一种基于EMD-Wavelet的MFCC相似度的语音段检测方法与流程
本发明涉及一种基于emd-wavelet的mfcc相似度的语音段检测方法,属于语音信号处理中语音段的检测领域。
背景技术:
语音段检测是语音信号分析处理的重要环节,其目的是从包含语音的一段信号中提取语音信号的语音段,其检测精度直接影响对语音信号的处理时间和运算量。因此,提高语音段起止点检测的准确率和效率一直是语音识别技术研究中的热点。传统的语音段检测算法常采用短时能量、短时过零率和自相关最大值等方法,这些方法在高信噪比情况下得到了比较好的检测效果,然而,在低信噪比情况下检测效果很差。后来学者们相继提出了多种在噪声环境下的语音段检测方法,在一定程度上降低了噪声的影响。其中,小波分析具有良好的时频局域性,特别适合于非平稳语音信号的分析,在信号去噪领域得到了广泛的应用,但是小波去噪方法也存在一些缺点,如去噪效果与信号特点及小波基函数有很大关系,当信噪比较小时,去噪效果不理想。emd是基于信号本身的时间尺度特征的时频分析方法,可以直接把复杂信号由精细尺度到粗大尺度分解为若干本征模态分量(intrinsicmodefunction,imf)和一个余项,克服了小波去噪需要选择基函数的缺点,但消噪效果整体上不如小波阈值消噪。mel倒谱参数(mfcc)特征对于语音信号性质的依赖性不强,该特征参数的依靠人耳听觉模型,对低频信号灵敏,而对高频信号比较模糊。虽然mfcc能够很好地体现语音信号的信号特征,但在信噪比较低的情况下,mfcc用于语音段检测的效果并不明显。本发明根据语音信号非线性、非平稳性的特点,利用小波分析对语音信号的高低频部分有较好分辨率的优势,将emd和小波分析相结合,分析了语音信号中语音和非语音段的mfcc参数特征,提出了一种基于emd-wavelet的mfcc相似度的语音段检测方法。实验结果表明,该方法在不同噪声环境下均能得到理想的语音段提取效果,且在低信噪比时优势更明显。
技术实现要素:
为提高在不同噪声环境下语音段检测的准确率,本发明提供一种基于emd-wavelet的mfcc相似度的语音段检测方法。该方法具有更好的鲁棒性和适应性,语音段检测的准确率更高,能够很好的应用于语音信号的语音段提取。
上述的目的通过以下技术方案实现,该方法包括如下步骤:
一种基于emd-wavelet的mfcc相似度的语音段检测方法,具体包括如下步骤:
步骤1,对人说话的语音信号进行测量,采集到的语音信号作为源信号;
步骤2,利用emd对含噪的语音信号进行分解,得到体现语音信号高低频能量的的各阶本征模函数(imf);
步骤3,求各阶本征模函数imf的自相关系数,以自相关系数的方差确定噪声为主导模态的imf阶数,对噪声为主导模态的imf进行小波阈值降噪,把降噪后的低阶imf分量和余下的高阶imf分量进行重构,获得降噪后的语音信号;
步骤4,计算降噪后语音信号的mel倒谱参数(mfcc),对比分析语音段和噪声段的参数特征,以欧氏距离作为语音信号mfcc相似度的测度;
步骤5,从相似度曲线中可明显区分语音段和非语音段,从而从语音信号中实现语音段的提取。
作为本发明一种基于emd-wavelet的mfcc相似度的语音段检测方法的进一步优选方案,在步骤3中,将emd和小波分析相结合对语音信号进行降噪处理,其具体方法如下:
信号经emd分解后,通过求解各阶imf分量的自相关函数的方差判断各阶imf分量的噪声含量高低,判断前面k阶imf分量中噪声为主导模态,对前k阶imf进行阈值去噪,然后将去噪后的前k阶imf与余下的imf对信号进行重建,得到降噪后的语音信号,以上降噪步骤如下:
步骤3.1,对含噪信号x(t)进行emd分解,得到n个imf模态分量和余项r(t);
