基于改进长短时记忆网络的婴儿哭声情感识别方法与流程
本发明涉及情感识别
技术领域:
,具体涉及一种基于改进长短时记忆网络的婴儿哭声情感识别方法。
背景技术:
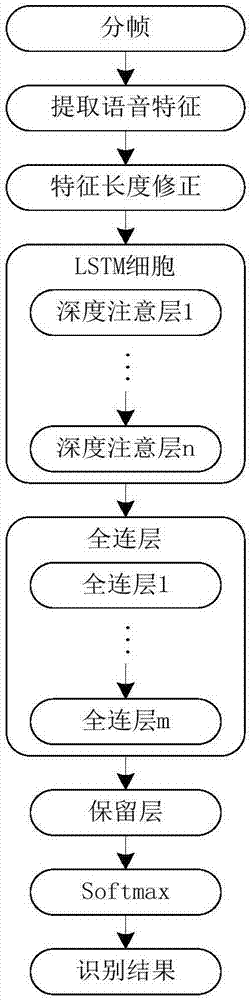
:新生婴儿的啼哭是孩子的一种表达方式,父母及时了解自己宝宝的需求显得异常重要。婴儿出生后的最先几个月内获得的安全感将伴随今后生活,因此及时满足宝宝需求会让孩子更健康的成长。对于一个″呱呱″落地的婴儿来说,其表达情感需求信息的方式有限,基本上只能通过哭和笑来表达需求和心情。然而婴儿通常以笑的方式来表达当时的心情,其传达的信息比较简单明确,一般表示开心、愉悦等心理情感状态。因此,婴儿只能通过哭泣的方式来向父母或者监护人来表达自己的需求。相对于婴儿的笑声来说,哭声相对比较复杂,哭声所传达的信息也是比较模糊的,比如饥饿、痛苦、困倦等,婴儿都可以依靠哭泣方式来向父母或监护人来表达自己的需求。但是,对于一个有经验的保姆来说分清婴儿哭声中所包含的需求尚很困难,更不用说初为人父的青年父母。面对以上种种难题,当前比较好的解决方案是采取人机结合的方式。通过对婴儿在不同需求下啼哭语音进行分析筛选出有效特征,并使用这些特征来进行相关模型的训练,然后将采集到的新的啼哭语音通过已训练好的分类模型来对哭声语音进行分类,从而达到智能识别的目的。通过这种方式,可以减轻父母照顾婴儿的压力,提高年轻父母的生活幸福指数,且还能提高婴儿的生活质量。早在十九世纪中叶,达尔文就进行了婴儿啼哭的相关研究工作,他利用收集到的各种代表婴儿情绪的照片和图表,研究婴儿在不同生理状态和病理状态下所发出哭声的特点。进入21世纪,婴儿哭声相关的研究课题越来越受到相关研究人员的关注。这里列举部分研究工作:1)对婴儿哭声语音进行梅尔频率倒谱系数(mel-frequencycepstralcoefficients,mfcc)提取并将mfcc作为特征向量,然后使用隐马尔科夫模型进行类别的划分,最后对婴儿哭声语音进行识别,从而分辨出婴儿是否处于健康状态;2)通过图像与音频相结合的方式来共同确定婴儿哭声所表达的情感需求;3)将语谱图作为特征向量,选取卷积神经网络作为分类模型,应用于婴儿疼痛、饥饿及困倦等三种状态下的哭声分类;4)将支持向量机作为分类器对婴儿在饥饿、疼痛及困倦等三种状态下的哭声进行分类,得到不错的识别效果。上述工作推动了婴儿哭声情感的研究,但是,也存在一些值得深入研究的问题,具体如下:(1)语音存在长短问题,如果对语音求固定长度的特征,必定会流失时序上的信息;(2)从分类算法看,早期的分类算法效果对特征依赖较大,算法本身不具有特征学习能力。(3)尚缺乏统一的、成熟的婴儿哭声情感需求信息识别的特征描述和分类方法,同时也缺少相应鲁棒性比较好的特征描述及识别算法。因此,如何克服上述问题,是当前急需解决的问题。技术实现要素:本发明的目的是克服现有的婴儿哭声情感识别方法中存在的语音长短不一,以及分类算法效率低等问题。本发明的基于改进长短时记忆网络的婴儿哭声情感识别方法,将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征,并针对不同长度的时序相关特征建立长短时记忆网络的处理算法;然后,将注意力机制结合时序的深度的策略引入长短时记忆网络的遗忘门,输入门上,实验结果显示,该方法不但能大量减少模型参数,而且在实录的婴儿情感数据库上体现出显著的识别性能,且识别效率高,具有良好的应用前景。为了达到上述目的,本发明所采用的技术方案是:一种基于改进长短时记忆网络的婴儿哭声情感识别方法,包括以下步骤,步骤(a),将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征;步骤(b),将长度不同的时序相关特征补零到固定长度,形成该数据集语音的时序相关特征测试集;步骤(c),计算长短时记忆网络的注意力门以及深度注意力门;步骤(d),用深度注意力门替换长短时记忆网络的输入门和遗忘门,形成改进长短时记忆网络;步骤(e),通过训练集训练该改进长短时记忆网络,每间隔训练十步,并将时序相关特征测试集输入训练好的改进长短时记忆网络进行婴儿哭声情感评测,得到此刻婴儿哭声数据集分类的情感以及识别率。前述的基于改进长短时记忆网络的婴儿哭声情感识别方法,步骤(a),将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征,包括以下步骤,(a1),将婴儿哭声数据集语音进行端点检测,用于消除静默段保证从有效的语音信息提取时序相关特征;(a2),将端点检测后的婴儿哭声数据集语音按照每40ms一帧进行分帧,划分为多组帧数据;(a3),将每组多组帧数据均提取93维的时序相关特征。