一种基于等长熵码字替换的压缩音频自适应隐写方法和系统与流程
本发明涉及一种信息隐藏技术,尤其是涉及一种以mp3等压缩音频为载体的信息自适应嵌入及提取的方法和系统。
背景技术:
随着互联网信息技术的迅速发展,信息安全问题日益严重,已经成为当前社会的热点,并引起学术界的重视。隐写术是确保信息安全传输、实现隐蔽通信的重要方法,是信息安全领域的重要分支。隐写术主要是通过隐藏通信行为实现秘密信息的安全传输,它将秘密信息嵌入到数字媒体文件,如音视频、图像和文档,并且不会引起原始载体的视觉和听觉上的感知失真,使秘密信息在不引起第三方注意的情况下完成传递。
音频作为最常见的多媒体形式之一,是一种良好的信息隐藏载体。目前,已有多种音频隐写方法适用于时域音频和压缩域音频。由于时域音频需要较大的存储空间和传输带宽,给存储和传播带来挑战,因此互联网上的音频多数以mp3和aac等压缩格式存在。鉴于压缩格式音频的广泛传播和使用,以压缩格式音频为载体的隐写算法具有较大的实用价值。压缩域音频隐写算法已经逐渐成为音频隐写的研究重点。英国剑桥大学的petitcolas开发的mp3stego成为最经典、使用最广泛的mp3隐写软件之一。mp3stego算法通过调整量化编码块长度的奇偶性来实现信息嵌入。严迪群等人为解决mp3stego算法在低码率嵌入下的死循环问题,提出了改进的基于量化步长奇偶性的隐写方法(参考文献:严迪群.压缩域音频隐写与隐写分析中若干问题的研究[d].宁波大学,2012)。此外,严迪群等人还提出了基于码字替换的大容量隐写算法(参考文献:yandq,wangrd,zhanglg.ahighcapacitymp3steganographybasedonhuffmancoding[j].journalofsichuanuniversity,2011,48(6):1281-1286)。张垚等人提出了直接修改小值区哈夫曼码字的隐写算法(参考文献:张垚,潘峰,申军伟.基于mp3的后置式自适应隐写算法[j].计算机科学,2016,43(8):114-117)和基于哈夫曼码表索引的隐写算法(参考文献:张垚,潘峰,申军伟.基于mp3的内嵌型自适应隐写算法[j].计算机工程与设计,2016,37(6):1537-1542)。董亚坤提出了基于符号位修改的mp3隐写算法和基于linbits位修改的mp3隐写算法(参考文献:董亚坤.基于mp3的信息隐藏技术研究[d].北京邮电大学,2015)。相关的发明专利主要包括:中国发明专利cn103106901b提出了基于音频颗粒索引值的mp3隐写方法;中国发明专利cn102097098a提出了以窗口类型切换规则为依据的压缩域音频隐写方法;中国发明专利cn106228981a提出了一种直接修改频域量化系数的mp3自适应隐写算法。
经分析,已有针对mp3的隐写算法存在安全负载率低和抗检性差等问题。例如,针对mp3stego等算法的检测正确率已经能达到90%以上(参考文献:陈益如,王让定,严迪群.基于huffman码表索引的mp3stego隐写分析方法[j].计算机工程与应用,2012,48(9):124-126;王让定,羊开云,严迪群,等.一种针对mp3stego隐写后的音频的隐写检测方法,cn104282310a[p].2015)。
技术实现要素:
针对现有mp3等压缩音频隐写方法容量低和安全性差等问题,本发明提出了一种基于等长熵码字替换的压缩音频自适应隐写方法和系统。