步骤3.2,分别计算出各imf分量的自相关函数,第i个imf分量的自相关函数表示为:ri(τ)=e[ci(t)ci(t+τ)],并对其进行归一化处理:ρi(τ)=ri[τ]/ri(0);
步骤3.3,求各阶imf归一化自相关函数方差,由方差衡量各阶imf分量的噪声含量,通过求取前k阶与所有imf自相关函数方差和的比值pk,确定要去噪的前k阶imf;计算公式可表示为:
步骤3.4,对含噪高的低阶imf1(t)~imfk(t)通过sym8小波基函数进行阈值消噪,得到去噪后的模态imf1'(t)~imfk'(t);
步骤3.5,重构原信号:则x'(t)为去噪后的信号:
作为本发明一种基于emd-wavelet的mfcc相似度的语音段检测方法的进一步优选方案,在小波去噪的方式上采用的是软阈值去噪,阈值确定准则为自适应史坦无偏估计(heursure),小波层数为4。
作为本发明一种基于emd-wavelet的mfcc相似度的语音段检测方法的进一步优选方案,在步骤4中,将计算语音信号的mel倒谱参数的相似度,其具体方法如下:
步骤4.1,提取各阶降噪后语音信号的各阶mel倒谱系数,计算所有帧的mfcc矢量;
步骤4.1,假定语音信号的前10帧为背景噪声,对前10帧mfcc矢量求平均,得到背景噪声mel倒谱矢量c0的近似值;
步骤4.1,求每一帧ci和c0的相似度d(ci,c0),计算各阶mfcc各帧与噪声帧的相似度均值,得到各阶mfcc相似度均值曲线,用于检测连续语音的端点;
其中,本发明选用euclidean(欧式)距离进行相似度测定,设向量x=(x1,x2,…xn)和向量y=(y1,y2…yn)的距离为d=(x,y),euclidean(欧式)距离表达式为:
作为本发明一种基于emd-wavelet的mfcc相似度的语音段检测方法的进一步优选方案,求语音信号mel倒谱系数时,mel频率滤波器组个数为24,mfcc系数阶数为12。
本发明所产生的有益效果:
(1)利用emd和小波算法的优点,将两者相结合,能够详细描述语音信号的非平稳和非线性特征,无论在高信噪比还是在低信噪比的情况下,都能有效抑制噪声对语音信号的影响;
(2)mfcc依靠人耳听觉模型,能够很好地体现语音信号的信号特征,但在信噪比较低的情况下,mfcc用于语音段检测的效果并不明显,将emd-wavelet与mfcc相结合,在低信噪比的情况下语音信号的语音段检测准确率明显提高;
(3)在相同的语音库和噪声库下,与emd能量法,小波幅值积法和mfcc距离法相比,基于emd-wavelet的mfcc相似度的语音段检测在低信噪比的情况下,具有更好的鲁棒性和适应性,语音段检测的准确率更高,能够很好的应用于语音信号的语音段检测。
附图说明
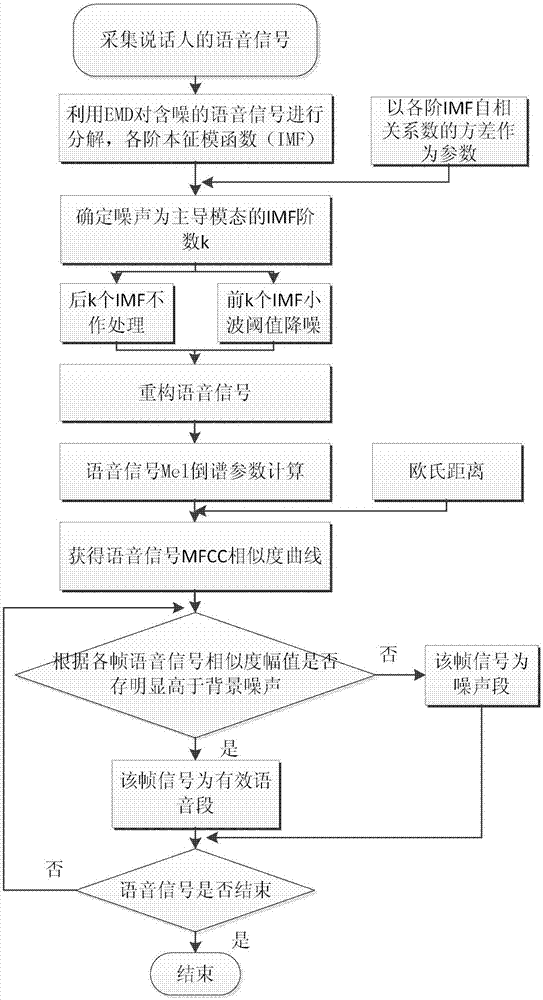
图1是本发明的流程图;
图2(a)是本发明纯语音波形的语音时域波形图;
图2(b)是本发明加噪语音信噪比=10db的语音时域波形图;
图2(c)是本发明加噪语音信噪比=5db的语音时域波形图;
图2(d)是本发明加噪语音信噪比=0db的语音时域波形图;
图2(e)是本发明加噪语音信噪比=-5db的语音时域波形图;
图2(f)是本发明加噪语音信噪比=-10db的语音时域波形图;
图3是本发明各阶imf自相关系数方差占比曲线图;
图4是本发明加噪语音信噪比=-5db的emd-wavelet的mfcc相似度的特征曲线图;
图5(ia)是本发明加噪语音信噪比=-10db的emd-wavelet的mfcc相似度的特征曲线图;
图5(ib)是本发明加噪语音信噪比=-10db的短时emd分解后teager能量平均值的特征曲线图;
图5(ic)是本发明加噪语音信噪比=-10db的小波分解短时系数平均幅值积的特征曲线图;