前述的基于改进长短时记忆网络的婴儿哭声情感识别方法,(a3),所述93维的时序相关特征,包括声音概率、谐噪比、基频、无声段的基频原始值、基频包络、连续周期之间的平均绝对差、连续周期之间的连续差的平均绝对差值、连续周期内插值峰值振幅的平均绝对差、谐波分量的均方根能量、噪声的均方根能量、响度、响度增量回归系数、15个美尔倒谱系数mfcc,15个mfcc的增量回归系数、26个美尔谱,8个对数美尔频段,8个线性预测编码系数、8个线谱对频率、过零率。前述的基于改进长短时记忆网络的婴儿哭声情感识别方法,步骤(b),将长度不同的时序相关特征补零到固定长度为先将所有不等长时序相关特征结尾处补零,使所有时序相关特征长度达到与数据集中的最长时序相关特征等长,补长后的时序相关特征的实际有效长度通过其的绝对值求和并判断是否为零来获得。前述的基于改进长短时记忆网络的婴儿哭声情感识别方法,步骤(c),计算长短时记忆网络的注意力门以及深度注意力门,其中注意力门attnt,如公式(1)所示,其中,σ(x)为sigmod函数,va和wa为对上一时刻的细胞状态来计算注意力门的可训练的矩阵,ct-1为上一刻的细胞状态;由于不仅要关注上一时刻信息的深度length=1,还考虑t-2,t-3,…,t-n时刻,即深度length=n的细胞状态的信息,从而提出深度注意力门如公式(2)所示,其中,va和wa分别为对之前某一时刻的细胞状态来计算注意力门的共享参数的可训练矩阵。前述的基于改进长短时记忆网络的婴儿哭声情感识别方法,步骤(d),用深度注意力门替换长短时记忆网络的输入门和遗忘门,形成改进长短时记忆网络,该改进长短时记忆网络的细胞状态,如公式(3)所示,其中,ct为改进长短时记忆网络在t时刻的细胞状态、代表对应着当前时刻的前i个时刻的细胞状态的对齐向量。本发明的有益效果是:本发明的基于改进长短时记忆网络的婴儿哭声情感识别方法,将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征,并针对不同长度的时序相关特征建立长短时记忆网络的处理算法;然后,将注意力机制结合时序的深度的策略引入长短时记忆网络的遗忘门,输入门上,实验结果显示,该方法不但能大量减少模型参数,而且在实录的婴儿情感数据库上体现出显著的识别性能,且识别效率高,具有良好的应用前景,并具有以下优点,(1)采用改进长短时记忆网络来实现婴儿哭声情感识别方法,提取具有时序特点的特征并做等长处理,克服传统方法语音样本不等长问题;(2)将注意力机制结合时序的深度引入长短时记忆网络的遗忘门和输出门,提升了情感识别性能和效率。附图说明图1是本发明的基于多重注意力机制长短时记忆网络的儿童情感识别方法的流程图;图2是本发明与其他算法训练过程中训练集和测试集的准确率变化曲线图;图3是图2变化曲线收敛后的算法性能的箱型图。具体实施方式下面将结合说明书附图,对本发明作进一步的说明。如图1所示,本发明的基于改进长短时记忆网络的婴儿哭声情感识别方法,包括以下步骤,步骤(a),将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征,包括以下步骤,(a1),将婴儿哭声数据集语音进行端点检测,用于消除静默段保证从有效的语音信息提取时序相关特征;(a2),将端点检测后的婴儿哭声数据集语音按照每40ms一帧进行分帧,划分为多组帧数据;(a3),将每组多组帧数据均提取93维的时序相关特征,所述93维的时序相关特征,包括声音概率、谐噪比、基频、无声段的基频原始值、基频包络、连续周期之间的平均绝对差、连续周期之间的连续差的平均绝对差值、连续周期内插值峰值振幅的平均绝对差、谐波分量的均方根能量、噪声的均方根能量、响度、响度增量回归系数、15个美尔倒谱系数mfcc,15个mfcc的增量回归系数、26个美尔谱,8个对数美尔频段,8个线性预测编码系数、8个线谱对频率、过零率,该93维的时序相关特征能够完整且准确的表示出每帧测试集语音帧数据的基本特征。