本发明所述“等长熵”是指哈夫曼编码表中码字长度相等的码字集合所具备的一种属性,它反映了码字在编码过程中出现的统计频次相等或很接近。该方法通过构造特定的哈夫曼码字空间,生成可相互替换哈夫曼码字对,并对所有可隐写码字进行奇偶分配,以码字奇偶分配后的二进制串为载体进行信息嵌入。信息嵌入之前,以心理声学模型中人耳静音阈值为依据构造合理的代价函数,计算每个可嵌入点的修改代价。信息嵌入以stc(syndrome-trelliscodes)编码实现,结合每个嵌入点的修改代价,实现最优路径选择,使得嵌入总失真最小。本发明能够实现大容量隐写,能够满足实际应用的需求,并且实验证明本发明设计的自适应隐写方法在较高负载率下也能有效抵抗现有的多种mp3等压缩音频隐写分析方法,具有较好的抗检性。
本发明是一种自适应隐蔽通信方法,能在大容量隐写的前提下达到较高的安全性,它主要包括秘密信息嵌入和信息提取两部分。
秘密信息嵌入部分发生在mp3等压缩音频的音频编码过程中量化编码之后和哈夫曼编码之前,在音频编码的过程中实现信息的嵌入操作,包括如下子步骤:
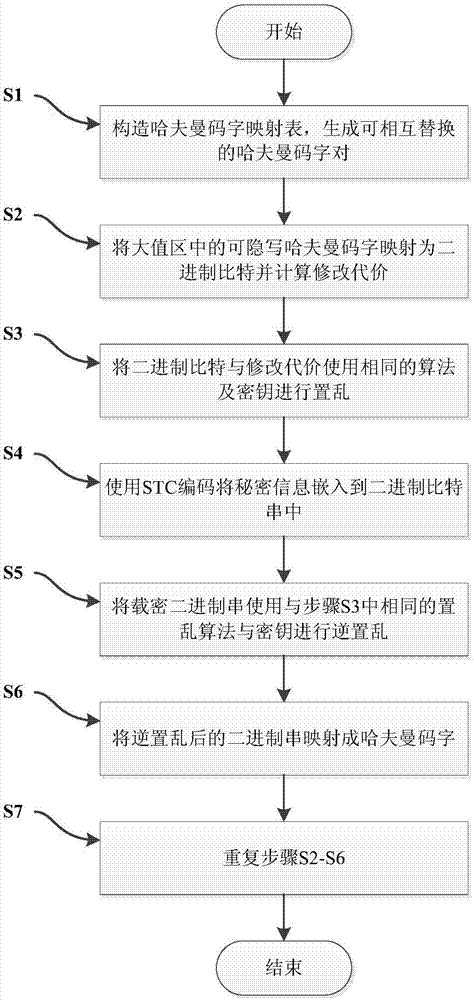
(s1)构造哈夫曼码字映射表,生成可相互替换的哈夫曼码字对。在任意哈夫曼编码表内,两个哈夫曼码字相互替换必须满足三个条件,即码字长度相等、码字对应系数符号位个数相等、码字linbits位一致。满足以上三个条件的两个哈夫曼码字相互替换不会影响码流的结构和长度,并且不会破坏音频的正常编解码。每一张码表中的哈夫曼码字可以根据此码表内是否存在可与其相互替换的码字,划分为可隐写码字和不可隐写码字。对可隐写码字空间中的哈夫曼码字进行奇偶分配,进一步划分为两个子空间,其中一个子空间中的码字表示比特‘0’,另一个空间中的码字表示比特‘1’。
(s2)mp3编码音频帧包含两个颗粒,每个颗粒包含576个频域系数。编码过程中系数按照顺序被分为大值区、小值区和零值区(mp3编码标准中的术语),本发明中仅使用大值区中的哈夫曼码字进行信息嵌入。针对每个帧音频,根据步骤(s1)构造的哈夫曼码字映射表将两个颗粒中大值区所有的可隐写码字映射为比特串c。在映射过程中,依据心理声学模型与哈夫曼码字对应系数的修改幅度计算所有可隐写码字的修改代价ρ。
(s3)将比特串c和修改代价ρ使用相同的算法及密钥进行置乱。
(s4)使用stc编码进行信息嵌入。stc编码器根据嵌入点的修改代价,自适应的选取最优嵌入路径将秘密信息嵌入到比特串c,使修改总失真最小,得到载密的比特串s。
(s5)使用与步骤(s3)相同的置乱算法与密钥将s进行逆置乱。
(s6)将载密比特串s逆映射成哈夫曼码字。如果当前码字是可隐写码字,则根据步骤(s1)中构造的哈夫曼码字映射表和当前哈夫曼码字,将s中的每个比特逆映射成原始的哈夫曼码字。
(s7)重复步骤(s2)~步骤(s6),直到所有的秘密信息嵌入完成或音频编码结束,生成新的隐藏秘密信息的mp3音频文件。
秘密信息提取部分发生在mp3等压缩音频的音频解码中哈夫曼解码过程和频域系数反量化过程之间,在音频解码的过程中实现信息的提取操作,包括如下子步骤:
(p1)根据嵌入过程步骤(s1)中哈夫曼码字映射表的构造方法构造哈夫曼码字映射表。
(p2)对音频进行部分解码,得到哈夫曼码字。根据哈夫曼码字映射表将每个可隐写码字映射成比特串s(s是载密比特串)。
(p3)使用步骤(s3)中的置乱算法与密钥对s进行置乱。
(p4)使用stc编码从s中提取秘密信息,提取过程使用的参数如生成矩阵的宽度和高度与嵌入过程中使用的参数保持一致。
(p5)重复上述步骤(p2)~步骤(p4),直到音频解码结束或信息完整提取,得到还原的秘密信息。
与上面方法对应地,本发明还提供一种基于等长熵码字替换的压缩音频自适应隐写系统,其包括码字-二进制映射模块、失真函数模块、置乱模块、stc编码模块、逆置乱模块和二进制-码字映射模块;所述码字-二进制映射模块将原始哈夫曼码流转换为二进制比特串;所述失真函数模块根据心理声学模型和系数修改幅度计算每个可嵌入位置的修改代价;所述置乱模块将二进制比特串和修改代价使用相同的置乱算法和密钥进行置乱;所述stc编码模块利用stc编码结合可嵌入位置的修改代价,将待嵌信息嵌入到置乱后的比特串中,得到载密比特串;所述逆置乱模块将载密比特串采用相同的置乱算法和密钥进行逆置乱;所述二进制-码字映射模块将逆置乱后的载密比特串逆映射成原始的哈夫曼码。
