一种麦克风阵列控制方法、装置及车辆与流程
本发明涉及汽车技术领域,尤其涉及一种麦克风阵列控制方法、麦克风阵列控制装置及车辆。
背景技术:
麦克风阵列(microphonearray)是指由一定数目的声学传感器(一般是麦克风)组成,用来对声场的空间特性进行采样并处理的系统。现有车载语音交互方案中,一般是通过在车内不同位置(如车内主驾驶侧、副驾驶侧和后排中间位置)布置若干个麦克风,在检测到车内语音信号时,唤醒麦克风阵列,并进行声源定位,然后根据声源定位的结果确定是否将对应的麦克风设置为拾音模式,而将其他麦克风设置为辅助降噪模式。
然而,这种语音交互方案中,麦克风阵列控制需要依赖声源定位的结果,且需在声源定位之后进行,从而使得语音交互效果易受声源定位准确率的制约,且对麦克风阵列的工作模式的调整存在较长的时延。
技术实现要素:
本发明实施例的目的在于提供一种麦克风阵列控制方法、麦克风阵列控制装置及车辆,解决了现有麦克风阵列控制方法存在较长时延的问题。
为了达到上述目的,本发明实施例提供一种麦克风阵列控制方法,应用于车辆,所述车辆设置有用于各座椅进行拾音的麦克风阵列,所述方法包括:
检测所述车辆的座椅状态,所述座椅状态包括有乘员或者无乘员;
根据所述座椅状态,设置所述座椅对应的麦克风阵列的工作模式。
可选的,所述麦克风阵列的工作模式包括拾音模式和辅助降噪模式;
所述根据所述座椅状态,设置所述座椅所对应的麦克风阵列的工作模式,包括:
在所述座椅的状态为无乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式;
在所述座椅的状态为有乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述拾音模式。
可选的,所述车辆的座椅设置有压力传感器,所述压力传感器用于检测所述车辆的座椅状态。
可选的,所述拾音模式包括监听唤醒词模式和语音交互模式中的至少一项。
可选的,所述方法还包括:
采用降噪算法,将处于辅助降噪模式的麦克风阵列所获取的语音信号作为降噪参考信号,对处于拾音模式的麦克风阵列所获取的语音信号进行降噪处理。
本发明实施例还提供一种麦克风阵列控制装置,应用于车辆,所述车辆设置有用于对各座椅进行拾音的麦克风阵列,所述麦克风阵列控制装置包括:
检测模块,用于检测所述车辆的座椅状态,所述座椅状态包括有乘员或者无乘员;
设置模块,用于根据所述座椅状态,设置所述座椅对应的麦克风阵列的工作模式。
可选的,所述麦克风阵列的工作模式包括拾音模式和辅助降噪模式;
所述设置模块包括:
第一设置子模块,用于在所述座椅的状态为无乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式;
第二设置子模块,用于在所述座椅的状态为有乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述拾音模式。
可选的,所述车辆的座椅设置有压力传感器,所述压力传感器用于检测所述车辆的座椅状态。
可选的,所述拾音模式包括监听唤醒词模式和语音交互模式中的至少一项。
可选的,所述麦克风阵列控制装置还包括:
降噪模块,用于采用降噪算法,将处于辅助降噪模式的麦克风阵列所获取的语音信号作为降噪参考信号,对处于拾音模式的麦克风阵列所获取的语音信号进行降噪处理。
本发明实施例还提供一种车辆,包括本发明实施例装置所提供的麦克风阵列控制装置。
本发明实施例中,通过检测车辆的座椅状态,以确定车辆的各座椅上是否有乘员,从而可以根据检测结果提前设置各座椅对应的麦克风阵列的工作模式,而无需等待麦克风阵列对车内语音信号进行声源定位之后再进行设置,这样,车内语音交互效果既不会受到声源定位准确率的制约,且可以缩短对麦克风阵列的工作模式的调整时延。
附图说明
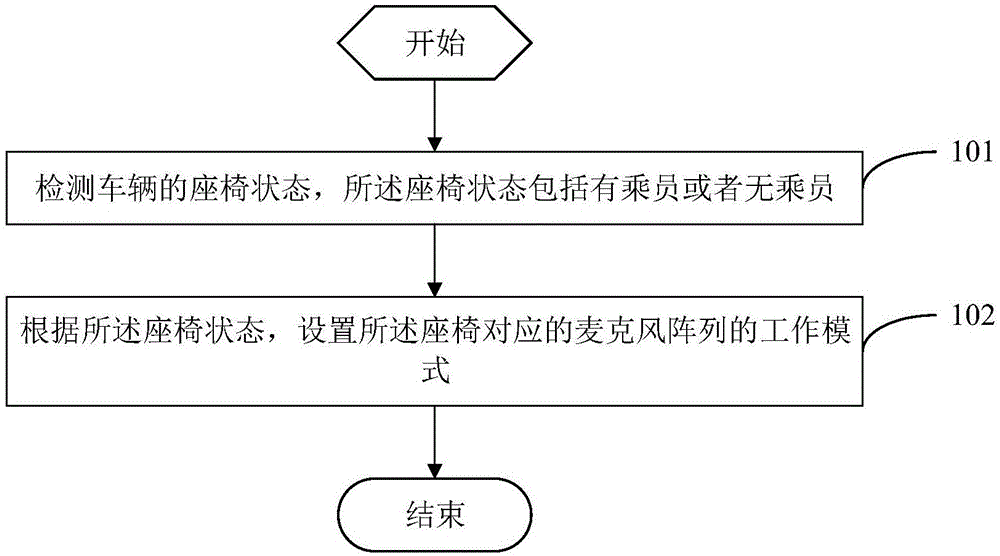
图1为本发明实施例提供的一种麦克风阵列控制方法的流程图;
图2为本发明实施例提供的一种麦克风阵列控制装置的结构示意图;
图3为本发明实施例提供的一种麦克风阵列控制装置的设置模块的结构示意图;
