乐器识别方法、介质、装置和计算设备与流程
本发明的实施方式涉及深度学习领域,更具体地,本发明的实施方式涉及乐器识别方法、介质、装置和计算设备。
背景技术:
本部分旨在为权利要求书中陈述的本发明的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
现有的音乐软件的曲库中动辄有上千万的歌曲,对于这些歌曲的归类一般都是基于歌手、国家和类型。如果需要按照音乐的演奏乐器进行分类,则需要采用人工分辨并由人工标注的方式;目前尚不存在成熟的乐器识别算法。而人工识别的方式标记量小,检索的范围也相对较小,无法对曲库中的海量音乐进行乐器识别。
技术实现要素:
在本上下文中,本发明的实施方式期望提供一种乐器识别方法和装置。
在本发明实施方式的第一方面中,提供了一种乐器识别方法,包括:
获取音频样本;
将所述音频样本转换成听觉谱图;
采用卷积神经网络对所述听觉谱图进行识别;所述卷积神经网络的输出为演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述获取音频样本,包括:
获取所述音频文件,将所述音频文件转化为频谱文件,检测所述频谱文件中每一个能量增高超过预设阈值的帧的时间节点;
采用所述时间节点对所述音频文件进行分割,得到多个音频文件片段;
将每个音频文件片段进行固定长度标准化处理,得到所述音频样本。
在一种实施方式中,所述将所述音频样本转换成听觉谱图,包括:
采用基底膜模型和听觉系统内毛细胞meddis模型对所述音频样本进行处理,得到所述听觉谱图。
在一种实施方式中,所述基底膜模型包括n个伽马音调带通滤波器,将所述音频样本分解为n个不同中心频率的通道内容;所述n为2的幂次方;
所述听觉系统内毛细胞meddis模型对所述伽马音调带通滤波器输出的通道内容进行差分操作,并采用积分窗对所述差分操作的结果进行处理。
在一种实施方式中,所述卷积神经网络包括第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层;其中,
所述第一层卷积层的输入内容为所述听觉谱图,输出内容为所述第一层池化层的输入内容;
所述第一层池化层的输出内容为所述第二层卷积层的输入内容;
所述第二层卷积层的输出内容为所述第二层池化层的输入内容;
所述第二层池化层的输出内容为所述第三层卷积层的输入内容;
所述第三层卷积层的输出内容为所述第三层池化层的输入内容;
所述第三层池化层的输出内容为所述全连接层的输入内容;
所述全连接层的输出内容为所述分类层的输入内容;
所述分类层的输出内容为所述演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述全连接层采用640节点的显层和200节点的隐层。
在一种实施方式中,所述分类层采用柔性最大分类器。
在一种实施方式中,所述卷积神经网络是采用反向传播算法训练得到的。
在一种实施方式中,所述卷积神经网络是采用信号丢失方式训练得到的。
在本发明实施方式的第二方面中,提供了一种卷积神经网络训练方法,包括:
获取音频样本;
将所述音频样本转换成听觉谱图;采用所述听觉谱图训练卷积神经网络;所述卷积神经网络的输出为演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述获取音频样本,包括:
获取所述音频文件,将所述音频文件转化为频谱文件,检测所述频谱文件中每一个能量增高超过预设阈值的帧的时间节点;
采用所述时间节点对所述音频文件进行分割,得到多个音频文件片段;
将每个音频文件片段进行固定长度标准化处理,得到所述音频样本。
在一种实施方式中,所述将所述音频样本转换成听觉谱图,包括:
采用基底膜模型和听觉系统内毛细胞meddis模型对所述音频样本进行处理,得到所述听觉谱图。
在一种实施方式中,所述基底膜模型包括n个伽马音调带通滤波器,将所述音频样本分解为n个不同中心频率的通道内容;所述n为2的幂次方;
