一种基于KL散度的音频特征提取方法与流程
本发明属于声学技术领域,涉及一种音频特征提取方法,尤其涉及一种基于kl散度的声学场景分类的音频特征提取方法。
背景技术
随着互联网和各种移动终端的快速发展,人们日常可以接触到的视频、音频信息呈爆发性增长。声音承载有关于我们日常环境和物理事件的大量信息。近年来,如何高效利用这些数量大且信息量丰富的音频数据,给我们生活提供更加便利的服务成为迫切需要。声场景分类(acousticsceneclassification,asc)的目标就是通过分析语音片段,判别出该语音所发生的场景,例如沙滩,公园,咖啡馆等。asc是计算机听觉场景分析(computationalauditorysceneanalysis,casa)领域的一种特定任务,它的目标是让计算机像人耳一样能够识别音频发生环境,进而达到感知和理解周边环境的目的。asc的实现主要依靠信号处理技术和机器学习方法达到自动识别音频场景的目的。
正是由于asc可以感知和理解周边环境,因此目前已将它应用到移动终端和可穿戴设备上给人们提供个性化的定制服务。例如将asc运用到机械轮椅上,轮椅会根据感知到所处环境在室内还是室外,自动切换两种服务模式;将asc运用到智能手机设备上,手机会根据感知到使用者所处的环境,将一些设置进行转换,提供更好的用户体验;此外,还将asc运用到军事刑侦等方面。asc性能最后的好坏很大程度由训练模型所用数据集的规模以及提取到的特征所决定。
asc应用前景广泛,2013年起,为了评测现有的环境声音检测方法,电子和电气工程师学会音频和声学信号处理协会(instituteofelectricalandelectronicsengineersaudioandacousticsignalprocess,ieeeaasp)开始举办声学场景和事件的检测与分类挑战赛(detectionandclassificationofacousticscenesandevents,dcase)。其中的任务一就是asc。dcase比赛已经分别于2013年、2016年和2017年举办。在dcase2017的声学场景分类比赛的评测结果显示,前五名均采用了cnn模型。基于卷积神经网络(convolutionalneuralnetwork,cnn)的深度学习方法已经取代传统的基于概率的学习模型成为主流方法。
在asc任务中,一般的方法是信号处理将音频文件转换成特征,然后进行模式匹配。目前在语音处理方面最为广泛使用的特征是基于梅尔滤波器下采样得到的梅尔谱图(melfrequencyspectrogram,mfs)。但梅尔标度是基于人耳的感知特性设计,这种主观测度与声场景模式匹配特性是否契合也是值得研究的问题。
传统的非深度学习的方法提取各种时域和频域特征,提升声场景分类的性能。如2002年,peltonen等人提取过零率、帧短时平均能量等时域特征,子带能量比、谱中心、相邻帧谱变化测度和梅尔频率倒谱系数(mel-frequencycepstralcoefficient,mfcc)等频域特征,用高斯混合模型(gaussianmixturemodel,gmm)和k近邻(k-nearestneighbor,knn)分类器融合进行声场景识别。
