一种交通道路声音监测与异常声音识别系统的制作方法
本发明涉及声音监测与识别技术领域,具体是一种交通道路声音监测与异常声音识别系统。
背景技术
异常声音是指某种正常环境下不应该产生的声音,公共场所的异常声音通常包括爆炸声、碰撞声、尖叫声、枪击声等。交通道路上的异常声音能够反映出交通事故与紧急情况的发生,通过对交通道路声音的监测,可以了解某条道路的交通状况,当发生异常情况时,通过对异常声音的识别,能够分析出该异常情况的性质。此外,还能根据监测情况判断出易于发生交通事故或交通拥堵的路段。
道路监控系统是智能交通的重要组成部分,现有交通道路监控系统中,通常只有音视频监控功能而没有事件识别功能,当发生异常事件时,通常通过人工回放监控录像进行事件识别或者通过图像处理算法进行事件识别。人工主动识别方式较为烦琐且费时,图像处理识别方式需要的计算量大且计算算法复杂。因此,对交通道路进行声音监测很重要,当产生异常声音时,对异常声音进行识别从而判断出异常事件的类型,也显得格外重要。
技术实现要素:
本发明目的在于克服上述交通道路监控系统中存在的问题,提出一种交通道路声音监测与异常声音识别系统,通过拾音器与声卡对声音进行采集,通过定位模块获取位置信息,数据处理模块将异常声音数据与位置信息数据通过无线网络发送至服务器端,服务器端对异常声音数据进行mfcc、短时能量、短时过零率等多特征提取,将提取到的特征数据输入至深度卷积神经网络中与异常音特征数据库进行对比,最终可得到异常声音的类型。将异常声音类型与定位信息结合,在地图中呈现出异常声音发生的位置与异常声音的类型。
为实现上述目的,本发明一种交通道路声音监测与异常声音识别系统,包括通过网络连接的声音采集端和服务器端;声音采集端包括拾音器、声卡、gps定位模块、数据处理模块、无线通信模块。
所述拾音器,用于对声音信号的采集;
所述声卡,用于对声音信号进行模数转换;
所述gps定位模块,用于获取卫星发来的定位信息;
所述数据处理模块,用于对采集的声音信号进行初步检测判断是否为异常声音,并将检测到的异常声音数据与定位信息数据一起发送至服务器端;
所述无线通信模块,用于为数据处理模块提供传输数据的通信网络;
所述服务器端,用于对异常声音数据进行mfcc、短时能量、短时过零率等多特征数据提取,将提取的特征数据输入至深度卷积神经网络中与异常声音特征数据库进行对比,综合三种特征的匹配率,识别并输出异常声音的类型;将异常声音类型与定位信息结合,在地图中呈现出异常声音发生的位置与异常声音的类型。
进一步地,所述数据处理模块对采集的声音信号进行初步检测判断是否为异常声音,其步骤包括:
1)分帧,将声音信号以帧为单位进行处理;
2)对声音信号进行快速傅里叶变换,得到每一帧对应的频谱;
3)计算每一帧的信号功率值;
4)由每一帧的功率值计算出声音的分贝值;
5)对每一帧的分贝值进行判决,大于40db则判定为异常声音(按照噪音标准,大于40db则判定为噪音)。
进一步地,所述服务器端对异常声音数据进行mfcc特征提取,包括以下步骤:
1)预加重,提升声音信号高频部分,使信号频谱变得平坦;
2)分帧,将声音信号以帧为单位进行处理;
3)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
4)快速傅里叶变换,得到每一帧对应的频谱;
5)mel滤波,将快速傅里叶变换后的频谱通过mel滤波器组转换为体现人类听觉特性的mel频谱;
6)取对数,计算每个滤波器组输出的对数能量;
7)离散余弦变换,对对数能量进行变换,求出mel倒谱系数;
8)提取动态差分参数,用静态特征的差分谱来描述动态特征,有效提高系统的识别性能;
9)取离散余弦变换后的第2到第13个系数与动态差分参数为mfcc特征。
进一步地,所述服务器端对异常声音数据进行短时能量特征提取,包括以下步骤:
1)分帧,将声音信号以帧为单位进行处理;