图5(id)是本发明加噪语音信噪比=-10db的短时mfcc倒谱距离值的特征曲线图;
图5(ie)是本发明加噪语音信噪比=-10db的短时短时能量的特征曲线图;
图5(iia)是本发明加噪语音信噪比=0db的emd-wavelet的mfcc相似度的特征曲线图;
图5(iib)是本发明加噪语音信噪比=0db的短时emd分解后teager能量平均值的特征曲线图;
图5(iic)是本发明加噪语音信噪比=0db的小波分解短时系数平均幅值积的特征曲线图;
图5(iid)是本发明加噪语音信噪比=0db的短时mfcc倒谱距离值的特征曲线图;
图5(iie)是本发明加噪语音信噪比=0db的短时短时能量的特征曲线图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明。
参见图1,图1是本发明的流程图。下面结合流程图对本发明的步骤作详细说明。
一种基于emd-wavelet的mfcc相似度的语音段检测方法,该方法包括如下步骤:
(1)对人说话的语音信号进行测量,采集到的语音信号作为源信号;
(2)利用emd对含噪的语音信号进行分解,得到体现语音信号高低频能量的各阶本征模函数(imf),其具体过程为:
(2.1)先分别找出整体信号的局部极值点,利用三次样条插值,分别形成信号的上包络和下包络。
(2.2)求出上、下包络的均值序列,将原信号减去该均值序列,得到该信号的差值序列。
(2.3)判断差值序列是否满足imf条件,否则用该差值序列替,跳转到步骤(1)直到均值趋近于零,该差值序列就是本次循环获得的imf。
(2.4)将原信号减去imf,得到该级imf对应的剩余项。
(2.5)对步骤(2.4)得到的第一个剩余项序作为原信号重复上述四个步骤,直到剩余项为单调函数为止。信号x(t)最终被分解成若干有限个imfi(t)(i=i~n)以及剩余项r(t),根据上述的emd的步骤,可以推断emd是一可逆过程,由此信号可以重构为:
(3)求各阶imf分量的自相关系数,以自相关函数的方差确定噪声为主导模态的imf阶数,对噪声为主导模态的imf进行小波阈值降噪,把降噪后的低阶imf分量和余下的高阶imf分量进行重构,获得降噪后的语音信号,其具体过程为:信号经emd分解后,通过求解各阶imf分量的自相关函数的方差判断各阶imf分量的噪声含量高低,判断前面k阶imf中噪声为主导模态,对前k阶imf进行阈值去噪,然后将去噪后的前k阶imf与余下的imf对信号进行重建,得到降噪后的语音信号,以上降噪步骤如下:
(3.1)对含噪信号x(t)进行emd分解,得到n个imf模态分量和余项r(t);
(3.2)分别计算出各imf分量的自相关函数,第i个imf分量的自相关函数表示为:ri(τ)=e[ci(t)ci(t+τ)],并对其进行归一化处理:ρi(τ)=ri[τ]/ri(0);
(3.3)求各阶imf归一化自相关函数方差,由方差衡量各阶imf分量的噪声含量,通过求取前k阶与所有imf自相关函数方差和的比值pk,确定要去噪的前k阶imf。
计算公式可表示为:
(3.4)对含噪高的低阶imf1(t)~imfk(t)通过sym8小波进行阈值消噪,得到去噪后的模态imf1'(t)~imfk'(t);
(3.5)重构原信号:则x'(t)为去噪后的信号。
其中,本文在小波去噪的方式上采用的是软阈值去噪。阈值确定准则为自适应史坦无偏估计(heursure),小波层数为4,小波基函数为sym8。
(4)计算语音信号的mel倒谱参数(mfcc),对比分析语音段和非语音段的参数特征,以欧氏距离作为语音信号mfcc相似度的测度,其具体过程为:
(4.1)提取各阶降噪后语音信号的各阶mel倒谱系数,计算所有帧的mfcc矢量。