所述听觉系统内毛细胞meddis模型对所述伽马音调带通滤波器输出的通道内容进行差分操作,并采用积分窗对所述差分操作的结果进行处理。
在一种实施方式中,所述卷积神经网络包括第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层;其中,
所述第一层卷积层的输入内容为所述听觉谱图,输出内容为所述第一层池化层的输入内容;
所述第一层池化层的输出内容为所述第二层卷积层的输入内容;
所述第二层卷积层的输出内容为所述第二层池化层的输入内容;
所述第二层池化层的输出内容为所述第三层卷积层的输入内容;
所述第三层卷积层的输出内容为所述第三层池化层的输入内容;
所述第三层池化层的输出内容为所述全连接层的输入内容;
所述全连接层的输出内容为所述分类层的输入内容;
所述分类层的输出内容为所述演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述全连接层采用640节点的显层和200节点的隐层。
在一种实施方式中,所述分类层采用柔性最大分类器。
在一种实施方式中,所述训练卷积神经网络的方式包括:采用反向传播算法进行训练,将所述卷积神经网络的输出结果与预设的标准进行比对,根据比对结果调整所述卷积神经网络的网络参数。
在一种实施方式中,所述训练卷积神经网络的方式包括:在训练过程中,将所述卷积神经网络中的神经网络单元按照预设的概率进行临时性丢弃。
在本发明实施方式的第三方面中,提供了一种乐器识别装置,包括:
第一样本获取模块,用于获取音频样本;
第一转换模块,用于将所述音频样本转换成听觉谱图;
识别模块,用于采用卷积神经网络对所述听觉谱图进行识别;其中,所述卷积神经网络的输出为演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述第一样本获取模块用于:
获取所述音频文件,将所述音频文件转化为频谱文件,检测所述频谱文件中每一个能量增高超过预设阈值的帧的时间节点;采用所述时间节点对所述音频文件进行分割,得到多个音频文件片段;将每个音频文件片段进行固定长度标准化处理,得到所述音频样本。
在一种实施方式中,所述第一转换模块用于:
采用基底膜模型和听觉系统内毛细胞meddis模型对所述音频样本进行处理,得到所述听觉谱图。
在一种实施方式中,所述第一转换模块采用包括n个伽马音调带通滤波器的所述基底膜模型,将所述音频样本分解为n个不同中心频率的通道内容;所述n为2的幂次方;
所述第一转换模块采用所述听觉系统内毛细胞meddis模型,对所述伽马音调带通滤波器输出的通道内容进行差分操作,并采用积分窗对所述差分操作的结果进行处理。
在一种实施方式中,所述卷积神经网络包括第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层;其中,
所述第一层卷积层的输入内容为所述听觉谱图,输出内容为所述第一层池化层的输入内容;
所述第一层池化层的输出内容为所述第二层卷积层的输入内容;
所述第二层卷积层的输出内容为所述第二层池化层的输入内容;
所述第二层池化层的输出内容为所述第三层卷积层的输入内容;
所述第三层卷积层的输出内容为所述第三层池化层的输入内容;
所述第三层池化层的输出内容为所述全连接层的输入内容;
所述全连接层的输出内容为所述分类层的输入内容;
所述分类层的输出内容为所述演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述全连接层采用640节点的显层和200节点的隐层。
在一种实施方式中,所述分类层采用柔性最大分类器。
在一种实施方式中,所述卷积神经网络是采用反向传播算法训练得到的。
在一种实施方式中,所述卷积神经网络是采用信号丢失方式训练得到的。
在本发明实施方式的第四方面中,提供了一种卷积神经网络训练装置,包括:
第二样本获取模块,用于获取音频样本;
第二转换模块,用于将所述音频样本转换成听觉谱图;
