基于MFrSRRPCA算法的语音增强系统及方法与流程
本发明属于信号处理领域,更进一步涉及语音信号处理技术领域中的一种基于多子带短时分数阶傅里叶谱随机重排鲁棒主成分分析mfrsrrpca(multi-bandshort-time-fractional-fourier-spectrogram-random-rearrangedrobustprincipalcomponentanalysis)算法的语音增强系统及方法。本发明不仅可用于语音接收系统中的语音增强与降噪,还能用作语音检测识别系统的预处理前端,提升语音检测识别的性能。
背景技术:
传统语音增强通常以谱减法和维纳滤波器等算法为基础,而由谱减法所得的增强语音中常常会引入大量音乐噪声,维纳滤波器却预先假设语音与噪声服从高斯分布,因此,传统语音增强方法的应用往往存在着诸多限制。近年来,随着信号处理技术的发展,语音增强技术经历了迅猛的发展。鲁棒主成分分析作为一种矩阵低秩稀疏分解算法,近年来被引入到了语音增强领域之中,该算法打破了传统语音增强方法的限制,尤其在低信噪比条件下,取得了更为良好的效果。然而,以鲁棒主成分分析为基础的语音增强方法在去除噪声的同时,也会将部分时频幅度谱较为低秩的语音成分一同消除,影响了语音增强的效果。
p.sun等人在其发表的论文“low-rankandsparsityanalysisappliedtospeechenhancementviaonlineestimateddictionary”(ieeesignalprocessingletters,23(12):1862-1866,2016)中提出了一种带有实时字典估计模块的低秩稀疏分解的语音增强系统。该系统包括时频分析模块、时频幅度谱增强模块、时域语音重构模块,还额外包括实时字典估计模块。其中,时频分析模块使用短时傅里叶变换用于生成含噪语音的时频信息;实时字典估计模块通过最大期望方法实时估计时频幅度谱的语音存在可能性字典;时频幅度谱增强模块结合语音存在可能性字典,使用增广拉格朗日乘子法求取增强语音的时频幅度谱;时域语音重构模块为增强语音的时频幅度谱赋予含噪语音的相位谱,并使用逆短时傅里叶变换重构出时域形式的增强语音。该系统可通过实时字典估计模块检测出语音谱凸包,因此,对处理有暂态突变的噪声具有尤为良好的效果。但是,该系统仍然存在的不足之处是,由于该系统中只含有一个时频幅度谱增强模块,导致语音增强参数只能根据单个时频幅度谱设置,因此,该系统在消除能量在时频幅度谱中非均匀分布的有色噪声时,会在增强语音中残留大量有色噪声分量。
航空电子系统综合技术重点实验室在其申请的专利文献“基于非负低秩和稀疏矩阵分解原理的语音增强方法”(申请号:201310548773.9申请日:2013.11.07申请公布号:cn103559888a)中公开了一种基于附加非负性约束的低秩稀疏矩阵分解方法进行语音增强方法。该方法的实施步骤为:第一步,使用短时傅里叶变换获取含噪语音的时频幅度谱与时频相位谱;第二步,利用非负低秩和稀疏矩阵分解算法对含噪语音时频幅度谱进行分解,获取非负的低秩矩阵和稀疏矩阵;第三步,利用稀疏矩阵和含噪语音相位谱重构增强语音时频谱,并使用逆短时傅里叶变换重构出时域形式的增强语音。