基于关键词改进麦克风阵列远场拾音的方法与流程
本发明涉及语音识别技术领域,特别涉及基于关键词改进麦克风阵列远场拾音的方法。
背景技术:
近年来人工智能呈现爆发式增长,语音交互是人工智能的一个重要领域,而远场语音友好的人机交互方式逐渐成为语音交互的主导方式,如智能音箱、车载语音等;麦克风阵列和远场拾音算法为语音交互提供的高质量语音信号是语音交互的前提。
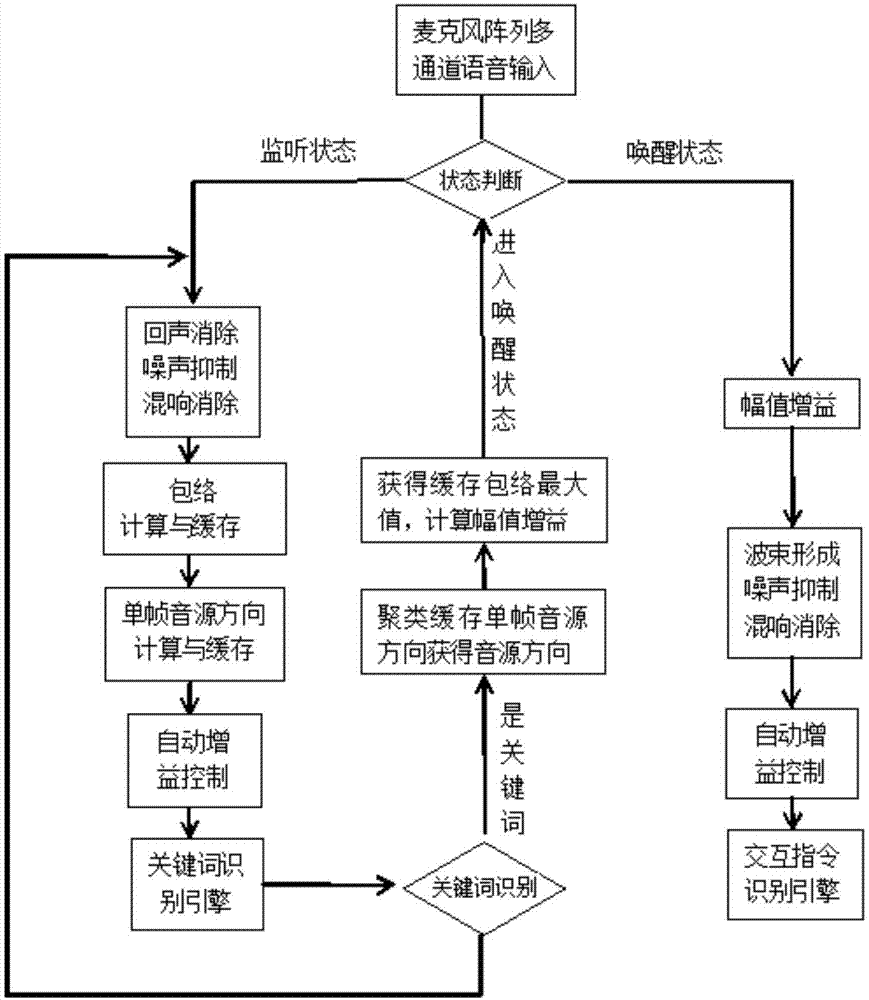
目前主流的远场拾音方式为:设备大部分时候在监听状态下工作,当关键词识别引擎监测到关键词后,设备进入唤醒状态;唤醒状态下,输入语音被识别为各种交互指令;在交互指令完成后,设备回到监听状态。一般情况下,监听状态下的拾音算法包括:回声消除、噪声抑制、混响消除、自动增益控制等;唤醒状态下,通常设备处于静音状态,拾音算法包括:音源定位、波束形成、噪声抑制、混响消除、自动增益控制等。
远场拾音的核心算法是回声消除和波束形成,噪声抑制和混响消除常作为回声消除和波束形成的后处理算法。回声消除算法已近比较成熟了,它通过采集设备自己输出给喇叭的信号作为参考信号,以此来消除麦克风拾取信号中包含的设备自身喇叭发出的声音、从而获得干净的外部输入信号。
波束形成算法是声呐和雷达的核心,旨在拾取目标方向的信号、而其他方向信号则被过滤掉,由于其他方向信号被过滤掉、则拾取到的目标方向信号的信噪比高、目标信号被增强;波束形成算法同样也是麦克风阵列远场拾音的核心,目前主要采用广义旁瓣消除器(gsc)及其改进算法,它需要音源定位算法为它指定期望拾取信号的方向。
音源定位问题分为移动音源定位和固定音源定位,大多数情况下的音源定位属于固定音源定位,如坐在沙发上与远场电视交互时的音源定位,以及车载语音的音源定位等,本专利处理的音源定位针对的就是固定音源。
现在的音源定位算法通常指单帧的音源定位,基本原理是不同方向的信号到达两个麦克风的时间差不同,而通过广义互相关理论可以计算出两个麦克风拾取信号的时间差,典型算法如gcc-phat及其衍生而来的csr-phat,
单帧音源算法通常采用广义互相关最大的方向作为目标音源方向,广义互相关越大对应的方向为正确方向的可能性越大;单帧音源定位算法在信噪比低时,其定位精度低,甚至定位出的是噪声方向,比如:正在进行语音识别时的关门声“砰”,如果将这个方向传递给波束形成,那么波束形成拾取的信号是关门声“砰”。
增益控制分为远场拾音输入信号的增益控制和远场拾音输出信号的增益控制。输入信号的增益控制主要由拾音硬件的放大器完成,需要保证近场交互时语音信号幅值不能被削顶,这使得远场交互时语音幅值往往偏小,这个增益通常在拾音硬件校准后就固定不变了。
由于在远场交互时,输入信号幅值偏小,远场算法处理后的输出信号也就偏小,需要采用agc/drc等自动增益算法调节输出信号的幅值后再将信号送入识别引擎;但这种自动增益算法不能设置较大的调节范围,如果需要放大幅值小的信号,会导致同等水平的背景噪声的放大;而如果对输入信号采用自动增益算法会破坏语音输入信号通道间的相关性,使得基于相关性的多通道算法难以正常工作,如音源定位。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供基于关键词改进麦克风阵列远场拾音的方法,可解决麦克风阵列远场拾音算法中因单帧音源方向不可靠、输入信号幅值低导致语音增强的效果受限的问题,通过缓存关键词的单帧方向信息和幅值包络,在关键词被识别后、综合缓存信息获得可靠的音源方向和合适的幅值增益;有了可靠的音源方向和合适的输入信号幅值,麦克风阵列远场拾音的语音增强效果得到提升,能提高远场语音识别率和改善人耳听觉效果。
为了达到上述的技术效果,本发明采取以下技术方案:
基于关键词改进麦克风阵列远场拾音的方法,包括以下步骤:
a.设定关键词、设定使用单帧音源定算法获得前n个最大可能的方向被缓存,其中,关键词持续时间为x毫秒、信号每帧持续时间为y毫秒、关键词持续的帧数k=x/y,设计长度为k×n的容器1用于缓存音源方向,设计长度为k的容器2用于缓存帧内包络最大值;设定语音信号最大幅值的期望值h;
其中,关键词及其识别引擎通常是针对特定产品专门定制的,关键词通常是很少出现在日常语言中、能代表产品个性的特殊词语,如“某某小白”、“某某同学”、“某某叮咚”等等;关键词识别引擎则是专门用于识别关键词的识别引擎,关键词及其识别引擎的细节不在本申请的技术方案的讨论范围内,而是直接使用;
b.在处于监听状态下,通过麦克风阵列采集一帧信号,信号依次经回声消除、噪声抑制、混响消除处理;
c.实施单帧音源定位算法,取前n个最大可能的方向,将这n个方向存入容器1,容器1中最先存入的n个方向则被挤出容器;
本申请的技术方案中是获取最大可能的前n个方向进行缓存,而不是仅仅取第一个方向,例如获取前2个方向,那么一个方向可能为音源方向、另一个可能为噪声方向;其中,缓存方向的容器可以采用如遵循先进先出规则的队列等,新获取的一组方向存入队列时,最旧的那组方向被挤出队列;
d.计算信号包络,将帧内包络最大值存入容器2,容器2中最先存入的帧内包络最大值被挤出容器;
e.信号经自动增益控制后送入关键词识别引擎;
f.判断关键词是否被关键词识别引擎识别出,如果没有则返回步骤b继续处理,如果关键词被识别出则进入步骤g;
g.取出容器1中缓存的k×n个方向,采用聚类算法对这k×n个方向进行聚类分析,其中,聚类算法的类数设置为m,采用总隶属度最大的类的中心作为最终的音源方向o;
当关键词识别引擎监测到关键词后,采用现有聚类算法对关键词从开始到结束时缓存的所有方向进行聚类分析,聚类算法能将缓存方向中的音源方向和噪声方向分别聚合在一起,最终采用总隶属度最大的类的中心作为最终的音源方向;
h.筛选出容器2中的k个值的最大值作为包络最大值,设定语音信号最大幅值的期望值h,期望值h与包络最大值的比值g即作为唤醒状态下远场拾音算法输入信号的增益;
在监听状态下,计算语音信号包络、并缓存帧内包络最大值;缓存方法同音源方向的缓存方法;当关键词识别引擎监测到关键词后,筛选出关键词从开始到结束时缓存的帧内包络最大值的最大值,这个全局最大值可以简称为包络最大值,即筛选出缓存容器中的k个值的最大值;
设定语音信号最大幅值的期望值,期望值与包络最大值的比值,即作为唤醒状态下远场拾音算法输入信号的增益;该增益为固定增益,不会影响语音输入信号通道之间的相关性,音源距离麦克风阵列越远,关键词持续期间的包络最大值越小,远场算法输入信号需要的增益越大,这样才能将输入信号幅值调节到期望值的水平;
i.进入唤醒状态,麦克风阵列采集一帧信号,信号乘以增益g;
j.波束形成指向获得的音源方向o拾取语音信号,处理乘以增益后的信号;
k.信号依次经噪声抑制、混响消除处理;
l.信号经自动增益控制后,送入交互指令识别引擎;
m.交互指令被识别出,则设备响应指令,并返回步骤b;否则返回步骤i;
本发明的方法中,在监听状态下,回声消除、噪声抑制、混响消除等算法之后,自动增益控制之前,加入单帧音源方向计算与加入信号包络计算、并对单帧音源方向与包络进行缓存;在关键词被关键词识别引擎监测到后,首先对缓存的单帧音源方位进行聚类运算获得可信度较高的音源方位,然后使用信号包络最大值计算远场拾音算法的输入信号增益,再将设备切换到唤醒状态;在唤醒状态下,算法包含输入信号增益调整、波束形成、噪声抑制、混响消除、自动增益控制等,此时自动增益控制可以设置较小的调整范围,避免放大作为背景噪声的低幅值信号,实现在监测到目标关键词时,根据关键词确定出唤醒状态下的音源方向和输入信号幅值增益,以此来提高麦克风阵列远场拾音的语音增强效果。
进一步地,所述步骤c中的单帧音源定位算法为srp-phat声源定位算法。
