基于信息熵及时间趋势分析的音频关注度计算方法及系统与流程
本发明涉及计算机音频处理领域,尤其涉及基于信息熵及时间趋势分析的音频关注度计算方法及系统。
背景技术:
听觉的产生是一个复杂过程,人类注意力资源有限,大脑必须对音频信息进行过滤和选择,有针对性的对部分音频信息产生重点关注,即所谓的音频关注事件。如何让计算机模拟人类听觉的选择关注机制并自动检测音频信号中的高关注度事件成为近年的研究热点。
现有研究方法中,典型的是通过对音频信号进行处理得到听觉图谱,转化为图像领域进行分析,通过相关滤波提取图像的强度、时间对比度等特征,整合不同特征下关注度图得到音频信号的整体关注度;也有基于音频信号双耳强度差、双耳声压差和短时过零率等基本特征进行相关计算得到关注度图,这些解决方式都是基于二维信号的处理,计算量较大且复杂。
上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
本发明的主要目的在于提供一种基于信息熵及时间趋势分析的音频关注度计算方法及系统,旨在解决现有技术中对音频关注度计算是基于二维信号处理,复杂度高的技术问题。
为实现上述目的,本发明提供一种基于信息熵及时间趋势分析的音频关注度计算方法,所述方法包括以下步骤:
获取待计算音频信号;
对所述待计算音频信号进行听觉外周处理,获得第一音频信号;
对所述第一音频信号进行分帧,并计算每帧音频信号的当前信息熵值;
根据所述当前信息熵值基于时间趋势分析算法获得当前关注度;
根据所述当前关注度确定所述待计算音频信号的关注度。
优选地,所述对所述待计算音频信号进行听觉外周处理,获得第一音频信号,具体包括:
对所述待计算音频信号进行类基底膜处理及类内毛细胞处理,获得第一音频信号。
优选地,所述对所述待计算音频信号进行类基底膜处理及类内毛细胞处理,获得第一音频信号,具体包括:
通过具有n个通道的滤波器组对所述待计算音频信号进行滤波处理,得到各通道下的第二音频信号;
将各通道的所述第二音频信号代入内毛细胞模型,获得各通道的发放概率;
将所述各通道的发放概率相加求取平均值并归一化到[-1,1]范围,获得第一音频信号。
优选地,所述滤波器组包括gammatone滤波器组,所述内毛细胞模型包括meddis模型。
优选地,所述对所述第一音频信号进行分帧,并计算每帧音频信号的当前信息熵值,具体包括:
对所述第一音频信号进行分帧,获得每帧音频信号;
将所述第一音频信号进行幅值区间划分,并计算所述每帧音频信号的幅度值落在幅值区间的概率;
根据所述概率基于信息熵计算公式获得每帧音频信号对应的当前信息熵值。
优选地,所述根据所述当前信息熵值基于时间趋势分析算法获得当前关注度,具体包括:
根据所述当前信息熵值基于expma算法获得所述当前关注度。
优选地,所述根据所述当前信息熵值基于expma算法获得所述当前关注度,具体包括:
根据所述当前信息熵值基于expma算法进行计算,获得短期指数平均动量值及长期指数平均动量值;
计算所述短期指数平均动量值与所述长期指数平均动量值的指数平均动量差值;
根据所述指数平均动量差值确定所述当前关注度。
优选地,根据所述当前信息熵值通过以下公式进行计算,获得短期指数平均动量值及长期指数平均动量值:
其中,expma(k,sn)为当前第k帧音频信号在前sn帧范围内的指数平均动量值,即所述短期指数平均动量值,expma(k,ln)为当前第k帧音频信号在前ln帧范围内的指数平均动量值,即所述长期指数平均动量值,ln>sn,h(k)为当前第k帧音频信号的信息熵值。
优选地,根据所述指数平均动量差值通过以下公式确定所述当前关注度:
mk=expma(dif,0.1(ln-sn));
其中,mk为当前第k帧音频信号的关注度,dif为所述指数平均动量差值。
此外,为实现上述目的,本发明还提供一种基于信息熵及时间趋势分析的音频关注度计算系统,所述基于信息熵及时间趋势分析的音频关注度计算系统包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于信息熵及时间趋势分析的音频关注度计算程序,所述基于信息熵及时间趋势分析的音频关注度计算程序配置为实现所述的基于信息熵及时间趋势分析的音频关注度计算方法的步骤。