该方法通过对低秩和稀疏矩阵分解添加了非负性约束,排除了增强语音时频幅度谱中负值的存在,有效地减少了会对人耳听觉系统产生强烈不适的音乐噪声,提升了语音听觉质量。但是,该方法仍然存在的不足之处是,由于该方法仅仅通过限制低秩矩阵秩的大小,降低低秩语音成分被错误消除的可能性,却未从根本上解决该问题,因此,仍然有部分低秩语音被视为噪声而滤除,影响了语音的可懂度。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出了一种基于mfrsrrpca算法的语音增强系统及方法。
实现本发明目的的具体思路是,首先使用短时分数阶傅里叶变换对含噪语音进行时频分析,将其结果中的时频幅度谱沿分数阶频率轴划分为若干子带,再将每个子带中各帧的分数阶傅里叶幅度谱元素排列顺序分别随机打乱,使用鲁棒主成分分析算法分别将每个子带分解,并恢复每个子带中各帧分数阶傅里叶幅度谱元素的排列顺序,得到多个增强子带,最后将所有增强子带重组成增强时频幅度谱,并重构出完整的时域增强语音。本发明用于语音系统中的语音增强,恢复被噪声严重污染的语音的音质与可懂度,达到增强含噪语音的目的。
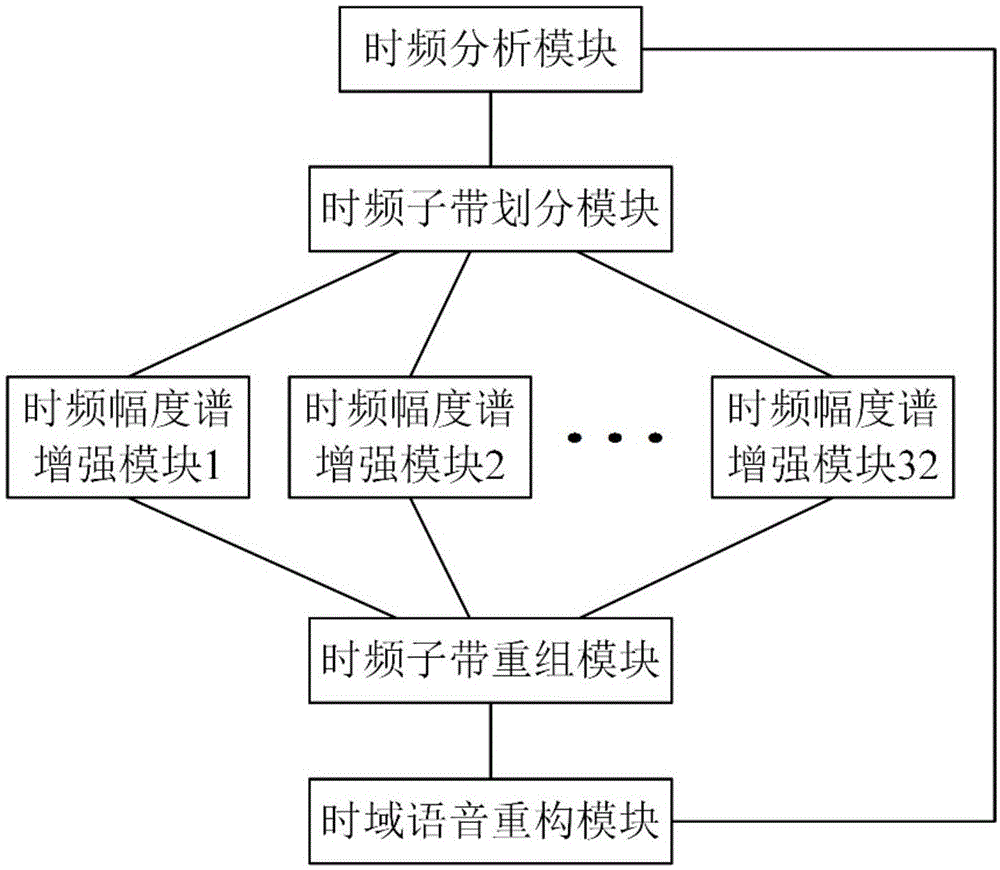
本发明的语音增强系统,包括时频分析模块、时域语音重构模块,其特征在于,还包括时频子带划分模块、时频子带重组模块、32个时频幅度谱增强模块;所述时频分析模块分别与时域语音重构模块、时频子带划分模块相连,所述时域语音重构模块与时频子带重组模块相连,所述32个时频幅度谱增强模块中的每个模块分别与时频子带划分模块、时频子带重组模块相连;其中:
所述时频分析模块,用于将待增强的含噪语音分为多帧短时语音,选取一个未处理帧的短时语音作为当前帧的短时语音,对当前帧的短时语音分别做不同阶次的分数阶傅里叶变换,选取最优阶次,保存当前帧的最优分数阶傅里叶相位谱,判断是否选取完所有帧的短时语音,构成含噪语音的短时分数阶傅里叶时频幅度谱;
所述时频子带划分模块,用于选取一个整数n作为子带划分的个数,接收时频分析模块生成的含噪语音短时分数阶傅里叶时频幅度谱,将含噪语音短时分数阶傅里叶时频幅度谱划分为n个含噪子带,启用32个时频幅度谱增强模块中所有编号小于等于n的时频幅度谱增强模块,将每个含噪子带输出到对应编号的时频幅度谱增强模块之中;
所述时频幅度谱增强模块,用于接收对应编号的含噪子带,随机打乱对应编号的含噪子带中各帧分数阶傅里叶幅度谱元素的排列顺序,估计相应含噪重排子带内的噪声强度,生成对应编号的稀疏子带,恢复对应编号稀疏子带中所有帧分数阶傅里叶幅度谱元素的排列顺序,生成对应编号的增强子带;
所述时频子带重组模块,用于接收所有编号小于等于n的时频幅度谱增强模块所生成的增强子带,组成增强短时分数阶傅里叶时频幅度谱;
所述时域语音重构模块,用于接收时频分析模块生成的所有帧的最优阶次与最优分数阶傅里叶相位谱,接收时频子带重组模块生成的增强短时分数阶傅里叶时频幅度谱,选取一个未处理帧的增强分数阶傅里叶幅度谱,作为当前帧的增强分数阶傅里叶幅度谱,重构当前帧的短时增强语音,判断是否选取完所有帧的增强分数阶傅里叶幅度谱,将所有帧的短时增强语音重构成完整的增强语音。
