一种语音识别的方法、装置及计算机存储介质与流程
本发明涉及智能家居领域,尤其是涉及一种语音识别的方法、装置及计算机存储介质。
背景技术:
在智能家居领域中,语音交互作为智能家居设备的一种新型的人机交互方式被广泛的使用。
例如,智能语音音箱、智能语音电视、智能语音空调等,用户都可以通过语音对它们进行控制。
然而,用户在对智能家居设备进行语音控制时,用户可能还同时在做其它事情,如跑步、炒菜、吹头发等,此时智能家居设备采集到的用户语音中必然会混入其它较多的噪音,这将降低智能家居设备对用户语音的识别率。
鉴于此,如何有效的提高智能家居设备的语音识别率,成为一个亟待解决的技术问题。
技术实现要素:
本发明提供一种语音识别的方法、装置及计算机存储介质,用以解决现有技术中存在的语音识别率不高的技术问题。
第一方面,为解决上述技术问题,本发明实施例提供的一种语音识别的方法,应用于智能家居设备,该方法的技术方案如下:
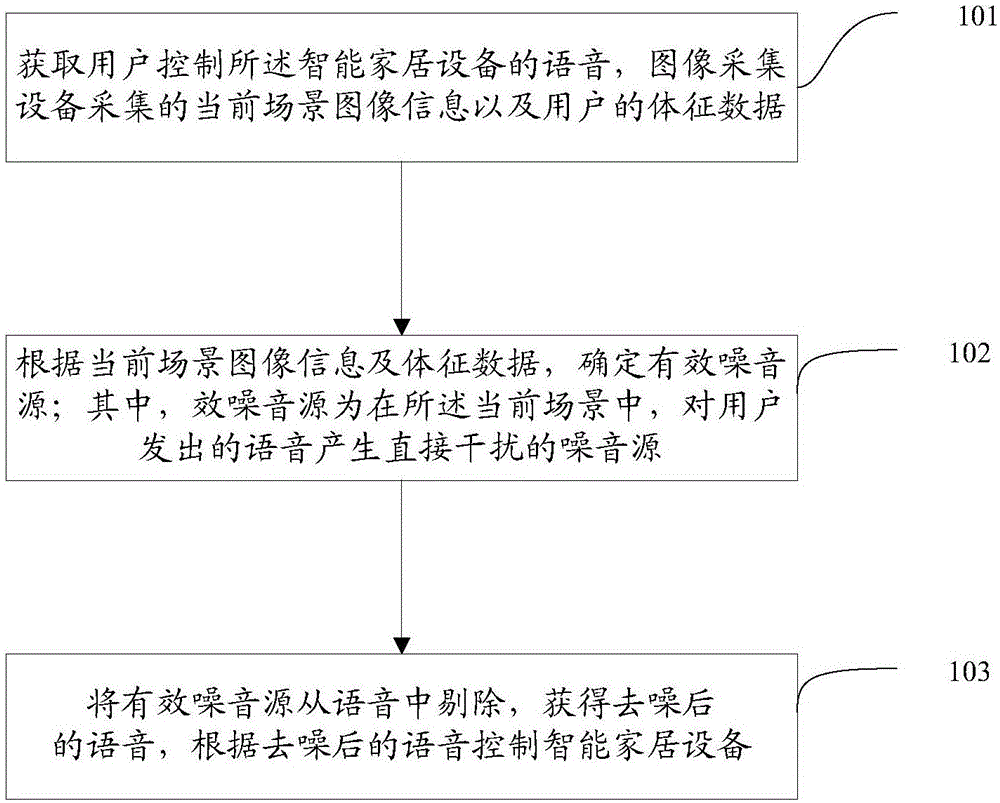
获取用户控制所述智能家居设备的语音,图像采集设备采集的当前场景图像信息以及用户的体征数据;
根据所述当前场景图像信息及所述体征数据,确定有效噪音源;其中,所述有效噪音源为在所述当前场景中,对用户发出的语音产生直接干扰的噪音源;
将所述有效噪音源从所述语音中剔除,获得去噪后的语音,根据所述去噪后的语音控制所述智能家居设备。
在获取用户控制智能家居设备的语音时,还通过图像采集设备采集当前场景图像信息以及用户的体征数据;并根据当前场景图像信息以及体征数据,将当前场景中对用户发出的语音产生直接干扰的噪音源确定为有效噪音源;并将有效噪音源从语音中剔除,获得去噪后的语音,再根据去噪后的语音控制智能家居设备。从而使智能家居设备能根据确定出的当前场景中的有效噪音源,对用户语音进行针对性降噪,从而提高语音识别率。
可选的,根据所述当前场景图像信息以及所述体征数据,确定有效噪音源,包括:
根据所述当前场景图像信息,从数据库中获取所述当前场景图像信息对应的用户场景中存在的噪音源集合;
根据所述数据库中每种用户状态对应的体征数据范围,判断所述体征数据对应的当前用户状态;
根据所述当前用户状态从所述噪音源集合中,获取所述有效噪音源。
可选的,根据所述当前用户状态从所述噪音源集合中,获取所述有效噪音源,包括:
根据所述当前用户状态,判断是否将用户产生的用户噪音对应的噪音源从所述噪音源集合中去除,获得判断结果;其中,所述用户噪音为用户运动时发出的声音;
若所述判断结果为需要去除所述用户噪音对应的噪音源,则从所述噪音源集合中去除所述用户噪音对应的噪音源,获得新的噪音源集合;
从所述新的噪音源集合中挑选出干扰值小于预设阈值的噪音源,获得所述有效噪音源。
可选的,将所述有效噪音源从所述语音中剔除,获得去噪后的语音,包括:
将所述有效噪音源对应的音频信号做反相处理后,叠加到所述语音对应的音频信号中,获得所述去噪后的语音。
可选的,所述体征数据具体是通过可穿戴设备采集的;所述可穿戴设备包括运动传感器、生物传感器、环境传感器、皮电传感器、心率传感器、气压计中的任一种或几种的组合。
第二方面,本发明实施例提供了一种用于语音识别的装置,包括:
