本地自适应语音训练方法和系统与流程
本发明涉及语音训练技术,特别是涉及一种识别精度高的本地自适应语音训练方法和系统。
背景技术:
随着网络与人工智能技术的发展,语音识别技术越来越多的进入智能家电控制中,但是语音识别技术是采用学习的算法,这样需要采集各种不同的样本,但是因为人的差异与各种方言、口语的存在,使得原有训练的模型,在实际应用中,识别率会出现很大的下降。
技术实现要素:
基于此,有必要提供一种识别精度高的本地自适应语音训练方法。
一种本地自适应语音训练方法,包括以下步骤:
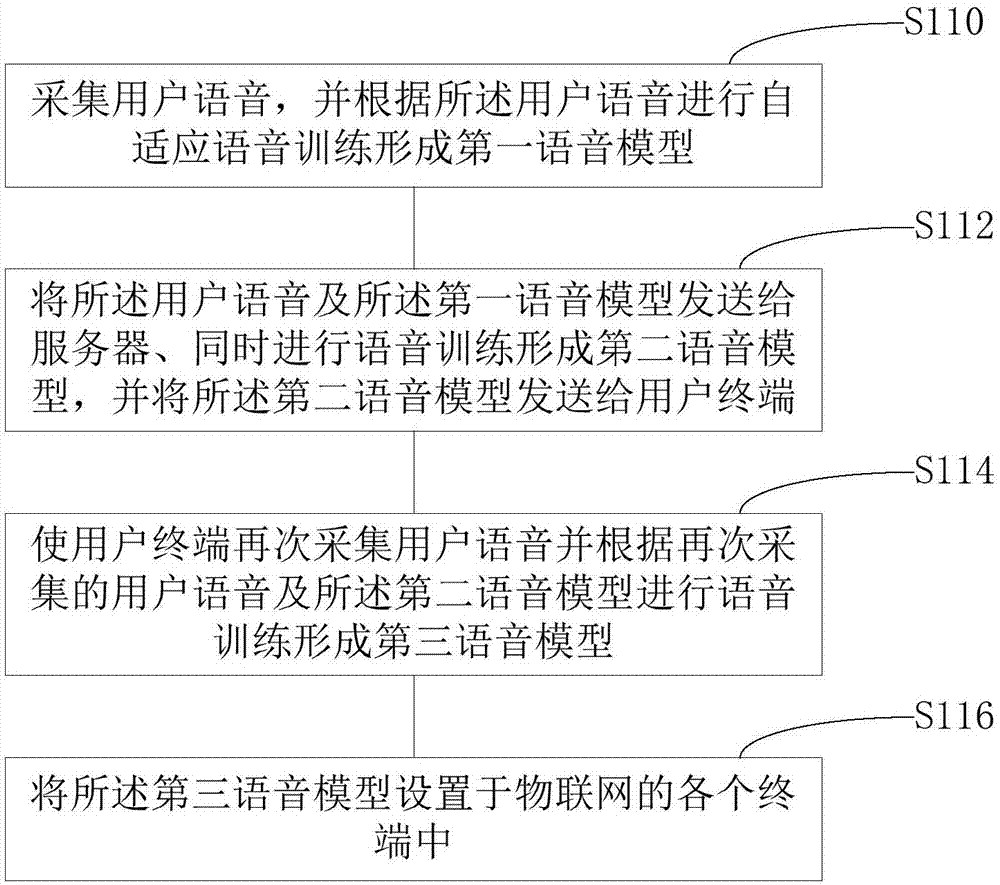
采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型;
将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端;
使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型;
将所述第三语音模型设置于物联网的各个终端中。
在其中一个实施例中,所述采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型的步骤包括:
将自适应语音模型发送给终端;
接收终端采集的用户语音,使所述自适应语音模型训练所述用户语音,并形成第一语音模型。
在其中一个实施例中,所述将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端的步骤包括:
将所述用户语音进行存储;
将所述用户语音及所述第一语音模型发送给服务器进行语音训练,并形成第二语音模型;
将所述第二语音模块发送给用户终端。
在其中一个实施例中,所述使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型的步骤包括:
使用户终端接收所述第二语音模型;
再次采集用户语音,采用再次采集的用户语音对所述第二语音模型进行语音校正形成所述第三语音模型。
在其中一个实施例中,所述将所述第三语音模型设置于物联网的各个终端中的步骤包括:
将第三语音模型设置于物联网的具有语音识别功能的家用电器中。
此外,还提供一种识别精度高的本地自适应语音训练系统。
一种本地自适应语音训练系统,包括采集模块、第一训练模块、通信模块、第三训练模块及设置模块;
所述采集模块用于采集用户语音,所述第一训练模块用于根据所述用户语音进行自适应语音训练形成第一语音模型;
所述通信模块用于将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端;
用户终端再次采集用户语音,所述第三训练模块用于根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型;
所述设置模块用于将所述第三语音模型设置于物联网的各个终端中。
在其中一个实施例中,还包括:
所述通信模块用于将自适应语音模型发送给终端;
所述采集模块用于接收终端采集的用户语音,使所述自适应语音模型训练所述用户语音,并形成第一语音模型。
在其中一个实施例中,还包括:存储模块;
所述存储模块用于将所述用户语音进行存储;
所述用户语音及所述第一语音模型发送给服务器进行语音训练,并形成第二语音模型;
所述通信模块用于将所述第二语音模块发送给用户终端。
在其中一个实施例中,还包括:
所述通信模块用于将所述第二语音模型发送给用户终端;
所述采集模块用于再次采集用户语音,所述第二语音模型用于对再次采集的用户语音进行语音训练形成所述第三语音模型。
在其中一个实施例中,还包括:所述设置模块用于将第三语音模型设置于物联网的具有语音识别功能的家用电器中。
上述的本地自适应语音训练方法和系统,通过采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型;将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端;使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型;将所述第三语音模型设置于物联网的各个终端中。因此,在经过自适应语音训练、服务器语音训练、再次通过用户进行语音训练等多次语音训练所形成的语音模型能够有效的识别用户语音,并作出准确的判断,提高用户语音识别精度。