本发明的方法具体步骤包括如下:
(1)生成含噪语音的时频信息:
(1a)时频分析模块从[20,50]毫秒的范围内任选一个值作为帧的时长,并在帧长度×[5%,95%]的范围内,选取一个值作为步进长度,将待增强的含噪语音分为多帧短时语音;
(1b)时频分析模块在所有帧的短时语音中,按时间顺序依次选取一个未处理帧的短时语音作为当前帧的短时语音;
(1c)时频分析模块对当前帧的短时语音分别做不同阶次的分数阶傅里叶变换,获得多个不同阶次的分数阶傅里叶谱,并求取每个阶次对应变换谱的幅度与相位分别作为该阶次的分数阶傅里叶幅度谱与分数阶傅里叶相位谱;
(1d)时频分析模块将每个阶次的分数阶傅里叶幅度谱作为一个列向量,按阶次的顺序排列,由所有阶次的分数阶傅里叶幅度谱构成阶次-分数阶傅里叶幅度谱矩阵,通过搜索矩阵中的最大值选取最优阶次,将最大值所对应的阶次与分数阶傅里叶幅度谱分别作为当前帧的最优阶次与最优分数阶傅里叶幅度谱,将最优阶次相应的分数阶傅里叶相位谱作为当前帧的最优分数阶傅里叶相位谱,保存当前帧的最优分数阶傅里叶相位谱;
(1e)时频分析模块判断是否选取完所有帧的短时语音,若是,执行步骤(1f),否则,执行步骤(1b);
(1f)时频分析模块将每帧的最优分数阶傅里叶幅度谱作为一个列向量,按时间顺序排列,由所有帧的最优分数阶傅里叶幅度谱构成含噪语音的短时分数阶傅里叶时频幅度谱,该短时分数阶傅里叶时频幅度谱与(1d)中保存的所有帧的最优阶次及最优分数阶傅里叶相位谱构成完整的含噪语音时频信息;
(2)划分出n个含噪子带:
(2a)时频子带划分模块在[1,32]的范围内,选取一个整数n作为子带划分的个数;
(2b)时频子带划分模块接收时频分析模块生成的含噪语音短时分数阶傅里叶时频幅度谱,沿分数阶频率轴将含噪语音短时分数阶傅里叶时频幅度谱划分为n个含噪子带,并将生成的所有含噪子带按含噪子带起始频率分数阶大小分别编号,各含噪子带所占频点个数大于等于4;
(2c)时频子带划分模块启用32个时频幅度谱增强模块中所有编号小于等于n的时频幅度谱增强模块;
(2d)将每个含噪子带作为一个时频幅度谱,将每个含噪子带输出到对应编号的时频幅度谱增强模块之中;
(3)生成n个增强子带:
(3a)每个已启用的时频幅度谱增强模块接收对应编号的含噪子带,随机打乱对应编号的含噪子带中各帧分数阶傅里叶幅度谱元素的排列顺序,分别得到对应编号的重排含噪子带,记录每个重排含噪子带中所有帧的重排顺序;
(3b)在[4,12]的范围内,选取一个整数c,作为估计子带内噪声强度所使用的帧数,每个已启用的时频幅度谱增强模块由对应编号的含噪重排子带的前c帧分数阶傅里叶幅度谱估计相应含噪重排子带内的噪声强度。
(3c)利用鲁棒主成分分析算法,每个已启用的时频幅度谱增强模块分别根据各自子带内噪声强度估计值,将对应编号的重排含噪子带自适应增强,生成对应编号的稀疏子带;
(3d)每个已启用的时频幅度谱增强模块分别根据各自在步骤(3a)中所记录的重排顺序,恢复对应编号稀疏子带中所有帧分数阶傅里叶幅度谱元素的排列顺序,生成对应编号的增强子带;
