一种基于多麦克风阵列的语音识别方法及系统与流程
本发明涉及语音信号处理技术领域,尤其涉及一种基于多麦克风阵列的语音识别方法及系统。
背景技术:
目前,人工智能(artificialintelligence,ai)语音识别技术主要使用多麦克风阵列来实现语音拾取、声源定位。
其中,多麦克风阵列从数量的角度进行分类可以包括2麦克风阵列、4麦克风阵列、6麦克风阵列等;其中,麦克风数量越多,语音信号拾取的角度会越宽,同时降噪效果也会越好。但是,无论是哪一种数量的麦克风阵列,都是基于平面设计的基础进行排列(如单排排列或环形排列)的,这些平面排列的多麦克风阵列对下方的噪声信号拾取不足,因此下方的噪声信号会给ai语音识别过程带来较大干扰,进而降低了ai语音识别结果的准确度。
技术实现要素:
本发明实施例公开了一种多基于麦克风阵列的语音识别方法及系统,能够减小下方的噪声信号给ai语音识别过程带来的干扰,提高ai语音识别结果的准确度。
本发明实施例第一方面公开一种基于多麦克风阵列的语音识别方法,所述多麦克风阵列包括的各个麦克风中包含朝正上方的麦克风、朝正下方的麦克风、水平朝四周指向的麦克风、以及倾斜朝四周指向的麦克风,所述方法包括:
将所述多麦克风阵列中的所述各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号;
从所述各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号;
利用噪声信号对所述初始音频信号进行噪声消除处理,获得目标音频信号;其中,所述噪声信号为所述各个处于人声频段的音频信号中除所述初始音频信号外的音频信号;
对所述目标音频信号进行语音识别。
作为一种可选的实施方式,在本发明实施例第一方面中,所述利用噪声信号对所述初始音频信号进行噪声消除处理,包括:
将噪声信号进行反相处理,获得目标噪声信号;
将所述初始音频信号与所述目标噪声信号进行加法处理,以消除所述初始音频信号中的噪声,获得目标音频信号。
作为一种可选的实施方式,在本发明实施例第一方面中,所述对所述目标音频信号进行语音识别之前,所述方法还包括:
对所述目标音频信号进行信号放大处理,获得放大的目标音频信号;
对所述放大的目标音频信号进行频率均衡处理,获得待识别音频信号;
所述对所述目标音频信号进行语音识别,包括:
对所述待识别音频信号进行语音识别。
作为一种可选的实施方式,在本发明实施例第一方面中,所述对所述待识别音频信号进行语音识别,包括:
将所述待识别音频信号发送至云端服务器,以使所述云端服务器对所述待识别音频信号进行语音识别,以获得语音识别结果;
接收所述云端服务器根据所述语音识别结果返回的答案数据。
作为一种可选的实施方式,在本发明实施例第一方面中,所述接收所述云端服务器根据所述语音识别结果返回的答案数据之后,所述方法还包括:
识别所述答案数据中是否存在图片元素,如果是,以文本形式输出所述答案数据。
作为一种可选的实施方式,在本发明实施例第一方面中,所述方法还包括:
如果所述答案数据中不存在所述图片元素,检测是否接收到输出形式要求指令;
如果检测到所述输出形式要求指令,以所述输出形式要求指令所指示的输出形式输出所述答案数据。
本发明实施例第二方面公开一种基于多麦克风阵列的语音识别系统,所述系统包括所述多麦克风阵列,所述多麦克风阵列包括的各个麦克风中包含朝正上方的麦克风、朝正下方的麦克风、水平朝四周指向的麦克风、以及倾斜朝四周指向的麦克风组成,所述系统还包括:
滤波单元,用于将所述多麦克风阵列中的所述各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号;
选取单元,用于从所述各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号;
处理单元,用于利用噪声信号对所述初始音频信号进行噪声消除处理,获得目标音频信号;其中,所述噪声信号为所述各个处于人声频段的音频信号中除所述初始音频信号外的音频信号;
第一识别单元,用于对所述目标音频信号进行语音识别。
作为一种可选的实施方式,在本发明实施例第二方面中,所述处理单元包括:
反相子单元,用于将噪声信号进行反相处理,获得目标噪声信号;
加法子单元,用于将所述初始音频信号与所述目标噪声信号进行加法处理,以消除所述初始音频信号中的噪声,获得目标音频信号。