附图说明
图1为本地自适应语音训练方法的流程图;
图2为本地自适应语音训练系统的模块图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
如图1所示,为本地自适应语音训练方法的流程图。
一种本地自适应语音训练方法,包括以下步骤:
步骤s110,采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型。
所述采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型的步骤包括:
将自适应语音模型发送给终端;
接收终端采集的用户语音,使所述自适应语音模型训练所述用户语音,并形成第一语音模型。
用于每个用户的语音并非完全标准的普通话,因此,在用户使用语音电子装置时,需要对语音电子装置中的语音模型进行训练。在初次训练用户语音时,可采用服务器中自适应语音训练模式,使当前采集的用户语音通过自适应语音训练的模式形成第一语音模型。
具体的,若该用户具有自身的语音习惯,那么将该语音习惯进行自适应语音调节,例如,该用户习惯说方言,那么可利用自适应语音对用户的方言进行训练,并形成第一语音模型。由于方言与普通话的发音具有差别,因此,自适应语音训练可进行方言匹配识别,使得能够采用自适应语音中的方言模型对用户的方言进行训练。
步骤s112,将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端。
所述将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端的步骤包括:
将所述用户语音进行存储;
将所述用户语音及所述第一语音模型发送给服务器进行语音训练,并形成第二语音模型;
将所述第二语音模块发送给用户终端。
在用户语音进行自适应语音训练完成后,需要进一步的进行精确语音训练。因此,将用户语音及第一语音模型发送到服务器,由服务器中的语音数据库对用户语音再次识别,并对第一语音模型进行训练,使得形成更为精确的第二语音模型。
具体的,若用户习惯说方言,那么需要将语音数据库中的方言提取出来,用于对用户的方言进行匹配识别,进而达到训练第一语音模型的目的,使得第二语音模型能够更为快速的识别用户方言。
步骤s114,使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型。
所述使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型的步骤包括:
使用户终端接收所述第二语音模型;
再次采集用户语音,采用再次采集的用户语音对所述第二语音模型进行语音校正形成所述第三语音模型。
具体的,用户终端在接收第二语音模块之后,再次采集用户语音,并进行人机交互对第二语音模型进行校正训练。
由于用户之间除了有说方言的区别,还有发音习惯问题,因此,在经过两次语音训练的模型中,可能还存在识别错误,因此,需要利用用户进行人机交互,进而实现第二语音模型的校正信息。
例如,用户终端在接收第二语音模型后,通过接收多个测试语音指令,并反馈给用户,若用户判断出用户终端识别有误,那么由用户反馈指令给用户终端,使得用户终端中的第二语音模型进行校正。因而,能够通过用户反馈实现第二语音模型的校正训练,进而形成精确度高、响应速度快的第三语音模型。
步骤s116,将所述第三语音模型设置于物联网的各个终端中。
所述将所述第三语音模型设置于物联网的各个终端中的步骤包括:
将第三语音模型设置于物联网的具有语音识别功能的家用电器中。
具体的,在物联网中,家用电器已包含有语音识别功能,进而通过语音指令对家用电器进行控制。因此,家用电器的语音识别功能是否精确、响应速度是否快已成为影响用户体验的重要因素。
在本实施例中,由于经历自适应语音训练、服务器语音训练及用户通过人机交互进行校正后的第三语音模型能够实现语音识别精确且响应速度快的效果,使得物联网中的语音控制更为精确及快速。
