一种异常声音分析系统的制作方法
本发明涉及声音识别技术领域,尤其涉及一种异常声音分析系统。
背景技术:
声音是由空气中分子的振动而产生的;自然声是以声波为载体传递信息的,随时间而变化的连续信号,声波的振幅表示声音信号的强弱程度,声波的频率反映出声音的音调,是多媒体信息的一个重要组成部分,也是表达思想和情感的一种必不可少的媒体;随着计算机技术的发展,声音信号由不同的振幅与频率的波合成而得到,并使声音信号实现数字化。
目前,市面上对于一些声音分析的安防产品比较少,个别声音分析产品如声强报警装置,检测到大分贝的声音就发出报警信号,这样的技术实现存在很大的不足,即是声音检测很容易受干扰,比如说声音比较大的车喇叭声音,银行广播声音等都会引起误报。
技术实现要素:
为了解决上述技术问题,针对以上问题点,本发明公开的异常声音分析系统,通过对特定的异常声音进行识别,能够更加精准地检测到异常事件的发生情况,同时也解决了传统的声音检测技术容易受干扰问题,实时地为用户提供对异常事件的检测结果,弥补视频检测方式的不足,从而用更加精准地作出相应对策,达到对违法犯罪行为的制止、震慑作用。
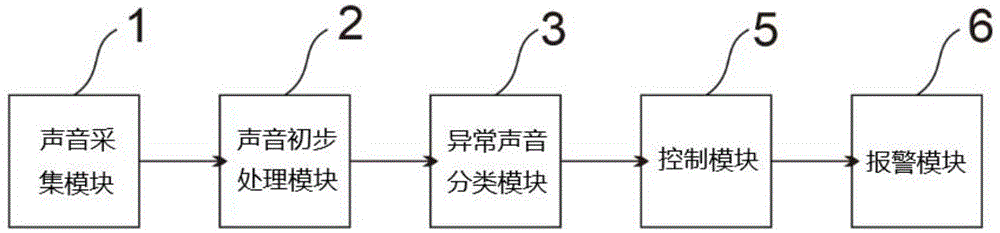
为了达到上述发明目的,本发明提供了一种异常声音分析系统,包括声音采集模块、声音初步处理模块、异常声音分类模块、信息接收模块、控制模块和报警模块;
所述声音采集模块,用于采集周围环境中的声音信息;
所述声音初步处理模块,对所述声音采集模块采集的声音信息进行初步处理,过滤干扰声音,得到异常声音信息;
所述异常声音分类模块,根据所述信息接收模块接收的异常声音信息,对声音进行分类,计算出各类声音的概率值,并将计算出的各类声音的概率值与预设的阈值进行对比,得出对比结果;
所述控制模块,用于对所述异常声音分类模块得出的对比结果进行分析,并将异常对比结果发送至所述报警模块;
所述报警模块,根据所述信息接收模块接收的所述控制模块得出异常对比结果,发出警报。
进一步地,所述异常声音分类模块包括特征提取模块和神经网络;
所述特征提取模块,根据所述信息接收模块接收的异常声音信息,提取声音特征算法,得出声音特征数据;
所述神经网络,根据所述信息接收模块接收的声音特征数据,将声音分成异常声音类、干扰声音类和背景声音类,分别计算得出异常声音类、干扰声音类和背景声音类的概率值,并将异常声音类的概率值与预设的阈值进行对比,得出对比结果。
更进一步地,所述特征提取模块中的提取声音特征算法为梅尔频率倒谱系数(mfcc)算法,mfcc算法根据接收到的异常声音信息得出数据的hz频谱特征,所述神经网络根据数据的hz频谱特征进行分类。
更进一步地,所述报警模块在所述神经网络计算的异常声音类的概率值与预设的阈值的对比结果异常时发出警报,其中对比结果异常即是异常声音类的概率值大于预设的阈值。
进一步地,所述报警模块包括报警显示器和寻呼装置;
所述报警显示器用于显示发生事故的地点及现场的情况;
所述寻呼装置用于根据异常结果发出警报信号。
更进一步地,所述报警显示器和所述寻呼装置均分别与所述控制模块连接。
进一步地,还包括通讯模块,所述通讯模块用于将所述声音采集模块采集的声音信息发送至所述信息接收模块,将所述声音初步处理模块计算得到的异常声音信息发送至所述信息接收模块;
所述通讯模块,还用于将所述控制模块得出的异常对比结果发送至所述信息接收模块。
更进一步地,所述信息接收模块包括第一信息接收模块、第二信息接收模块和第三信息接收模块;
所述第一信息接收模块,用于接收所述通讯模块发送的所述声音采集模块采集的声音信息;
所述第二信息接收模块,用于接收所述通讯模块发送的所述声音初步处理模块计算得到的异常声音信息;
所述第三信息接收模块,用于接收所述通讯模块发送的所述控制模块得出的异常对比结果。