作为一种可选的实施方式,在本发明实施例第二方面中,所述系统还包括:
放大单元,用于在对所述目标音频信号进行语音识别之前,对所述目标音频信号进行信号放大处理,获得放大的目标音频信号;
均衡单元,用于对所述放大的目标音频信号进行频率均衡处理,获得待识别音频信号;
所述第一识别单元对所述目标音频信号进行语音识别的方式具体为:
所述第一识别单元,用于对所述待识别音频信号进行语音识别。
作为一种可选的实施方式,在本发明实施例第二方面中,所述第一识别单元对所述待识别音频信号进行语音识别的方式具体为:
所述第一识别单元,用于将所述待识别音频信号发送至云端服务器,以使所述云端服务器对所述待识别音频信号进行语音识别,以获得语音识别结果;以及,接收所述云端服务器根据所述语音识别结果返回的答案数据。
作为一种可选的实施方式,在本发明实施例第二方面中,所述系统还包括:
第二识别单元,用于在接收所述云端服务器根据所述语音识别结果返回的所述答案数据之后,识别所述答案数据中是否存在图片元素,
输出单元,用于在所述答案数据中存在所述图片元素时,以文本形式输出所述答案数据。
作为一种可选的实施方式,在本发明实施例第二方面中,所述系统还包括:
检测单元,用于在所述答案数据中不存在所述图片元素时,检测是否接收到输出形式要求指令;
所述输出单元,还用于在检测到所述输出形式要求指令时,以所述输出形式要求指令所指示的输出形式输出所述答案数据。
本发明实施例第三方面公开一种电子设备,包括:
存储有可执行程序代码的存储器;
与所述存储器耦合的处理器;
所述处理器调用所述存储器中存储的所述可执行程序代码,执行本发明实施例第一方面公开的一种基于多麦克风阵列的语音识别方法。
本发明实施例第四方面公开一种计算机可读存储介质,其存储计算机程序,其中,所述计算机程序使得计算机执行本发明实施例第一方面公开的一种基于多麦克风阵列的语音识别方法。
本发明实施例第五方面公开一种计算机程序产品,当所述计算机程序产品在计算机上运行时,使得所述计算机执行第一方面的任意一种方法的部分或全部步骤。
本发明实施例第六方面公开一种应用发布平台,所述应用发布平台用于发布计算机程序产品,其中,当所述计算机程序产品在计算机上运行时,使得所述计算机执行第一方面的任意一种方法的部分或全部步骤。
与现有技术相比,本发明实施例具有以下有益效果:
本发明实施例应用于立体设计的多麦克风阵列,该多麦克风阵列包括朝正上方的麦克风、朝正下方的麦克风、水平朝四周指向的麦克风、以及倾斜朝四周指向的各个麦克风,该方法具体包括:将多麦克风阵列中的各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号;从各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号;利用噪声信号对初始音频信号进行噪声消除处理,获得目标音频信号;其中,噪声信号为上述各个处于人声频段的音频信号中除初始音频信号外的音频信号;对目标音频信号进行语音识别以获得答案数据。实施本发明实施例,立体设计的多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号,对这些音频信号进行带通滤波处理后能够获得各个处于人声频段的音频信号,选取其中信号强度最大的音频信号作为初始音频信号,其他的音频信号作为噪声信号,将初始音频信号与经过反相处理的噪声信号进行加法处理,能够滤除目标音频信号中各个方向的噪声,进而提高语音识别结果的准确度。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
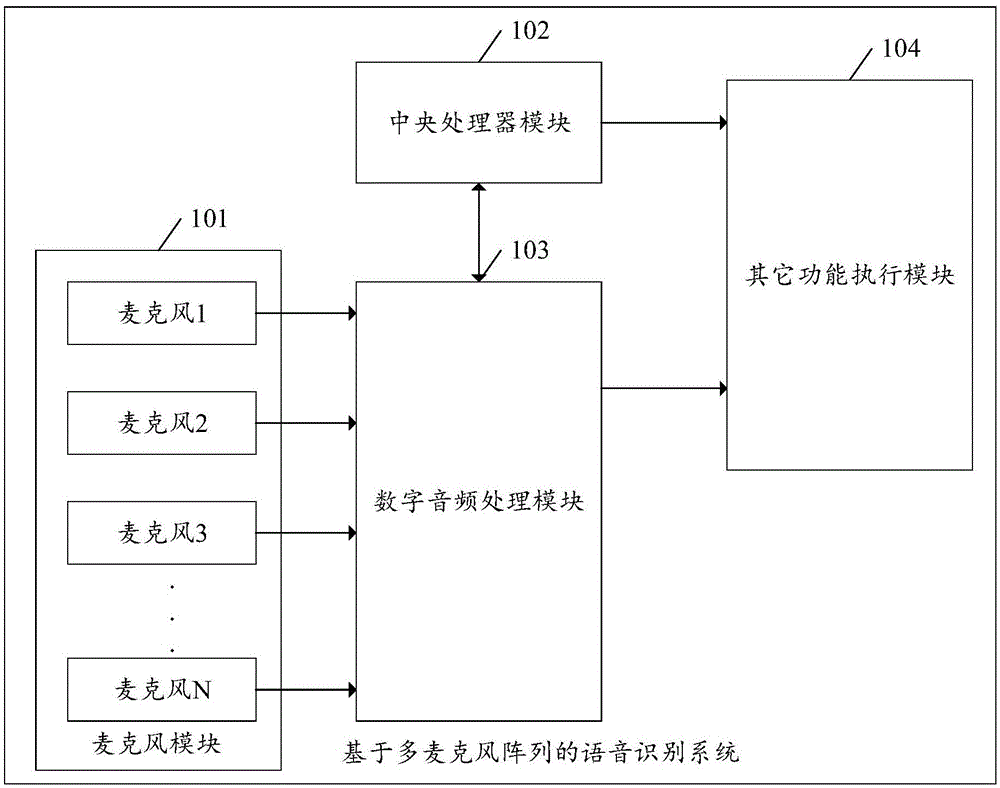
图1是本发明实施例公开的一种基于多麦克风阵列的语音识别系统的结构示意图;
图2是本发明实施例公开的一种多麦克风阵列的示意图;
图3是本发明实施例公开的一种基于多麦克风阵列的语音识别方法的流程示意图;
图4是本发明实施例公开的另一种基于多麦克风阵列的语音识别系统的流程示意图;
图5是本发明实施例公开的一种基于多麦克风阵列的语音识别系统的结构示意图;