本发明通过对输入音频信号进行听觉外周处理以达到人耳对声音信号的前期处理效果,对音频信号进行分帧处理并求取每帧信息熵值,利用统计学相关计算原理对整体音频信号熵值进行趋势性分析,最终得到关注度值,本发明技术方案通过复杂性低的计算方式实现了对音频信号中人耳较感兴趣事件进行自动检测,满足目前智能音频等领域的需求。
附图说明
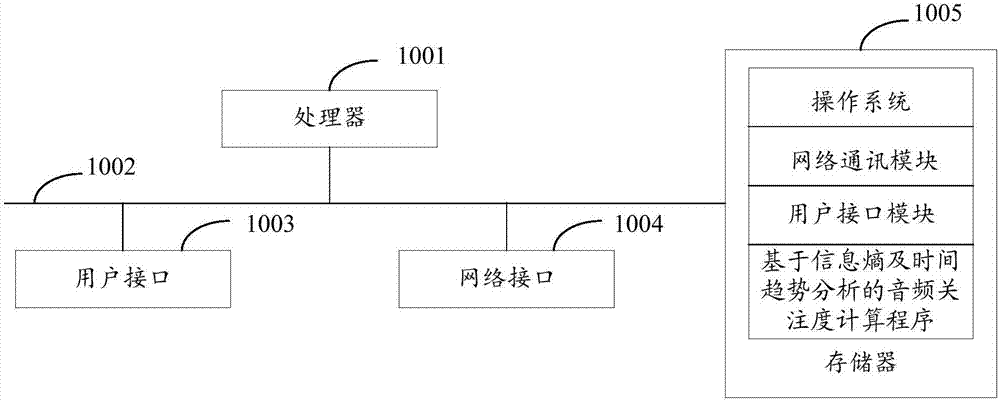
图1是本发明实施例方案涉及的硬件运行环境的基于信息熵及时间趋势分析的音频关注度计算系统结构示意图;
图2为本发明基于信息熵及时间趋势分析的音频关注度计算方法第一实施例的流程示意图;
图3为本发明基于信息熵及时间趋势分析的音频关注度计算系统方法第二实施例的流程示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,图1为本发明实施例方案涉及的硬件运行环境的基于信息熵及时间趋势分析的音频关注度计算系统结构示意图。
如图1所示,该基于信息熵及时间趋势分析的音频关注度计算系统可以包括:处理器1001,例如cpu,通信总线1002、用户接口1003,网络接口1004,存储器1005。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
本领域技术人员可以理解,图1中示出的结构并不构成对基于信息熵及时间趋势分析的音频关注度计算系统的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图1所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及基于信息熵及时间趋势分析的音频关注度计算程序。
在图1所示的基于信息熵及时间趋势分析的音频关注度计算系统中,网络接口1004主要用于与外部网络进行数据通信;用户接口1003主要用于接收用户的输入指令;所述基于信息熵及时间趋势分析的音频关注度计算系统通过处理器1001调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,并执行以下操作:
获取待计算音频信号;
对所述待计算音频信号进行听觉外周处理,获得第一音频信号;
对所述第一音频信号进行分帧,并计算每帧音频信号的当前信息熵值;
根据所述当前信息熵值基于时间趋势分析算法获得当前关注度;
根据所述当前关注度确定所述待计算音频信号的关注度。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
对所述待计算音频信号进行类基底膜处理及类内毛细胞处理,获得第一音频信号。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
通过具有n个通道的滤波器组对所述待计算音频信号进行滤波处理,得到各通道下的第二音频信号;
将各通道的所述第二音频信号代入内毛细胞模型,获得各通道的发放概率;
将所述各通道的发放概率相加求取平均值并归一化到[-1,1]范围,获得第一音频信号。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
对所述第一音频信号进行分帧,获得每帧音频信号;
将所述第一音频信号进行幅值区间划分,并计算所述每帧音频信号的幅度值落在幅值区间的概率;
根据所述概率基于信息熵计算公式获得每帧音频信号对应的当前信息熵值。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
根据所述当前信息熵值基于expma算法获得所述当前关注度。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
根据所述当前信息熵值基于expma算法进行计算,获得短期指数平均动量值及长期指数平均动量值;
计算所述短期指数平均动量值与所述长期指数平均动量值的指数平均动量差值;
根据所述指数平均动量差值确定所述当前关注度。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