优选地,所述声音采集模块为拾音器,所述拾音器设有至少一个。
优选地,所述声音初步处理模块为对讲主机,所述对讲主机与拾音器的数量相等。
实施本发明实施例,具有如下有益效果:
1、本发明公开的异常声音分析系统,通过对特定的异常声音进行识别,能够更加精准地检测到异常事件的发生情况,同时也解决了传统的声音检测技术容易受干扰问题,实时地为用户提供对异常事件的检测结果,弥补视频检测方式的不足,从而用更加精准地作出相应对策,达到对违法犯罪行为的制止、震慑作用。
附图说明
为了更清楚地说明本发明所述的异常声音分析系统,下面将对实施例所需要的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明异常声音分析系统的组成结构示意图;
图2为本发明异常声音分析系统的详细示意图;
图3为本发明优选实施例的组成结构示意图;
其中,图中附图标记对应为:1-声音采集模块,2-声音初步处理模块,3-异常声音分类模块,301-特征提取模块,302-神经网络,4-信息接收模块,401-第一信息接收模块,402-第二信息接收模块,403-第三信息接收模块,5-控制模块,6-报警模块,601-报警显示器,602-寻呼装置,7-通讯模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
实施例1:
如图1至图3所示:一种异常声音分析系统,包括声音采集模块1、声音初步处理模块2、异常声音分类模块3、信息接收模块4、控制模块5和报警模块6;
所述声音采集模块1,用于采集周围环境中的声音信息;
所述声音初步处理模块2,对所述声音采集模块1采集的声音信息进行初步处理,过滤干扰声音,得到异常声音信息;
所述异常声音分类模块3,根据所述信息接收模块4接收的异常声音信息,对声音进行分类,计算出各类声音的概率值,并将计算出的各类声音的概率值与预设的阈值进行对比,得出对比结果;
所述控制模块5,用于对所述控制模块5得出的异常对比结果进行分析,并将异常对比结果发送至所述报警模块6;
所述报警模块6,根据所述信息接收模块4接收的所述控制模块5得出异常对比结果,发出警报;本发明通过对特定的异常声音进行识别,能够更加精准地检测到异常事件的发生情况,同时也解决了传统的声音检测技术容易受干扰问题,实时地为用户提供对异常事件的检测结果,弥补视频检测方式的不足,从而用更加精准地作出相应对策,达到对违法犯罪行为的制止、震慑作用。
具体的,声音初步处理模块2将声音采集模块1采集的声音信息中的一些频率过高或过低、分贝值过低等一些非人声特征的声音过滤掉,将剩下的类似人声且分贝值比较大的声音作为异常声音信息发送至异常声音分类模块3。
具体的,所述异常声音分类模块3包括特征提取模块301和神经网络302;
所述特征提取模块301,根据所述信息接收模块4接收的异常声音信息,提取声音特征算法,得出声音特征数据;
所述神经网络302,根据所述信息接收模块4接收的声音特征数据,将声音分成异常声音类、干扰声音类和背景声音类,分别计算得出异常声音类、干扰声音类和背景声音类的概率值,并将异常声音类的概率值与预设的阈值进行对比,得出对比结果。
更为具体的,所述特征提取模块301中的提取声音特征算法为梅尔频率倒谱系数(mfcc)算法,mfcc算法根据接收到的异常声音信息得出数据的hz频谱特征,所述神经网络302根据数据的hz频谱特征进行分类。
进一步地,mfcc算法与hz频率成非线性对应关系,并通过这种对应关系计算得到hz频谱特征;
信息接收模块4接收的声音特征数据会预先送到神经网络302中预先训练好的分类模型,通过分类模型对声音特征数据进行分类;
另外,神经网络302由两层卷积层和一层全连接层组成,经mfcc算法计算得到的声音特征数据,依次经过两层卷积层、全连接层,最后通过softmax来计算并输出最后的功率。