获取单元,用于获取用户控制所述智能家居设备的语音,图像采集设备采集的当前场景图像信息以及用户的体征数据;
确定单元,用于根据所述当前场景图像信息及所述体征数据,确定有效噪音源;其中,所述有效噪音源为在所述当前场景中,对用户发出的语音产生直接干扰的噪音源;
剔除单元,用于将所述有效噪音源从所述语音中剔除,获得去噪后的语音,根据所述去噪后的语音控制所述智能家居设备。
可选的,所述确定单元具体用于:
根据所述当前场景图像信息,从数据库中获取所述当前场景图像信息对应的用户场景中存在的噪音源集合;
根据所述数据库中每种用户状态对应的体征数据范围,判断所述体征数据对应的当前用户状态;
根据所述当前用户状态从所述噪音源集合中,获取所述有效噪音源。
可选的,所述确定单元还用于:
根据所述当前用户状态,判断是否将用户产生的用户噪音对应的噪音源从所述噪音源集合中去除,获得判断结果;其中,所述用户噪音为用户运动时发出的声音;
若所述判断结果为需要去除所述用户噪音对应的噪音源,则从所述噪音源集合中去除所述用户噪音对应的噪音源,获得新的噪音源集合;
从所述新的噪音源集合中挑选出干扰值小于预设阈值的噪音源,获得所述有效噪音源。
可选的,所述剔除单元具体用于:
将所述有效噪音源对应的音频信号做反相处理后,叠加到所述语音对应的音频信号中,获得所述去噪后的语音。
可选的,所述体征数据具体是通过可穿戴设备采集的所述可穿戴设备包括运动传感器、生物传感器、环境传感器、皮电传感器、心率传感器、气压计中的任一种或几种的组合。
第三方面,本发明实施例还提供一种用于语音识别的装置,包括:
至少一个处理器,以及
与所述至少一个处理器连接的存储器;
其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述至少一个处理器通过执行所述存储器存储的指令,执行如上述第一方面所述的方法。
第四方面,本发明实施例还提供一种计算机可读存储介质,包括:
所述计算机可读存储介质存储有计算机指令,当所述计算机指令在计算机上运行时,使得计算机执行如上述第一方面所述的方法。
通过本发明实施例的上述一个或多个实施例中的技术方案,本发明实施例至少具有如下技术效果:
在本发明提供的实施例中,在获取用户控制智能家居设备的语音时,还通过图像采集设备采集当前场景图像信息以及用户的体征数据;并根据当前场景图像信息以及体征数据,将当前场景中对用户发出的语音产生直接干扰的噪音源确定为有效噪音源;并将有效噪音源从语音中剔除,获得去噪后的语音,再根据去噪后的语音控制智能家居设备。从而使智能家居设备能根据确定出的当前场景中的有效噪音源,对用户语音进行针对性降噪,从而提高语音识别率。
附图说明
图1为本发明实施例提供的一种语音识别方法的流程图;
图2为本发明实施例提供的跑步场景中智能家居设备进行语音识别的示意图;
图3为本发明实施例提供的一种语音识别装置的结构示意图。
具体实施方式
本发明实施列提供一种语音识别的方法、装置及计算机存储介质,以解决现有技术中存在的语音识别率不高的技术问题。
本申请实施例中的技术方案为解决上述的技术问题,总体思路如下:
提供一种语音识别的方法,包括:获取用户控制智能家居设备的语音,图像采集设备采集的当前场景图像信息以及用户的体征数据;根据当前场景图像信息以及体征数据,确定有效噪音源;其中,有效噪音源为在当前场景中,对用户发出的语音产生直接干扰的噪音源,将有效噪音源从语音中剔除,获得去噪后的语音,根据去噪后的语音控制智能家居设备。
