一种多人语音混合中目标说话人估计方法及系统与流程
本发明涉及计算机听觉与人工智能的技术领域,特别是一种多人语音混合中目标说话人估计方法及系统。
背景技术
随着计算机和人工智能技术的快速发展,智能语音技术在人机交互中被广泛应用。如微信、qq等移动通讯方式都有很多关于语音的应用。在理想的安静条件下,语音识别转文本、声纹识别解锁等智能语音技术给我们带来很多便利。但是在多人说话场景下,识别效果就大大降低,这就需要对多人混合语音进行目标说话人估计,以提高目标说话人语音的可懂度和识别率。针对背景噪声、其他人干扰语音的影响,最常见的方法就是进行语音分离或语音增强处理。然而语音的混合会导致语音分离得到的分离语音具有不确定性。具体来说,语音混合时我们不知道原始语音信号的状态,也不知道语音混合的方式,所以导致分离语音具有不确定性,也就是说,即使分离完也不知道分离的语音是属于谁的语音,不知道哪个语音是目标说话人的语音。所以,必须进行目标说话人估计,对多人混合语音分离得到的语音进行处理,概率估计出哪个分离语音是属于目标说话人的语音,以此提高语音的分离性能、可懂度、识别率。
公开号为cn103811020a的发明专利公开了一种智能语音处理方法,本发明通过建立对话人声音模型库,实现在多人语音环境下智能识别多个对话人的身份同时分离混合语音得到每个对话人的独立语音,根据用户需求为用户放大要听取的对话人的语音同时消除非用户要求的对话人的语音。该申请存在以下问题:(1)模型训练实时性不足。需要先建立模型库,再进行说话人身份识别,再分离混合语音;(2)建立对话人声音模型库,需要大量的语音样本数据。如果样本数据太多,训练会更耗时。如果样本数据太少,训练的模型适用性更差。(3)模型的泛化性、可移植性存在问题。因为不同背景噪声、不同的其他干扰人的语音训练的模型不同,不一定适用与其他的背景噪声环境和其他不同干扰说话人的声音环境。
技术实现要素:
为了解决上述的技术问题,本发明提出的一种多人语音混合中目标说话人估计方法及系统,不需要建立模型库,也不需要样本数据进行训练,实时性更好,不会因为背景环境或者干扰说话人改变而导致分离性能下降,适用性更强,解决了多人场景下混合语音分离的不确定性问题和语音识别率低的问题,对多人混合语音中目标说话人进行概率估计,以便增强目标说话人语音的可懂度和识别率。
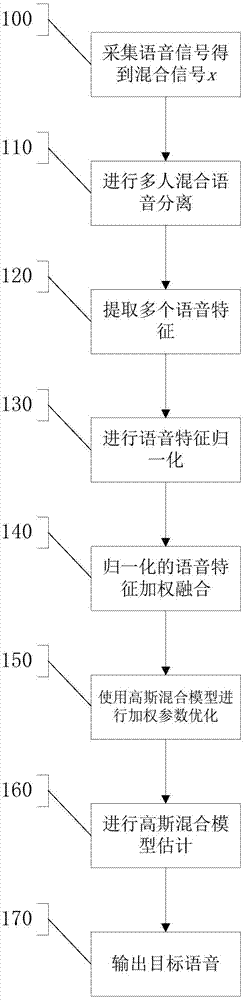
本发明的第一目的是提供一种多人语音混合中目标说话人估计方法,包括通用麦克风阵列采集语音信号得到混合信号x,还包括以下步骤:
步骤1:使用fastica算法进行多人混合语音分离,得到n个分离语音;
步骤2:提取多个语音特征;
步骤3:进行语音特征归一化;
步骤4:归一化的语音特征加权融合;
步骤5:使用高斯混合模型进行加权参数优化;
步骤6:使用期望最大化算法em算法进行高斯混合模型估计;
步骤7:输出目标语音。
优选的是,所述步骤1包括以下子步骤:
步骤11:对混合观测信号x中心化去均值,
其中,i=1…..n,n为实系数;
步骤12:白化处理去混合语音之间的相关性,
z=vx=ed-1/2etx
其中,v为白化矩阵,e为中心化数据的特征向量构成的正交矩阵,d为特征向量对应的特征值构成的对角矩阵,et为e转置矩阵;
步骤13;随机生成初始解混矩阵w0,‖w0‖2=1;
步骤14:更新解混矩阵w,
其中,g(y)=y×exp(-y2/2),g′为g的导数;
步骤15:如果所述解混矩阵w收敛,则wn+1解混矩阵,停止迭代,反之重新执行步骤14继续迭代;
步骤16:得到n个分离语音信号y=[y1,y2,……yn],
在上述任一方案中优选的是,判断所述解混矩阵w收敛的公式为|wn+1-wn|<ε,其中,ε为收敛门限。
在上述任一方案中优选的是,所述语音特征包括每次说话时长sn(l)、说话次数sn(n)、短时能量en和mfcc系数cn中至少一种。
