一种基于单通道、无监督式的目标说话人语音提取方法与流程
本发明涉及一种语音提取方法,尤其涉及一种复杂多说话人情境下基于单通道、无监督式的目标说话人语音提取方法。
背景技术:
教育质量的保证是我们各层次教育的关键。而在提高教育质量中,提高教学质量尤其是课堂教学质量应为重中之重。但目前传统的做法是基于人工(同行)现场观摩与评价的方法,这类方法虽然能够发挥一定的作用,但不具备普适可操作性,也不具备普适客观性,就其原因在于:一则教学主管部门很难做到时时刻刻地都在考察课堂、做出评价并给出建议,这势必会给教学管理带来沉重的负担也没有必要。再则,传统的现场观摩与评价,由于不能全程跟进教学进程,因此很难客观评价教师的教学质量。
信息与智能技术已然成为社会发展的重要依托,如何利用与发展信息与智能技术革新传统课堂,构建面向课堂教学的,高效、自动的“智能感知”则自然而然成为一个极具研究价值的科学问题。
实现面向课堂教学的“智能感知”,首当其冲要解决的问题是教师语音识别与获取。
目前除有监督的说话人识别方法外,无监督的说话人识别主要方法为说话人聚类。课堂语音中的教师语音识别也大体属于这一部分。对于说话人聚类的研究主要有以下4种:1.层次聚类;2.K-means聚类;3.谱聚类;4.近邻传播聚类。
文章<<无监督说话人聚类方法研究与实现>>中,研究了基于特征相似矩阵的谱聚类算法的运行效率,实现了一种通过自适应混合高斯模型来构建模型相似矩阵的谱聚类算法。首先根据GMM-UBM-MAP技术训练语音段获得高斯混合模型,即先离线训练背景模型(UBM),并根据最大后验准则(MAP)对UBM进行自适应,获得目标话者的高斯混合模型(Gauss Mixture Model,GMM)。之后,计算GMM 模型的相似度构造相似度矩阵,并针对矩阵进行特征提取用于聚类,获得目标人物的话语部分。
文章<<改进的说话人聚类初始化和GMM的多说话人识别>>中,提取语音段的梅尔倒谱系数(MFCC)特征,之后训练部分使用贝叶斯信息准则(BIC)对初始类进行处理,获得较纯的初始类别,之后采用聚类算法对于MFCC特征进行聚类,并对每一类训练获得GMM模型特征,在识别阶段,使用基于GMM模型的说话人识别进行说话人判断。
对于教师语音的提取,除需要对单独的教师语音进行识别外,还需对包含教师话语的重叠语音进行语音分离。语音分离的目的从多个同时发声的声源中,分离出感兴趣的语音。语音分离根据接收的源信号与采集的混合信号之间的关系分为多通道语音分离与单通道语音分离。单通道语音仅需单一信号源,较多通道语音信号而言不仅更易获取而且更符合现实情况。但对于单通道语音信号进行语音分离更加困难。单通道语音分离的研究主要有以下3种:1.基于计算听觉场景分析;2.基于模型;3.基于时频分布。
文章<<An Auditory Scene Analysis Approach to Monaural Speech Segregation>>Hu Wang提出了基于CASA的语音分离系统框架。通过模拟人耳耳蜗的基底膜特性,将混合信号分解为时频表达并提取语音分离所需特征进行听觉时频分割,组合同一声源的相邻时频单元形成听觉片段并最终合并形成同一声源的听觉片段,最后基于同一声源的波形合成实现语音分离。之后,Hu Wang 对CASA系统进行了一系列改进,包括对于清浊音信号分离的优化。文章 <<CNMF-based acoustic features for noise-robust ASR>>指出NMF是一种无监督的基于字典学习的方法,其在处理各种类型的信号分离时起到了很好的作用。NMF算法要求进行纯加性运算,分解后所有分量均为非负矩阵,并能够实现矩阵降维运算。随着研究不断的深入,NMF算法己具有快速运算和精确的特点,非常便于大规模数据的处理,因此在诸多领域得到广泛运用。