训练模块,用于采用所述听觉谱图训练卷积神经网络;所述卷积神经网络的输出为演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述第二样本获取模块用于:
获取所述音频文件,将所述音频文件转化为频谱文件,检测所述频谱文件中每一个能量增高超过预设阈值的帧的时间节点;采用所述时间节点对所述音频文件进行分割,得到多个音频文件片段;将每个音频文件片段进行固定长度标准化处理,得到所述音频样本。
在一种实施方式中,所述第二转换模块用于:采用基底膜模型和听觉系统内毛细胞meddis模型对所述音频样本进行处理,得到所述听觉谱图。
在一种实施方式中,所述第二转换模块采用包括n个伽马音调带通滤波器的所述基底膜模型,将所述音频样本分解为n个不同中心频率的通道内容;所述n为2的幂次方;
所述第二转换模块采用所述听觉系统内毛细胞meddis模型,对所述伽马音调带通滤波器输出的通道内容进行差分操作,并采用积分窗对所述差分操作的结果进行处理。
在一种实施方式中,所述卷积神经网络包括第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层;其中,
所述第一层卷积层的输入内容为所述听觉谱图,输出内容为所述第一层池化层的输入内容;
所述第一层池化层的输出内容为所述第二层卷积层的输入内容;
所述第二层卷积层的输出内容为所述第二层池化层的输入内容;
所述第二层池化层的输出内容为所述第三层卷积层的输入内容;
所述第三层卷积层的输出内容为所述第三层池化层的输入内容;
所述第三层池化层的输出内容为所述全连接层的输入内容;
所述全连接层的输出内容为所述分类层的输入内容;
所述分类层的输出内容为所述演奏音频文件的乐器的标识,以及所述乐器的标识对应的概率。
在一种实施方式中,所述全连接层采用640节点的显层和200节点的隐层。
在一种实施方式中,所述分类层采用柔性最大分类器。
在一种实施方式中,所述训练模块采用反向传播算法训练卷积神经网络,将所述卷积神经网络的输出结果与预设的标准进行比对,根据比对结果调整所述卷积神经网络的网络参数。
在一种实施方式中,所述训练模块在训练过程中,将所述卷积神经网络中的神经网络单元按照预设的概率进行临时性丢弃。
在本发明实施方式的第五方面中,提供了一种介质,其存储有计算机程序,该程序被处理器执行时实现如本发明实施方式的第一方面所述的方法。
在本发明实施方式的第六方面中,提供了一种介质,其存储有计算机程序,该程序被处理器执行时实现如本发明实施方式的第二方面所述的方法。
在本发明实施方式的第七方面中,提供了一种计算设备,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如本发明实施方式的第一方面所述的方法。
在本发明实施方式的第八方面中,提供了一种计算设备,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如本发明实施方式的第二方面所述的方法。
根据本发明实施方式的乐器识别方法和装置,可以采用卷积神经网络识别音频样本所对应的听觉谱图,从而自动识别出演奏音频文件的乐器,满足对海量音乐的分类需求。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
图1示意性地示出了根据本发明实施方式的识别乐器方法的流程图;
图2示意性地示出了根据本发明实施方式的识别乐器方法中获取音频样本的示例图;
图3示意性地示出了根据本发明实施方式的识别乐器方法中检测时间节点的示例图;
图4示意性地示出了根据本发明实施方式的识别乐器方法中钢琴的听觉谱图和小提琴的听觉谱图的示例图;
图5示意性地示出了根据本发明实施方式的识别乐器方法中卷积神经网络的结构示意图;
图6示意性地示出了根据本发明实施方式的卷积神经网络训练方法的流程图;
图7示意性地示出了根据本发明一实施方式的用于识别乐器方法、以及根据本发明又一实施方式的用于卷积神经网络训练方法的介质示意图;
图8示意性地示出了根据本发明实施方式的乐器识别装置的结构示意图;
图9示意性地示出了根据本发明实施方式的卷积神经网络训练装置的结构示意图;