在本实施例中,用户终端连接物联网后,根据接收的控制指令对物联网内的各电器进行控制,并及时接收各电器反馈的状态;该控制指令可以为用户的语音指令。
在其他实施例中,通过用户终端将训练好的第三语音模型发送给各具有语音识别功能的家用电器,使得各家用电器能够直接的识别用户的语音指令,使得家用电器的语音控制更为快捷准确。
基于上述实施例,一般是使用一个预先采集的数据,然后使gmm-hmm算法来进行训练,但是实际应用中,采集的数据是很难做到全面覆盖,因为在中国存在很多方言、口语,还有年龄的差异。因为我们提出使用一种增强的方式,使用中,先使用预先采集的数据对模型进行训练,将模型下载到用户的设备中,然后用户可以通过手机,采集个人的数据,然后在基础模型之上,增加对用户个人采集数据的训练,这样训练的模型将可以大大提高用户识别率。同时可以在用户采集数据时,增加噪音,学习时加进应用场景噪音,也能使得模型可以更好的适配噪音环境。
gmm,高斯混合模型,也可以简写为mog。高斯模型就是用高斯概率密度函数精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数形成的模型。
隐马尔可夫模型(hiddenmarkovmodel,hmm)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别mfcc(mel-frequencycepstralcoefficients):梅尔频率倒谱系数。梅尔频率是基于人耳听觉特性提出来的,它与hz频率成非线性对应关系。梅尔频率倒谱系数(mfcc)则是利用它们之间的这种关系,计算得到的hz频谱特征。主要用于语音数据特征提取和降低运算维度。
如图2所示,为本地自适应语音训练系统的模块图。
一种本地自适应语音训练系统,包括采集模块201、第一训练模块202、通信模块203、第三训练模块204及设置模块205;
所述采集模块201用于采集用户语音,所述第一训练模块202用于根据所述用户语音进行自适应语音训练形成第一语音模型;
所述通信模块203用于将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端;
用户终端再次采集用户语音,所述第三训练模块204用于根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型;
所述设置模块205用于将所述第三语音模型设置于物联网的各个终端中。
本地自适应语音训练系统还包括:
所述通信模块203用于将自适应语音模型发送给终端;
所述采集模块201用于接收终端采集的用户语音,使所述自适应语音模型训练所述用户语音,并形成第一语音模型。
本地自适应语音训练系统还包括:存储模块;
所述存储模块用于将所述用户语音进行存储;
所述用户语音及所述第一语音模型发送给服务器进行语音训练,并形成第二语音模型;
所述通信模块203用于将所述第二语音模块发送给用户终端。
本地自适应语音训练系统还包括:
所述通信模块203用于将所述第二语音模型发送给用户终端;
所述采集模块201用于再次采集用户语音,所述第二语音模型用于对再次采集的用户语音进行语音训练形成所述第三语音模型。
本地自适应语音训练系统还包括:所述设置模块205用于将第三语音模型设置于物联网的具有语音识别功能的家用电器中。
上述的本地自适应语音训练方法和系统,通过采集用户语音,并根据所述用户语音进行自适应语音训练形成第一语音模型;将所述用户语音及所述第一语音模型发送给服务器、同时进行语音训练形成第二语音模型,并将所述第二语音模型发送给用户终端;使用户终端再次采集用户语音并根据再次采集的用户语音及所述第二语音模型进行语音训练形成第三语音模型;将所述第三语音模型设置于物联网的各个终端中。因此,在经过自适应语音训练、服务器语音训练、再次通过用户进行语音训练等多次语音训练所形成的语音模型能够有效的识别用户语音,并作出准确的判断,提高用户语音识别精度。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!