目前主流的基于cnn模型的深度学习方法,使用的特征包括基于梅尔测度的特征谱,常数q变换(constant-q-transform,cqt)谱图,或者直接用语谱图(spectrogram)。梅尔测度特征谱包括对数梅尔能量谱(log-melenergies)和梅尔谱mfs,其中对数梅尔能量谱是梅尔谱幅度的平方取对数。在dcase2017前5名参赛者中,除了第3名外,均采用了梅尔测度的特征。梅尔测度是基于人耳的感知特性的谱降维方法,通过主观实验确定谱分辨率的大小。人耳低频敏感,谱分辨率高;高频感知相对粗糙,谱分辨率渐次降低。dcase2017第3名的参赛者zhengweiping等人实现了基于原始语谱图和cqt谱两种输入的cnn分类算法,cqt也是一种谱降维方法,谱分辨率由低频到高频渐次降低。与基于人耳感知特性的梅尔测度不同,cqt在谱降维时,设定频率和谱分辨率的比例为常数。cqt谱声场景分类的性能比原始语谱图低5%,可能因为cqt谱主要针对音乐信号的谐波特性而设计,而大多数声场景信号的谐波特性并不明显,cqt谱可以作为声场景分类算法的补充特征。dcase2017第1名的参赛者seongkyumun等人实现了基于对数梅尔能量谱和原始语谱图两种输入的cnn分类算法,虽然降维后的梅尔能量谱的谱分辨率降低了6倍,但二者的分类准确率相当。在数据扩充后,对数梅尔能量谱的识别率甚至比原始语谱图高0.5%。由此可见,梅尔测度特征能够比较有效的对原始谱降维。
梅尔测度谱在cnn模型的声场景分类算法中得到普遍应用,但梅尔测度谱是基于人耳感知特性,通过主观实验确定谱分辨率。这种基于感知谱降维提取的特征,很可能并非机器识别声场景分类的关键特征,或者说这种感知谱降维并非为声场景分类量身定制。lulu等人在dcase2017的比赛中提交了基于对数梅尔能量谱和基于声场景类间频域标准差的谱图像特征(acrossscenesfrequencystandarddeviationbasedspectrogramimagefeature,asfstd-sif)两种输入的cnn分类算法。asfstd-sif是基于声场景类间标准差的谱降维方法,实际上是基于训练集的统计特性设计的谱降维方法,asgfsd-sif在评测集上的识别率比对数梅尔能量谱的方法高3.7%。这种为声场景分类设计的统计特征给本发明开拓了新思路,本发明希望寻找能够更好区分类间差异性的度量方法。
上述asfstd的谱降维方法是根据频点数值的类间标准差确定其类间区分的重要性,但标准差对应的是数据集的离散程度,作为类间区分测度存在不足。solomonkullback和richardleibler在信息论和动力系统里面引入相对熵,即kullback-leibler散度(简称kl散度,kldivergence),kl散度是两个概率分布p和q的一个非对称的度量,是量化两种概率分布差异性的方式。因此本发明拟引入kl散度,度量类间差异性,提出基于类间kl散度的谱降维方法,对声场景语谱图进行降维,提取基于kl散度的特征谱,以期更好的区分类间差异性,提升声场景分类的性能。