在上述现有技术中,存在以下缺陷:
1.层次聚类在进行无监督的说话人聚类识别时,以最小类间距是否大于一定的阈值作为判定聚类结束的标准,阈值的确定限制了层次聚类算法的效果。
2.文章<<无监督说话人聚类方法研究与实现>>中所提出的
GMM-UBM-MAP结合特征相似矩阵的谱聚类算法,需要对于语音信号的GMM模型进行训练,无法实现完全无监督的说话人识别。此外,该方法要求待检测语音中的说话人段相对较平均,且对于各说话人段的“纯度”要求较高,对于各形式的真实情景的适应性较差。
3.文章<<改进的说话人聚类初始化和GMM的多说话人识别>>中对于
MFCC系数进行聚类,MFCC是根据对语音进行分帧来提取相应特征的,对于较长的语音段,如40min的课堂录音,运算量会很大,且聚类准确率得不到好的保证。
4.文章<<An Auditory Scene Analysis Approach to Monaural Speech Segregation>>基于CASA进行语音分离,模拟人耳进行语音分离,但是模型人耳的特征难以选取。
5.文章<<CNMF-based acoustic features for noise-robust ASR>>需要事先给定分离语音的训练语音。
6.单通道语音分离结果中仍存在噪声的影响,上述语音分离方法很少对语音分离结果进一步去噪,提纯分离语音信号。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种基于单通道、无监督式的目标说话人语音提取方法。可利用并发展相关信息与智能技术手段对课堂语音信号进行获取、分析处理和识别,立足于构建自适应、无监督式的智能方法,鲁棒地从课堂语音信号中检测并提取出教师语音部分。。
为了解决上述技术问题,本发明实施例提供了一种基于单通道、无监督式的目标说话人语音提取方法,包括教师语言检测步骤和教师语言GGMM(General Gauss Mixture Model)模型训练步骤;
所述教师语言检测步骤包括以下步骤:
S1:对课堂录音获得语音数据;
S2:进行语音信号处理;
S3:语音分割与建模,所述语音分割包括对课堂语音进行等长分割,之后针对每段语音提取相应的MFCC特征,并基于MFCC特征构造各段语音的GMM模型;
S4:教师语音检测,将教师话语类别外的各段语音的GMM模型与GGMM进行相似度计算,设定自适应的阈值,将小于所述阈值的标记为教师话语类别,由此获得最终的教师话语类别;
所述教师语言GGMM模型训练步骤包括以下步骤:
S5:对S3所得到的语音数据进行聚类处理;获得初始的教师话语类别,并基于初始教师话语类别提取GGMM模型。
进一步地,所述聚类处理包括以下步骤:
S51:选取聚类中心点;
S52:计算所有样本与所述中心点距离、迭代并直到满足预设的停机条件;
S53:循环执行S51步和S52共n次,可获得n种教师语音划分组,按照设定的规则选择最大满足度的划分组作为初始教师语音;
S54:从所述划分组中选择若干个训练GGMM模型,并计算类中平均距离;
S55:根据GGMM和平均距离,对剩余的语音样本段进行二次判断,基距离小于设定阀值,则将样本加入到教师类别中;
S56:输出所有教师语音样本并写入数据库。
更进一步地,所述S51的步骤具体包括:
S511:从所有语音段中随机选取一个作为第一个中心点;
S512:计算剩余语音段与第一个中心点的GMM模型距离,选择距离最大的语音段作为第二个中心点;
S513:依次计算未选择作为中心点的语音段与中心点的距离,选择距离中心点距离最大的作为下一个中心点;