(4)组成增强时频幅度谱:
时频子带重组模块接收所有编号小于等于n的时频幅度谱增强模块所生成的增强子带,并将这n个增强子带重新按编号顺序,沿频率轴组成增强短时分数阶傅里叶时频幅度谱;
(5)生成所有帧的短时增强语音:
(5a)时域语音重构模块接收时频分析模块生成的所有帧的最优阶次与最优分数阶傅里叶相位谱,接收时频子带重组模块生成的增强短时分数阶傅里叶时频幅度谱;
(5b)时域语音重构模块在增强短时分数阶傅里叶时频幅度谱中,按时间顺序依次选取一个未处理帧的增强分数阶傅里叶幅度谱,作为当前帧的增强分数阶傅里叶幅度谱;
(5c)时域语音重构模块将当前帧相应的最优分数阶傅里叶相位谱,与当前帧的增强分数阶傅里叶幅度谱结合,使用当前帧最优阶次的逆分数阶傅里叶变换重构当前帧的短时增强语音;
(5d)时域语音重构模块判断是否选取完所有帧的增强分数阶傅里叶幅度谱,若是,执行步骤(6),否则,执行步骤(5b);
(6)重构增强语音:
时域语音重构模块使用重叠相加overlappedadd法,将所有帧的短时增强语音重构成完整的增强语音。
与现有技术相比,本发明具有如下优点:
第一,由于本发明的系统中采用时频子带划分模块,可用于将含噪语音短时分数阶傅里叶时频幅度谱划分为n个含噪子带,将每个含噪子带作为一个时频幅度谱分别输出到对应编号的时频幅度谱增强模块之中,克服了现有技术只含有一个时频幅度谱增强模块,导致语音增强参数只能根据单个时频幅度谱设置,在消除能量在时频幅度谱中非均匀分布的有色噪声时,会在增强语音中残留大量有色噪声分量,使得本发明语音增强参数可以根据每个子带内的噪声强度自适应设置,提高了系统消除有色噪声的性能。
第二,由于本发明的方法在生成增强子带时,随机打乱对应编号的含噪子带中各帧分数阶傅里叶幅度谱元素的排列顺序,克服了现有技术仅仅通过限制低秩矩阵秩的大小,降低低秩语音成分被错误消除的可能性,使得本发明中低秩语音成分变为接近满秩,不再具有低秩的特性,有效地将低秩语音成分保留在了增强语音之中。
附图说明
图1为本发明系统的框图;
图2为本发明方法的流程图;
图3为本发明仿真实验1中短时傅里叶幅度谱切面与短时分数阶傅里叶幅度谱切面的对比图;
图4为本发明仿真实验2中本发明与鲁棒主成分分析算法白噪声条件下的语音增强效果的时频幅度谱直观对比图;
图5为本发明仿真实验3中本发明与鲁棒主成分分析算法在七种不同类型噪声条件下的平均语音增强效果客观指标对比图。
具体实施方式
下面结合附图对本发明做进一步详细描述。
参照附图1,对本发明系统的结构做进一步详细描述。
本发明的系统包括时频分析模块、时域语音重构模块、时频子带划分模块、时频子带重组模块、32个时频幅度谱增强模块;所述时频分析模块分别与时域语音重构模块、时频子带划分模块相连,所述时域语音重构模块与时频子带重组模块相连,所述32个时频幅度谱增强模块中的每个模块分别与时频子带划分模块、时频子带重组模块相连;其中:
所述时频分析模块,用于将待增强的含噪语音分为多帧短时语音,选取一个未处理帧的短时语音作为当前帧的短时语音,对当前帧的短时语音分别做不同阶次的分数阶傅里叶变换,选取最优阶次,保存当前帧的最优分数阶傅里叶相位谱,判断是否选取完所有帧的短时语音,构成含噪语音的短时分数阶傅里叶时频幅度谱;