2)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
3)取绝对值,计算出每一帧内的所有样点幅值;
4)计算每一帧内所有样点的短时能量,对所有样点的短时能量求和;
5)取每一帧的短时能量值对应为一个短时能量特征。
进一步地,所述服务器端对异常声音数据进行短时过零率特征提取,包括以下步骤:
1)分帧,将声音信号以帧为单位进行处理;
2)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
3)判断每一帧内相邻的两个样点是否具有不同的代数符号,是则发生
了过零;
4)计算每一帧内过零的次数;
5)取每一帧内过零的次数对应为一个过零率特征。
进一步地,所述服务器端利用深度卷积神经网络对异常声音信号进行识别,包括以下步骤:
1)建立异常声音特征数据库;
2)将提取到的异常声音的mfcc、短时能量、过零率特征数据输入至深度卷积神经网络;
3)提取的mfcc特征数据与数据库中的mfcc特征数据进行对比,由分类器识别出匹配率最高的类型;
4)提取的短时能量特征数据与数据库中的短时能量特征数据进行对比,由分类器识别出匹配率最高的类型;
5)提取的短时过零率特征数据与数据库中的短时过零率特征数据进行对比,由分类器识别出匹配率最高的类型;
6)综合上述三个特征的对比匹配率及识别类型,得出最佳识别结果。
本发明的有益效果:一种交通道路声音监测与异常声音识别系统,拾音器及数据处理模块可根据需求在指定路段进行布置安装;对交通道路声音进行实时监测,当监测到异常声音时,才将异常声音数据传输至服务器端进行进一步识别,大大减少了数据传输量;提取异常声音信号的多种特征值,结合神经网络进行识别与分类;对异常声音数据进行识别分类时,采用深度卷积神经网络(cnn),非常适用于声音的识别与分类,该网络能够大大提高训练效率与识别精度,高效识别交通道路中产生的异常声音。
附图说明
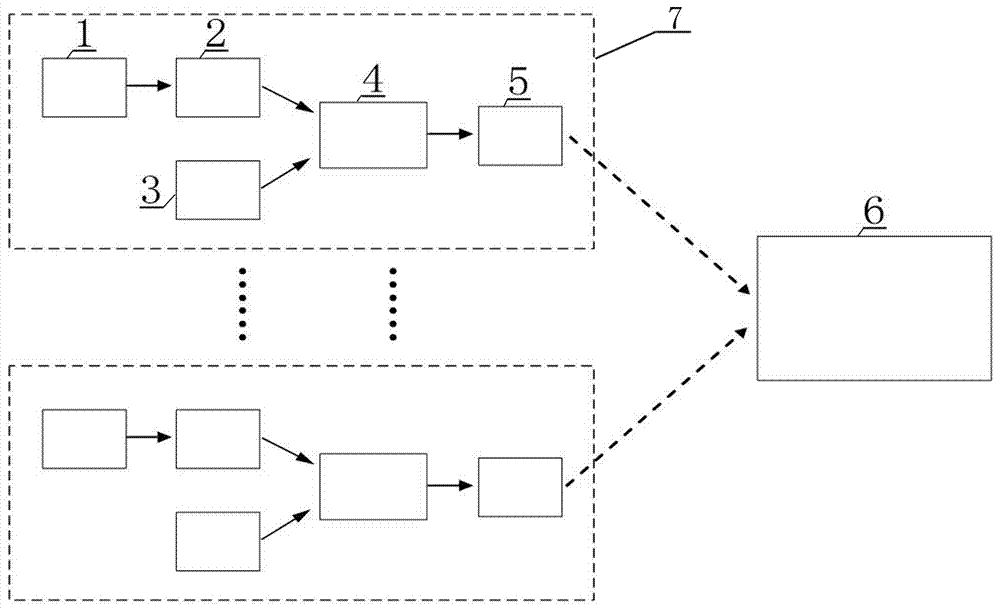
图1是本发明交通道路声音监测与异常声音识别系统结构框图;
图2是本发明系统中的声音采集端的示意图;
图3是本发明系统中数据处理模块的示意图;
图4是本发明系统中服务器端处理数据的示意图;
图5是本发明系统中提取mfcc特征的步骤示意图;
图6是本发明系统中提取短时能量特征的步骤示意图;
图7是本发明系统中提取短时过零率特征的步骤示意图。
具体实施方式
下面结合实施例和附图对本发明内容作进一步的说明,但不是对本发明的限定。
实施例
如图1系统结构框图所示,本发明的交通道路声音监测与异常声音识别系统包括通过网络连接的声音采集端7和服务器端6,声音采集端7包括拾音器1、声卡2、gps定位模块3、数据处理模块4、无线通信模块5。
拾音器1采集并放大声音信号,将声音信号传输至声卡2。声卡2将采集到的声音信号(模拟信号)转化为数字信号,将数字信号传输至数据处理模块4。gps定位模块3接收卫星发来的定位信息,将定位信息传输至数据处理模块4。数据处理模块4对接收到的声音信号进行初步检测,判断是否存在异常声音,若检测到异常声音则通过无线通信模块5发送至服务器端6,同时对接收到的gps定位信息进行处理,选择二维位置信息数据通过无线通信模块5发送至服务器端6。服务器端6对收到的异常声音数据进行多特征提取,结合深度卷积神经网络进行分类识别。最终结合收到的位置信息,将异常音发生位置与分类识别结果在地图上呈现。
如图2所示,拾音器1中,麦克风采集声音信号,此声音信号为模拟信号,通过运算放大器进行第一级放大,再通过自动增益放大器(agc)进行第二级放大,输出经过放大的模拟信号。该双级放大电路有效地控制声音信号的强弱,避免瞬间高分贝声音对后级设备的影响。声卡2中,经过放大的模拟信号经过采样、量化、编码后,输出数据处理模块4可识别的pcm数字信号。