(4.2)假定语音信号的前10帧为背景噪声,对前10帧mfcc矢量求平均,得到背景噪声mel倒谱矢量c0的近似值。
(4.3)求每一帧ci和c0的相似度d(ci,c0),计算各阶mfcc各帧与噪声帧的相似度均值,得到各阶mfcc相似度均值曲线,用于检测连续语音的端点。
其中,本发明选用euclidean(欧式)距离进行相似度测定,设向量x=(x1,x2,…xn)和向量y=(y1,y2…yn)的距离为d=(x,y),euclidean(欧式)距离表达式为:
提取语音信号的梅尔倒谱参数,其特点在于,求语音信号mel倒谱系数时,mel频率滤波器组个数为24,mfcc系数阶数为12。
(5)从相似度曲线中可以明显区分语音段和噪声段,从而从语音信号中实现语音段的提取。
图2(a)是本发明纯语音波形的语音时域波形图;图2(b)是本发明加噪语音信噪比=10db的语音时域波形图;图2(c)是本发明加噪语音信噪比=5db的语音时域波形图;图2(d)是本发明加噪语音信噪比=0db的语音时域波形图;图2(e)是本发明加噪语音信噪比=-5db的语音时域波形图;图2(f)是本发明加噪语音信噪比=-10db的语音时域波形图,语音信号选自标准语音库timit,噪音选自标准噪声库noise-98。所选语音编号为sx313,采样频率为16khz。实验参数如下:帧长为256;帧移为128;mfcc阶数为24。实验通过人工加载的方法,将噪声库中的白噪声加载到纯净的语音信号中,噪声比(snr/db)分别为-10db,-5db,0db,5db,10db。
附图3是经过emd分解后,各阶imf分量自相关系数方差占总方差的比例曲线图,从图中可明显看出前10阶imf分量的方差总和占所有阶的方差总和较低,为1.72%,因此认为前10阶imf分量占据了语音噪声的主要部分,对处于高频的前10阶imf分量消噪处理。
附图4是本发明加噪语音信噪比=-5db的emd-wavelet的mfcc相似度的特征曲线图,从图2(e)中时域波形中只能看出能量高的清音段,能量低的浊音段无法被检查。但从图4中的mfcc相似度曲线,可以看出部分能量低的浊音段仍然能被监测,曲线的变化规律在一定程度上与纯语音信号能量的变化规律具有一致性。
图5(ia)是本发明加噪语音信噪比=-10db的emd-wavelet的mfcc相似度的特征曲线图;图5(ib)是本发明加噪语音信噪比=-10db的短时emd分解后teager能量平均值的特征曲线图;
图5(ic)是本发明加噪语音信噪比=-10db的小波分解短时系数平均幅值积的特征曲线图;图5(id)是本发明加噪语音信噪比=-10db的短时mfcc倒谱距离值的特征曲线图;图5(ie)是本发明加噪语音信噪比=-10db的短时短时能量的特征曲线图;图5(iia)是本发明加噪语音信噪比=0db的emd-wavelet的mfcc相似度的特征曲线图;图5(iib)是本发明加噪语音信噪比=0db的短时emd分解后teager能量平均值的特征曲线图;图5(iic)是本发明加噪语音信噪比=0db的小波分解短时系数平均幅值积的特征曲线图;图5(iid)是本发明加噪语音信噪比=0db的短时mfcc倒谱距离值的特征曲线图;图5(iie)是本发明加噪语音信噪比=0db的短时短时能量的特征曲线图,从图中可以看出,本发明提到的方法,语音段和非语音段的特征参数区别更明显。
表1是不同信噪比下各方法语音段检测识别率,从表中可以看出,高信噪比情况下5种端点检测算法都具有良好的检测性能,但当噪声不断加大时,几种不同的语音段检测算法的性能下降也有所不同,本发明语音段检测的准确率更高,具有更好的鲁棒性和适应性,能够很好的应用于语音信号的语音段检测。
表1
- 还没有人留言评论。精彩留言会获得点赞!