由于在上述方案中,在获取用户控制智能家居设备的语音时,还通过图像采集设备采集当前场景图像信息以及用户的体征数据;并根据当前场景图像信息以及体征数据,将当前场景中对用户发出的语音产生直接干扰的噪音源确定为有效噪音源;并将有效噪音源从语音中剔除,获得去噪后的语音,再根据去噪后的语音控制智能家居设备。从而使智能家居设备能根据确定出的当前场景中的有效噪音源,对用户语音进行针对性降噪,从而提高语音识别率。
为了更好的理解上述技术方案,下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本发明技术方案的详细的说明,而不是对本发明技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。
请参考图1,本发明实施例提供一种语音识别的方法,应用于智能家居设备中,该方法的处理过程如下。
步骤101:获取控制智能家居设备的语音,图像采集设备采集用的当前场景图像信息以及用户的体征数据。
随着语音识别技术在智能家居设备中的广泛应用,不仅让用户省去了在欲控制智能家居设备时需要寻找控制器,或到智能家居设备上操作控制按钮的烦劳,让用户在家中时可以随时控制智能家居设备。例如,以往控制空调可以使用遥控器,现在可以通过语音控制空调。
在本发明提供的实施例中,图像采集设备可以是摄像头、ccd传感器、相机等,图像采集设备可以是智能家居设备的组成部分,也可以是外置的图像采集设备,还可以是智能手机上的摄像头,外置的图像采集设备可以通过有线的方式与智能家居设备进行通信,也可以通过无线的方式与智能家居设备进行通信,具体不做限定。
可选的,用户的体征数据具体是通过可穿戴设备采集的。
例如,在获取用户控制智能家居设备的语音时,由智能家具设备向可穿戴设备发出采集用户的体征数据;或在图像采集设备采集当前场景图像信息时,由图像采集设备向可穿戴设备发出采集用户的体征数据;或可穿戴设备定期向智能家居设备或图像采集设备上报用户的体征数据。
具体的,可穿戴设备可以是智能手环、运动传感器、生物传感器、环境传感器、皮电传感器、心率传感器、气压计中的任一种或几种的组合,可穿戴设备可以通过无线网络,如无线局域网、蓝牙、zigbee等与智能家居设备进行通信,将测得的体征数据传输给智能家居设备或图像采集设备采集,具体可穿戴设备与智能家居设备之间以何种方式进行通信,在此不做限定。
例如,请参见图2,用户在跑步机上跑步时,随着跑步时间的增加,使用户产生了较多的热量,用户想要开启空调,但又不愿意停下来用遥控器进行控制,此时,用户可以在跑步的同时向空调发出语音控制指令,如向空调说“开机,调节到26℃”。
此时,智能家居设备空调获取到用户控制智能家居设备空调的语音,并通过图像采集设备采集当前场景图像信息(跑步场景),同时还通过可穿戴设备(如智能手环)采集用户的体征数据(如心率、运动速度等)。
在获取控制智能家居设备的语音,图像采集设备采集用的当前场景图像信息以及用户的体征数据之后,便可执行步骤102。
步骤102:根据当前场景图像信息及体征数据确定有效噪音源;其中,有效噪音源为在所述当前场景中,对用户发出的语音产生直接干扰的噪音源。