技术实现要素:
本发明针对数据集的特点,充分挖掘实验数据集中的不同类别数据之间的差异性信息,提出了基于kl散度的音频特征提取方法,使得提取的kl散度统计特征比传统的mel谱特征更加适用于场景分类问题。
本发明所采用的技术方案是:一种基于kl散度的音频特征提取方法,其特征在于,包括以下步骤:
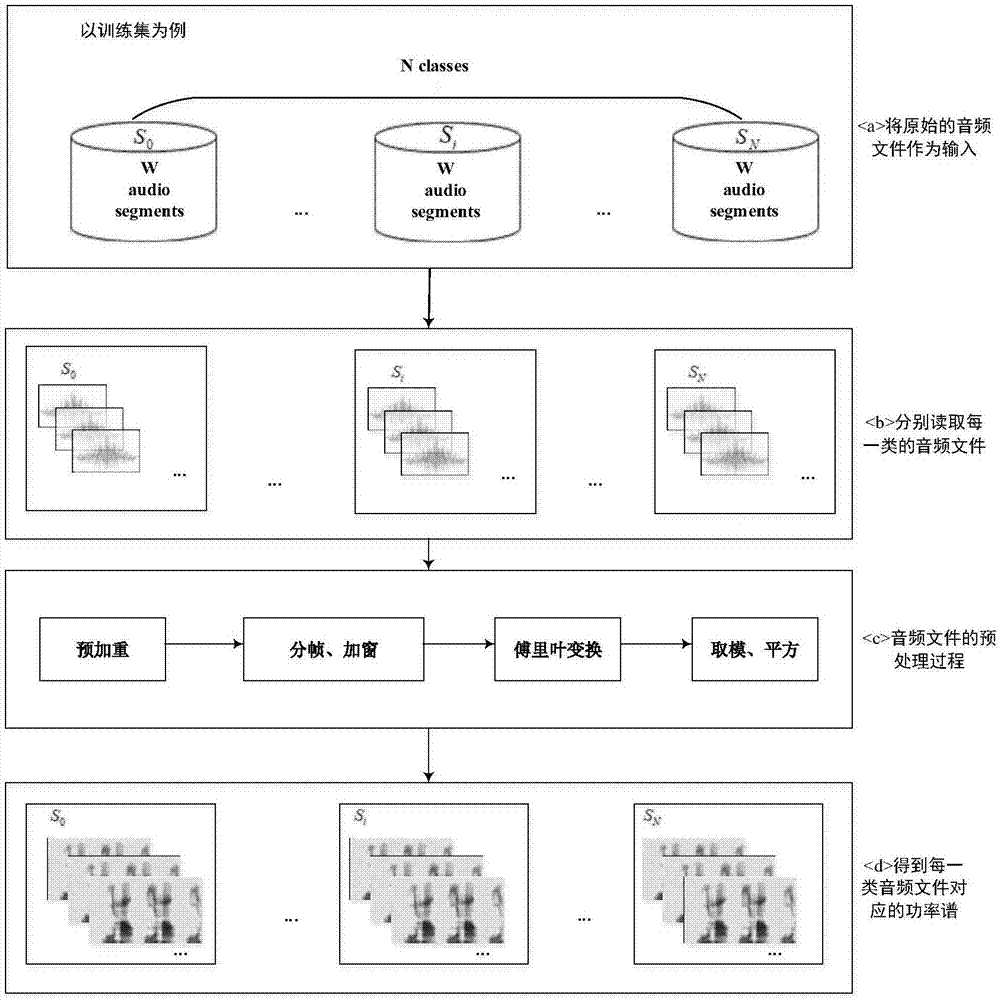
步骤1:读取训练集中原始的音频文件,得到计算机能够处理的时域音频信号数据;
步骤2:将步骤1得到的时域音频信号数据进行预处理;
步骤3:对预处理后的时域音频信号转变为频域信号;
步骤4:计算频域信号的功率谱;
步骤5:将功率谱取对数,并将对数功率谱进行归一化处理,以此得到归一化对数功率谱;
步骤6:利用步骤5得到的归一化对数功率谱设计kl滤波器;
步骤7:将步骤4得到的功率谱通过kl滤波器,得到kl谱特征;
步骤8:对步骤7中求出来的kl谱特征取对数并归一化,得到归一化对数kl谱特征;
步骤9:将步骤8中得到的归一化对数kl谱特征作为网络模型的输入,训练网络模型,验证评估结果;
步骤10:对测试集也进行步骤1~4的操作,然后将步骤4得到的功率谱通过步骤6设计出来的kl滤波器,提取到测试集对应的kl谱特征;
步骤11:将提取的测试集的kl谱特征归一化之后,输入到步骤9训练好的网络模型进行评估,得到在该数据集下的asc分类结果。
本发明方法充分挖掘了数据集中不同声学场景分布之间差异性信息,提取出基于kl散度的音频特征,相比传统的基于人耳的mel特征能更有效地表征音频信号,更适用于音频场景分类问题。
附图说明
图1是本发明实施例的音频信号预处理模块框图;
图2是本发明实施例的基于kl散度滤波器组的总体设计框图;
图3是本发明实施例的场景s1的频点矩阵ai的计算过程示意图;
图4是本发明实施例的基于类间kl散度的频谱特征的提取过程框图;
图5是本发明实施例的cnn网络结构和参数配置示意图;
图6是本发明实施例的训练和验证网络模型使用的四则交叉验证示意图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
本发明提供的方法能够用计算机软件技术实现流程,实施例以数据集dcase2017为例对本发明的流程进行一个具体的阐述。在dcase2017的训练集中,一共有15类声学场景,每一类场景有312段音频文件,每一段音频文件持续时间为10秒,采样率为44.1khz。
本发明提供的一种基于kl散度的音频特征提取方法,具体实施步骤如下:
步骤1:按场景类别读取训练集中的音频文件,将音频文件转换成计算机能够处理的时域数据x(n);
步骤2:对读取的时域音频信号进行预处理。
针对步骤2,本实施例可以采用以下步骤实现:
步骤2a.1:预加重;预加重处理即将时域音频信号通过一个高通滤波器:
h(z)=1-μz-1,本发明取μ=0.95;
其中,μ是常数,表示预加重因子,通常取0.95或0.98。
步骤2a.2:分帧;利用语音信号的短时不变性,将一段10s的语音信号分成一帧一帧的数据进行处理。本发明取帧长为40ms,帧叠为20ms。
步骤2a.3:加窗,即对每一帧语音乘以汉明窗或海宁窗;对分帧后的信号进行加窗处理,以保证分帧后信号的连续性。本发明的窗函数选用海明窗,海明窗公式如下:
其中,n表示离散信号中的抽样点,n表示快速傅里叶变换的点数,本发明设置n=2048。
针对步骤2,本实施例也可以采用以下步骤实现:
步骤2b.1:将时域音频信号进行分帧处理得到xi(m),其中下标i表示分帧后的第i帧;
步骤2b.2:将分帧后的信号进行加窗处理,即对每一帧语音乘以汉明窗或海宁窗。
步骤3:对预处理后的时域音频信号转变为频域信号;
本实施例可以通过快速傅里叶变换(dft)、常数q变换(cqt)或离散余弦变换(dct)将时域音频信号转换为频域信号。
其中,对预处理后的信号进行快速傅里叶变换,变换公式如下:
步骤4:计算频域信号的功率谱;
本实施例计算经过dft后的频域信号取模、平方,得到对应的功率谱|x(k)|2;
经过步骤1~4的处理后,每一类音频文件转化成对应的功率谱。功率谱大小为1025行*501列的矩阵。行数表示时频变换的点数,列数表示分帧后的总帧数。因此每一类场景对应312个大小为1025×501的功率谱矩阵;参见图1。
步骤5:将功率谱取对数,并将对数功率谱进行归一化处理,以此得到归一化对数功率谱;
本实施例对数功率谱进行归一化处理,采用的是z-score标准化,使功率谱中的数据服从均值为0,标准差为1的正态分布。
对数功率谱进行归一化处理,还可以采用的是min-max标准化、z-score标准化、log函数转换或atan函数转换。
步骤6:利用步骤5得到的归一化对数功率谱设计kl滤波器;其中kl滤波器组的总体设计概括图参见图2。
其具体实现包含以下子步骤:
步骤6.1:计算频点矩阵;
以场景s1为例,说明频点矩阵的计算过程,参见图3。
将每个归一化对数功率谱矩阵的相同行rik拼接到一起得到
将在同一频点处的“能量向量”的集合拼接到一起得到频点矩阵ai,如下式所示:(在本实施例中,n=15,l=1025)
步骤6.2:在频点矩阵的基础上计算类间kl矩阵;
对于离散的概率分布p和q,kl散度定义为:
对于形如dkl(p||q)的kl散度而言,其中p为真实分布,q为近似分布,dkl(p||q)的取值越大,说明真实分布p与近似分布q差异性越大;反之,dkl(p||q)的取值越小,说明真实分布p与近似分布q差异性越小。
这是描述两个概率分布p和q差异的一种非对称方法,即:dkl(p||q)≠dkl(q||p)。在实际应用中定义两个概率分布p和q的kl散度j(p,q)为:
对ai矩阵的每一行进行概率分布统计,得到每一个频点处某一类场景与其他类场景的数值概率分布情况,具体公式如下式:(在本案例中,n=15,l=1025)
...
...