在上述任一方案中优选的是,所述每次说话时长sn(l)是指检测语音段的起始时间和结束时间中间的时间长度。
在上述任一方案中优选的是,所述说话次数sn(n)是指每条语音中出现的分段语音的次数。
在上述任一方案中优选的是,所述短时能量en是指语音信号的第n个采样点的短时能量。
在上述任一方案中优选的是,所述mfcc系数cn是指每个人语音的梅尔频率倒谱系数特征点。
在上述任一方案中优选的是,所述步骤3为使用下面公式对所述语音特征进行归一化处理,
其中,
在上述任一方案中优选的是,所述步骤3还为将所述每次说话时长sn(l)、所述说话次数sn(n)、所述短时能量en和所述mfcc系数cn分别带入到上面公式中,得到归一化的说话时长
在上述任一方案中优选的是,所述步骤4为融合构成各个人的语音特征矢量xn,
其中,λ为对应的加权参数。
在上述任一方案中优选的是,所述步骤5包括在目标说话人语音特征空间中,使用概率密度函数p(x|λ)计算d维的特征参数矢量x的分布,
其中,n(x;μi;∑i)表示d维每个子分布的联合高斯概率分布函数,αi表示第i个子高斯分布在总体混合高斯分布中所占的权值,μi和∑i分别表示第i个高斯分量的均值和协方差,m表示描述总体分布所用的高斯函数的个数。
在上述任一方案中优选的是,所述联合高斯概率分布函数n(x;μi;∑i)的计算公式为
在上述任一方案中优选的是,所述步骤5为计算高斯混合模型λ的似然度,公式为
其中,λ=(m;x;μi;∑),为高斯混合模型,x=[x1,x2,……xn]表示分离的说话人的总体的语音特征矢量序列。
在上述任一方案中优选的是,所述em算法是一种递归最大似然估计算法,每次迭代都会不断优化参数λ的值,使得似然度l(x|λ)达到最大,所述em算法分e步和m步。
在上述任一方案中优选的是,所述e步是指利用模型初始参数,计算特征矢量xi在第k个高斯模型上的后验概率p(k|xi,λ),
其中,m为子高斯分布的个数,n(x;μk;∑k)为子高斯分布的联合概率密度函数。
在上述任一方案中优选的是,所述m步为对第k个混合度的所述后验概率p(k|xi,λ)分别计算混合度的权值ai、均值μi、协方差∑i的最大似然估计值。
在上述任一方案中优选的是,第k个所述混合度的权值αk的计算公式为
在上述任一方案中优选的是,第k个所述混合度的均值μk的计算公式为
在上述任一方案中优选的是,第k个所述混合度的协方差αk的计算公式为
在上述任一方案中优选的是,所述步骤7为通过高斯混合模型对语音特征矢量序列x=[x1,x2,……xn]进行概率估计,得到对应的特征矢量xi的概率αi,概率值大的是目标说话人的语音特征。
本发明的第二目的是提供一种多人语音混合中目标说话人估计系统,包括用于进行多人混合语音分离的语音分离模块,还包括以下模块:
多语音特征融合模块:提取多个语音特征,特征归一化之后,进行加权参数融合,得到语音特征序列;
融合参数优化模块:用高斯混合模型对融合参数进行优化,通过期望最大化算法em算法,估计出概率值最大的语音特征序列。
优选的是,所述混合语音分离方法包括以下步骤:
步骤11:对混合观测信号x中心化去均值,
其中,i=1…..n,n为实系数;
步骤12:白化处理去混合语音之间的相关性,
z=vx=ed-1/2etx
其中,v为白化矩阵,e为中心化数据的特征向量构成的正交矩阵,d为特征向量对应的特征值构成的对角矩阵,et为e转置矩阵;
步骤13;随机生成初始解混矩阵w0,‖w0‖2=1;
步骤14:更新解混矩阵w,
其中,g(y)=y×exp(-y2/2),g′为g的导数;
步骤15:如果所述解混矩阵w收敛,则wn+1解混矩阵,停止迭代,反之重新执行步骤14继续迭代;
步骤16:得到n个分离语音信号y=[y1,y2,……yn],
在上述任一方案中优选的是,判断所述解混矩阵w收敛的公式为|wn+1-wn|<ε,其中,ε为收敛门限。
在上述任一方案中优选的是,所述语音特征包括每次说话时长sn(l)、说话次数sn(n)、短时能量en和mfcc系数cn中至少一种。
