一种小规模语料DNN-HMM声学模型的制作方法
本发明涉及声学技术领域,更具体的说,尤其涉及一种小规模语料dnn-hmm声学模型。
背景技术
由于深度神经网络在建模中,具有根据数据特点自动提取数据特征、记忆数据特征的特点,同时,对数据的分布不做任何假设,因此被广泛的应用到机器学习中。
所以,在语音识别的声学建模中引入了深度神经网络。
但是,深度神经网络建模时,需要大量的语料数据才能让神经网络得到饱和训练,使得建模的效果才能更好,才能达到实际应用的需要。
小规模语料下训练dnn-hmm声学模型过程中,由于标注数据规模小且数据分布不均衡出现大量初始参数没有更新,模型不能很好描述语料中的语音特征,导致识别率下降的问题。
有鉴于此,针对现有的问题予以研究改良,提供一种利用源语料和目标语料分别训练声学模型,然后将源语料模型隐含层参数迁移到目标语料模型形成初始模型,旨在通过该技术,达到解决问题与提高实用价值性的目的。
技术实现要素:
本发明的目的在于提供一种小规模语料dnn-hmm声学模型,以解决背景技术中提出的小规模语料下训练dnn-hmm声学模型过程中,由于标注数据规模小且数据分布不均衡出现大量初始参数没有更新,模型不能很好描述语料中的语音特征,导致识别率下降的问题。
为实现上述目的,本发明提供了一种小规模语料dnn-hmm声学模型,由以下具体技术手段所达成:
一种小规模语料dnn-hmm声学模型,在dnn-hmm声学模型的小规模语料语音识别主要先对输入的小规模语料语音进行特征提取,利用将提取后的特征对dnn-hmm声学模型进行训练,并得到dnn-hmm声学模型;再利用小规模语料语音对应的文本信息对语言模型训练,得到小规模语料语言模型;利用声学模型、语言模型以及字典构建得到解码器,从而得到整个小规模语料语音识别框架;
整个小规模语料语音识别的步骤包括有训练和识别两个阶段:
训练阶段包括有语音数据库与特征提取、dnn-hmm声学模型、文本数据库、语言模型、字典、语音解码和搜索算法;
识别阶段包括有语音输入、特征提取、语音解码和搜索算法和文本输出;
在小规模语料库下的dnn-hmm声学建模中,首先对小规模语料下dnn-hmm声学模型参数进行迁移训练,并采用两种模型参数迁移方式:(1)同构模型参数迁移;(2)异构模型参数迁移;将同构模型和异构模型给出定义及其参数迁移方法,同时将dnn-hmm模型训练方法与异构模型参数迁移方法进行结合,得出dnn-hmm异构模型的参数迁移训练算法;
(1)同构模型参数迁移:
定义一:模型结构,将深度神经网络的模型结构为m,m=(n,p,f,l),其中n是网络节点n={n_1,n_2,…,n_i,…,n_l},n_i指神经网络中第i层的节点数;p=(w,b),p={p_1^2,p_2^3,…,p_i^(i+1),…,p_(l-1)^l},p_i^(i+1)指神经网络第i层到第i+1层的参数矩阵;w={w_1^2,w_2^3,…,w_i^(i+1),…,w_(l-1)^l},w_i^(i+1)指神经网络第i层到第i+1层的权值矩阵;b指偏置向量b={b_1,b_2,…,b_i,…,b_(l-1)},b_i指中神经网络第i层的偏置向量;f={g(·),o(·)},其中g(·)表示神经网络隐含层的激活函数,o(·)表示神经网络输出层的函数;l指网络深度;
定义二:数据源,ds={xs,ys}和dt={xt,yt},s表示源数据,t表示目标数据,x表示输入训练数据,y表示标签数据;
定义三:同构模型,指源模型ms与目标模型mt的n、l和f相同,表示ms=mt;
定义四:同构模型参数迁移,指在使用源数据ds构建的源模型ms中ws和bs替换目标数据dt构建的目标模型mt中的wt和bt,得到迁移模型tr-m;
当ms=mt时,表明ms模型中ws和bs与mt模型中wt和bt属于同型矩阵,在进行模型参数迁移时可以直接将ms模型中参数矩阵迁移到mt模型参数对应的位置上;
其同构模型参数迁移算法:
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-m,//tr-m表示迁移后模型;
1:initalize(ms);//初始化;
2:ms←train(xs,ys,ms);
3:mt←ms;
4:tr-m←train(xt,yt,mt);
(2)异构模型参数迁移:
定义五:异构模型,指源模型ms与目标模型mt的l相同,f相同,n1到nl-1相同,nl不相同,表示ms<>mt;
定义六:异构模型参数迁移。指在使用源数据ds构建的源模型ms中部分ws和bs对目标数据dt构建的目标模型mt中的wt和bt进行替换,得到迁移模型tr-m;
异构模型下参数迁移:
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-m,//tr-m表示迁移后模型;
1:initalize(ms);
2:ms←train(xs,ys,ms);
3:mt←initalize(mt);
4:
5:tr-m←train(xt,yt,mt);
在异构模型下,由于nl-1不相同,不能直接将源领域数据训练得到的模型参数直接以对应关系迁移目标领域数据训练出来的模型中,增加参数迁移的难度;
dnn-hmm的声学模型训练过程步骤:
步骤一:gmm-hmm的模型训练,得到hmm的初始参数,同时得到对齐的训练语料;
步骤二:根据(1)中对齐语料,按照编号和对齐语料构建dnn语料;
步骤三:使用(2)的语料进行dnn预训练;
步骤四:利用初始的hmm和预训练的dnn构建dnn-hmm初始模型;
步骤五:利用(2)的语料对dnn-hmm进行再一次训练,直到模型的性能优于gmm-hmm模型。
优选的,异构模型参数迁移流程如图3所示,且在dnn-hmm声学模型参数迁移过程图中异构神经网络模型中,ms模型中
优选的,所述dnn-hmm的声学模型训练过程步骤:
步骤一:gmm-hmm的模型训练,得到hmm的初始参数,同时得到对齐的训练语料;
步骤二:根据步骤一中对齐语料,按照编号和对齐语料构建dnn语料;
步骤三:使用步骤二的语料进行dnn预训练;
步骤四:利用初始的hmm和预训练的dnn构建dnn-hmm初始模型;
步骤五:利用步骤二的语料对dnn-hmm进行再一次训练,直到模型的性能优于gmm-hmm模型。
所述首先利用源数据对dnn-hmm模型训练,得到源模型(命名为sdnn);然后,使用目标数据对dnn-hmm模型训练,得到目标模型(命名为tdnn);其中,源数据与目标数据选用不同规模、不同语言数据;最后,将sdnn模型参数迁移到tdnn模型中,经过再一次对迁移后模型的训练得到tr-dnn模型;其dnn-hmm声学模型参数迁移过程如图4所示,在dnn-hmm声学模型参数迁移过程图中,sdnn模型由源数据训练出来,tdnn模型是由目标数据训练出来。图中m∈n1,n∈nl-1,k∈nl,u∈nl,其中sdnn.m=tdnn.m,sdnn.n=tdnn.n,sdnn.k≠tdnn.u,导致
且dnn-hmm异构模型下参数迁移算法:
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-dnn,//tr-dnn表示迁移后dnn模型;
1:initalize(sdnn);
2:sdnn←train(xs,ys,sdnn);
3:tdnn←initalize(tdnn);
4:
5:tdnn.b←sdnn.b;
6:tr-dnn←train(xt,yt,tdnn);。
优选的,所述语音识别声学模型训练采用timit数据对sdnn模型进行训练,而tdnn模型训练使用的数据是藏语语料;所述建模数据主要包含有藏语语音数据、藏语语音对应的文本以及藏语对应的标注文本,其音频的格式为wav、单声道、16khz、比特率为16bit;藏语文本语料存储时采用utf-8编码,存储成txt文件格式。