所述时频子带划分模块,用于选取一个整数n作为子带划分的个数,接收时频分析模块生成的含噪语音短时分数阶傅里叶时频幅度谱,将含噪语音短时分数阶傅里叶时频幅度谱划分为n个含噪子带,启用32个时频幅度谱增强模块中所有编号小于等于n的时频幅度谱增强模块,将每个含噪子带输出到对应编号的时频幅度谱增强模块之中;
所述时频幅度谱增强模块,用于接收对应编号的含噪子带,随机打乱对应编号的含噪子带中各帧分数阶傅里叶幅度谱元素的排列顺序,估计相应含噪重排子带内的噪声强度,生成对应编号的稀疏子带,恢复对应编号稀疏子带中所有帧分数阶傅里叶幅度谱元素的排列顺序,生成对应编号的增强子带;
所述时频子带重组模块,用于接收所有编号小于等于n的时频幅度谱增强模块所生成的增强子带,组成增强短时分数阶傅里叶时频幅度谱;
所述时域语音重构模块,用于接收时频分析模块生成的所有帧的最优阶次与最优分数阶傅里叶相位谱,接收时频子带重组模块生成的增强短时分数阶傅里叶时频幅度谱,选取一个未处理帧的增强分数阶傅里叶幅度谱,作为当前帧的增强分数阶傅里叶幅度谱,重构当前帧的短时增强语音,判断是否选取完所有帧的增强分数阶傅里叶幅度谱,将所有帧的短时增强语音重构成完整的增强语音。
下面参照附图2,对本发明的方法的实现步骤作进一步的描述。
步骤1,生成含噪语音的时频信息。
(1.1)时频分析模块从[20,50]毫秒的范围内任选一个值作为帧的时长,并在帧长度×[5%,95%]的范围内,选取一个值作为步进长度,将待增强的含噪语音分为多帧短时语音。
(1.2)时频分析模块在所有帧的短时语音中,按时间顺序依次选取一个未处理帧的短时语音作为当前帧的短时语音。
(1.3)时频分析模块对当前帧的短时语音分别做不同阶次的分数阶傅里叶变换,获得多个不同阶次的分数阶傅里叶谱,并求取每个阶次对应变换谱的幅度与相位分别作为该阶次的分数阶傅里叶幅度谱与分数阶傅里叶相位谱。
所述对当前帧的短时语音分别做不同阶次的分数阶傅里叶变换的步骤如下。
第1步,在[0.5,0.95]的范围内,选取一个值作为最优阶次搜索的下限,最优阶次搜索的上限为1,在[10,1000]的范围内,选取一个值作为最优阶次搜索的次数,由最优阶次搜索的上限减去最优阶次搜索的下限的差值得到最优阶次搜索区间长度,由最优阶次搜索区间长度除以最优阶次搜索次数的商值得到搜索步进。
第2步,在最优阶次搜索范围内,从最优阶次搜索下限开始,按大小顺序依次选取一个未处理的阶次作为当前阶次。
第3步,利用下述的分数阶傅里叶变换公式,计算当前帧的短时语音在当前阶次下的分数阶傅里叶变换,并生成当前帧的短时语音在当前阶次下的分数阶傅里叶谱:
其中,xα(k)表示当前阶次α的分数阶傅里叶变换谱中第k个分数阶频点上的谱值,k=1,2,...,m,m表示以时域语音采样时间间隔t对当前帧的短时语音进行采样的采样点的总数,aα表示由
第4步,判断当前阶次是否达到最优阶次搜索上限,若是,执行第5步,否则,执行第2步。
第5步,获得多个不同阶次的分数阶傅里叶谱。