如图3数据处理模块4处理数据示意图所示,数据处理模块4首先对接收到的声音信号进行分帧,将信号以帧为单位进行处理,接着对每一帧信号进行快速傅里叶变换(fft),得到每一帧对应的频谱,然后计算每一帧的信号功率值,通过每一帧的功率值计算出声音的分贝值,最后对每一帧的分贝值进行判决,大于40db则判定为异常声音(按照噪音标准,大于40db则判定为噪音)。特别地说明,若产生异常声音,则该声音信号在若干连续帧的分贝值皆大于40db。同时,对gps定位信息进行二维位置坐标提取。将提取到的异常声音数据与二维位置坐标数据打包,通过无线通信模块5提供的网络传输至服务器终端。
如图4服务器端处理数据示意图所示,服务器端6接收到数据处理模块4发来的数据包,通过解包得到声音数据与二维位置坐标。对于声音数据,首先保存至本地,接着对声音数据进行滤波,然后对声音信号进行多特征提取,最后将特征数据输入深度卷积神经网络进行识别与分类,得出分类结果。对于分类结果,将其保存至对应库进行异常音数据库的建立,如将车祸碰撞声保存至车祸碰撞声数据库。对于二维位置坐标,首先保存至本地,然后进行坐标转换,将地球经纬度坐标转换为对应的地图坐标,本发明实施例调用百度/google地图。最终,结合分类结果与位置坐标,在地图上呈现异常声音发生的位置与类别。
进一步地,如上所述,涉及对声音信号进行多特征提取。异常声音是一种非周期、非平稳的随机信号,仅用时域或者频域上的一种特征不能充分地对异常声音进行描述。在短时间内,一般为10ms-30ms,异常声音信号可视为一种短时平稳信号,基于此特性,可提取声音信号时域与频域中的多个特征,利用多个特征进行识别,可提高识别率。对异常声音信号进行多特征提取,包括mfcc、短时能量、短时过零率三个特征。
进一步地,如图5所示,mfcc特征提取包括以下步骤:
1)预加重,提升声音信号高频部分,使信号频谱变得平坦;
2)分帧,将声音信号以帧为单位进行处理;
3)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
4)快速傅里叶变换,得到每一帧对应的频谱;
5)mel滤波,将快速傅里叶变换后的频谱通过mel滤波器组转换为体现人类听觉特性的mel频谱;
6)取对数,计算每个滤波器组输出的对数能量;
7)离散余弦变换,对对数能量进行变换,求出mel倒谱系数;
8)提取动态差分参数,用静态特征的差分谱来描述动态特征,有效提高系统的识别性能;
9)取离散余弦变换后的第2到第13个系数与动态差分参数为mfcc特征。
进一步地,如图6所示,短时能量特征提取包括以下步骤:
1)分帧,将声音信号以帧为单位进行处理;
2)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
3)取绝对值,计算出每一帧内的所有样点幅值;
4)计算每一帧内所有样点的短时能量,对所有样点的短时能量求和;
5)取每一帧的短时能量值对应为一个短时能量特征。
进一步地,如图7所示,短时过零率特征提取包括以下步骤:
1)分帧,将声音信号以帧为单位进行处理;
2)加窗,对一帧数据加窗以增加帧左端和右端的连续性;
3)判断每一帧内相邻的两个样点是否具有不同的代数符号,是则发生了过零;
4)计算每一帧内过零的次数;
5)取每一帧内过零的次数对应为一个过零率特征。
进一步地,涉及深度卷积神经网络对异常声音信号的识别,包括以下步骤:
1)建立异常声音特征数据库;
2)将提取到的异常声音的mfcc、短时能量、过零率特征数据输入至深度卷积神经网络;
3)提取的mfcc特征数据与数据库中的mfcc特征数据进行对比,由分类器识别出匹配率最高的类型;
4)提取的短时能量特征数据与数据库中的短时能量特征数据进行对比,由分类器识别出匹配率最高的类型;
5)提取的短时过零率特征数据与数据库中的短时过零率特征数据进行对比,由分类器识别出匹配率最高的类型;
6)综合上述三个特征的对比匹配率及识别类型,得出最佳识别结果。
- 还没有人留言评论。精彩留言会获得点赞!