优选的,所述在计算机测试程序中,主要使用得到的程序为声学特征提取部分的程序以及解码部分的程序,且藏语语音识别测试过程:语音输入-特征提取-语音解码和搜索算法-文本输出。
优选的,所述在计算机进行藏语语音识别的测试时,需先进行特征音频提取的格式进行藏语语音的输入,然后对输入的藏语语音进行特征提取,将提取出来的特征输入到解码器中,解码器就会产生输入的藏语音频对应的藏语文字。
优选的,所述小规模语料基于藏语语料,并将目标语料采用小规模藏语语料库作为目标语料,且实验基于kaldi平台。
由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
本发明参数迁移学习在小规模数据下的参数迁移训练算法,是将该算法应用到dnn-hmm藏语声学模型中进行验证,通过对比不同规模源语料库的大小对参数迁移学习的影响以及神经网络中隐含层层数对迁移学习性能影响这几组实验,实验结果表明:
(1)不同规模的源数据影响着模型对目标数据的建模能力,在对源模型训练时,源数据规模的并不是越大,参数迁移的效果就会越好,而是源数据规模大小受目标数据规模的影响,只有当源数据规模与目标数据规模达到一个合适的比例,参数迁移才能达到一个好的效果。
(2)在模型训练中加入参数迁移的方法,使得迁移后的模型对目标数据拥有更强的建模能力。
(3)隐含层层数影响着迁移学习在藏语语音识别中的效果,随着隐含层层数的增加,参数迁移后模型的学习能力先是提升然后下降,说明了在相同数据量下参数迁移学习能力是有限的。
通过以上这3点,说明了参数迁移方法的有效性,从而有效的解决了本发明在背景技术一项中提出的问题。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
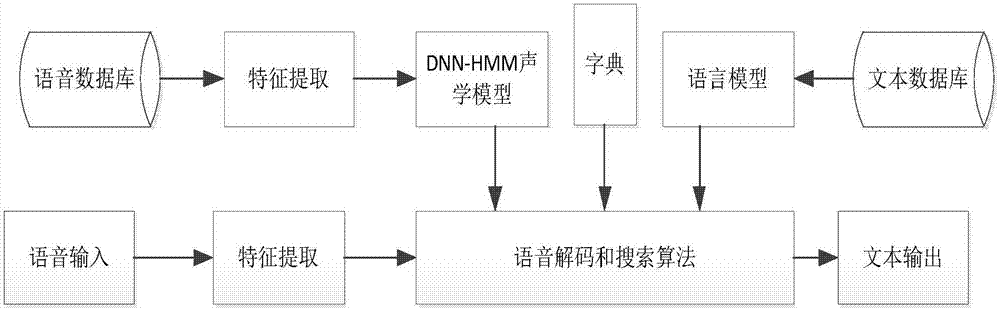
图1为本发明的dnn-hmm声学模型的语音识别的步骤与顺序结构示意图。
图2为本发明的语音识别测试结构示意图。
图3为本发明的异构模型参数迁移过程结构示意图。
图4为本发明的dnn-hmm声学模型参数迁移过程结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
请参见图1至图4,本发明提供一种小规模语料dnn-hmm声学模型的具体技术实施方案:
一种小规模语料dnn-hmm声学模型,其特征在于:在dnn-hmm声学模型的小规模语料语音识别主要先对输入的小规模语料语音进行特征提取,利用将提取后的特征对dnn-hmm声学模型进行训练,并得到dnn-hmm声学模型;再利用小规模语料语音对应的文本信息对语言模型训练,得到小规模语料语言模型;利用声学模型、语言模型以及字典构建得到解码器,从而得到整个小规模语料语音识别框架;
整个小规模语料语音识别的步骤包括有训练和识别两个阶段:
训练阶段包括有语音数据库与特征提取、dnn-hmm声学模型、文本数据库、语言模型、字典、语音解码和搜索算法;
识别阶段包括有语音输入、特征提取、语音解码和搜索算法和文本输出;
在小规模语料库下的dnn-hmm声学建模中,首先对小规模语料下dnn-hmm声学模型参数进行迁移训练,并采用两种模型参数迁移方式:(1)同构模型参数迁移;(2)异构模型参数迁移;将同构模型和异构模型给出定义及其参数迁移方法,同时将dnn-hmm模型训练方法与异构模型参数迁移方法进行结合,得出dnn-hmm异构模型的参数迁移训练算法;
(1)同构模型参数迁移:
定义一:模型结构,将深度神经网络的模型结构为m,m=(n,p,f,l),其中n是网络节点n={n_1,n_2,…,n_i,…,n_l},n_i指神经网络中第i层的节点数;p=(w,b),p={p_1^2,p_2^3,…,p_i^(i+1),…,p_(l-1)^l},p_i^(i+1)指神经网络第i层到第i+1层的参数矩阵;w={w_1^2,w_2^3,…,w_i^(i+1),…,w_(l-1)^l},w_i^(i+1)指神经网络第i层到第i+1层的权值矩阵;b指偏置向量b={b_1,b_2,…,b_i,…,b_(l-1)},b_i指中神经网络第i层的偏置向量;f={g(·),o(·)},其中g(·)表示神经网络隐含层的激活函数,o(·)表示神经网络输出层的函数;l指网络深度;