图6是本发明实施例公开的另一种基于多麦克风阵列的语音识别系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书中的术语“第一”、“第二”、“第三”“第四”等是用于区别不同的对象,而不是用于描述特定顺序。本发明实施例的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例公开了一种多基于麦克风阵列的语音识别方法及系统,能够减小下方的噪声信号给ai语音识别过程带来的干扰,提高ai语音识别结果的准确度。以下结合实施例进行详细说明。
为了更好地理解本发明实施例公开的一种基于多麦克风阵列的语音识别方法及系统,下面首先结合图1和图2对本发明实施例适用的系统架构进行描述,图1是本发明实施例公开的一种基于多麦克风阵列的语音识别系统的结构示意图,图2是本发明实施例公开的一种多麦克风阵列的示意图。该系统可以包括麦克风模块101、中央处理器模块102、数字音频处理模块103和其它功能执行模104(可以包括通信模块、麦克风信号放大模块、麦克风信号反相模块、功率放大模块、扬声器模块和电源管理模块等)。其中,麦克风模块101用于将外界音频信号转换为电信号;数字音频处理模块103中的数字音频处理器(digitalsignalprocessing,dsp)用于把模拟音频信号转换为数字音频信号,并且能对数字音频信号做频率、幅度、相位等方面的调整,dsp一般都集成了带通滤波器(band-passfilter,bpf),可以实现带通滤波;中央处理器模块102中的微控制单元(microcontrollerunit,mcu)是一个系统的指挥中枢,它根据接收到的信息,经过运算后发出相应的指令给各模块,使整套系统正常工作;其它功能执行模块104主要是根据mcu的指令将dsp传过来经过各种算法处理的音频信号执行其他功能,比如上传到云端服务器进行语义解析,并返回答案数据。上述麦克风模块101包括一个多麦克风阵列,该多麦克风阵列包括n(n为正整数)个麦克风,其中包括朝正下方(在车辆中,以车底方向为正下方)的麦克风、朝正上方的麦克风、水平朝四周指向的麦克风(构成一个环形结构)、以及倾斜朝四周指向的麦克风。多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号。举例来说,请参考图2,可见,其中,麦克风201朝正下方;麦克风202朝正上方;麦克风203至麦克风206水平指向四周,并构成一个水平面p(水平面p可以是长方形、三角形或多边形等环形结构的形状);麦克风207至麦克风219(视角问题,麦克风208位于麦克风207后方,麦克风210位于麦克风209后方)与水平面p向上成第一预设角度夹角倾斜朝向四周,优选的,第一预设角度可以是45度或30度等;麦克风211至麦克风214(视角问题,麦克风212位于麦克风211后方,麦克风214位于麦克风213后方)与水平面p向下成第二预设角度夹角倾斜朝向四周,优选的,第二预设角度可以是45度或30度等;可以理解,该多麦克风阵列包括的各个麦克风能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号。需要说明的是,图2所示的多麦克风阵列为本发明实施例的一个实现方式,而不是全部的实现方式。
实施例一
请参阅图3,图3是本发明实施例公开的一种基于多麦克风阵列的语音识别方法的流程示意图,如图3所示,该基于多麦克风阵列的语音识别方法可以包括以下步骤:
301、mcu控制dsp将多麦克风阵列中的各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号。
本发明实施例中,多麦克风阵列中的各个麦克风拾取到的音频信号包括了不需要用到的音频信号,考虑到语音识别是以人声频段的音频信号为基础,而人声频段基础频率基本集中在100-1000hz频段,因此可以先进行带通滤波处理,获得处于人声频段的音频信号以减少其它频段的干扰,如减少车辆下方传来的路噪、胎噪以及震动等噪声的干扰。
302、mcu控制dsp从各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号。
可以理解,与用户距离最近,朝向用户的麦克风拾取到的人声频段的音频信号强度是最强的。
303、mcu控制dsp利用噪声信号对初始音频信号进行噪声消除处理,获得目标音频信号;其中,噪声信号为各个处于人声频段的音频信号中除初始音频信号外的音频信号。