图10示意性地示出了根据本发明一实施方式的计算设备的结构示意图。
在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
下面将参考若干示例性实施方式来描述本发明的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本发明,而并非以任何方式限制本发明的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
本领域技术人员知道,本发明的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
根据本发明的实施方式,提出了一种乐器识别方法、介质、装置和计算设备,以及一种卷积神经网络训练方法、介质、装置和计算设备。
在本文中,附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。
下面参考本发明的若干代表性实施方式,详细阐释本发明的原理和精神。
发明概述
本发明人发现,目前尚不存在成熟的乐器识别算法,用于识别音乐的演奏乐器。
有鉴于此,本发明实施例提供了一种乐器识别方法和装置,能够将音频样本转换成听觉谱图,再采用卷积神经网络对听觉谱图进行识别,自动识别出演奏音频文件的乐器。这样,无需对音乐采用人工识别的方式,能够满足海量音乐的分类需求。
在介绍了本发明的基本原理之后,下面具体介绍本发明的各种非限制性实施方式。
示例性方法
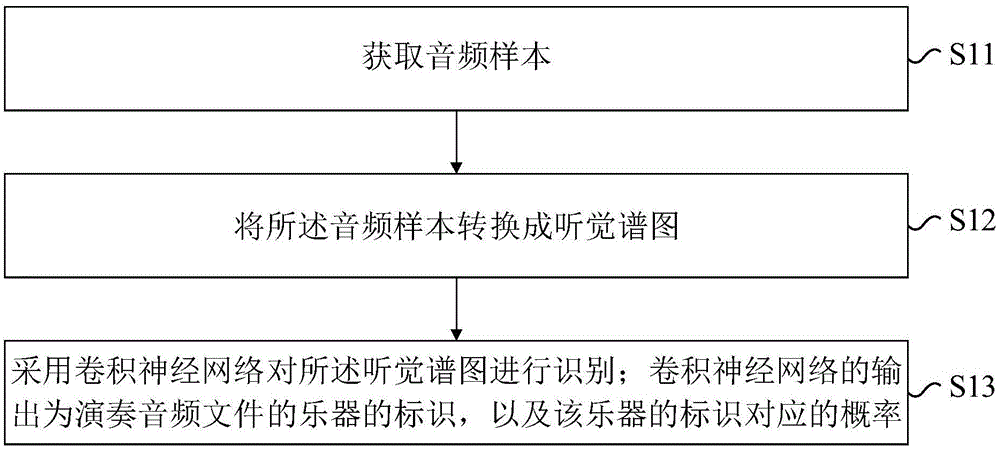
本发明实施例提出一种乐器识别方法。如图1所示,本发明实施例的乐器识别方法可以包括以下步骤:
s11:获取音频样本。
s12:将所述音频样本转换成听觉谱图。
s13:采用卷积神经网络对所述听觉谱图进行识别;该卷积神经网络的输出为演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。
以下结合附图,分别举具体的实施例,对上述各个步骤做详细介绍。
在本实施例中,为了音频文件能够被识别,首先需要将音频文件分割为多个音频样本。各个音频样本的长度相同,也可以不同,并且每个音频样本中均包含能够作为乐器识别依据的音色信息。
为满足上述要求,在一种可能的实施方式中,上述步骤s11的方式可以包括如图2所示的步骤:
s111:获取音频文件,将音频文件转化为频谱文件,检测频谱文件中每一个能量增高超过预设阈值的帧的时间节点。
在本实施例中,可以对音频文件进行短时傅里叶变换(stft,short-timefouriertransform),得到对应的频谱文件;然后根据音频的频谱计算每一帧的能量,找出能量增高超过预设阈值的帧(也就是能量突然变高的帧)的时间节点,该时间节点也就是开始(onset)节点。如图3为本发明实施例中检测onset节点的示意图。在图3中,实线表示的是频谱的能量线,可以看到频谱文件中每一帧的能量是不断变化的;虚线表示的是检测到的onset节点。在音频文件中,onset节点是一个音的开始位置,由于建立音色一般是靠一个音从开始位置产生的0.3秒内的震动信息,因此,可以将音频文件按照onset节点进行分割,将分割之后的文件进一步处理,得到供识别演奏乐器的音频文件。具体为下述步骤s112和s123。
s112:采用上述时间节点对音频文件进行分割,得到多个音频文件片段。
s113:将每个音频文件片段进行固定长度标准化处理,得到音频样本。
由于神经网络需要一个固定长度的输入,因此需要将步骤s112中分割得到的音频文件长度做标准化处理。在本实施例中,标准化处理可以采用2个指标:长度和音量。
针对上述长度指标,标准化处理的方式可以为:由于音频建立音色需要至少0.3秒的长度,在本实施例中,采用2秒作为长度指标。即:对于一个分割得到的音频文件片段,若长度大于2秒,则截取前2秒的文件,作为音频样本;若长度小于2秒,则在其后补充0,补满2秒,作为音频样本。在本发明的其他实施例中,长度指标也可以取其他的具体数值,比如,可以是1.5秒,还可以是2.2秒等等,只要能够保留建立音色需要的长度即可。