进一步地,所述步骤c中n的取值不小于1。
进一步地,所述步骤g中的聚类算法为模糊c-均值聚类算法。
进一步地,所述步骤g中的m取值为3。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于关键词改进麦克风阵列远场拾音的方法中,通过关键词获得的音源方向比单帧音源方向要更可靠,能够减少唤醒状态下波束形成算法中语音成分的损失;在唤醒状态下为输入信号增加固定增益,虽然语音和背景噪声被同时放大,但经过远场拾音算法的处理、背景噪声会被抑制到较低水平,拾音算法输出信号的自动增益算法就不用去放大幅值小的信号了、也就不存在将噪声一起放大的问题;语音损失的减少与合理的信号幅值改善了远场语音交互时的语音识别率和人耳听觉效果;具有算法复杂度低,cpu占用少的优点,可以提高麦克风阵列远场拾音的语音增强效果,即提高语音识别率和改善人耳听觉效果。
附图说明
图1是本发明的基于关键词改进麦克风阵列远场拾音的方法的流程示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
未采用本发明时,监听状态下的拾音流程:回声消除、噪声抑制、混响消除、自动增益控制等,唤醒状态下的拾音流程:音源定位、波束形成、噪声抑制、混响消除、自动增益控制等。
采用本发明时,监听状态下的拾音流程:回声消除、噪声抑制、混响消除、单帧音源方向计算与缓存、信号包络计算与缓存、自动增益控制等.
当关键词识别引擎识别到目标关键词时,采用模糊c均值聚类算法获得音源方向,计算唤醒状态下的信号幅值增益,然后切换到唤醒状态;在唤醒状态下,对输入信号进行增益后,波束形成指向目标音源方向对语音进行增强,然后依次进行噪声抑制,混响消除,自动增益控制等;如图1所示,该方法具体步骤如下:
步骤1:初始化;
设关键词为“某某某某”,关键词持续时间为x毫秒,信号每帧持续时间为y毫秒,关键词持续的帧数k=x/y;
设定使用单帧音源定算法获得前n个最大可能的方向被缓存;设计长度为k×n的队列1用于缓存音源方向,设计长度为k的队列2用于缓存帧内包络最大值;设定语音信号最大幅值的期望值h;
步骤2:处于监听状态下,麦克风阵列采集一帧信号,信号依次经回声消除、噪声抑制、混响消除处理。
步骤3:实施单帧音源定位算法,如srp-phat,取前n个最大可能的方向,将这n个方向存入队列1,队列1中最旧的n个方向被挤出队列;本实施例中n可以等于2。
步骤4:计算信号包络,将帧内包络最大值存入对列2,队列2中最旧的帧内包络最大值被挤出队列。
步骤5:信号经自动增益控制后,送入关键词识别引擎。
步骤6:判断关键词是否被关键词识别引擎识别出,如果没有则返回步骤2继续处理,如果关键词被识别出则进行步骤7。
步骤7:取出队列1中缓存的k×n个方向,采用聚类算法如模糊c均值聚类对这k×n个方向进行聚类分析,聚类算法的类数设置为m,最终采用总隶属度最大的类的中心作为最终的音源方向o;m可以等于3。
步骤8:筛选出队列2中的k个值的最大值作为包络最大值,期望值h与包络最大值的比值g即作为唤醒状态下远场拾音算法输入信号的增益。
步骤9:进入唤醒状态,麦克风阵列采集一帧信号,信号乘以增益g。
步骤10:波束形成指向音源方向o,处理乘以增益后的信号。
步骤11:信号依次经噪声抑制、混响消除处理。
步骤12:信号经自动增益控制后,送入交互指令识别引擎。
步骤13:交互指令被识别出、设备响应指令,然后再从步骤2执行;否则从步骤9继续进行。
由上可知,本发明的技术方案可在监测到目标关键词时,根据关键词确定出唤醒状态下的音源方向和输入信号幅值增益,并以此来提高麦克风阵列远场拾音的语音增强效果。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!