S514:迭代直至中心点个数达到指定类别个数。
更进一步地,所述S52的步骤具体包括:
S521:计算剩余部分GMM模型与中心点的距离,将每个GMM划分到最近的中心点中;
S522:更新中心点,取各类中,与类中所有点距离之和最小的作为新的中心点;
S523:迭代直至满足预设的停止条件或迭代到指定次数。
更进一步地,所述S53的步骤具体包括:迭代获得了N个教师类别向量进行相似度计算,取与其余N-1个向量相似度之和最大的作为最终聚类获得的初始教师类别。
更进一步地,所述S54的步骤具体包括:随机选取教师类别中的段,其中M为聚类获得教师类别中的语音段个数,随机取的目的是降低对于教师类别中全部语音段进行GMM模型训练的时间,N为根据M的大小自适应获得的常数,其获得方式如下所示:
其中,α为时间调节参数,用于调节进行GMM训练的语音段数量,length(C) 表示原始课堂语音经分割后获得语音段的总个数,系数0.4*length(C)表示最少的教师语音段个数。
更进一步地,所述S3包括:
S31:重叠语音检测,获得课堂语音中的重叠语音段;
S32:判断重叠语音中是否包含教师语音;
S33:选择与重叠语音最接近的语音段,作为训练语音段;
S34:设计CNMF+JADE方法进行语音分离。
更进一步地,所述S31包括:
使用静音点获得重叠语音段,通过设定能量阈值进行静音帧的判断,所述能量阈值通过以下方法进行获得:
其中,Ei表示第i帧语音帧的能量,其中N为语音段总帧数,r 为一个常数,范围为(0,1),表示向上取整。
更进一步地,所述S32包括:使用GMM相似度判断重叠语音中是否包含教师,相似度通过采用改进的巴特查里亚距离,判断依据如下:
其中,disp(A,B)表示A,B语音段GMM模型的距离,A表示重叠语音段,B为教师语音段,t为一自适应阈值,其计算公式如下:
其中,p为调节参数,取值为[0.5,0.8]之间,K为学生部分的语音段数量,Si为第i段学生语音段,B为教师语音段。
更进一步地,所述S33包括:选择与重叠语音最为接近的非教师语音段与教师语音段一起训练CNMF,选择方式为:
vi=min(disp(Ai,Sj)),i=1,2,..,N,j=1,2,...,K
其中,Ai为第i个重叠语音段,vi为对应选择的第i个训练语音段。
实施本发明实施例,具有如下有益效果:本发明面向高复杂性的课堂教学 (主要包括课堂情境的多样性、教师主体的多样性以及教师课堂组织的多样性),提出一种无监督式的,自适应鲁棒的教师语音检测与提取方法,有效提升了系统的在实际应用中的适应性与智能性,亦为后续应用与研究奠定基础。
附图说明
图1是本发明的框架流程结构示意图;
图2是教师语言检测步骤的流程示意图;
图3是教师语言GGMM模型训练步骤示意图;
图4是聚类算法的步骤流程示意图;
图5是语音分离实施步骤示意图;
图6是语音增强实施步骤。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
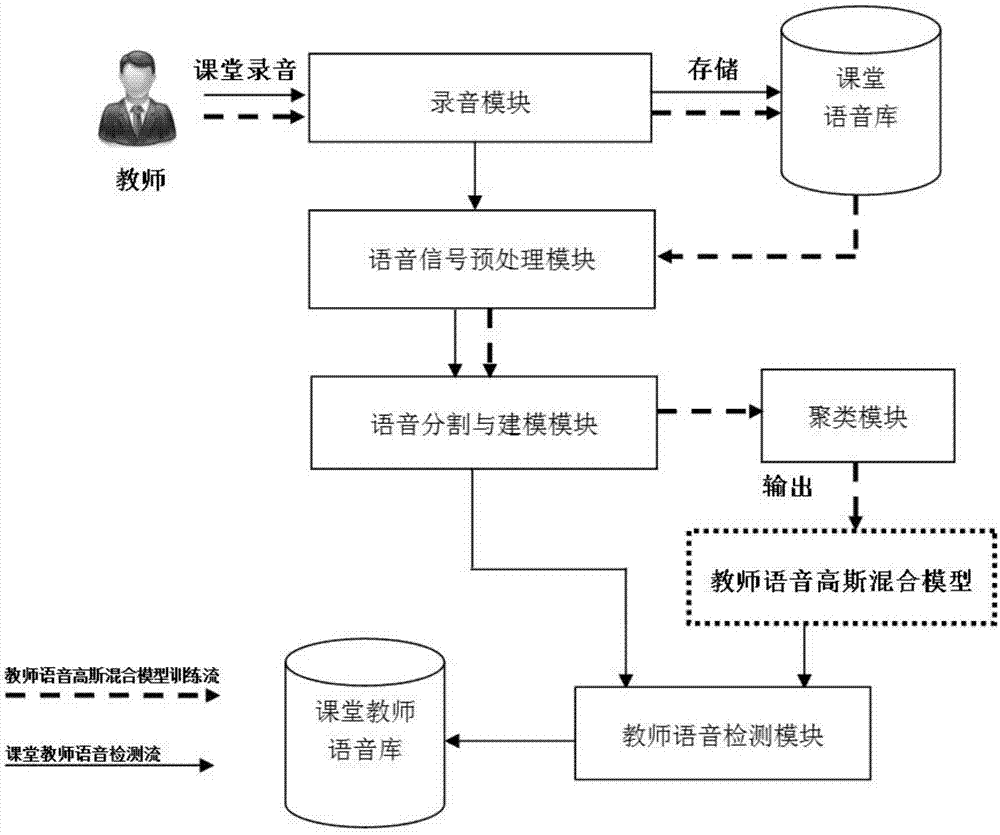
参照图1所示,本发明的一种基于单通道、无监督式的目标说话人语音提取方法,包括教师语言检测步骤和教师语言GGMM模型训练步骤。
如图2所示,教师语言检测应包含以下几个步骤:
S110、录音;
S120、语音信号预处理;
S130、语音分割与建模;
S140、教师语音检测。
如图3所示,教师语音GGMM模型训练功能单元应包含以下几个步骤:
S110、录音;
S120、语音信号预处理;
S130、语音分割与建模;
S240、聚类。
其中,在S110中通过使用录音设备获得相应的课堂语音数据。
S120中对于录音获取的课堂语音进行预处理,包括分帧,加窗,预加重等语音预处理常用方法。