神经网络302需要通过大量的数据进行训练,最终训练得到模型,其中,通过对一些特定的场景(如自助银行)发生的异常声音(如救命啊、抢劫啊等)进行收集,特征提取,并对整理后的数据采用tensorflow进行训练,最后输出一个可以识别上述特定场景异常结果的模型;
其中一般整理出来5000份训练数据和10000份的预测数据进行训练时,训练得到的模型准确率为98%以上。
具体的,所述报警模块6在所述神经网络302计算的异常声音类的概率值与预设的阈值的对比结果异常时发出警报,其中对比结果异常即是异常声音类的概率值大于预设的阈值。
具体的,还包括通讯模块7,所述通讯模块7用于将所述声音采集模块1采集的声音信息发送至所述信息接收模块4,将所述声音初步处理模块2计算得到的异常声音信息发送至所述信息接收模块4;
所述通讯模块7,还用于将所述控制模块5得出的异常对比结果发送至所述信息接收模块4。
进一步地,所述信息接收模块4包括第一信息接收模块401、第二信息接收模块402和第三信息接收模块403;
所述第一信息接收模块401,用于接收所述通讯模块7发送的所述声音采集模块1采集的声音信息;
所述第二信息接收模块402,用于接收所述通讯模块7发送的所述声音初步处理模块2计算得到的异常声音信息;
所述第三信息接收模块403,用于接收所述通讯模块7发送的所述控制模块5得出的异常对比结果。
实施例2:为实施例1的优选实施例
如图1至图3所示:一种异常声音分析系统,包括声音采集模块1、声音初步处理模块2、异常声音分类模块3、信息接收模块4、控制模块5和报警模块6;
所述声音采集模块1,用于采集周围环境中的声音信息;
所述声音初步处理模块2,对所述声音采集模块1采集的声音信息进行初步处理,过滤干扰声音,得到异常声音信息;
所述异常声音分类模块3,根据所述信息接收模块4接收的异常声音信息,对声音进行分类,计算出各类声音的概率值,并将计算出的各类声音的概率值与预设的阈值进行对比,得出对比结果;
所述控制模块5,用于对所述控制模块5得出的异常对比结果进行分析,并将异常对比结果发送至所述报警模块6;
所述报警模块6,根据所述信息接收模块4接收的所述控制模块5得出异常对比结果,发出警报;本发明通过对特定的异常声音进行识别,能够更加精准地检测到异常事件的发生情况,同时也解决了传统的声音检测技术容易受干扰问题,实时地为用户提供对异常事件的检测结果,弥补视频检测方式的不足,从而用更加精准地作出相应对策,达到对违法犯罪行为的制止、震慑作用。
具体的,声音初步处理模块2将声音采集模块1采集的声音信息中的一些频率过高或过低、分贝值过低等一些非人声特征的声音过滤掉,将剩下的类似人声且分贝值比较大的声音作为异常声音信息发送至异常声音分类模块3。
优选地,所述声音采集模块1为拾音器,所述拾音器设有至少一个。
所述声音初步处理模块2为对讲主机,所述对讲主机与拾音器的数量相等。
具体的,所述异常声音分类模块3包括特征提取模块301和神经网络302;
所述特征提取模块301,根据所述信息接收模块4接收的异常声音信息,提取声音特征算法,得出声音特征数据;
所述神经网络302,根据所述信息接收模块4接收的声音特征数据,将声音分成异常声音类、干扰声音类和背景声音类,分别计算得出异常声音类、干扰声音类和背景声音类的概率值,并将异常声音类的概率值与预设的阈值进行对比,得出对比结果。
更为具体的,所述特征提取模块301中的提取声音特征算法为梅尔频率倒谱系数(mfcc)算法,mfcc算法根据接收到的异常声音信息得出数据的hz频谱特征,所述神经网络302根据数据的hz频谱特征进行分类。
进一步地,mfcc算法与hz频率成非线性对应关系,并通过这种对应关系计算得到hz频谱特征;
