声控装置及相关的声音信号处理方法与流程
本发明是有关于声控装置,尤指一种设置在电视或是电视机顶盒中的声控装置。
背景技术:
在目前的声控装置中,为了随时可以辨识语音信息,声控装置中的处理器、存储器及相关电路必须一直处于使能状态而无法进入休眠模式,因而造成声控装置在不需要使用的情形下仍然有较高的功率消耗。
技术实现要素:
因此,本发明揭露了一种声控装置及相关的声音信号处理方法,其可以允许声控装置中有部分电路进入休眠状态以达到省电的效果,但声控装置仍可以由用户的一特定语音命令唤醒,并开始进行语音识别,以解决先前技术的问题。
在本发明的一个实施例中,揭露了一种声控装置,其包含有一接收电路、一声音处理电路、一存储器控制电路以及一主要处理电路。在该声控装置的操作中,该接收电路是用以依序接收一第一声音数据以及一第二声音数据,并储存在一第一存储器中;该声音处理电路是用以自该第一存储器中读取该第一声音数据,以及当该第一声音数据包含一特定命令时产生一控制信号;该存储器控制电路是用以根据该控制信号以自该第一存储器中读取该第二声音数据,并将所读取的该第二声音数据储存至一第二存储器中;以及该主要处理电路是用以根据该控制信号以自该第二存储器中读取该第二声音数据以进行语音识别。
在本发明的另一个实施例中,揭露了一种声音信号处理方法,其包含有以下步骤:依序接收一第一声音信号以及一第二声音数据,并储存在一第一存储器中;自该第一存储器中读取该第一声音数据,以及当该第一声音数据包含一特定命令时产生一控制信号;根据该控制信号以自该第一存储器中读取该第二声音数据,并将所读取的该第二声音数据储存至一第二存储器中;以及根据该控制信号以自该第二存储器中读取该第二声音数据以进行语音识别。
附图说明
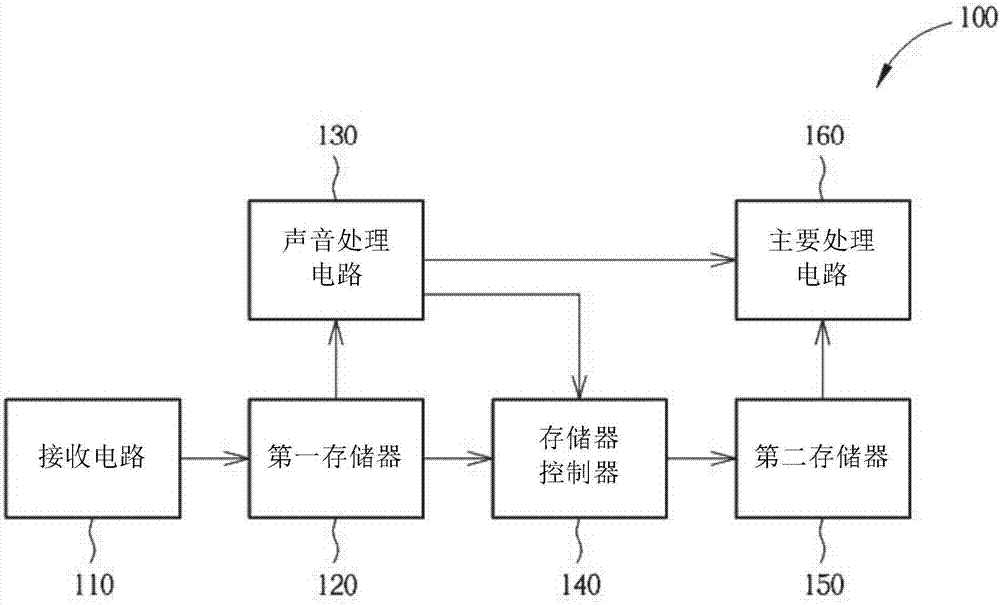
图1为根据本发明一实施例的声控装置的方块图。
图2为根据本发明一实施例的声控装置接收声音数据以及部份元件的时序图。
图3为根据本发明一实施例的一种声音信号处理方法的流程图。
图4为根据本发明另一实施例的声控装置的方块图。
符号说明
100、400声控装置
110、410接收电路
120、420第一存储器
130、430声音处理电路
140、440存储器控制器
150、450第二存储器
160、460主要处理电路
300~308步骤
470安全性控制电路
具体实施方式
图1为根据本发明一实施例的声控装置100的方块图。如图1所示,声控装置100包含了一接收电路110、一第一存储器120、一声音处理电路130、一存储器控制器140、一第二存储器150以及一主要处理电路160。在本实施例中,第一存储器110以及第二存储器150可以分别是静态随机存取存储器以及动态随机存取存储器,且除了第二存储器150以外的其他元件可以设置在一芯片中。此外,声控装置100是设置在一电视或是一电视机顶盒中,用以接收声音数据后进行语音识别,并据以控制电视的操作。
在一些实施例中,接收电路110可以包含一数字麦克风以及一转换电路,其中该数字麦克风是用以将所接收的声音信号转换为一脉冲密度调变(pulsedensitymodulation,pdm)信号,且该转换将该脉冲密度调变编码为一脉冲编码调变(pulse-codemodulation,pcm)信号;接收电路110也可以包含一模拟麦克风以及一转换电路,其中该模拟麦克风是用以接收声音信号,且该转换电路将该声音信号转换/编码为一脉冲编码调变信号,其中该转换电路可以是一模拟数字转换电路、一模拟数字转换至芯片间传输(adctoi2s)信号、或是一模拟数字转换至芯片间传输时分复用(adctoi2stdm)信号。