针对上述音量指标,标准化处理的方式可以为:为了排除音量对乐器识别结果的影响,本实施例可以截取平均音量高于20分贝的音频文件片段作为音频样本。在本发明的其他实施例中,音量指标也可以取其他的具体数值,只要保证音量不影响乐器识别即可。
通过上述实施例,获取到了用于乐器识别的音频样本,之后,可以对音频样本进行去噪、去除冲击音、人声和背景音乐分离等预处理。
由于卷积神经网络一般用于图像识别,为了使卷积神经网络能够识别音频文件,需要将上述实施例中获取的音频样本转换成图像形式,即,执行上述步骤s12:将音频样本转换成听觉谱图。
在一种可能的实施方式中,上述步骤s12的方式可以包括:
采用基底膜模型和听觉系统内毛细胞meddis模型对音频样本进行处理,得到听觉谱图。
例如,基底膜模型可以包括n个(例如128个)伽马音调(gammatone)带通滤波器,将所述音频样本分解为n个不同中心频率的通道内容,所述n为2的幂次方。每个通道包含乐音的谐波成分随时间变化的信息。
听觉系统内毛细胞meddis模型可以对gammatone带通滤波器输出的通道内容进行差分操作,来模拟侧抑制作用。并采用积分窗对差分操作的结果进行处理,来模拟神经网络的神经元无法对快速变化的信号进行响应的情况。
通过上述过程,音频样本被转换成听觉谱图,如图4为本发明实施例中的一组听觉谱图示意图。其中,左侧为钢琴所演奏音乐的听觉谱图,右侧为小提琴所演奏音乐的听觉谱图。
听觉谱图是卷积神经网络能够识别的形式,可以继续执行上述步骤s13,即采用卷积神经网络对听觉谱图进行识别。
在一种可能的实施方式中,上述步骤s13中采用的卷积神经网络可以包括如图5所示的多个层:第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层。
如图5所示,上述各个层依次连接,各层的输入和输入内容如下所述:
第一层卷积层的输入内容为步骤s12中得到的听觉谱图,输出内容为第一层池化层的输入内容。
第一层池化层的输出内容为第二层卷积层的输入内容。
第二层卷积层的输出内容为第二层池化层的输入内容。
第二层池化层的输出内容为第三层卷积层的输入内容。
第三层卷积层的输出内容为第三层池化层的输入内容。
第三层池化层的输出内容为全连接层的输入内容。
全连接层的输出内容为分类层的输入内容。
分类层的输出内容为演奏音频文件的乐器的标识,以及乐器的标识对应的概率。
在一种可能的实施例中,第一层卷积层采用112个3*3卷积核对输入的数据进行卷积;第一层池化层采用3*3池化窗口对卷积后的数据进行最大值池化,输出112*32*25的数据。
该112*32*25的数据作为第二层卷积层的输入数据,第二层卷积层采用64个3*3卷积核对输入的数据进行卷积;第二层池化层采用3*3池化窗口对卷积后的数据进行最大值池化,输出64*10*8的数据结果。
该64*10*8的数据作为第三层卷积层的输入数据,第三层卷积层采用128个3*3卷积核对输入的数据进行卷积;第三层池化层采用3*3池化窗口对卷积后的数据进行最大值池化,输出128*3*2的数据结果。
通过三层卷积层和池化层的处理,完成了对听觉谱图的特征提取,并保证提取出的特征维度较小。
第三层池化层输出的数据作为全连接层的输入数据,在一种可能的实施方式中,全连接层采用640节点的显层和200节点的隐层,将输入的局部特征结合变成全局特征,用来计算最后每一类的得分。
全连接层输出的数据作为分类层输入数据,在一种可能的实施方式中,分类层采用柔性最大(softmax)分类器,输出演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。至此,卷积神经网络识别出了输入的听觉谱图由各种乐器演奏的概率。