图4为本发明实施例提供的另一种麦克风阵列控制装置的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
参见图1,图1是本发明实施例提供一种麦克风阵列控制方法的流程图,应用于车辆,所述车辆设置有用于对各座椅进行拾音的麦克风阵列,如图1所示,所述方法包括以下步骤:
步骤101、检测车辆的座椅状态。
本实施例中,所述座椅状态包括有成员或者无乘员。所述车辆设置有用于对各座椅进行拾音的麦克风阵列,具体可以是所述车辆的各个座椅旁分别设置有麦克风,用于对对应的座椅处的声源进行拾音,或者是通过麦克风位置、拾音方向的调整,使一个麦克风阵列对多个座位进行拾音,麦克风阵列可至少包括一个麦克风。
上述座椅状态可采用座椅乘坐参数来表征,即座椅乘坐参数可以是用于指示座椅上是否有乘员的参数,例如,可以用“1”表示座椅上有乘员,用“0”表示座椅上没有乘员,检测所述车辆的座椅乘坐参数,可以是检测所述车辆的各个座椅上是否有乘员。
具体地,所述车辆的座椅设置有压力传感器,所述压力传感器用于检测所述车辆的座椅乘坐参数,即可以在所述车辆的各个座椅上设置压力传感器,用于检测各座椅上的座椅乘坐参数。例如,可以在所述车辆的每个座椅内置压力传感器,或者在需要根据座椅乘坐参数设置麦克风阵列的工作模式的座椅内置压力传感器,以通过座椅内的压力传感器检测对应座椅是否有乘员。
其中,当某座椅上的压力传感器的压力检测数据低于预设阈值时,可以判断为该座椅上没有乘员,对应的座椅乘坐参数为“0”,而当某座椅上的压力传感器的压力检测数据高于预设阈值时,可以判断为该座椅上有乘员,对应的座椅乘坐参数为“1”。
步骤102、根据所述座椅状态,设置所述座椅对应的麦克风阵列的工作模式。
上述根据所述座椅状态,设置所述座椅对应的麦克风阵列的工作模式,可以是根据所述所述座椅的座椅乘坐参数,确定所述所述座椅上是否有乘员,然后根据所述座椅上的有无乘员情况,分别设置所述座椅对应的麦克风阵列为不同的工作模式。
例如:若所述座椅乘坐参数指示所述座椅上无乘员,则可以设置所述座椅对应的麦克风阵列的工作模式为辅助降噪模式、休眠模式或低功耗模式,若所述座椅乘坐参数指示所述座椅上有乘员,则可以设置所述座椅对应的麦克风阵列的工作模式为拾音模式或唤醒模式。这样,通过所述座椅乘坐参数,便可设置所述座椅对应的麦克风阵列的工作模式,而无需等待麦克风阵列对车内语音信号进行声源定位后才设置。
可选的,所述麦克风阵列的工作模式包括拾音模式和辅助降噪模式;
所述根据所述座椅状态,设置所述座椅所对应的麦克风阵列的工作模式,包括:
在所述座椅的状态为无乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式;
在所述座椅的状态为有乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述拾音模式。
本实施例中,所述麦克风阵列的工作模式可以包括拾音模式和辅助降噪模式,其中,所述拾音模式可以包括监听唤醒词模式和语音交互模式中的至少一项,所述监听唤醒词模式可以理解为监听车内乘员发出的语音信号中是否包括预设唤醒词的模式,所述语音交互模式则可以理解为与识别车内乘员发出的语音指令,并执行相应的控制操作的模式;所述辅助降噪模式可以理解为采集背景噪声作为降噪参考信号的模式,即不对车内乘员发出的语音信号进行识别,而是仅将采集到的语音信号作为背景噪声以辅助其他麦克风阵列进行降噪。
该实施方式中,在所述座椅上没有乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式,以使该麦克风阵列采集的声音信息,作为降噪参考信号,例如,将采集到的车内背景噪声作为降噪参考信号,传输给降噪算法,以辅助工作于拾音模式的麦克风阵列,提高语音识别准确率。降噪算法利用所述降噪参考信号对接收到的语音信号进行降噪运算,进而提高工作于拾音模式的麦克风阵列的语音识别准确率。
在所述座椅上有乘员的情况下,考虑到所述座椅上的乘员有发出语音指令的需求,因而需要通过所述座椅对应的麦克风阵列采集的声音信号进行语音识别,实现语音控制功能。因此可以将所述座椅对应的麦克风阵列的工作模式设置为所述拾音模式,以保证该麦克风阵列可以接收所述目标座椅上的乘员发出的语音指令,并监听乘员发出的语音指令中是否包含特定的唤醒词,或对乘员发出的语音指令进行识别,进而响应乘员发出的语音指令。