根据所述当前信息熵值通过以下公式进行计算,获得短期指数平均动量值及长期指数平均动量值:
其中,expma(k,sn)为当前第k帧音频信号在前sn帧范围内的指数平均动量值,即所述短期指数平均动量值,expma(k,ln)为当前第k帧音频信号在前ln帧范围内的指数平均动量值,即所述长期指数平均动量值,ln>sn,h(k)为当前第k帧音频信号的信息熵值。
进一步地,处理器1001可以调用存储器1005中存储的基于信息熵及时间趋势分析的音频关注度计算程序,还执行以下操作:
优选地,根据所述指数平均动量差值通过以下公式确定所述当前关注度:
mk=expma(dif,0.1(ln-sn));
其中,mk为当前第k帧音频信号的关注度,dif为所述指数平均动量差值。
本实施例通过上述方案,对输入音频信号进行听觉外周处理以达到人耳对声音信号的前期处理效果,对音频信号进行分帧处理并求取每帧信息熵值,利用统计学相关计算原理对整体音频信号熵值进行趋势性分析,最终得到关注度值,通过复杂性低的计算方式实现了对音频信号中人耳较感兴趣事件进行自动检测,满足目前智能音频等领域的需求。
基于上述硬件结构,提出本发明基于信息熵及时间趋势分析的音频关注度计算方法实施例。
参照图2,图2为本发明基于信息熵及时间趋势分析的音频关注度计算方法第一实施例的流程示意图。
在第一实施例中,所述基于信息熵及时间趋势分析的音频关注度计算方法包括以下步骤:
s10:获取待计算音频信号。
应理解的是,所述音频信号为带有语音、音乐和音效的有规律的声波的频率、幅度变化信息载体,音频信号的获取可以由用户输入。
需要说明的是,本实施例的硬件环境包括但不限于:intel(r)core(tm)i5-3210m计算机、8gb内存,运行的软件环境包括但不限于:matlabr2016a和window10。可以通过使用matlab软件实现本实施例提出的方法,当然也可以用其他商业数学软件,本实施例对此不加以限制。
s20:对所述待计算音频信号进行听觉外周处理,获得第一音频信号。
可以理解的是,听觉系统是对声音收集、传导、处理、综合的感觉系统,分为外周部分和中枢部分。外周部分包括外耳、中耳、内耳和听神经,而听觉外周处理,主要包括对中耳和耳蜗基底膜及内毛细胞的模拟,即模拟人耳对音频信号处理进行处理。
具体地,所述听觉外周处理包括类基底膜处理及类内毛细胞处理。
所述类基底膜处理主要是完成中耳、内耳的频率分析和滤波特性,由低通滤波器组构成,类内毛细胞处理主要是完成由基底膜振动到听觉神经发放的变换。
s30:对所述第一音频信号进行分帧,并计算每帧音频信号的当前信息熵值。
需要说明的是,信息熵是信息论中描述信息量多少的指标,音频信号中不同频率能量的信号,其信息熵值存在显著差异。
在具体实现中,对所述第一音频信号进行分帧,获得每帧音频信号;将所述第一音频信号进行幅值区间划分,并计算所述每帧音频信号的幅度值落在幅值区间的概率;根据所述概率基于信息熵计算公式获得每帧音频信号对应的当前信息熵值。
可以理解的是,由于通常获取的音频信号是准稳态信号,而只有稳态的信号才能进行信号处理,所以需要对整段待计算的音频信号进行分帧,对信号进行分帧以后,可以求取每帧音频信号的信息熵值。具体计算方式如下:
幅值区间划分,包括将音频信号归一化后在[-1,1]之间的幅度值进行划分,若划分等距区间数为n,则y={y1,y2,y3...yn}表示整个划分后区间;
概率pi计算,包括计算幅度值落在区间的概率,通过以下公式进行计算:
根据概率pi,通过以下公式获得信息熵值:
其中,k表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集。变量的不确定性越大,信息熵也就越大。
s40:根据所述当前信息熵值基于时间趋势分析算法获得当前关注度。
需要说明的是,人耳听觉产生关注是依赖于对当下的声音感知,同时也依赖于对过去一段时间内的听觉感知,趋势性分析方法就是同时考虑当下和过去信息熵值进行分析。因为人类听觉对音频的关注度会随着时间而下降,比如一段5分钟以前的音频与一段10分钟以前的音频相比,前者往往受到的关注度会更高。考虑到当前和过去一段时间范围内音频信号对当前语音关注的影响,在确定了信息熵值后,需要运用统计学相关方法进行趋势性分析最终得到待计算音频的关注度。