信息接收模块4接收的声音特征数据会预先送到神经网络302中预先训练好的分类模型,通过分类模型对声音特征数据进行分类;
另外,神经网络302由两层卷积层和一层全连接层组成,经mfcc算法计算得到的声音特征数据,依次经过两层卷积层、全连接层,最后通过softmax来计算并输出最后的功率。
神经网络302需要通过大量的数据进行训练,最终训练得到模型,其中,通过对一些特定的场景(如自助银行)发生的异常声音(如救命啊、抢劫啊等)进行收集,特征提取,并对整理后的数据采用tensorflow进行训练,最后输出一个可以识别上述特定场景异常结果的模型;
其中一般整理出来5000份训练数据和10000份的预测数据进行训练时,训练得到的模型准确率为98%以上。
神经网络302中在对模型训练进行训练数据在采集时,首先安装好各对讲主机(100台以上),然后在每台对讲主机接入拾音器实时采集声音,对讲主机收集到声音后会对声音进行初步的筛选,把可能为异常声音的声音数据通过网络发送到特征提取模块301没最后通过人工手段来对声音进行分类。
具体的,所述报警模块6在所述神经网络302计算的异常声音类的概率值与预设的阈值的对比结果异常时发出警报,其中对比结果异常即是异常声音类的概率值大于预设的阈值。
更为具体的,所述报警模块6包括报警显示器601和寻呼装置602;
所述报警显示器601用于显示发生事故的地点及现场的情况;
所述寻呼装置602用于根据异常结果发出警报信号。
所述报警显示器601和所述寻呼装置602均分别与所述控制模块5连接。
具体的,还包括通讯模块7,所述通讯模块7用于将所述声音采集模块1采集的声音信息发送至所述信息接收模块4,将所述声音初步处理模块2计算得到的异常声音信息发送至所述信息接收模块4;
所述通讯模块7,还用于将所述控制模块5得出的异常对比结果发送至所述信息接收模块4。
进一步地,所述信息接收模块4包括第一信息接收模块401、第二信息接收模块402和第三信息接收模块403;
所述第一信息接收模块401,用于接收所述通讯模块7发送的所述声音采集模块1采集的声音信息;
所述第二信息接收模块402,用于接收所述通讯模块7发送的所述声音初步处理模块2计算得到的异常声音信息;
所述第三信息接收模块403,用于接收所述通讯模块7发送的所述控制模块5得出的异常对比结果。
与实施例1的不同之处在于:
优选地,所述声音采集模块1为拾音器,所述拾音器设有至少一个。
所述声音初步处理模块2为对讲主机,所述对讲主机与拾音器的数量相等。
神经网络302中在对模型训练进行训练数据在采集时,首先安装好各对讲主机(100台以上),然后在每台对讲主机接入拾音器实时采集声音,对讲主机收集到声音后会对声音进行初步的筛选,把可能为异常声音的声音数据通过网络发送到特征提取模块301没最后通过人工手段来对声音进行分类。
更为具体的,所述报警模块6包括报警显示器601和寻呼装置602;
所述报警显示器601用于显示发生事故的地点及现场的情况;
所述寻呼装置602用于根据异常结果发出警报信号。
所述报警显示器601和所述寻呼装置602均分别与所述控制模块5连接。
实施例3:为实施例2的优选实施例
与实施例2的不同之处在于:
优选地,拾音器设有3个,对讲主机设有3个。
优选地,通讯模块7为can总线。
本发明公开的异常声音分析系统,通过对特定的异常声音进行识别,能够更加精准地检测到异常事件的发生情况,同时也解决了传统的声音检测技术容易受干扰问题,实时地为用户提供对异常事件的检测结果,弥补视频检测方式的不足,从而用更加精准地作出相应对策,达到对违法犯罪行为的制止、震慑作用。
以上所揭露的仅为本发明一种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!