步骤(b),将长度不同的时序相关特征补零到固定长度,形成该数据集语音的时序相关特征测试集,先将所有不等长时序相关特征结尾处补零,使所有时序相关特征长度达到与数据集中的最长时序相关特征等长,补长后的时序相关特征的实际有效长度通过其的绝对值求和并判断是否为零来获得,并在长短时记忆网络中去根据实际长度决定是否计算下一个时刻信息;步骤(c),计算长短时记忆网络(lstm)的注意力门以及深度注意力门,其中注意力门attnt,如公式(1)所示,其中,σ(x)为sigmod函数,va和wa分别为对上一时刻的细胞状态来计算注意力门的可训练的矩阵,ct-1为上一刻的细胞状态,由于不仅要关注上一时刻信息的深度length=1,还考虑t-2,t-3,…,t-n时刻,即深度length=n的细胞状态的信息,从而提出深度注意力门如公式(2)所示,其中,va和wa分别为对之前某一时刻的细胞状态来计算注意力门的共享参数的可训练的矩阵;步骤(d),用深度注意力门替换长短时记忆网络的输入门和遗忘门,形成改进长短时记忆网络,我们知道长短时记忆网络的关键就是细胞状态,有通过精心设计的称作为″门″的结构来去除或者增加信息到细胞状态的能力,算法通过考虑对每一刻的细胞状态做自注意力,并对细胞状态不需要注意的部分加入输入的信息,从而用注意力门替换了遗忘门和输入门,该改进长短时记忆网络的细胞状态,如公式(3)所示,其中,ct为改进长短时记忆网络在t时刻的细胞状态、代表对应着当前时刻的前i个时刻的细胞状态的对齐向量;步骤(e),通过训练集训练该改进长短时记忆网络,每间隔训练十步,并将将最后一个时刻的输出作为全连接层的输入,为了避免过拟合,需要在训练时刻加入dropout层,来随机的遗忘部分信息,最后,为了对标签进行预测,我们需要将dropout的输出通过一个softmax层,来计算该样本属于每一个类别的概率,并将概率最大的类别判定为该样本所属的类别,从而实现将时序相关特征测试集输入训练好的改进长短时记忆网络进行婴儿哭声情感评测,得到该婴儿哭声数据集语音对应的情感。根据本发明的基于改进长短时记忆网络的婴儿哭声情感识别方法,如图2-3所示,介绍一下识别效果:实验均采用单向两层lstm堆叠结构,并使用了一个全连接层和一个softmax层作为训练模型,训练过程中,采用tanh作为激活函数,采用小批量梯度下降法,批量为64,对800个训练样本总共训练了1500个epochs,每次训练10个batch。通过对测试集打印一次测试的结果以验证模型的效果。为了保证对比有效性,以下实验的所有参数均完全相同(除了第一层全连接层,因为输入的维度不一样,但输出的维度是相同的)。参数设置如表1所示。表1网络参数parametersvalueseta0.001adambeta1,20.7,0.7batchsize64epochs1500ninputs93lstmcells[512,256],单向denselayers[128,5]l20.0001trainsamples800testsamples200实验比较的模型包括传统lstm以及深度分别为1,2和3的lstm+deepf_1,lstm+deepf_2,lstm+deepf_3模型。其中,图2为训练过程中训练集和测试集的准确率变化曲线,图3为变化曲线收敛后的算法性能的箱型图,从图2的准确率变化曲线可知,提出的lstm+deepf不管在什么深度下,在训练集和测试集上收敛速度和识别效果均高于传统lstm,而且lstm+deepf_2和lstm+deepf_3性能均优于lstm+deepf_1。从图3的箱型图来看,传统lstm模型有8个异常值,lstm+deepf_1有两个,lstm+deepf_2有5个,而lstm+deepf_3没有异常值。对比模型收敛后的识别率三项指标,lstm+deepf_3模型、lstm+deepf_2模型和lstm+deepf_1模型的三项指标分别为(0.920,0.815,0.869),(0.920,0.810,0.868)和(0.915,0.805,0.859)。相比较lstm模型的相同指标(0.870,0.745,0.805)均有提升,而且随着深度的增加,性能也在逐渐增加。由上述实验所示,采用自注意力门可以大幅度提高lstm的识别率,且加深自注意力门的深度,也可以提高浅自注意力门的识别率。综上所述,本发明的基于改进长短时记忆网络的婴儿哭声情感识别方法,将婴儿哭声数据集语音进行端点检测并分帧,提取该婴儿哭声数据集语音的时序相关特征,并针对不同长度的时序相关特征建立长短时记忆网络的处理算法;然后,将注意力机制结合时序的深度的策略引入长短时记忆网络的遗忘门,输入门上,实验结果显示,该方法不但能大量减少模型参数,而且在实录的婴儿情感数据库上体现出显著的识别性能,且识别效率高,具有良好的应用前景,并具有以下优点,(1)采用改进长短时记忆网络来实现婴儿哭声情感识别方法,提取具有时序特点的特征并做等长处理,克服传统方法语音样本不等长问题;(2)将注意力机制结合时序的深度引入长短时记忆网络的遗忘门和输出门,提升了情感识别性能和效率。以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1