(1.4)时频分析模块将每个阶次的分数阶傅里叶幅度谱作为一个列向量,按阶次的顺序排列,由所有阶次的分数阶傅里叶幅度谱构成阶次-分数阶傅里叶幅度谱矩阵,通过搜索矩阵中的最大值选取最优阶次,将最大值所对应的阶次与分数阶傅里叶幅度谱分别作为当前帧的最优阶次与最优分数阶傅里叶幅度谱,将最优阶次相应的分数阶傅里叶相位谱作为当前帧的最优分数阶傅里叶相位谱,保存当前帧的最优分数阶傅里叶相位谱。
(1.5)时频分析模块判断是否选取完所有帧的短时语音,若是,执行本步骤的第(1.6)步,否则,执行本步骤的第(1.2)步。
(1.6)时频分析模块将每帧的最优分数阶傅里叶幅度谱作为一个列向量,按时间顺序排列,由所有帧的最优分数阶傅里叶幅度谱构成含噪语音的短时分数阶傅里叶时频幅度谱,该短时分数阶傅里叶时频幅度谱与本步骤的第(1.4)步中保存的所有帧的最优阶次及最优分数阶傅里叶相位谱构成完整的含噪语音时频信息。
步骤2,划分出n个含噪子带。
时频子带划分模块在[1,32]的范围内,选取一个整数n作为子带划分的个数。
时频子带划分模块接收时频分析模块生成的含噪语音短时分数阶傅里叶时频幅度谱,沿分数阶频率轴将含噪语音短时分数阶傅里叶时频幅度谱划分为n个含噪子带,并将生成的所有含噪子带按含噪子带起始频率分数阶大小分别编号,各含噪子带所占频点个数大于等于4。
时频子带划分模块启用32个时频幅度谱增强模块中所有编号小于等于n的时频幅度谱增强模块。
将每个含噪子带作为一个时频幅度谱,将每个含噪子带输出到对应编号的时频幅度谱增强模块之中。
步骤3,生成n个增强子带。
(3.1)每个已启用的时频幅度谱增强模块接收对应编号的含噪子带,随机打乱对应编号的含噪子带中各帧分数阶傅里叶幅度谱元素的排列顺序,分别得到对应编号的重排含噪子带,记录每个重排含噪子带中所有帧的重排顺序。
(3.2)在[4,12]的范围内,选取一个整数c,作为估计子带内噪声强度所使用的帧数,每个已启用的时频幅度谱增强模块由对应编号的含噪重排子带的前c帧分数阶傅里叶幅度谱估计出相应含噪重排子带内的噪声强度。
(3.3)利用鲁棒主成分分析算法,每个已启用的时频幅度谱增强模块分别根据各自子带内噪声强度估计值,将对应编号的重排含噪子带自适应增强,生成对应编号的稀疏子带。
所述的鲁棒主成分分析算法是指:利用增广拉格朗日法对下述含噪重排子带增强的鲁棒主成分分析算法模型进行优化求解,分解含噪重排子带,生成包含语音信息的稀疏子带:
其中,
(3.4)每个已启用的时频幅度谱增强模块分别根据各自在本步骤的第(3.1)步中所记录的重排顺序,恢复对应编号稀疏子带中所有帧分数阶傅里叶幅度谱元素的排列顺序,生成对应编号的增强子带。
步骤4,组成增强时频幅度谱。
时频子带重组模块接收所有编号小于等于n的时频幅度谱增强模块所生成的增强子带,并将这n个增强子带重新按编号顺序,沿频率轴组成增强短时分数阶傅里叶时频幅度谱。
步骤5,生成所有帧的短时增强语音。
(5.1)时域语音重构模块接收时频分析模块生成的所有帧的最优阶次与最优分数阶傅里叶相位谱,接收时频子带重组模块生成的增强短时分数阶傅里叶时频幅度谱。
(5.2)时域语音重构模块在增强短时分数阶傅里叶时频幅度谱中,按时间顺序依次选取一个未处理帧的增强分数阶傅里叶幅度谱,作为当前帧的增强分数阶傅里叶幅度谱。