本实施例中,所述时间趋势分析算法为expma算法,所述根据所述当前信息熵值基于时间趋势分析算法获得当前关注度,具体包括以下步骤:
根据所述当前信息熵值基于expma算法进行计算,获得短期指数平均动量值及长期指数平均动量值;计算所述短期指数平均动量值与所述长期指数平均动量值的指数平均动量差值;根据所述指数平均动量差值确定所述当前关注度。
具体地,可以根据所述当前信息熵值通过以下公式进行计算,获得短期指数平均动量值及长期指数平均动量值:
其中,expma(k,sn)为当前第k帧音频信号在前sn帧范围内的指数平均动量值,即所述短期指数平均动量值,expma(k,ln)为当前第k帧音频信号在前ln帧范围内的指数平均动量值,即所述长期指数平均动量值,ln>sn,h(k)为当前第k帧音频信号的信息熵值。
需要说明的是,sn与ln的取值可以自定义,比如,设置sn=40,ln=100,或其他数值,本实施例对此不加以限制。
具体地,可以通过以下公式计算所述短期指数平均动量值与所述长期指数平均动量值的指数平均动量差值:
dif=expma(k,sn)-expma(k,ln),ln>sn;(5)
其中,dif为指数平均动量差值。
具体地,根据所述指数平均动量差值通过以下公式确定所述当前关注度:
mk=expma(dif,0.1(ln-sn));(6)
其中,mk为当前第k帧音频信号的关注度,dif为所述指数平均动量差值。
s50:根据所述当前关注度确定所述待计算音频信号的关注度。
需要说明的是,由于每帧音频信号是由所述第一音频信号分帧得到的,因此计算出每帧音频信号的关注度以后,也得到了所述第一音频信号的关注度值,即所述待计算音频信号的关注度。
本实施例通过对输入音频信号进行听觉外周处理以达到人耳对声音信号的前期处理效果,对音频信号进行分帧处理并求取每帧信息熵值,利用统计学相关计算原理对整体音频信号熵值进行趋势性分析,最终得到关注度值,本发明技术方案通过复杂性低的计算方式实现了对音频信号中人耳较感兴趣事件进行自动检测,满足目前智能音频等领域的需求。
进一步地,如图3所示,基于第一实施例提出本发明基于信息熵及时间趋势分析的音频关注度计算方法第二实施例,在本实施例中,所述步骤s20具体包括:
s21:通过具有n个通道的滤波器组对所述待计算音频信号进行滤波处理,得到各通道下的第二音频信号。
可以理解的是,对所述待计算音频信号进行类基底膜处理,通常是采用一组相互交叠的带通滤波器组实现耳蜗基底膜的频率分解作用,本实施例采用gammatone滤波器组模拟人耳耳蜗的听觉模型,滤波器的通道数n=25,滤波频率范围200hz~5500hz,所述待计算音频信号经过滤波器组滤波后得到25个通道下信号数据。
需要说明的是,所述滤波器组也可以是mel滤波器组,本实施例对此不加以限制。
s22:将各通道的所述第二音频信号代入内毛细胞模型,获得各通道的发放概率。
需要说明的是,所述内毛细胞模型包括但不限于meddis模型,输入各通道的所述第二音频信号后,经过meddis模型中的数学相关表达式可以得到各通道的发放概率v(t)。
s23:将所述各通道的发放概率相加求取平均值并归一化到[-1,1]范围,获得第一音频信号。
可以理解的是,将各个通道的发放概率v(t)相加求取平均值并归一化到[-1,1]范围,生成第一音频信号,有利于后续进行幅值区间划分及信息熵的计算。
本实施例通过具有n个通道的滤波器组对所述待计算音频信号进行滤波处理,得到各通道下的第二音频信号,将各通道的所述第二音频信号代入内毛细胞模型,获得各通道的发放概率,将所述各通道的发放概率相加求取平均值并归一化到[-1,1]范围,获得第一音频信号,实现了将所述待计算音频信号中的信息进行提取和处理,提高了计算的准确性。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,空调器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!