采用本实施例的方法,首先从音频文件中截取包含音色信息的音频样本。之后,基于仿生结构,采用基底膜模型和听觉系统内毛细胞meddis模型对音频样本进行处理,转换成听觉谱图,听觉谱图是卷积神经网络能够识别的图片形式。最后,基于深度学习技术,采用卷积神经网络对输入的听觉谱图进行识别,从而得出演奏音频文件的乐器的标识及其概率。通过这种方式,能够自动识别出演奏音频文件的乐器,满足对海量音乐的分类需求。
本发明实施例还提出一种卷积神经网络训练方法。如图6所示,本发明实施例的卷积神经网络训练方法可以包括以下步骤:
s11:获取音频样本。
s12:将音频样本转换成听觉谱图。
s63:采用听觉谱图训练卷积神经网络;该卷积神经网络的输出为演奏音频文件的乐器的标识,以及乐器的标识对应的概率。
其中,步骤s11和步骤s12与上述实施例中的s11和步骤s12内容相同,不再赘述。
步骤s63中训练的卷积神经网络的结构,与上述实施例中步骤s13中所使用的卷积神经网络的结构相同,不再赘述。
在一种可能的实施方式中,步骤s63中训练卷积神经网络的方式包括:采用反向传播(bp,backpropagation)算法进行训练,将卷积神经网络的输出结果与预设的标准进行比对,根据比对结果调整卷积神经网络的网络参数。本实施例中,针对同一个听觉谱图可以循环遍历100次,根据输出结果与预设标准的对比结果,调整卷积神经网络的网络参数,减小输出结果与预设标准之间的误差。
在一种可能的实施方式中,步骤s63中训练卷积神经网络的方式包括:在训练过程中,将所述卷积神经网络中的神经网络单元按照预设的概率进行临时性丢弃。即,采取信号丢失(dropout)方式来限制卷积神经网络的过拟合问题。
采用本实施例的方法,从音频文件中截取包含音色信息的音频样本;之后,基于仿生结构,采用基底膜模型和听觉系统内毛细胞meddis模型对音频样本进行处理,转换成听觉谱图。听觉谱图是卷积神经网络能够识别的图片形式,因此可以采用听觉谱图训练卷积神经网络,使经过训练的卷积神经网络能够识别出演奏音频文件的乐器,满足对海量音乐的分类需求。
示例性介质
在介绍了本发明示例性实施方式的方法之后,接下来,参考图7对本发明示例性实施方式的介质进行说明。
在一些可能的实施方式中,本发明的各个方面还可以实现为一种计算机可读介质,其上存储有程序,当该程序被处理器执行时用于实现本说明书上述“示例性方法”部分中描述的根据本发明各种示例性实施方式的乐器识别方法中的步骤。
具体地,上述处理器执行上述程序时用于实现如下步骤:获取音频样本;将音频样本转换成听觉谱图;采用卷积神经网络对听觉谱图进行识别;该卷积神经网络的输出为演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。
在一些可能的实施方式中,本发明的各个方面还可以实现为一种计算机可读介质,其上存储有程序,当该程序被处理器执行时用于实现本说明书上述“示例性方法”部分中描述的根据本发明各种示例性实施方式的卷积神经网络训练方法中的步骤。
具体地,上述处理器执行上述程序时用于实现如下步骤:获取音频样本;将音频样本转换成听觉谱图;采用听觉谱图训练卷积神经网络;该卷积神经网络的输出为演奏音频文件的乐器的标识,以及乐器的标识对应的概率采用卷积神经网络对听觉谱图进行识别。
需要说明的是:上述的介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以是但不限于:电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
如图7所示,描述了根据本发明的实施方式的介质70,其可以采用便携式紧凑盘只读存储器(cd-rom)并包括程序,并可以在设备上运行。然而,本发明不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于:电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的程序代码,上述程序设计语言包括面向对象的程序设计语言-诸如java、c++等,还包括常规的过程式程序设计语言-诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络-包括局域网(lan)或广域网(wan)-连接到用户计算设备。