可以理解,将初始音频信号与经过反相处理的噪声信号进行加法处理后,初始音频信号中的除目标音频信号的干扰信号将会被抵消掉。
304、mcu控制通信模块对上述目标音频信号进行语音识别。
作为一种可选的实施方式,在步骤304之前,还可以包括以下步骤:
mcu控制通信模块对上述目标音频信号进行信号放大处理,获得放大的目标音频信号;对放大的目标音频信号进行频率均衡处理,获得待识别音频信号。
步骤304可以包括:对待识别音频信号进行语音识别。
可选的,上述mcu控制通信模块对上述目标音频信号进行信号放大处理,获得放大的目标音频信号;对放大的目标音频信号进行频率均衡处理,获得待识别音频信号可以包括:
mcu控制通信模块对上述放大的目标音频信号进行频率均衡处理,获得频率均衡的音频信号;判断该频率均衡的音频信号是否存在失真现象;若频率均衡的音频信号存在失真现象,获取失真类型;对频率均衡的音频信号采取对应于该失真类型的处理方式进行处理,获得待识别音频信号。
实现本实施方式,能够检测目标音频信号在进行新号放大处理、频率均衡处理的过程中是否引发了失真,若出现失真现象,及时采取相应的措施进行处理,能够提高语音识别的准确率。
可见,实施本实施方式,对上述目标音频信号进行信号放大处理,可以避免后续因信号强度太小而无法进行语音识别的情况;放大信号后,再进行频率均衡,能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。
可见,在图3所描述的方法中,立体设计的多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号,对这些音频信号进行带通滤波处理后能够获得各个处于人声频段的音频信号,选取其中信号强度最大的音频信号作为初始音频信号,其他的音频信号作为噪声信号,将初始音频信号与经过反相处理的噪声信号进行加法处理,能够滤除目标音频信号中各个方向的噪声,进而提高语音识别结果的准确度。此外,对目标音频信号进行信号放大以及频率均衡处理,不仅可以避免后续因信号强度太小而无法进行语音识别的情况,还能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。
实施例二
请参阅图4,图4是本发明实施例公开的另一种基于多麦克风阵列的语音识别方法的流程示意图。如图3所示,该基于多麦克风阵列的语音识别方法可以包括以下步骤:
401、mcu控制dsp将多麦克风阵列中的各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号。
402、mcu控制dsp从各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号。
403、mcu控制dsp将噪声信号进行反相处理,获得目标噪声信号;其中,噪声信号为各个处于人声频段的音频信号中除初始音频信号外的音频信号。
404、mcu控制dsp将初始音频信号与目标噪声信号进行加法处理,以消除初始音频信号中的噪声,获得目标音频信号。
405、mcu控制dsp对上述目标音频信号进行信号放大处理,获得放大的目标音频信号。
406、mcu控制dsp对上述放大的目标音频信号进行频率均衡处理,获得待识别音频信号。
407、mcu控制通信模块将上述待识别音频信号发送至云端服务器,以使该云端服务器对待识别音频信号进行语音识别,以获得语音识别结果。
408、mcu控制通信模块接收云端服务器根据语音识别结果返回的答案数据。
作为一种可选的实施方式,在步骤408之后,还可以包括以下步骤:
mcu判断答案数据是否包括预设设备控制指令;若是,根据答案数据获取目标设备的设备标识;根据该目标设备的设备标识向目标设备发送答案数据以控制目标设备执行答案数据中的预设设备控制指令。
可见,实施本实施方式,能够自动将包括预设设备控制指令的答案数据发送至目标设备,进而控制目标设备执行相应的指令,能够提升用户体验。
409、mcu识别答案数据中是否存在图片元素,如果是,执行步骤410;如果否,执行步骤411~412。
410、mcu以文本形式输出答案数据。
411、mcu检测是否接收到输出形式要求指令;如果是,执行步骤412。
本发明实施例中,如果没有接收到输出形式要求指令,以默认的输出形式输出答案数据,其中默认输出形式可以是音频形式,也可以是文本形式。