在上述任一方案中优选的是,所述每次说话时长sn(l)是指检测语音段的起始时间和结束时间中间的时间长度。
在上述任一方案中优选的是,所述说话次数sn(n)是指每条语音中出现的分段语音的次数。
在上述任一方案中优选的是,所述短时能量en是指语音信号的第n个采样点的短时能量。
在上述任一方案中优选的是,所述mfcc系数cn是指每个人语音的梅尔频率倒谱系数特征点。
在上述任一方案中优选的是,所述多语音特征融合模块用于使用下面公式对所述语音特征进行归一化处理,
其中,
在上述任一方案中优选的是,所述多语音特征融合模块还用于所述每次说话时长sn(l)、所述说话次数sn(n)、所述短时能量en和所述mfcc系数cn分别带入到上面公式中,得到归一化的说话时长
在上述任一方案中优选的是,所述多语音特征融合模块还用于融合构成各个人的语音特征矢量xn,
其中,λ为对应的加权参数。
在上述任一方案中优选的是,所述融合参数优化模块用于在目标说话人语音特征空间中,使用概率密度函数p(x|λ)计算d维的特征参数矢量x的分布,
其中,n(x;μi;∑i)表示d维每个子分布的联合高斯概率分布函数,αi表示第i个子高斯分布在总体混合高斯分布中所占的权值,μi和∑i分别表示第i个高斯分量的均值和协方差,m表示描述总体分布所用的高斯函数的个数。
在上述任一方案中优选的是,所述联合高斯概率分布函数n(x;μi;∑i)的计算公式为
在上述任一方案中优选的是,所述融合参数优化模块还用于计算高斯混合模型λ的似然度,公式为
其中,λ=(m;x;μi;∑),为高斯混合模型,x=[x1,x2,……xn]表示分离的说话人的总体的语音特征矢量序列。
在上述任一方案中优选的是,所述em算法是一种递归最大似然估计算法,每次迭代都会不断优化参数λ的值,使得似然度l(x|λ)达到最大,所述em算法分e步和m步。
在上述任一方案中优选的是,所述e步是指利用模型初始参数,计算特征矢量xi在第k个高斯模型上的后验概率p(k|xi,λ),
其中,m为子高斯分布的个数,n(x;μk;∑k)为子高斯分布的联合概率密度函数。
在上述任一方案中优选的是,所述m步为对第k个混合度的所述后验概率p(k|xi,λ)分别计算混合度的权值ai、均值μi、协方差∑i的最大似然估计值。
在上述任一方案中优选的是,第k个所述混合度的权值αk的计算公式为
在上述任一方案中优选的是,第k个所述混合度的均值μk的计算公式为
在上述任一方案中优选的是,第k个所述混合度的协方差αk的计算公式为
在上述任一方案中优选的是,所述融合参数优化模块还用于通过高斯混合模型对语音特征矢量序列x=[x1,x2,……xn]进行概率估计,得到对应的特征矢量xi的概率αi,概率值大的是目标说话人的语音特征。
本发明提出了一种多人语音混合中目标说话人估计方法及系统,解决了fastica算法的分离不确定性(无序性)问题,提高多人混合语音的分离性能。
附图说明
图1为按照本发明的多人语音混合中目标说话人估计方法的一优选实施例的流程图。
图2为按照本发明的多人语音混合中目标说话人估计系统的一优选实施例的模块图。
图3为按照本发明的多人语音混合中目标说话人估计方法的另一优选实施例的流程图。
图4为按照本发明的多人语音混合中目标说话人估计方法的如图3所示实施例的fastica算法流程图。
图5为按照本发明的多人语音混合中目标说话人估计方法的如图3所示实施例的分离语音对应说话时长和说话次数检测示意图。
图5a为按照本发明的多人语音混合中目标说话人估计方法的如图5所示实施例的分离语音短时能量示意图。
图5b为按照本发明的多人语音混合中目标说话人估计方法的如图5所示实施例的分离语音mfcc系数特征示意图。
图6为按照本发明的多人语音混合中目标说话人估计方法的如图3所示实施例的分离语音特征归一化示意图。
图7为按照本发明的多人语音混合中目标说话人估计方法的如图3所示实施例的高斯混合模型参数优化过程示意图。