S130中对于课堂语音进行等长分割,之后针对每段语音提取相应的MFCC特征,并基于MFCC特征构造各段语音的GMM模型。之后将各段语音的GMM模型作为S240的输入数据进行聚类操作,获得初始的教师话语类别,并基于初始教师话语类别提取GGMM模型。S140中将教师话语类别外的各段语音的GMM模型与 GGMM进行相似度计算,设定自适应的阈值,将小于阈值的标记为教师话语类别,由此获得最终的教师话语类别。
S240中的聚类算法如图4所示。
聚类算法具体实施例包含以下几个步骤:
S2401、初始中心点选取方法;
1)从所有语音段中随机选取一个作为第一个中心点。
2)计算剩余语音段与第一个中心点的GMM模型距离,选择距离最大的语音段作为第二个中心点。
3)依次计算未选择作为中心点的语音段与中心点的距离,选择距离中心点距离最大的作为下一个中心点。
4)迭代直至中心点个数达到指定类别个数。
上述中心点选择方法相比于随机中心点选取方法在最终聚类结果的准确率上获得了明显的提高。上述中心点选取方案可能会存在将离群点选为中心点的问题从而影响聚类结果,但在实际中,由于GMM-Kmeans算法在S2402(3)中所设置的停止条件,离群点作为中心点所获得的聚类结果会在迭代过程中被排除,所以通过上述方法选取初始中心点可以获得稳健的聚类结果。
仅通过上述方法依旧无法很好的度量高斯混合模型间的距离,即定义GMM A 与GMM B的离散度如下:
称为GMM A相对于GMM B的离散度,其中WAi表示GMM A的第i个混元的权重,WBj表示GMM B的第j个混元的权重,dAB(i,j)表示GMM A的第i个高斯分布与GMM B的第j个高斯分布间的距离,考虑到计算量的原因以及多个高斯分布出现均值向量完全相同的可能性,本实施例选用马氏距离作为dAB(i,j)的距离计算方法。
其中,表示两个多维高斯分布,μ1,μ2为两个分布的均值向量,为两个分布的协方差矩阵。
出于对称性的考虑,最终的GMM距离度量公式如下:
其中A,B分别表示两个GMM模型。
S2402、计算所有样本与中心点距离、迭代并直到满足预设的停机条件;
1)计算剩余部分GMM模型与中心点的距离,将每个GMM划分到最近的中心点中。
2)更新中心点,取各类中,与类中所有点距离之和最小的作为新的中心点。
迭代直至满足预设的停止条件(当所获得的聚类结果中语音段数量最多的类别所包含的语音段数量大于总语音段的40%并且语音段数量比第二大类别中语音段数量多时输出)或迭代到指定次数。
S2403、循环执行S2401步和S2402共n次,可获得n种教师语音划分组,按照一定的规则选择最大满足度的划分组作为初始教师语音。
S2403迭代获得了N个教师类别向量进行相似度计算,取与其余N-1个向量相似度之和最大的作为最终聚类获得的初始教师类别。由于所获得的N个教师类别向量的长度不唯一,进行相似度计算之前需要进行相应的处理使向量长度相同。
在本实施例中,使用补零法使向量长度相等。
该方法选取N个教师类别向量中长度最长的记为M,将所有向量长度扩展到 M,不足M的部分使用0元素代替,即:
M=max(length(T1),length(T2),...,length(TN))
Ti=[Ti,Appendi],i=1,2,...,N
Appendi=zeros(1,M-length(Ti)),i=1,2,...,N
其中,T1,T2,...,TN为N个教师类别向量,M为最长的向量长度,length(T)表示获得T向量长度,Appendi为第i个教师类别向量所有添加的0元素向量,zeros(i,j) 表示形成一个i行j列的0元素向量。