定义二:数据源,ds={xs,ys}和dt={xt,yt},s表示源数据,t表示目标数据,x表示输入训练数据,y表示标签数据;
定义三:同构模型,指源模型ms与目标模型mt的n、l和f相同,表示ms=mt;
定义四:同构模型参数迁移,指在使用源数据ds构建的源模型ms中ws和bs替换目标数据dt构建的目标模型mt中的wt和bt,得到迁移模型tr-m;
当ms=mt时,表明ms模型中ws和bs与mt模型中wt和bt属于同型矩阵,在进行模型参数迁移时可以直接将ms模型中参数矩阵迁移到mt模型参数对应的位置上;
其同构模型参数迁移算法:
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-m,//tr-m表示迁移后模型;
1:initalize(ms);//初始化;
2:ms←train(xs,ys,ms);
3:mt←ms;
4:tr-m←train(xt,yt,mt);
(2)异构模型参数迁移:
定义五:异构模型,指源模型ms与目标模型mt的l相同,f相同,n1到nl-1相同,nl不相同,表示ms<>mt;
定义六:异构模型参数迁移。指在使用源数据ds构建的源模型ms中部分ws和bs对目标数据dt构建的目标模型mt中的wt和bt进行替换,得到迁移模型tr-m;
异构模型下参数迁移
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-m,//tr-m表示迁移后模型;
1:initalize(ms);
2:ms←train(xs,ys,ms);
3:mt←initalize(mt);
4:
5:tr-m←train(xt,yt,mt);
在异构模型下,由于nl-1不相同,不能直接将源领域数据训练得到的模型参数直接以对应关系迁移目标领域数据训练出来的模型中,增加参数迁移的难度;
dnn-hmm的声学模型训练过程步骤:
步骤一:gmm-hmm的模型训练,得到hmm的初始参数,同时得到对齐的训练语料;
步骤二:根据(1)中对齐语料,按照编号和对齐语料构建dnn语料;
步骤三:使用(2)的语料进行dnn预训练;
步骤四:利用初始的hmm和预训练的dnn构建dnn-hmm初始模型;
步骤五:利用(2)的语料对dnn-hmm进行再一次训练,直到模型的性能优于gmm-hmm模型。
具体的,异构模型参数迁移流程如图3所示,且在dnn-hmm声学模型参数迁移过程图中异构神经网络模型中,ms模型中
具体的,dnn-hmm的声学模型训练过程步骤:
步骤一:gmm-hmm的模型训练,得到hmm的初始参数,同时得到对齐的训练语料;
步骤二:根据步骤一中对齐语料,按照编号和对齐语料构建dnn语料;
步骤三:使用步骤二的语料进行dnn预训练;
步骤四:利用初始的hmm和预训练的dnn构建dnn-hmm初始模型;
步骤五:利用步骤二的语料对dnn-hmm进行再一次训练,直到模型的性能优于gmm-hmm模型。
首先利用源数据对dnn-hmm模型训练,得到源模型(命名为sdnn);然后,使用目标数据对dnn-hmm模型训练,得到目标模型(命名为tdnn);其中,源数据与目标数据选用不同规模、不同语言数据;最后,将sdnn模型参数迁移到tdnn模型中,经过再一次对迁移后模型的训练得到tr-dnn模型;其dnn-hmm声学模型参数迁移过程如图4所示,在dnn-hmm声学模型参数迁移过程图中,sdnn模型由源数据训练出来,tdnn模型是由目标数据训练出来。图中m∈nl,n∈nl-1,k∈nl,u∈nl,其中sdnn.m=tdnn.m,sdnn.n=tdnn.n,sdnn.k≠tdnn.u,导致