图8为按照本发明的多人语音混合中目标说话人估计方法的如图3所示实施例的多人混合语音中目标说话人估计工作示意图。
具体实施方式
下面结合附图和具体的实施例对本发明做进一步的阐述。
实施例一
如图1、2所示,执行步骤100,语音分离模块200使用通用麦克风阵列采集语音信号得到混合信号x。
执行步骤110,语音分离模块200使用fastica算法进行多人混合语音分离,得到n个分离语音。该步骤包括以下子步骤:
步骤111:对混合观测信号x中心化去均值,
其中,i=1…..n,n为实系数;
步骤112:白化处理去混合语音之间的相关性,
z=vx=ed-1/2etx
其中,v为白化矩阵,e为中心化数据的特征向量构成的正交矩阵,d为特征向量对应的特征值构成的对角矩阵,et为e转置矩阵;
步骤113;随机生成初始解混矩阵w0,‖w0‖2=1;
步骤114:更新解混矩阵w,
其中,g(y)=y×exp(-y2/2),g′为g的导数;
步骤115:如果所述解混矩阵w收敛,即|wn+1-wn|<ε,其中,ε为收敛门限(据正态分布3-σ原则,一般取ε=0.00135),则wn+1解混矩阵,停止迭代,反之重新执行步骤14继续迭代;
步骤116:得到n个分离语音信号y=[y1,y2,……yn],
执行步骤120,多语音特征融合模块210提取多个语音特征,语音特征包括每次说话时长sn(l)、说话次数sn(n)、短时能量en和mfcc系数cn中至少一种,每次说话时长sn(l)是指检测语音段的起始时间和结束时间中间的时间长度,说话次数sn(n)是指每条语音中出现的分段语音的次数,所述短时能量en是指语音信号的第n个采样点的短时能量,mfcc系数cn是指每个人语音的梅尔频率倒谱系数特征点。
执行步骤130,多语音特征融合模块210使用下面公式对步骤110中的语音特征进行归一化处理,
其中,
执行步骤140,多语音特征融合模块210对归一化的语音特征加权融合,融合构成各个人的语音特征矢量xn,
其中,λ为对应的加权参数。
执行步骤150,融合参数优化模块220使用高斯混合模型进行加权参数优化。在目标说话人语音特征空间中,使用概率密度函数p(x|λ)计算d维的特征参数矢量x的分布,
其中,n(x;μi;∑i)表示d维每个子分布的联合高斯概率分布函数,αi表示第i个子高斯分布在总体混合高斯分布中所占的权值,μi和∑i分别表示第i个高斯分量的均值和协方差,m表示描述总体分布所用的高斯函数的个数。联合高斯概率分布函数n(x;μi;∑i)的计算公式为
计算高斯混合模型λ的似然度,公式为
其中,λ=(m;x;μi;∑),为高斯混合模型,x=[x1,x2,……xn]表示分离的说话人的总体的语音特征矢量序列
执行步骤160,融合参数优化模块220使用期望最大化算法em算法进行高斯混合模型估计。em算法是一种递归最大似然估计算法,每次迭代都会不断优化参数λ的值,使得似然度l(x|λ)达到最大,所述em算法分e步和m步。e步是指利用模型初始参数,计算特征矢量xi在第k个高斯模型上的后验概率p(k|xi,λ),
其中,m为子高斯分布的个数,n(x;μk;∑k)为子高斯分布的联合概率密度函数。
m步为对第k个混合度的所述后验概率p(k|xi,λ)分别计算混合度的权值ai、均值μi、协方差∑i的最大似然估计值。第k个所述混合度的权值αk的计算公式为
第k个所述混合度的均值μk的计算公式为
第k个所述混合度的协方差αk的计算公式为
执行步骤170,融合参数优化模块220输出目标语音。通过高斯混合模型对语音特征矢量序列x=[x1,x2,……xn]进行概率估计,得到对应的特征矢量xi的概率αi,概率值大的是目标说话人的语音特征。
实施例二