本实施例中,通过使用补零法使教师类别向量获得统一的长度,之后计算两两向量之间的距离,由于人为添加了0元素,利用向量间距离度量向量相似的方法,比如:欧氏距离等,会存在很大的误差,故,此处选用余弦相似度作为度量向量间相似度的方法。
余弦相似度用向量空间中两个向量夹角的余弦值表示向量的相似度。余弦值越接近于1,则表明夹角越接近于0度,则向量就越相似。
向量a,b间的余弦相似度定义如下:
其中a=(a1,a2,...,aN),b=(b1,b2,...,bN)分别表示一个N维向量。
S2404中随机选取教师类别中的段,其中M为聚类获得教师类别中的语音段个数,随机取的目的是降低对于教师类别中全部语音段进行GMM 模型训练的时间,N为根据M的大小自适应获得的常数,其获得方式如下所示:
其中,α为时间调节参数,用于调节进行GMM训练的语音段数量,本实施例取α=2。length(C)表示原始课堂语音经30s一段分割后获得语音段的总个数。系数0.4*length(C)表示最少的教师语音段个数。上式表示,聚类获得的教师类别语音段个数越大,在进行GMM模型训练时,取其中越小的比例。通过上述公式,使得不同语音进行GMM模型训练时所需的语音段个数趋于相似。
设置相似度阈值为S/γ,其中S为教师类别语音段的类间相似度均值,γ为自适应调节参数,用于最大限度的保证教师类别的完整性。其获得方式如下所示:
其中,β为调节参数,范围为[0,1],本实施例取β=1/5。Smax,Smin分别表示教师类别类间相似度的最大值和最小值。length(C)表示原始课堂语音经30s一段分割后获得语音段的总个数。M为教师类别中语音段的数量。上式表示M越大时,γ越大,即相似度阈值设置越小。且当类间相似度的范围越大时,取越小的相似度阈值,使得对于剩余部分是否为教师话语的准确度更高。
通过GMM-Kmeans算法的处理,最终可以获得一个相对稳定的教师类别向量,通过试验中与人工划分的类别进行比较,所获得的教师类别与人工标注的教师类别有较高的相似度,相比较于直接使用为改进的K-means进行聚类所获得的结果,本实施例所使用的GMM-Kmeans算法在聚类准确率上有显著的提高。
在获得教师类别之后,之后为对于静音以及重叠语音部分的判断。由
于学生类别无明确的特征,而且学生数量未知,所以无法对学生类别先进行检测。本实施例通过优先检测教师类别,静音以及重叠语音类别,通过排除上述三部分所包含的语音段将剩余语音段标注为学生话语类别。
参照图5所示,具体的语音分离实施步骤如下:
S310、重叠语音检测,获得课堂语音中的重叠语音段
S320、判断重叠语音中是否包含教师语音
S330、选择与重叠语音最接近的语音段,作为训练语音段
S340、设计CNMF+JADE方法进行语音分离
S310中基于静音点获得重叠语音段,研究发现,静音帧与非静音帧相比具有较低的能量,通过设定能量阈值可以进行静音帧的判断。能量阈值定义如下:
其中,Ei表示第i帧语音帧的能量,其中N为语音段总帧数,r 为一个常数,范围为(0,1),表示向上取整。
重叠语音表示一段语音中包含两个或两个以上人同时说话。在真实课堂中重叠语音主要表现为:1.学生分小组讨论;2.教师提问时,多个学生同时回答等。重叠语音段在静音帧的表现上不同于静音段。研究发现,在一个语音段中,当静音持续时间越长则该段包含重叠语音的概率越低[56]。联系本实施例所处理的问题,可以考虑通过静音帧的数量确定潜在的重叠语音类别。获得潜在重叠语音类别的方法与获得潜在静音类别方法类似,如下所示:
ClassOfOverlapi=I(numberOfSilencei<Thresholds),i=1,2,...,N