412、mcu以上述输出形式要求指令所指示的输出形式输出答案数据。
可见,在图4所描述的方法中,立体设计的多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号,使得后续对目标音频信号降噪的过程中能够滤除目标音频信号中各个方向的噪声,进而提高语音识别结果的准确度。此外,对目标音频信号进行信号放大以及频率均衡处理,不仅可以避免后续因信号强度太小而无法进行语音识别的情况,还能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。此外,在云端服务器进行语音识别,并获取答案数据,能够降低本地服务器的负载。此外,在输出答案数据前先识别答案数据是否存在图片元素,考虑到了图片难以用语音形式输出的因素。此外,若答案数据中没有图片元素,那么在检测到用户对输出形式有要求时,以用户的输出形式要求指令所指示的输出形式输出答案数据,能够提升用户体验。
实施例三
请参阅图5,图5是本发明实施例公开的一种基于多麦克风阵列的语音识别系统的结构示意图。如图5所示,该基于多麦克风阵列的语音识别系统可以包括:
多麦克风阵列501,用于拾取以多麦克风阵列501为中心的360度立体指向的音频信号;多麦克风阵列501包括的各个麦克风中包含朝正上方的麦克风、朝正下方的麦克风、水平朝四周指向的麦克风、以及倾斜朝四周指向的麦克风;
滤波单元502,用于将多麦克风阵列中的各个麦克风拾取到的音频信号进行带通滤波处理,获得各个处于人声频段的音频信号;
选取单元503,用于从各个处于人声频段的音频信号中选取信号强度最大的音频信号作为初始音频信号;
处理单元504,用于利用噪声信号对初始音频信号进行噪声消除处理,获得目标音频信号;其中,噪声信号为各个处于人声频段的音频信号中除初始音频信号外的音频信号;
第一识别单元505,用于对目标音频信号进行语音识别。
作为一种可选的实施方式,图5所示的基于多麦克风阵列的语音识别系统还可以包括:
放大单元506,用于在对目标音频信号进行语音识别之前,对目标音频信号进行信号放大处理,获得放大的目标音频信号;
均衡单元507,用于对放大的目标音频信号进行频率均衡处理,获得待识别音频信号;
可选的,均衡单元507,用于对放大的目标音频信号进行频率均衡处理,获得待识别音频信号的方式具体可以为:
对上述放大的目标音频信号进行频率均衡处理,获得频率均衡的音频信号;判断该频率均衡的音频信号是否存在失真现象;若频率均衡的音频信号存在失真现象,获取失真类型;对频率均衡的音频信号采取对应于该失真类型的处理方式进行处理,获得待识别音频信号。
实现本实施方式,能够检测目标音频信号在进行新号放大处理、频率均衡处理的过程中是否引发了失真,若出现失真现象,及时采取相应的措施进行处理,能够提高语音识别的准确率。
第一识别单元505对目标音频信号进行语音识别的方式具体为:
第一识别单元505,用于对待识别音频信号进行语音识别。
可见,实施本实施方式,对上述目标音频信号进行信号放大处理,可以避免后续因信号强度太小而无法进行语音识别的情况;放大信号后,再进行频率均衡,能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。
结合图1,可以理解,多麦克风阵列501对应麦克风模块101;滤波单元502、选取单元503、处理单元504、放大单元506以及均衡单元507均属于数字音频处理模块103;第一识别单元505对应其他功能执行模块104。
可见,实施图5所示的基于多麦克风阵列的语音识别系统,立体设计的多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号,对这些音频信号进行带通滤波处理后能够获得各个处于人声频段的音频信号,选取其中信号强度最大的音频信号作为初始音频信号,其他的音频信号作为噪声信号,将初始音频信号与经过反相处理的噪声信号进行加法处理,能够滤除目标音频信号中各个方向的噪声,进而提高语音识别结果的准确度。此外,对目标音频信号进行信号放大以及频率均衡处理,不仅可以避免后续因信号强度太小而无法进行语音识别的情况,还能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。
实施例四