示例性装置
在介绍了本发明示例性实施方式的介质之后,接下来,参考图8和图9对本发明示例性实施方式的装置进行说明。
如图8所示,本发明实施例的乐器识别装置可以包括:
第一样本获取模块801,用于获取音频样本;
第一转换模块802,用于将音频样本转换成听觉谱图;
识别模块803,用于采用卷积神经网络对听觉谱图进行识别;其中,该卷积神经网络的输出为演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。
在一种可能的实施方式中,第一样本获取模块801用于:
获取音频文件,将音频文件转化为频谱文件,检测频谱文件中每一个能量增高超过预设阈值的帧的时间节点;采用所述时间节点对音频文件进行分割,得到多个音频文件片段;将每个音频文件片段进行固定长度标准化处理,得到音频样本。
在一种可能的实施方式中,第一转换模块802用于:
采用基底膜模型和听觉系统内毛细胞meddis模型对音频样本进行处理,得到听觉谱图。
在一种可能的实施方式中,第一转换模块802采用包括n个伽马音调带通滤波器的基底膜模型,将音频样本分解为n个不同中心频率的通道内容;所述n为2的幂次方;
第一转换模块802采用听觉系统内毛细胞meddis模型,对伽马音调带通滤波器输出的通道内容进行差分操作,并采用积分窗对差分操作的结果进行处理。
在一种可能的实施方式中,识别模块803所采用的卷积神经网络包括第一层卷积层、第一层池化层、第二层卷积层、第二层池化层、第三层卷积层、第三层池化层、全连接层和分类层;其中,
第一层卷积层的输入内容为听觉谱图,输出内容为第一层池化层的输入内容;
第一层池化层的输出内容为第二层卷积层的输入内容;
第二层卷积层的输出内容为第二层池化层的输入内容;
第二层池化层的输出内容为第三层卷积层的输入内容;
第三层卷积层的输出内容为第三层池化层的输入内容;
第三层池化层的输出内容为全连接层的输入内容;
全连接层的输出内容为分类层的输入内容;
分类层的输出内容为演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。
在一种可能的实施方式中,全连接层采用640节点的显层和200节点的隐层。
在一种可能的实施方式中,分类层采用柔性最大分类器。
在一种可能的实施方式中,卷积神经网络是采用反向传播算法训练得到的。
在一种可能的实施方式中,卷积神经网络是采用信号丢失方式训练得到的。
如图9所示,本发明实施例的卷积神经网络训练装置可以包括:
第二样本获取模块901,用于获取音频样本;
第二转换模块902,用于将音频样本转换成听觉谱图;
训练模块903,用于采用听觉谱图训练卷积神经网络;该卷积神经网络的输出为演奏音频文件的乐器的标识,以及该乐器的标识对应的概率。
在本实施例中,第二样本获取模块901与上述实施例中的第一样本获取模块801的功能相同,第二转换模块902与上述实施例中的第一转换模块801的功能相同,训练模块903所训练的卷积神经网络与上述实施例中的识别模块803所采用的卷积神经网络相同,不再赘述。
在一种可能的实施方式中,训练模块903采用反向传播算法训练卷积神经网络,将卷积神经网络的输出结果与预设的标准进行比对,根据比对结果调整卷积神经网络的网络参数。
在一种可能的实施方式中,训练模块903在训练过程中,将卷积神经网络中的神经网络单元按照预设的概率进行临时性丢弃。
示例性计算设备
在介绍了本发明示例性实施方式的方法、介质和装置之后,接下来,参考图10对本发明示例性实施方式计算设备进行说明。
本发明实施例提供了一种计算设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序;当上述一个或多个程序被上述一个或多个处理器执行时,使得上述一个或多个处理器实现上述乐器识别方法中的任一方法。