进一步地,在提取秘密信息时,所述码字-二进制映射模块根据哈夫曼码字映射表将哈夫曼码字串映射成比特串;所述置乱模块将比特串进行置乱;所述stc编码模块利用stc解码使用stc编码从置乱后的比特串中提取秘密信息。
本发明与现有技术相比的有益效果在于:
(1)本发明中,隐写算法具有更高的安全性。与传统的非自适应mp3隐写算法相比,本发明计算每个可嵌入点的修改代价,并且结合了stc编码实现自适应隐写,每次嵌入选择最佳嵌入路径使修改总失真最小,提高隐写方法的抗隐写分析能力。
(2)本发明与多数传统的mp3隐写算法相比,具有更大的隐写容量。多数mp3隐写方法隐写容量相对较小,难以满足实际应用的需要。本发明中的方法,320kbps码率音频最大隐写容量可达到11kbps,128kbps码率时最大隐写容量也能达到5kbps。
(3)本发明与专利cn106228981a中的音频隐写方法相比,具有更高的嵌入速率。cn106228981a中的自适应隐写方法不能确保一次就嵌入成功,可能需要多次重复嵌入;本发明中的隐写方法不需要迭代嵌入的方式,只需一次嵌入就能成功,降低了嵌入的时间开销。
附图说明
图1是本发明信息隐写方法的实现流程图;
图2是与图1所述方法对应的信息隐写系统的模块构成及工作流程图;
图3是本发明秘密信息隐写过程示意图;
图4是本发明码表空间搜索示意图;
图5是本发明信息提取方法实现流程图;
图6是本发明秘密信息提取过程示意图。
具体实施方式
本发明的基于等长熵码字替换的压缩音频自适应隐写方法包括信息嵌入和信息提取,具体实施详细说明如下。
图1是本发明信息隐写方法的实现流程图,图2是与该方法对应的隐写系统的模块构成及工作流程图。主要可以分为六个模块:码字-二进制映射模块、失真函数模块、置乱模块、stc编码模块、逆置乱模块和二进制-码字映射模块。首先,原始哈夫曼码流hc经过码字-二进制映射模块会被转换为载体比特串c。其次,失真函数模块根据心理声学模型和系数修改幅度计算每个可嵌入位置的修改代价ρ。置乱模块将c和ρ使用相同的置乱算法和密钥进行置乱,得到置乱后的比特串c1和置乱后的修改代价ρ1。接着,stc编码模块利用stc编码结合可嵌入位置的修改代价,将待嵌信息m嵌入到置乱后的比特串c1中,得到载密比特串s1。逆置乱模块将s1采用相同的置乱算法和密钥进行逆置乱,得到比特串s。最后,经过二进制-码字映射模块将s逆映射成原始的哈夫曼码hs。嵌入算法的数学关系式可表示为:
图3是本发明秘密信息隐写过程示意图,显示了本发明在信息嵌入过程中数据流的变化。嵌入操作完成后,最终的载密码流与原始码流相比,有两个码字hk和hk+2发生了改变。信息嵌入方法的具体实现过程如下:
步骤1:基于等长熵码字替换的隐写方法首先要构造哈夫曼码字映射表,在此之前要确定哈夫曼码字可替换的条件。大值区两个频域系数编码后的码流结构,称为一个编码单元,信息嵌入操作不能改变此编码单元的长度和结构,否则会造成编解码错误。假定
(c1)
(c2)
(c3)
根据上述三个条件,哈夫曼码字映射表的详细构造方法如下:
(1)记集合π(k)表示包含第k张码表中所有的哈夫曼码字。
(2)将π(k)分为两个不重叠的子集:
(3)划分
根据哈夫曼码字统计分布特征发现,一般地,两个可相互替换的码字在以zig-zag顺序搜索时距离最近。如图4所示,是第7号哈夫曼码表进行码字空间搜索原理示意图。根据可隐写码字条件(c2),大值区的qmdct系数对被划分为3个子区域r0、r1和r2,每个区域都独立进行搜索,搜索顺序如图4中箭头所示的方向。以长度为8的哈夫曼码字为例,存在h<2,3>、h<3,2>、h<5,1>、h<4,2>、h<2,4>和h<1,5>共六个码字都能同时符合条件(c1)-(c3)。按照zig-zag顺序遍历时,6个码字组成了3个码字对:
其中h的码字-二进制映射过程fctb(h)可以表示为:
相反地,其逆映射二进制-码字映射过程fbtc(m,g)可以表示为:
其中,m表示经过stc编码后的比特值,g表示m对应的哈夫曼码字,
步骤2:计算每一个可嵌入位置的修改代价。信息嵌入操作是基于可隐写码字替换实现的,码字替换操作最终会造成qmdct系数的变化。嵌入点的修改失真主要受两个方面影响,一方面是qmdct系数的修改幅度,另一方面是人耳对qmdct系数频线的听觉灵敏度。
(1)使用哈夫曼码字hi替换为hj时,即从<xi,yi>变成<xj,yj>,qmdct系数对之间的变化可用平面点的曼哈顿距离dij来计算,
dij=|xi-xj|+|yi-yj|
其中,dij越大表示使用这对哈夫曼码字进行隐写嵌入带来的失真越大。
(2)人耳对不同频率的听觉灵敏度可用绝对静音阈值衡量。绝对静音阈值tf是通过大量实验得到的,其数学式可近似表示为,
其中,f表示频率值,tf越小表示人耳对当前频率越敏感。
综合(1)和(2)可得,本发明中隐写方法的代价函数定义为,
其中,i是哈夫曼码字在颗粒中的索引值,ρi表示在第i个哈夫曼码字进行隐写嵌入的失真代价,tf2i表示第2个频线的绝对听觉阈值,σ是定值常量,保证
依据码字映射公式,当前码字h在集合
步骤3:将比特串c和对应的修改代价ρ进行置乱,得到c1和ρ1。本发明中使用logistic混沌映射算法对c和ρ进行置乱,对c和ρ进行置乱时使用相同的代价置乱密钥。置乱的目的是使得嵌入点的代价能够均匀分布,达到更优的嵌入路径选择。
步骤4:利用stc编码,将秘密信息m嵌入到载体c1中,得到载密的比特串s1。嵌入过程可表示为,
s1=stc(c1,m,ρ,height,width)
其中,height和width分别是stc编码器的子矩阵的高度和宽度。stc编码能够根据修改代价选择最优嵌入路径,使得每次嵌入总失真最小。
步骤5:使用步骤3中的混沌置乱算法,并使用相同的密钥将载密串s1进行逆映射得到s,使其次序与原始次序相同。
步骤6:遍历帧,如果大值区哈夫曼码字hi在集合
步骤7:重复上述步骤2~步骤6,直到遍历所有音频帧或秘密消息全部嵌入完成,得到载密mp3音频。
图5是本发明信息提取方法实现流程图。信息提取与信息嵌入是相反的过程,主要分为三个部分,首先在码字-二进制映射模块根据映射表将哈夫曼码字串hs映射成比特串s;其次,将s进行置乱得到s1;最后,利用stc解码从s1中提取信息m。图6是本发明秘密信息提取过程实例示意图,信息提取方法的具体实现过程:
步骤1:使用信息嵌入过程中哈夫曼码字映射表的构造方法生成映射表,具体过程如下:
(1)记集合π(k)表示包含第k张码表中所有的哈夫曼码字。
(2)将π(k)分为两个不重叠的子集:
(3)划分
步骤2:对于每个音频帧,当大值区中的哈夫曼码字在集合
将哈夫曼码字序列映射为比特串s,如果h在集合
步骤3:使用混沌置乱算法对s进行置乱操作,置乱算法密钥设置与嵌入过程置乱算法密钥相同,得到新的比特串s1。
步骤4:使用stc解码器从载密串s1中提取信息,即,
m=stc-1(s1,height,width)
其中,height是stc解码器中子矩阵高度,width是stc解码器中子矩阵宽度。
步骤5:重复上述步骤2~步骤4,直到所有音频帧结束或者信息完全提取。
本发明中,置乱算法和代价函数可以采用其它不同的算法替代,但不影响系统结构和流程。另外,本发明方法同样适用于aac(mpeg-4标准)压缩音频。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!