具体的,可以先根据当前场景图像信息,从数据库中获取与当前场景图像信息对应的用户场景中存在的噪音源集合;其然后,再根据数据库中每种用户状态对应的体征数据范围,判断体征数据对应的当前用户状态;最后,根据当前用户状态从噪音源集合中,获取有效噪音源。
例如,仍然以图2中的例子为例,智能家居设备可以根据数据库中的场景图像信息中的特征,与采集到的当前场景图像信息中的特征进行比对,如跑步场景中用户的身体有一定的倾斜度、手臂在前后摆动、脚交替的离开地面,且节奏与手臂摆动的幅度相同、有跑步机等,当场景图像信息中的特征与数据库中的跑步场景图像信息中的特征相似度达到设定阈值(如90%)时,可以确定当前场景图像信息对应的是跑步场景图像信息。进而可以从数据库中确定,跑步场景图像信息中对应的噪音源有跑步机工作时产生的机器噪音源、用户在跑步机上运动时产生的摩擦噪音源、用户的喘息噪音源等,进而从数据库中确定出当前场景图像信息对应的用户场景中存在的噪音源集合为:机器噪音源、摩擦噪音源、喘息噪音源。
之后,根据数据库中每种用户状态对应的体征数据范围(如心率数据范围),判断空调通过智能手环得到的体征数据(即心率数据)对应的当前用户状态,例如数据库中用户为静态时心率范围为80-100对应静止或慢走状态,用户为慢跑时的心率范围为101-120对应慢跑状态,用户在快跑时的心率范围为大于121对应快跑状态。若通过智能手环得到的体征数据即心率为90则说明用户当前状态为静止或慢走状态;若测得的心率为130,则说明用户当前状态为快跑状态。
在确定用户的当前状态之后,根据当前用户状态从噪音源集合中,获取有效噪音源,可以通过以下方式来实现:
首先,根据当前用户状态,判断是否将用户产生的用户噪音从噪音源集合中去除,获得判断结果;其中,用户噪音为用户运动时发出的声音。
其次,若判断结果为去除用户噪音对应的噪音源,则从噪音源集合中去除用户噪音对应的噪音源,获得新的噪音源集合。
最后,从新的噪音源集合中挑选出干扰值小于预设阈值的噪音源,获得有效噪音源。
例如,若当前状态为静止或慢走状态,此时喘息声对用户发出的语音影响很小可以忽略,进而可以将喘息声从噪音源集合中去除,获得新的噪音源集合为机器噪音源和摩擦噪音源,之后从新的噪音源集合中将干扰值小于设定阈值的噪音源(如为摩擦噪音源)去除,获得有效噪音源为机器噪音源。若当前状态为快跑状态,此时喘息噪音源对用户发出的语音影响较大,不能忽略,获得新的噪音源集合为机器噪音源和摩擦噪音源、喘息噪音源,之后从中将干扰值小于设定阈值的噪音源(如喘息噪音源)去除,获得有效噪音源为机器噪音源、摩擦噪音源。
在获得有效噪音源之后,便可执行步骤103。
步骤103:将有效噪音源从语音中剔除,获得去噪后的语音,根据去噪后的语音控制智能家居设备。
具体的,将有效噪音源对应的音频信号做反相处理后,叠加到语音对应的音频信号中,获得去噪后的语音。
例如,依然以图2中的例子为例,有效噪音源为机器噪音源、摩擦噪音源,将机器噪音源和摩擦噪音源各自对应的音频信号做反相处理后,叠加到用户控制智能家居设备的语音中,使用户控制智能家居设备的语音中的机器噪音源和摩擦噪音源被抵消,从而获得去除机器噪音源和摩擦噪音源之后的语音(即去噪后的语音)。然后根据去噪后的语音控制智能家居设备执行开机及温度调节(将温度调节到26℃)。
