出值的均值,σ2表示输出值的方差,
s213、将所述输出值输入activation层,利用激活函数relu(rectifiedlinearunit,线性整流函数)激活;具体的,对于每一个神经元节点输出值x,relu激活函数表示为f(x)=max(0,x);
s214、通过maxpooling层对输出值进行最大池化操作;最大化幅度为2,即在相邻输出xi-1,xi中取最大值,减少输入维度,提高训练速度。
参见图5,步骤s4的实现步骤为:
s41、基于所述深度学习模型,对n个所述待标注语谱图片段进行标注,得到每个所述待标注语谱图片段对应的标注结果c={c1,c2,c3,…,ck};k为标注类别的数量;
s42、设置第i个所述待标注语谱图片段的标注结果为c[i],其最终标注结果为:
s43、选取最终标注结果数值最大的前n个作为音频标注输出;本实施例优选,一般取值n=3。
具体地,例如以音乐风格的标注为例,将音乐分为爵士、蓝调、流行、电子乐、古典乐和摇滚:
假设将待标注音频文件通过音频预处理,得到10个待标注语谱图片段;
基于所述深度学习模型,得到其与6种音乐风格对应的标注值分别为5,0,2,2,0,1;
选取最大的前3个,也就是爵士、流行和电子乐。
综上所述,本发明基于深度学习技术,利用卷积神经网络训练音频深度学习网络,构建深度学习模型,并利用最大投票算法实现音频自动化标注,相比于传统的人工标注方式,提高了标注准确率,提升了音频标注效率。
本发明实施例中,步骤s4进行音频标注的算法优选为最大投票算法,其标注效果最好,应当理解,该步骤进行音频标注的过程还可以简化为直接音频标注,也可通过取均值进行音频标注,其算法的替换均应包含在本发明的保护范围之内。
应当理解,本发明的具体实施方式中所表述的步骤顺序,是不定的,其可以根据实际使用本发明方法时更改,例如步骤s3可以在步骤s1之前进行,并不以步骤的数字大小限定本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!