在本发明所揭露的声控装置100中,接收电路110、第一存储器120以及声音处理电路130是永远处于使能状态以随时侦测是否有需要进行语音识别的事件发生,而存储器控制器140、第二存储器150以及主要处理电路160是可以允许在空闲的时候进入休眠状态以节省电力消耗(例如,第二存储器150可以是一待机模式(suspendtoram(str))。具体来说,当声控装置于一段时间内没有接收到任何有效的声音信息之后,存储器控制器140、第二存储器150以及主要处理电路160便可以进入休眠状态(例如,断电或者仅供给很低的电力)以节省电力;而接收电路110、第一存储器120以及声音处理电路130接收到具有一特定命令的声音数据之后,会据以产生一唤醒信号来重新使能存储器控制器140、第二存储器150以及主要处理电路160,并产生一控制信号至存储器控制器140与主要处理电路160以对后续的声音数据进行语音识别。在本实施例中,该控制信号与该唤醒信号是为同一个信号,且在以下的说明中是以控制信号来作为说明。
详细来说,请同时参考图1、2,其中图2为根据本发明一实施例的声控装置100接收声音数据时部分元件的时序图。首先,假设在时间t0时存储器控制器140、第二存储器150以及主要处理电路160是处于休眠状态,此时用户想要询问目前的天气状况,因此说出了"哈啰晨星,天气如何?"的句子,其中"哈啰晨星"是作为用来启动声控装置100的语音识别功能的一特定命令。在用户说出"哈啰晨星"的过程中,接收电路110会依序将所接收到的声音数据储存至第一存储器120中,而声音处理电路130会根据一读取触发机制以自第一存储器120中读取声音数据,其中该读取触发机制可以是第一存储器120中的有效数据储存量已到达一邻界值、每隔一段特定时间、或是第一存储器120接收到完整的一笔封包数据后...等等。请注意,“有效数据”是指尚未被处理而不可被删除的声音数据,而非实际上仍储存于存储器120中未被删除的数据。在图2中,可以看到第一存储器120中有效数据储存量的变化。第一存储器120不断地被存写入声音数据(有效数据储存量增加),并不断地被声音处理电路130读出声音数据(有效数据储存量降低),因此有效数据储存量维持在一较低的水位。
接着,在时间t1的时候,假设用户所说出的句子"哈啰晨星"已经依序被储存至第一存储器120中,而声音处理电路130自第一存储器120中读取声音数据,并在时间t2判断出第一存储器120先前所储存的声音数据包含了用来启动声控装置100的语音识别功能的特定命令"哈啰晨星"。因此,声音处理电路130产生该控制信号以唤醒存储器控制器140以及主要处理电路160。
在时间点t2,存储器控制器140以及主要处理电路160开始进行正常操作前的一前置作业,而声音处理电路130则不再继续自第一存储器120中读取声音数据。然而第一存储器120仍持续被写入接收电路110所接收到的声音数据,例如本实施例中的"天气如何",因此,在图2中,可以看到时间点t2开始,第一存储器120中有效数据储存量持续增加至一较高的水位。
当存储器控制器140以及主要处理电路160完成前置作业之后(如图示的时间点t3),声音处理电路130便会控制存储器控制器140自第一存储器120中读取暂存的有效数据(例如,声音数据"天气如何"),并储存至使能状态的第二存储器150中,且主要处理电路160接着自第二存储器150读取前述的暂存的有效数据””以进行语音识别。由于前述的暂存的有效数据由存储器控制器140自第一存储器120转存至第二存储器150,因此,在图2中,可以看到时间点t2开始,第一存储器120中有效数据储存量回复到该较低的水位。
在图1、2所示的实施例中,由于声控装置100在闲置状态下只有接收电路110、第一存储器120以及声音处理电路130需要处于使能状态,再加上声音处理电路130在设计上只需要能够辨识具有特定命令"哈啰晨星"的声音数据即可,因此这些需要长期使能的元件仅需要很小的功率消耗。相对来说,具有较多耗电量的元件,例如主要处理电路160,则可以在闲置时进入休眠状态,故可以大幅降低耗电量。