其中
接着利用矩阵
其中i=0,1,...,l-1;n=1,2,...,n。
到此为止,n类音频场景在l个频点处的类间kl散度计算完成;
步骤6.3:在类间kl矩阵的基础上划分kl滤波器组的频率群;
对于每个音频场景而言,类间kl矩阵jl×n中的散度值表示该类与其他类的差异信息。因此n个类,在单个频点中存在n个差异信息。本发明取n个kl散度值的平均值以获得每个频点的平均差异性度量:
为了得到m个有交叠的kl散度滤波器组,滤波器带宽间隔为[f(m-1),f(m+1)](m=1,…,m),f(m)为滤波器的中心频率,m表示kl滤波器中三角滤波器个数。
f(m)的计算公式如下:
将上述方法确定的区间[f(m-1),f(m)]的端点作为划分频段的端点值,从而得到基于kl散度划分的频率群:
kl_scale=[f(0),f(1),...,f(m),...,f(m+1)],m=0…m+1;
其中f(0)=0,f(m+1)=l-1;
步骤6.4:按照mel刻度滤波器组hm(k)创建kl散度滤波器组,如下式:
其中,1≤m≤m,m为滤波器的个数;每个滤波器具有三角形滤波特性,其中心频率为f(m);0≤k≤l-1,l表示时频变换的点数;其中
步骤7:将步骤4得到的功率谱通过kl滤波器,得到kl谱特征。
步骤8:对步骤7中求出来的kl谱特征取对数并归一化,得到归一化对数kl谱特征,参见图4;
步骤9:将步骤8中得到的归一化对数kl谱特征作为网络模型的输入,训练网络模型,验证评估结果;
本实施例的网络模型采用的是卷积神经网络(cnn),模型评估方法采用的是四则交叉验证。
网络模型还可以采用卷积神经网络cnn、多层感知机mlp、循环神经网络rnn、lstm、残差网络resnet、支持向量机svm中一种或者多种组合模型。
本实施例中,将步骤8中得到的归一化对数kl谱特征作为卷积神经网络(cnn)的输入,训练cnn模型,四则交叉验证的评估结果。cnn模型及参数配置参见图5;四则交叉验证原理参见图6;
步骤10:对dcase2017的测试集也进行步骤1~4的操作,然后将步骤4得到的功率谱通过步骤6设计出来的kl滤波器,提取到测试集对应的kl谱特征
步骤11:将提取的测试集的kl谱特征归一化之后,输入到步骤9训练好的cnn模型进行评估,得到在该实施例数据集下的asc分类结果。
以上步骤1-11是在dcase2017数据上实施的具体步骤,类似的可以在其他asc数据集上进行相关实验。
本发明利用数据集中不同类别之间的差异性信息,通过在3个音频数据集上进行评估实验,分别提取了本发明提出的基于kl散度的频谱特征和传统的基于人耳的mel谱特征,并比较两者在相应的四则交叉验证的准确率和测试集的准确率,其中,3个数据集的场景类别如表1所示;对应的实验结果如表2所示:
表13个数据集的场景类别说明
表2kl谱特征和mel谱特征的四则交叉验证结果和评测结果
从表中可以看出,3个不同的数据集,使用kl特征的四则交叉验证的平均准确率和测试准确率都比使用mfs特征的准确率高;其中,在dcase2017数据集中,使用kl特征的测试准确率比mfs特征的测试准确率提高了2.2%;在dcase2016中提高3.1%;在litisrouen中提高1.7%;不同的数据集提高的程度不一样,这与数据集中数据本身的分布也有关。由实验结果可以证明,基于类间kl散度的特征提取方法确实能够利用数据集中数据之间的差异性,使用该方法提取出来的音频特征能够在特征提取这一模块提升asc的分类性能。
可以证明,在相同网络模型的条件下,使用kl特征能够进一步提高asc的分类准确率。
本发明主要基于卷积神经网络,考虑数据集中不同类别数据的差异性,提出的一种基于kl散度的音频特征提取方法。本发明充分挖掘了数据间的差异信息,并与传统的mel谱特征进行对比实验。实验结果证明,通过本发明提出的音频特征提取算法能够更适用于音频场景分类问题,获得更高的准确率。
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!