请参阅图6,图6是本发明实施例公开的一种基于多麦克风阵列的语音识别系统的结构示意图。如图6所示,该基于多麦克风阵列的语音识别系统中:
处理单元504包括:
反相子单元5041,用于将噪声信号进行反相处理,获得目标噪声信号;
加法子单元5042,用于将初始音频信号与目标噪声信号进行加法处理,以消除初始音频信号中的噪声,获得目标音频信号。
第一识别单元505,用于对待识别音频信号进行语音识别的方式具体为:
第一识别单元505,用于将待识别音频信号发送至云端服务器,以使云端服务器对该待识别音频信号进行语音识别,以获得语音识别结果;以及,接收云端服务器根据该语音识别结果返回的答案数据;
作为一种可选的实施方式,第一识别单元505,还用于接收云端服务器根据该语音识别结果返回的答案数据之后,判断答案数据是否包括预设设备控制指令;若是,根据答案数据获取目标设备的设备标识;根据该目标设备的设备标识向目标设备发送答案数据以控制目标设备执行答案数据中的预设设备控制指令。
可见,实施本实施方式,能够自动将包括预设设备控制指令的答案数据发送至目标设备,进而控制目标设备执行相应的指令,能够提升用户体验。
如图6所示的基于多麦克风阵列的语音识别系统还可以包括:
第二识别单元508,用于在接收云端服务器根据语音识别结果返回的答案数据之后,识别该答案数据中是否存在图片元素;
输出单元509,用于在答案数据中存在图片元素时,以文本形式输出答案数据;
检测单元510,用于在第二识别单元508识别出答案数据中不存在图片元素时,检测是否接收到输出形式要求指令;
输出单元509,还用于在检测单元510检测到输出形式要求指令时,以该输出形式要求指令所指示的输出形式输出答案数据。
结合图1,可以理解,第二识别单元508、输出单元509以及检测单元510对应中央处理器模块102。
可见,实施图6所示的基于多麦克风阵列的语音识别系统,立体设计的多麦克风阵列能够拾取以该多麦克风阵列为中心的360度立体指向的音频信号,使得后续对目标音频信号降噪的过程中能够滤除目标音频信号中各个方向的噪声,进而提高语音识别结果的准确度。此外,对目标音频信号进行信号放大以及频率均衡处理,不仅可以避免后续因信号强度太小而无法进行语音识别的情况,还能够使得放大的目标音频信号在频率响应特性上平滑,进而提高语音识别的准确性。此外,在云端服务器进行语音识别,并获取答案数据,能够降低本地服务器的负载。此外,在输出答案数据前先识别答案数据是否存在图片元素,考虑到了图片难以用语音形式输出的因素。此外,若答案数据中没有图片元素,那么在检测到用户对输出形式有要求时,以用户的输出形式要求指令所指示的输出形式输出答案数据,能够提升用户体验。
本发明实施例公开一种计算机可读存储介质,其存储计算机程序,其中,该计算机程序使得计算机执行图3~图4任意一种基于多麦克风阵列的语音识别方法。
本发明实施例还公开一种计算机程序产品,其中,当计算机程序产品在计算机上运行时,使得计算机执行如以上各方法实施例中的方法的部分或全部步骤。
本发明实施例还公开一种应用发布平台,该应用发布平台用于发布计算机程序产品,其中,当上述计算机程序产品在计算机上运行时,使得计算机执行如以上各方法实施例中的方法的部分或全部步骤。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(read-onlymemory,rom)、随机存储器(randomaccessmemory,ram)、可编程只读存储器(programmableread-onlymemory,prom)、可擦除可编程只读存储器(erasableprogrammablereadonlymemory,eprom)、一次可编程只读存储器(one-timeprogrammableread-onlymemory,otprom)、电子抹除式可复写只读存储器(electrically-erasableprogrammableread-onlymemory,eeprom)、只读光盘(compactdiscread-onlymemory,cd-rom)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
以上对本发明实施例公开的一种基于多麦克风阵列的语音识别方法及系统进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!