且dnn-hmm异构模型下参数迁移算法:
输入:xs,ys,xt,yt,//xs表示源数据,ys表示源数据的标注数据;xt表示目标数据,yt表示目标数据的标签数据,输出:tr-dnn,//tr-dnn表示迁移后dnn模型;
1:initalize(sdnn);
2:sdnn←train(xs,ys,sdnn);
3:tdnn←initalize(tdnn);
4:
5:tdnn.b←sdnn.b;
6:tr-dnn←train(xt,yt,tdnn);。
具体的,语音识别声学模型训练采用timit数据对sdnn模型进行训练,而tdnn模型训练使用的数据是藏语语料;建模数据主要包含有藏语语音数据、藏语语音对应的文本以及藏语对应的标注文本,其音频的格式为wav、单声道、16khz、比特率为16bit;藏语文本语料存储时采用utf-8编码,存储成txt文件格式。
具体的,在计算机测试程序中,主要使用得到的程序为声学特征提取部分的程序以及解码部分的程序,且藏语语音识别测试过程:语音输入-特征提取-语音解码和搜索算法-文本输出。
具体的,在计算机进行藏语语音识别的测试时,需先进行特征音频提取的格式进行藏语语音的输入,然后对输入的藏语语音进行特征提取,将提取出来的特征输入到解码器中,解码器就会产生输入的藏语音频对应的藏语文字。
具体的,小规模语料基于藏语语料,且实验基于kaldi平台。
具体实施步骤:
(1)dnn-hmm声学模型的藏语语音识别的步骤与顺序如图1。
由图1可知,基于dnn-hmm声学模型的藏语语音识别主要流程为先对输入的藏语语音进行特征提取,利用提取后的特征对dnn-hmm声学模型进行训练,得到dnn-hmm声学模型;利用藏语语音对应的文本信息对语言模型训练,得到藏语语言模型;利用声学模型、语言模型以及字典构建得到解码器,从而得到整个藏语语音识别框架。在整个藏语语音识别的步骤包括有训练和识别两个阶段,其中训练部分主要指的是图1中的上半部分,包括有语音数据库、特征提取、dnn-hmm声学模型、文本数据库、语言模型、字典以及语音解码和搜索算法;识别阶段包括有语音输入、特征提取、语音解码和搜索算法和文本输出这几部分。
(2)建模数据主要包含有藏语语音数据、藏语语音对应的文本以及藏语对应的标注文本,其音频的格式为wav、单声道、16khz、比特率为16bit;藏语文本语料存储时采用utf-8编码,存储成txt文件格式。
(3)在计算机测试程序中,主要使用得到的程序为声学特征提取部分的程序以及解码部分的程序。
具体的藏语语音识别测试过程如图2所示。
根据图2可知,在使用计算机进行藏语语音识别的测试时,需先按(2)中音频的格式进行藏语语音的输入,然后对输入的藏语语音进行特征提取,将提取出来的特征输入到解码器中,解码器就会产生输入的藏语音频对应的藏语文字。
综上所述:本发明参数迁移学习在小规模数据下的参数迁移训练算法,是将该算法应用到dnn-hmm藏语声学模型中进行验证,通过对比不同规模源语料库的大小对参数迁移学习的影响以及神经网络中隐含层层数对迁移学习性能影响这几组实验,实验结果表明:
(1)不同规模的源数据影响着模型对目标数据的建模能力,在对源模型训练时,源数据规模的并不是越大,参数迁移的效果就会越好,而是源数据规模大小受目标数据规模的影响,只有当源数据规模与目标数据规模达到一个合适的比例,参数迁移才能达到一个好的效果。
(2)在模型训练中加入参数迁移的方法,使得迁移后的模型对目标数据拥有更强的建模能力。
(3)隐含层层数影响着迁移学习在藏语语音识别中的效果,随着隐含层层数的增加,参数迁移后模型的学习能力先是提升然后下降,说明了在相同数据量下参数迁移学习能力是有限的。
通过以上这3点,说明了参数迁移方法的有效性,从而有效的解决了本发明在背景技术一项中提出的问题。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!