这样,该实施方式中,在目标座椅上没有乘员的情况下,将与所述目标座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式。所述目标座椅上有乘员的情况下,将与所述目标座椅对应的麦克风阵列的工作模式设置为所述拾音模式,从而可以提前设置所述目标座椅对应的麦克风阵列的工作模式,有效缩短工作模式调整时延。
可选的,所述方法还包括:
采用降噪算法,将处于辅助降噪模式的麦克风阵列所获取的语音信号作为降噪参考信号,对处于拾音模式的麦克风阵列所获取的语音信号进行降噪处理。
上述降噪算法可以是预先载入的降噪算法,例如,利用波束成形进行降噪的算法,该实施方式中,在确定所述车辆的各座椅对应的麦克风阵列的工作模式后,可以通过处于辅助降噪模式的麦克风阵列采集车内声音信号,并将采集的声音信号作为所述降噪算法的降噪参考信号,通过处于拾音模式的麦克风阵列获取车内语音信号,并将所采集的语音信号作为待降噪处理的信号,然后通过所述降噪算法,利用所述降噪参考信号对所述待降噪处理的信号进行降噪处理,得到较为清晰的语音信号,进而提高工作于拾音模式的麦克风阵列的语音识别率。
本实施例中,通过压力传感器对座椅的状态进行检测,进而可根据所述座椅状态,提前设置目标座椅对应的麦克风阵列的工作模式,不仅使得各麦克风阵列的工作模式的设置无需依赖于声源定位结果,从而可以有效保证语音识别准确率,而且还能缩短对麦克风阵列的工作模式的调整时延。
本发明实施例中的麦克风阵列控制方法,通过检测车辆的座椅状态,以确定车辆的各座椅上是否有乘员,从而可以根据检测结果提前设置各座椅对应的麦克风阵列的工作模式,而无需等待麦克风阵列对车内语音信号进行声源定位之后再进行设置,这样,车内语音交互效果既不会受到声源定位准确率的制约,且可以缩短对麦克风阵列的工作模式的调整时延。
参见图2,图2是本发明实施例提供的一种麦克风阵列控制装置的结构示意图,应用于车辆,所述车辆设置有用于对各座椅进行拾音的麦克风阵列,如图2所示,麦克风阵列控制装置200包括:
检测模块201,用于检测所述车辆的座椅状态,所述座椅状态包括有乘员或者无乘员;
设置模块202,用于根据所述座椅状态,设置所述座椅对应的麦克风阵列的工作模式。
可选的,如图3所示,所述麦克风阵列的工作模式包括拾音模式和辅助降噪模式;
设置模块202包括:
第一设置子模块2021,用于在所述座椅的状态为无乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述辅助降噪模式;
第二设置子模块2022,用于在所述座椅的状态为有乘员的情况下,将与所述座椅对应的麦克风阵列的工作模式设置为所述拾音模式。
可选的,所述车辆的座椅设置有压力传感器,所述压力传感器用于检测所述车辆的座椅状态。
可选的,所述拾音模式包括监听唤醒词模式和语音交互模式中的至少一项。
可选的,如图4所示,麦克风阵列控制装置200还包括:
降噪模块203,用于采用降噪算法,将处于辅助降噪模式的麦克风阵列所获取的语音信号作为降噪参考信号,对处于拾音模式的麦克风阵列所获取的语音信号进行降噪处理。
麦克风阵列控制装置200能够实现图1所示的方法实施例中麦的各个过程,为避免重复,这里不再赘述。本发明实施例的麦克风阵列控制装置200通过检测车辆的座椅状态,以确定车辆的各座椅上是否有乘员,从而可以根据检测结果提前设置各座椅对应的麦克风阵列的工作模式,而无需等待麦克风阵列对车内语音信号进行声源定位之后再进行设置,这样,车内语音交互效果既不会受到声源定位准确率的制约,且可以缩短对麦克风阵列的工作模式的调整时延。
本发明实施例还提供一种车辆,包括图2至图4所示的任一实施例中所述的麦克风阵列控制装置。本实施例中,所述车辆能达到和图2至图4所示的实施例相同的有益效果,为避免重复,这里不再赘述。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!