其中,α'为常量,用于获得重叠语音判断类别阈值Thresholdo。本实施例取α'=0.6。将语音段中静音帧数量小于阈值Thresholdo的段认为是潜在的重叠语音段,基于此获得潜在重叠语音类别。
S320、S330统称为语音分离前端处理,这一处理共两个目的:判断重叠语音中是否包含目标说话人,寻找除目标说话人之外与重叠语音最接近的语音段作为CNMF训练数据。本发明基于GMM相似度判断重叠语音中是否包含教师。相似度计算方法采用改进的巴特查里亚距离,判断依据如下:
其中,disp(A,B)表示A,B语音段GMM模型的距离,A表示重叠语音段,B为教师语音段。t为一自适应阈值,其计算公式如下:
其中,p为调节参数,取值为[0.5,0.8]之间,K为学生部分的语音段数量,Si为第i段学生语音段,B为教师语音段。通过与学生段进行计算可以获得一个自适应的阈值来判断重叠语音中是否包含教师。
语音分离前处理的第二个任务为选择与重叠语音段最接近的非教师语音段进行CNMF训练,该步骤对于后续语音分离有较大影响。本发明通过选择与重叠语音最为接近的非教师语音段与教师语音段一起训练CNMF,选择方式为:
vi=min(disp(Ai,Sj)),i=1,2,..,N,j=1,2,...,K
其中,Ai为第i个重叠语音段,vi为对应选择的第i个训练语音段。
S340对包含教师的重叠语音进行语音分离,本发明提出一种融合CNMF及 JADE进行单通道语音分离的方法,基于JADE对CNMF分离后的语音信号进行二次分离。CNMF+JADE算法旨在获得单通道混合语音中的所有说话人的分离语音信号,其步骤如下:
输入:待分离说话人纯净语音t1,t2,...,tN,待训练混合语音o1,o2,...oN-1,待分离混合语音O。
输出:分离后说话人语音s1,s2,...,sN。
Step1:选择目标说话人t1及对应混合语音o1训练CNMF
Step2:对混合语音O进行分离获得及
Step3:生成随机矩阵R1,混合及形成双通道语音信号S1。
Step4:基于JADE实现S1的分离获得s1及O1。
Step5:以O1作为待分离混合语音,t2,...,tN为待分离说话人纯净语音,o2,...oN-1为待训练混合语音,重复执行Step1-Step5。
Step6:获得分离后语音s1,s2,...,sN。
上述算法中,t1,t2,...,tN表示混合语音O中包含的说话人的纯净语音。N表示混合语音O中包含说话人个数。o1,o2,...oN-1为依次从混合语音O中除去对应说话人后的混合语音,表示如下:
在现实情况下,获取o1,o2,...oN-1非常困难,因此可通过随机选择一个当前混合语音中非目标说话人语音作为替代训练CNMF。经实验验证,该方法较原始 CNMF+JADE效果略有下降,但可将CNMF+JADE算法推广到更一般的情形。
Step3中的双通道语音信号生成形式如下:
其中,Ri为2×2的矩阵。
如图6所示,具体的语音增强实施步骤如下:
S410、待语音增强数据为语音分离后的教师语音
S420、对语音分离后教师语音进行自适应判断,选取合适的语音段进行语音增强
S430、应用小波变换进行语音增强
小波变换是近年来语音处理方面的研究热点。相较于传统的傅里叶变换等频域分析方法,小波变换可以同时给出信号的时域状态,是一种具有多分辨率分析、时频局部变换及灵活选择小波函数等特点的时频分析方法。下面将介绍小波变换的原理。
设L2(R)为一平方可积空间,且总有若其傅里叶变换满足:
称为一个基本小波或母小波。
将母小波经一实数对(a,b),其中a,b∈R,a≠0缩放和平移后,就可以获得一簇函数:
称这簇函数为小波基函数,其中a称为缩放因子,b称为平移因子,为窗口函数,其窗口大小固定但其形状可改变。基于这一特性小波变换具有多分辨率分析的特点。为归一化因子,作用是使小波在不同的尺度下具有相同的能量。