(5.3)时域语音重构模块将当前帧相应的最优分数阶傅里叶相位谱,与当前帧的增强分数阶傅里叶幅度谱结合,使用当前帧最优阶次的逆分数阶傅里叶变换重构当前帧的短时增强语音。
(5.4)时域语音重构模块判断是否选取完所有帧的增强分数阶傅里叶幅度谱,若是,执行步骤6,否则,执行本步骤的第(5.2)步。
步骤6,重构增强语音。
时域语音重构模块使用重叠相加overlappedadd法,将所有帧的短时增强语音组成完整的增强语音。
本发明的效果可以通过下面仿真实验得到进一步证明。
1.仿真条件:
本发明的仿真实验通过matlab仿真软件实现,设定语音采样率为8000赫兹,时频分析模块中每帧短时语音时长为32毫秒,帧与帧间的步进长度为16毫秒,短时分数阶傅里叶变换的最优阶次搜索下限为0.95,最优阶次搜索上限为1,搜索步进为0.001。本发明仿真以将含噪时频幅度谱沿分数阶傅里叶域划分成16个等大小的含噪子带为例,每个时频幅度谱增强模块中使用exactalm(exactaugmentedlagrangemultiplier)方法求解鲁棒主成分分析算法,其中,每个时频幅度谱增强模块中鲁棒主成分分析算法的权重参数与相应含噪重排子带内的噪声强度相关,可通过如下公式自适应确定:
λi=0.04×log10(μi)+0.24
其中,λi表示编号为i的时频幅度谱增强模块中鲁棒主成分分析算法的权重参数,log10(·)表示求取以10为底的对数操作,μi表示编号为i的时频幅度谱增强模块中的含噪重排子带前8个无语音帧的分数阶傅里叶幅度谱平均功率。
2.仿真内容:
本发明的仿真实验有三个。仿真实验1是采用现有技术短时傅里叶变换方法与本发明的短时分数阶傅里叶变换方法,分别对含噪语音进行时频分析,并比较现有技术短时傅里叶变换方法与本发明的短时分数阶傅里叶变换方法所得时频幅度谱的稀疏性。为了比较的直观性,图3是仿真实验1以两种方法所得的时频幅度谱中对应的一帧傅里叶域/最优阶次的分数阶傅里叶域切面为例,从侧面展示了短时傅里叶幅度谱与短时分数阶傅里叶幅度谱的对比结果图。图3中的横坐标表示两种方法对应的傅里叶域与最优阶次分数阶傅里叶域,纵坐标表示谱值。图3中虚线表示该帧短时语音的傅里叶幅度谱,而实线表示该帧短时语音的最优阶次分数阶傅里叶幅度谱。
仿真实验2是对利用本发明的算法与现有技术的鲁棒主成分分析算法的语音增强效果进行直观对比,得到图4的时频幅度谱直观对比图。本发明仿真实验2中一段干净语音被白噪声所污染,信噪比为5分贝,分别用本发明的算法和现有技术的鲁棒主成分分析算法进行语音增强。为了时频幅度谱对比的直观性,本次仿真实验2中本发明的算法并未使用短时分数阶傅里叶变换进行时频分析,而是采用了现有技术鲁棒主成分分析算法所使用的短时傅里叶变换进行时频分析。图4(a)表示干净语音的时频幅度谱俯视图,图4(b)表示噪声的时频幅度谱俯视图,图4(c)表示鲁棒主成分分析算法所得语音成分时频幅度谱俯视图,图4(d)表示鲁棒主成分分析算法所得噪声成分时频幅度谱俯视图,图4(e)表示本发明算法所得语音成分时频幅度谱俯视图,图4(f)表示本发明算法所得噪声成分时频幅度谱俯视图。图4中每个时频幅度谱中的横轴表示时间轴,单位为秒,纵轴表示频率轴,单位为千赫兹,并且,每个时频幅度谱以对数谱的形式展现,谱值单位为分贝。
