一种基于多模情感识别技术的音视频输出方法与流程
本发明涉及一种基于多模情感识别技术的音视频输出方法,属于检测设备技术领域。
背景技术:
目前人机交互技术得到了迅猛发展,但目前系统的智能化能力还有所欠缺,人机交互还不尽如人意,远远没有达到自然逼真的实际应用要求。鉴于情感在人际交往中的重要性,国内外研究人员近年来进行了许多工作,努力使计算机与人的交互更加自然。而情感计算的研究仍然是一个需要进一步深入研究的领域,存在着许多有待解决与突破的问题,主要包括以下三个方面:第一,各种类型信号特征语义描述的问题。音频,视频和生理信号来自不同采集设备,通常存在不同的捕获速率及不同数据格式的情况。此外,由于多种与情感特征有关的不确定因素,如语言,性别和文化差异等,将影响在不同的情绪状态下对特定情感特征描述的充分性和准确性。第二,多源数据无缝融合的问题。由于多模态特征向量流中不同形态数据存在特征表达分布差异情况,可靠特征信息往往在过程的不同位置出现,导致特征选择的不确定性。而常规策略取决于二阶统计量及最优的高斯分布分析,通常采用线性方法,简单丢弃冗余组件和降低数据维数,缺少分析原始数据特征向量、揭示输入信息自然性质的能力。第三,数据整合优化的问题。
技术实现要素:
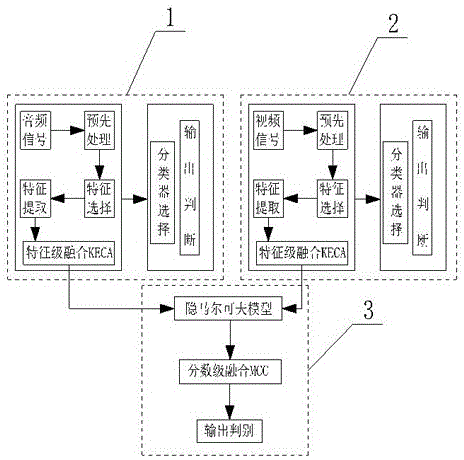
为了克服背景技术中存在的缺陷,本发明解决其技术问题所采用的技术方案是:一种基于多模情感识别技术的音视频输出方法,包括基于音频信号的情感识别系统、基于视频信号的情感识别系统和分数级信息融合优化系统,所述基于音频信号的情感识别系统内的音频信号依次经过预选处理、特征选择和特征提取进入特征级融合keca,所述基于音频信号的情感识别系统内设有分类器选择模块和输出判断模块;所述基于视频信号的情感识别系统内的视频信号依次经过预选处理、特征选择和特征提取进入特征级融合keca,所述基于视频信号的情感识别系统内设有分类器选择模块和输出判断模块;所述基于音频信号的情感识别系统和基于视频信号的情感识别系统内的特征级融合keca与分数级信息融合优化系统的隐马尔可夫模块相连接,所述分数级信息融合优化系统有隐马尔可夫模块、分数级融合mcc模块和输出判断模块组成,所述隐马尔可夫模块依次与分数级融合mcc模块和输出判断模块相连接。
本发明设计了一种基于多模情感识别技术的音视频输出方法,该基于多模情感识别技术的音视频输出方法中将多级信息融合的思想引入到多源信号对情感识别系统特征语义表达的分析过程中,突破常规策略中从单一融合阶段考虑数据流变化对特征描述准确性和可靠性的影响,提出分级融合的计算和分析方法,基于核熵成分分析及最大相关熵校准算法解决多模态生物信号对交互系统的影响及智能情感识别技术中的理论、建模及优化方法问题。
本项目预计创新点归纳为以下三个方面:
1、基于核熵成分分析算法作用于多模态情感信息的语义表达,提出一种新的特征级融合方法。针对不同信号作用于情感信息语义表达的特征多样化、作用过程复杂性,分析显著情感特征的变化规律及特点,构建能够量化情感信息内容,提高特征提取的可分性的新的特征级融合方法。
2、提出最大相关熵校准的最优分数级融合方法。以适应性度量替代二阶统计量进行局域相似性测量,由核函数方法计算参数的概率密度函数并确定数据流的耦合匹配分值,结合优化成本函数实现系统的稳定、最优判别。
3、提出多模态信息双级融合框架,探索复杂生物特征识别领域新思路。情感状态识别是智能人机接口通过对复杂生物特征分析实现的高度模拟人类行为的重要技术手段。双级融合策略针对情感动态表达的准确描述,解决多模态系统信息融合的特定性、复杂性问题,为特定应用情境下多模信息融合系统建模及优化提供理论与方法支撑。
总之,该基于多模情感识别技术的音视频输出方法结构设计合理,输出准确,适合推广使用。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明一种基于多模情感识别技术的音视频输出方法的结构示意图;
其中:1、基于音频信号的情感识别系统;2、基于视频信号的情感识别系统;3、分数级信息融合优化系统。
具体实施方式
现在结合附图对本发明作进一步详细的说明。附图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
具体实施例一,请参阅图1,一种基于多模情感识别技术的音视频输出方法,包括基于音频信号的情感识别系统1、基于视频信号的情感识别系统2和分数级信息融合优化系统3,所述基于音频信号的情感识别系统1内的音频信号依次经过预选处理、特征选择和特征提取进入特征级融合keca,所述基于音频信号的情感识别系统1内设有分类器选择模块和输出判断模块;所述基于视频信号的情感识别系统2内的视频信号依次经过预选处理、特征选择和特征提取进入特征级融合keca,所述基于视频信号的情感识别系统2内设有分类器选择模块和输出判断模块;所述基于音频信号的情感识别系统1和基于视频信号的情感识别系统2内的特征级融合keca与分数级信息融合优化系统3的隐马尔可夫模块相连接,所述分数级信息融合优化系统3有隐马尔可夫模块、分数级融合mcc模块和输出判断模块组成,所述隐马尔可夫模块依次与分数级融合mcc模块和输出判断模块相连接。
本发明设计了一种基于多模情感识别技术的音视频输出方法,该基于多模情感识别技术的音视频输出方法中将多级信息融合的思想引入到多源信号对情感识别系统特征语义表达的分析过程中,突破常规策略中从单一融合阶段考虑数据流变化对特征描述准确性和可靠性的影响,提出分级融合的计算和分析方法,基于核熵成分分析及最大相关熵校准算法解决多模态生物信号对交互系统的影响及智能情感识别技术中的理论、建模及优化方法问题。
本项目预计创新点归纳为以下三个方面:
1、基于核熵成分分析算法作用于多模态情感信息的语义表达,提出一种新的特征级融合方法。针对不同信号作用于情感信息语义表达的特征多样化、作用过程复杂性,分析显著情感特征的变化规律及特点,构建能够量化情感信息内容,提高特征提取的可分性的新的特征级融合方法。
2、提出最大相关熵校准的最优分数级融合方法。以适应性度量替代二阶统计量进行局域相似性测量,由核函数方法计算参数的概率密度函数并确定数据流的耦合匹配分值,结合优化成本函数实现系统的稳定、最优判别。
3、提出多模态信息双级融合框架,探索复杂生物特征识别领域新思路。情感状态识别是智能人机接口通过对复杂生物特征分析实现的高度模拟人类行为的重要技术手段。双级融合策略针对情感动态表达的准确描述,解决多模态系统信息融合的特定性、复杂性问题,为特定应用情境下多模信息融合系统建模及优化提供理论与方法支撑。
总之,该基于多模情感识别技术的音视频输出方法结构设计合理,输出准确,适合推广使用。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!