本发明实施例还提供了另一种计算设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序;当上述一个或多个程序被上述一个或多个处理器执行时,使得上述一个或多个处理器实现上述卷积神经网络训练方法中的任一方法。
所属技术领域的技术人员能够理解,本发明的各个方面可以实现为系统、方法或程序产品。因此,本发明的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。
在一些可能的实施方式中,根据本发明实施方式的计算设备可以至少包括至少一个处理单元、以及至少一个存储单元。其中,上述存储单元存储有程序代码,当上述程序代码被上述处理单元执行时,使得上述处理单元执行本说明书上述“示例性方法”部分中描述的根据本发明的各种示例性实施方式的乐器识别方法中的步骤。
在一些可能的实施方式中,根据本发明实施方式的计算设备可以至少包括至少一个处理单元、以及至少一个存储单元。其中,上述存储单元存储有程序代码,当上述程序代码被上述处理单元执行时,使得上述处理单元执行本说明书上述“示例性方法”部分中描述的根据本发明的各种示例性实施方式的卷积神经网络训练方法中的步骤。
下面参照图10来描述根据本发明的实施方式的计算设备100。图10显示的计算设备100仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图10所示,计算设备100以通用计算设备的形式表现。计算设备100的组件可以包括但不限于:上述至少一个处理单元1001、上述至少一个存储单元1002以及连接不同系统组件(包括处理单元1001和存储单元1002)的总线1003。
总线1003包括数据总线、控制总线和地址总线。
存储单元1002可以包括易失性存储器形式的可读介质,例如随机存取存储器(ram)10021和/或高速缓存存储器10022,可以进一步包括非易失性存储器形式的可读介质,例如只读存储器(rom)10023。
存储单元1002还可以包括具有一组(至少一个)程序模块10024的程序/实用工具10025,这样的程序模块10024包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
计算设备100也可以与一个或多个外部设备1004(例如键盘、指向设备等)通信。这种通信可以通过输入/输出(i/o)接口1005进行。并且,计算设备100还可以通过网络适配器1006与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图10所示,网络适配器1006通过总线1003与计算设备100的其它模块通信。应当理解,尽管图中未示出,可以结合计算设备100使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
应当注意,尽管在上文详细描述中提及了装置的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
此外,尽管在附图中以特定顺序描述了本发明方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
虽然已经参考若干具体实施方式描述了本发明的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
应当注意,尽管在上文详细描述中提及了乐器识别装置的若干单元/模块或子单元/模块,以及卷积神经网络训练装置的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
此外,尽管在附图中以特定顺序描述了本发明方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
虽然已经参考若干具体实施方式描述了本发明的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
- 还没有人留言评论。精彩留言会获得点赞!