基于小波域进行信号处理是目前语音信号处理的主要手段之一。基于小波变换多分辨率、低熵性及去相关性的特性,使其在进行语音信号处理时具有极大的优势。大量的小波基可以应对不同的场景,故小波变换非常适合语音信号处理。
在利用小波变换进行语音增强时,均是使用小波变换中的多分辨率分析的特性,根据噪声与语音的小波系数在不同尺度的小波域上表现出的不同的特征,制定相应的规则,完成对噪声信号小波系数的处理。
小波变换去噪的主要步骤如下:
Step1:对含噪信号进行小波变换
Step2:在不同尺度上对小波系数进行去噪处理
Step3:将处理后的小波系数做小波逆变换,获得增强后的重构信号
小波去噪的方式大致可以分为如下三类:利用小波变换模极大值原理进行取噪;利用小波变换空间系数的相关性进行去噪;利用小波阈值去噪。本实施例主要使用第三种基于小波阈值去噪。
小波阈值去噪是比较常用的去噪方法之一,其基本过程如下:
Step1:根据待处理信号选择一个合适的小波基,确定合理地分解层数,对
含噪语音信号进行多层分解。
Step2:对分解后的小波系数在不同尺度上选择合适的阈值,并量化。
Step3:根据阈值量化后的处理结果进行小波重构获得增强后的语音信号。
小波基的多样性是小波变换进行时频分析的优点之一,故选择合适的小波函
数至关重要。研究表明,在进行语音信号处理时为更有利于处理语音信号的瞬态变化需要选择光滑性、对称性较好且有较低的消失矩的小波基函数。
小波分解的级数,作为影响语音增强算法去噪效果的因素历来备受关注。随着分解级数的增加,语音信号与噪声信号的细节部分更加清晰,更利于去噪。但是随着分解级数的增加,语音能量会越来越分散而导致失真而且算法运行速度也会越来越慢;分解级数少则会导致信号与噪声混淆从而无法分离出噪声。研究人员通过大量研究实验分析发现,针对小波分解级数的选取,取最合理的分解级数为N为数据长度,表示向下取整。
在小波阈值去噪算法中,对于阈值的估计是决定去噪效果的重要因素之一。小波变换将含噪语音信号分解为高频细节部分与低频近似部分,而噪声的频率通常偏高,故噪声能量主要集中于高频小波系数上,语音能量主要集中于语音信号的低频部分。所以可以通过设定一个门限值将小于该值的噪声分量截断进行去噪。该门限值就是小波阈值去噪中的所要研究的阈值。
对于小波阈值去噪阈值的选取主要包含如下经典方法:
统一阈值法。
统一阈值估计是基于最小均方误差准则推导获得。可表示为:
其中σn是噪声的标准差,N为信号长度。噪声的方差由下式获得:
σn=Mj/0.6745
其中Mj为分解小波系数各层的绝对中值,0.6745为经验值。
该方法实现简单,对于滤除高斯白噪声效果较好,但由于与语音长度相关,在数据量很大时会导致效果变差。
SUREShrink阈值[73]
SUREShrink阈值估计是一种自适应阈值选择的方法,是最优阈值的无偏估计。阈值的选择可通过如下风险函数定义:
想要获得阈值估计函数则需要满足风险函数最小,即:
代入信号长度,则有:
其中表示取集合{Y||Yi|<t}中的元素个数。
Minimaxi阈值
Minimaxi阈值又叫做极大极小阈值,该方法产生的是一个最小均方误差的
极值。Minimaxi阈值的计算公式如下:
其中,N为信号长度。
此外,阈值函数与阈值估计一样,也在小波阈值去噪算法中起到至关重要的作用,常用的阈值函数如下:
硬阈值函数
硬阈值函数如下:
其中,为估计小波系数,ωj,k为分解小波系数,λ为去噪阈值。从上式可以发现,硬阈值去噪的原理是将ωj,k与λ作比较,小于λ的将被置零,大于λ的被保留,这样的处理可能使得信号在重构时引入震荡信号,影响去噪效果。