基于同一发明构思,本发明一实施例中提供一种用于语音识别的装置,该装置的语音识别方法的具体实施方式可参见方法实施例部分的描述,重复之处不再赘述,请参见图3,该装置包括:
获取单元301,用于获取用户控制所述智能家居设备的语音,图像采集设备采集的当前场景图像信息以及用户的体征数据;
确定单元302,用于根据所述当前场景图像信息及所述体征数据,确定有效噪音源;其中,所述有效噪音源为在所述当前场景中,对用户发出的语音产生直接干扰的噪音源;
剔除单元303,用于将所述有效噪音源从所述语音中剔除,获得去噪后的语音,根据所述去噪后的语音控制所述智能家居设备。
可选的,所述确定单元302具体用于:
根据所述当前场景图像信息,从数据库中获取所述当前场景图像信息对应的用户场景中存在的噪音源集合;
根据所述数据库中每种用户状态对应的体征数据范围,判断所述体征数据对应的当前用户状态;
根据所述当前用户状态从所述噪音源集合中,获取所述有效噪音源。
可选的,所述确定单元302还用于:
根据所述当前用户状态,判断是否将用户产生的用户噪音对应的噪音源从所述噪音源集合中去除,获得判断结果;其中,所述用户噪音为用户运动时发出的声音;
若所述判断结果为需要去除所述用户噪音对应的噪音源,则从所述噪音源集合中去除所述用户噪音对应的噪音源,获得新的噪音源集合;
从所述新的噪音源集合中挑选出干扰值小于预设阈值的噪音源,获得所述有效噪音源。
可选的,所述剔除单元303具体用于:
将所述有效噪音源对应的音频信号做反相处理后,叠加到所述语音对应的音频信号中,获得所述去噪后的语音。
可选的,所述体征数据具体是通过可穿戴设备采集的;
所述可穿戴设备包括运动传感器、生物传感器、环境传感器、皮电传感器、心率传感器、气压计中的任一种或几种的组合。
基于同一发明构思,本发明实施例中提供了一种用于语音识别的装置,包括:至少一个处理器,以及
与所述至少一个处理器连接的存储器;
其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述至少一个处理器通过执行所述存储器存储的指令,执行如上所述的语音识别方法。
基于同一发明构思,本发明实施例还提一种计算机可读存储介质,包括:
所述计算机可读存储介质存储有计算机指令,当所述计算机指令在计算机上运行时,使得计算机执行如上所述的语音识别方法。
在本发明提供的实施例中,在获取用户控制智能家居设备的语音时,还通过图像采集设备采集当前场景图像信息以及用户的体征数据;并根据当前场景图像信息以及体征数据,将当前场景中对用户发出的语音产生直接干扰的噪音源确定为有效噪音源;并将有效噪音源从语音中剔除,获得去噪后的语音,再根据去噪后的语音控制智能家居设备。从而使智能家居设备能根据确定出的当前场景中的有效噪音源,对用户语音进行针对性降噪,从而提高语音识别率。
本领域内的技术人员应明白,本发明实施例可提供为方法、系统、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明实施例是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!