在第一存储器120中暂存的有效数据被转存至第二存储器150之后,由于声控装置100中的语音识别已交由主要处理电路160进行,声音处理电路130不再继续自第一存储器120中读取声音数据,因此在第1、2图所示的实施例中,声音处理电路130可以被切换至休眠状态(例如,断电或者仅供给很低的电力)以进一步节省电力,直到主要处理电路160再次进入休眠才被重新唤醒。在另一实施例中,由于声音处理电路130为低功率消耗元件,因此亦可以选择持续使能状态。
此外,在图1、2所示的实施例中,在第一存储器120中暂存的有效数据被转存至第二存储器150之后,接收电路110是持续将声音数据存入第一存储器120,以及存储器控制器140是持续将声音数据自第一存储器120转存至第二存储器150。然而在另一实施例中,在第一存储器120中暂存的有效数据被转存至第二存储器150之后,接收电路110可切换为直接将后续接收的声音数据存入第二存储器150。
在一实施例中,上述的“哈啰晨星”可以视为一第一特定命令,而声音处理电路130另外可以根据声音数据是否包含一第二特定命令来决定主要处理电路160是要使用哪一个数据库来对后续的声音信号进行辨识。具体来说,若是声音信号中另外包含了“ok,google”,则声音处理电路130会产生控制信号至主要处理电路160以透过网络使用google数据库来进行语音识别;而若是声音信号中另外包含了“ok,alexa”,则声音处理电路130会产生控制信号至主要处理电路160以透过网络使用amazon数据库来进行语音识别。另外,主要处理电路160中使用不同数据库来进行语音识别的元件可以是相同的硬件或是不同的硬件。
图3为根据本发明一实施例的一种声音信号处理方法的流程图。同时参考以上图1、2的实施例所揭露的内容,图3的流程如下所述:
步骤300:流程开始。
步骤302:依序接收一第一声音信号以及一第二声音数据,并储存在一第一存储器中。
步骤304:自该第一存储器中读取该第一声音数据,以及当该第一声音数据包含一特定命令时产生一控制信号。
步骤306:根据该控制信号以自该第一存储器中读取该第二声音数据,并将所读取的该第二声音数据储存至一第二存储器中。
步骤308:根据该控制信号以自该第二存储器中读取该第二声音数据以进行语音识别。
图4为根据本发明另一实施例的声控装置400的方块图。如图4所示,声控装置400包含了一接收电路410、一第一存储器420、一声音处理电路430、一存储器控制器440、一第二存储器450、一主要处理电路460以及一安全性控制电路470。图4实施例与图1所示的声控装置100的差异在于多了安全性控制电路470,因此以下仅针对安全性控制电路470来作说明。
在声控装置400中,安全性控制电路470是用来设定第一存储器420及/或是第二存储器450的访问权限,以避免储存在第一存储器420或是第二存储器450中的声音数据被窃取。具体来说,安全性控制电路470可以将第一存储器420的一部分设定为一安全保护区域,而接收电路410是将所接收到的声音数据储存至该安全保护区域中,且该安全保护区域只允许声音处理电路430以及存储器控制器440进行读取操作;类似地,安全性控制电路470亦可以将第二存储器450的一部分设定为一安全保护区域,而存储器控制器440是将来自第一存储器420的声音数据储存至该安全保护区域中,且该安全保护区域只允许主要处理电路460进行读取操作。由于接收电路410是持续运作,因此会不断地将周遭的声音接收并存入第一存储器420及/或第二存储器450中,透过安全性控制电路470,则可以避免第一存储器420或是第二存储器450中的声音数据被窃取,免除了声控装置成为有心人士进行窃听的管道。
简要归纳本发明,在本发明的声控装置及相关的种声音信号处理方法中,由于声控装置在休眠状态下可以关闭具有较高功耗的元件,而仅有部分需要很小功耗的元件维持开启以判断声音数据中是否包含有特定命令,因此,声控装置可在节省功耗的情形下根据用户的一特定语音命令以唤醒声控装置并开始进行语音识别,兼顾了环保及用户的便利性。
以上所述仅为本发明的较佳实施例,凡依本发明权利要求书所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!