软阈值函数
为消除硬阈值去噪的影响,引入软阈值去噪的方法,其形式如下:
与硬阈值函数相比,软阈值函数加强了语音信号的平滑性,但同样会一定程度上丢失特征造成失真[74]。
半软阈值函数
为克服软,硬阈值函数的缺陷,有学者提出半软阈值函数,其函数如下:
其中λ1,λ2分别为下阈值和上阈值且有0<λ1<λ2,根据经验λ1的取值与语音有关,当清音较多时,λ1取值表较小,当浊音较多,λ1取值较大。通过调整λ1,λ2可使得使得该方法兼具软,硬阈值的优点,但两个参数会增加算法计算复杂度。
Garrote阈值函数
Garrote阈值函数表示如下:
该函数将阈值引入到阈值函数中,动态的剔除大于选定阈值的小波系数。
本发明设计一个基于小波变换的自适应方法对CNMF+JADE分离后语音信号进行分析,期望实现有选择性地进行语音增强,即在语音增强前自动过滤那些语音增强后可能会导致语音质量下降的语音段。通过对多段语音分离后语音信号及经过小波变换后语音效果的分析发现,当分离后语音之间的距离较大时,在进行小波变换语音增强时效果会有所下降。基于上述发现,本发明设计如下方法进行语音增强前自适应判断。
i=1,2,...,N
Oi-1=Oi+si+l
O0=O
ON=sN
其中,si表示经过CNMF+JADE分解后的第i个教师语音信号。Oi表示混合语音Oi-1经CNMF+JADE分离出si后的混合语音信号。分别表示si、Oi对应的 GMM。l表示分离过程中的损失。N表示混合信号中包含的说话人个数。disp(·)为上文所提出的GMM距离计算公式,p为缩放因子,取值为[1,1.2]。
1.本发明基于课堂教学这一复杂情境,设计教师语音提取方法,衍生了信息化课堂的应用范畴,不仅是智慧课堂(人工智能+教育)的重要组成部分,更是未来教育的一种全新体现。具我们参阅资料所知,目前同类型的研究极少,基本上还没有形成可用的框架与理论。本发明可谓在智慧课堂的研究中迈出了一大步,开拓了基于人工智能的教育方法学的新视野。
2.本发明基于单通道、自适应、无监督式的对课堂教师语音进行识别与提取。相较于已有的方法,不需要任何先验知识,且对于不同形式,不同长度的课堂语音,不同的课堂环境均有很好的自适应能力。同时本文提出的方法,不仅仅可以应用在课堂教学中,还可以应用在诸如会议、助听、通讯等领域(比如,将语音分离技术与助听器结合,使得助听器具有更强大的信号处理功能,提高助听器的语音质量。手机通讯领域中,在设备端应用语音分离技术达到抑制非目标说话人,提高语音质量及可懂度等等。)
3.本发明设计并实现一种改进的GMM-Kmeans聚类方法,以GMM模型作为特征进行聚类,最大限度的保留了原始特征,提高聚类的准确率。以GMM作为特征并计算距离,避免直接处理较大长度语音信号,从而缩短了算法处理时间,总体上实现了一种准确率高并且速度快的课堂教室语音识别。
4.在GMM-Kmeans聚类算法的基础上,考虑环境的影响,基于聚类结果,自适应的选取合适的语音段并构造GGMM模型,自适应获取相似度阈值,二次检测教师话语,从而获得准确地教师语音类。所有的阈值均为通过设计公式自适应的根据课堂语音数据获得,无人工干涉,从而使得该算法针对不同课堂环境,课堂情形具有很强的鲁棒性。
5.本发明设计并实现一种CNMF+JADE的语音分离算法,通过应用JADE对 CNMF语音分离结果进行二次语音分离。语音分离结果得到有效的提升。7.本发明设计并实现一种自适应小波变换语音增强的方法,对CNMF+JADE语音分离后的语音进行自适应判断,过滤不适合再次进行语音增强的语音段,有目的性的对语音信号进行去噪。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!