仿真实验3是对利用本发明的算法与现有技术鲁棒主成分分析算法在七种不同类型的噪声(white、babble、hfchannel、f16、factory1、buccaneer1与buccaneer2)污染下的平均语音增强效果进行对比,其结果如图5所示。图5为仿真实验3本发明与现有技术鲁棒主成分分析算法,在七种不同类型噪声条件下的平均语音增强效果客观指标对比图,其中语音增强效果分别用两种客观指标衡量,即信号失真比指标与pesq(perceptualevaluationofspeechquality)指标,信号失真比指标能够衡量增强语音与干净语音之间客观差异,而pesq指标能够模拟人耳感官的角度,对增强语音的音质进行评估,两种指标的数值越大代表语音增强效果越好。图5(a)中以正方形标示的曲线表示本发明的算法在上述七种噪声污染下所得增强语音的平均信号失真比受信噪比影响的变化曲线。图5(a)中以五角星标示的曲线表示了现有技术鲁棒主成分分析算法,在上述七种噪声污染下所得增强语音的平均信号失真比受信噪比影响的变化曲线。图5(a)中的横坐标表示信噪比,单位为分贝,纵坐标表示信号失真比指标,单位为分贝。图5(b)中以正方形标示的曲线表示本发明的算法,在上述七种噪声污染下所得增强语音的平均pesq指标受信噪比影响的变化曲线。图5(b)中以五角星标示的曲线表示现有技术鲁棒主成分分析算法,在上述七种噪声污染下,所得增强语音的平均pesq指标受信噪比影响的变化曲线。图5(b)中的横坐标表示信噪比,单位为分贝,纵坐标表示pesq指标。
3.仿真结果分析:
从图3可见,本发明的短时分数阶傅里叶幅度谱切面比现有技术的短时傅里叶幅度谱切面具有更高且更窄的谱峰。原因在于傅里叶变换可被视为一种特殊阶次(1阶)的分数阶傅里叶变换,其能量聚焦性弱于某些阶次的分数阶傅里叶变换,拓展到时频分析的角度,本发明的短时分数阶傅里叶变换相较于现有技术短时傅里叶变换具有更好的稀疏性,而更稀疏的时频幅度谱有利于以矩阵低秩稀疏分解为基础的语音增强方法获取更好的语音增强效果。
从图4可见,其中图4(d)的现有技术鲁棒主成分分析算法所得的噪声成分时频幅度谱残留了大量的语音成分,而图4(f)本发明算法所得的噪声成分时频幅度谱中残留的语音成分却极少;同时,图4(e)中的语音成分能量远远强于图4(c),直观地体现出了本发明的算法具有更好的语音增强效果。其原因在于,本发明通过将各子带内每帧分数阶傅里叶谱元素的排列顺序随机打乱,进一步降低了语音成分,包括低秩语音成分,时频幅度谱帧与帧之间的相似性,使得语音成分变得更为稀疏,从而优化了语音增强的效果。
从图5可见,本发明的算法得到的信号失真比指标曲线和pesq指标曲线,分别在现有技术鲁棒主成分分析算法对应的两种指标曲线之上,说明在两种指标下,本发明的算法语音增强性能都要优于现有技术鲁棒主成分分析算法。仿真证明本发明在多种噪声污染的条件下,都具有较强的噪声去除能力,同时尽可能地将更多的语音成分保留在了增强语音之中,具有良好的语音增强效果。
- 还没有人留言评论。精彩留言会获得点赞!