本申请的目的在于解决多人场景下语音分离的不确定性问题和语音识别率低的问题,提出了一种多人混合语音中目标说话人估计方法。首先对多人混合语音分离,然后对分离后的语音进行目标说话人估计,以此提高目标说话人语音的分离效果和识别率。本发明主要分为三个模块:(1)语音分离模块,使用著名的fastica语音分离算法进行多人混合语音分离;(2)多语音特征融合模块,提取多个语音特征,特征归一化之后,进行加权参数融合,得到语音特征序列;(3)融合参数的优化模块,即使用高斯混合模型对融合参数进行优化,通过期望最大化算法,估计出概率值最大的语音特征序列,概率最大最可能是目标说话人。
一个人可以在众多混合声音中听取其感兴趣的声音,人耳能够在混合声音中区分自己关注的声音。但对于机器而言,在多人的环境下分离不同人的声音是一个非常困难的问题,独立成分分析(ica)可以有效的解决这一问题,进行多人混合语音的分离。每个人的音色不同,每个人的声音都有其独特的规律,所以多人语音的混合可以近似看着是多个相对独立成分的线性混合。ica方法假定每个源信号之间都是统计独立的,根据源信号的统计特性,从混合观测信号中分离出源信号的各个具有非高斯性的独立成分。快速独立成分分析算法(fastfixed-pointalgorithmforica,fastica),也被称作固定点算法,是一种以分离速度快和鲁棒性好而著名的ica算法。该算法是基于牛顿迭代法来实现混合信号中隐藏的独立成分局部非高斯性极大化的方法。
由于fastica算法的不确定性(无序性),导致分离得到的语音并不知道哪一个是属于目标语音。所以,需要进行目标说话人估计,以便提取目标语音,提升目标说话人语音的可懂度和识别率。
本发明通过可行的技术方案,具有以下几点有益效果:
1.解决了fastica算法的分离不确定性(无序性)问题,提高多人混合语音的分离性能。
2.对多人混合语音中目标说话人进行概率估计,以便增强目标说话人语音的可懂度和识别率。
结合图3进一步对本发明的具体实施过程进行说明。本发明在fastica算法上进行分离语音的目标说话人估计,以便去除环境噪声和非目标人的语音干扰,提高多人混合语音中目标说话人语音的分离性能、可懂度和识别率。
顺序执行步骤300和步骤310,采集多人场景下的混合语音数据并进行预处理。执行步骤320,进行多人混合语音的分离。如图4所示,使用著名的fastica算法对多人混合语音进行分离,得到多个分离语音。执行步骤400,用麦克风阵列采集语音信号,得到混合信号x。执行步骤410,对混合观测信号x中心化去均值,
执行步骤420,白化处理去混合语音之间的相关性,
z=vx=ed-1/2etx
执行步骤430,随机生成初始解混矩阵w0,‖w0‖2=1。执行步骤440,更新解混矩阵w,
执行步骤330,提取多个语音特征。不同语音特征示意图如图5、5a、5b所示,图5对应的是分离语音对应说话时长和说话次数检测示意图,图5a对应的是分离语音短时能量示意图,图5b对应的是分离语音mfcc系数特征示意图。
执行步骤340,进行目标说话人估计。分别对语音特征进行归一化处理,是每个语音特征的取值大小在[0,1]之间。语音特征归一化示意图如图6所示。完成语音特征序列的高斯混合模型参数优化。分别对多个语音特征序列构成的高斯混合模型进行估计,优化过程不断迭代,得到不同的参数值。参数优化过程如图7所示。
执行步骤350,输出目标语音。根据语音特征序列xi对应的权重值ai的大小进行判断,权重值ai大的就是概率估计的目标说话人对应的语音。
本申请提出的一种多人混合语音中目标说话人估计方法的工作示意图如图8所示。
为了更好地理解本发明,以上结合本发明的具体实施例做了详细描述,但并非是对本发明的限制。凡是依据本发明的技术实质对以上实施例所做的任何简单修改,均仍属于本发明技术方案的范围。本说明书中每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似的部分相互参见即可。对于系统实施例而言,由于其与方法实施例基本对应,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
- 还没有人留言评论。精彩留言会获得点赞!