一种基于大规模养殖场厂哺乳动物异常声音监测方法与流程
本发明属于声音识别领域,具体涉及一种无监督的声音识别方法。
背景技术:
声音识别技术应用广泛,在公共安全、医疗、智能养殖等各个领域都有研究。现有的技术中,声音识别技术多采用监督学习的方式,需要手动参与音频的分割和标注,声音处理和识别的过程较复杂,成本较高。2015年福州大学发明了一种基于声谱图双特征的动物声音识别方法(cn104882144a)通过建立声音样本库,对将预存声音样本及待识别的声音信号转化成声谱图,将声谱图进行规范化,并进行特征值分解和投影,以声音样本库中预存声音样本对应的双层特征集为训练样本集,以待识别的声音信号对应的双层特征为输入样本,通过随机森林的训练,得出待识别的声音信号于声音样本库中对应的类别并输出结果。此方法采用监督学习的方式实现声音识别,需手工标注大量数据,且实现过程复杂。2016年浙江大华技术有限公司发明了一种典型异常声音检测方法(cn105810213a)通过对采集到的声音进行预处理,获取有效信号片段的声谱图并根据声谱图确定待测试识别特征矩阵,用于表示声音信号在时频域上的声音强度分布情况,计算待测试识别特征矩阵与异常声音模型库中的各标准识别特征矩阵的相似度,根据计算结果确定所述有效信号片段中的异常声音类型。该方法用有监督的方式对音频进行预处理,且仅用声谱图的声音强度分布信息,很难实现高精度。2017年杭州华为数字技术有限公司发明了一种异常声音的分类方法和装置(cn106683687a)该方法通过对异常声音信号进行分帧处理,之后对每帧信号进行滤波处理,得到该异常声音信号的能量特征信息。根据该异常声音信号的能量特征信息,设置相应的阈值,进而确定该异常声音信号的分类结果。此方法需用监督学习的方式根据异常帧的能量设置阈值,阈值设置对分类准确度影响很大,且操作较为复杂,无法实现简便可靠识别的目的。
基于此,有必要提出一种简便实用的无监督的声音识别方法,能够自动的对音频分割且无需手工标注。
技术实现要素:
本发明提供了一种基于大规模养殖场厂哺乳动物异常声音监测方法,目的在于提出一种简便实用的无监督的声音识别方法,能够自动的对音频分割且无需手工标注。
本发明主要包括以下几个部分:
步骤一、谱图分析:对采集来的音频进行频谱、时频谱分析,以确定声音识别方案的可行性。
步骤二、音频降噪:对音频降噪处理,除去背景噪声,可提高声音识别的准确性。
步骤三、无监督音频分割:简化音频处理过程,无需手动切分即可得到包含所需声音事件的音频段。
步骤四、音频特征提取:本发明对音频采用的特征提取技术为mel频率倒谱系数。
步骤五、无监督分类:本发明采用的无监督分类方法为k均值算法。
本发明还进一步包括:
所述的谱图分析具体为:采用audacity软件打开音频文件,选择spectrogram选项即可快速做出声音信号的时频谱图。时频谱即声谱图,横轴表示时间,纵轴表示频率,谱图颜色的深浅代表能量大小,可以反映出声音的三维信息,即是信号的原始特征。为了进一步得到不同频率下的能量分布,又分别作出了不同类别声音信号的频谱。通过分析得到不同类别声音的谱图特征存在有明显的差异,利用这些差异性即可对声音信号进行特征提取,分类识别。因此,可以得出声音识别方案的可行性。
所述的音频降噪操作具体为:降噪用audacity软件实现,先获取一段时间背景噪声的特征,再应用到整段音频上。操作步骤如下:打开音频文件,选中噪声段,选择effect->noisereduction->getnoiseprofile,即可获取噪声特征;之后选择edit->selectall,选中整段音频,重新执行降噪过程effect->noisereduction->ok,完成整段音频的降噪处理。
所述的无监督音频分割包括如下步骤:
第一步:提取短时特征。对每个帧长为25ms短时窗口进行特征提取,得到34维的特征向量,包括3维时域特征(过零率、短时能量、能量熵值)和31维的频域特征(频谱质心、频谱熵、mel频率倒谱系数等)。
第二步:训练支持向量机。支持向量机模型被训练以区分高能帧和低能帧。首先根据特征提取中每帧的能量,取出能量最高的前10%和能量最低的后10%,分别标记为高能帧和低能帧,进而用这些标记的数据作为训练集,训练二分类的支持向量机来区分高能帧和低能帧。
第三步:用训练好的支持向量机分类器应用到整段音频,输出一系列概率值,这些概率值对应于各个短时帧属于音频事件的置信水平。这样即可得到整段音频中每帧信号属于音频事件可能性大小的连续概率曲线,横轴表示的对应音频的时间轴,纵轴对应于支持向量机预测出的概率值。
第四步:动态阈值处理用于检测音频事件。通过对第三步得到的每帧为音频事件的概率值,设置不同的平滑系数smoothing和概率阈值系数weight,可得到不同的概率曲线。通过合适的参数设置,可实现精确的音频切分。即对于连续性较强的声音信号,需设置较小的smoothing和较大的weight;对于较稀疏的突发性声音信号,需设置较大的smoothing和较小的weight。本发明对不同参数条件下音频的切分效果进行了对比,最终确定了分割效果较好平滑系数(smoothing,0.5)和概率阈值系数(weight,0.3)进行切分。
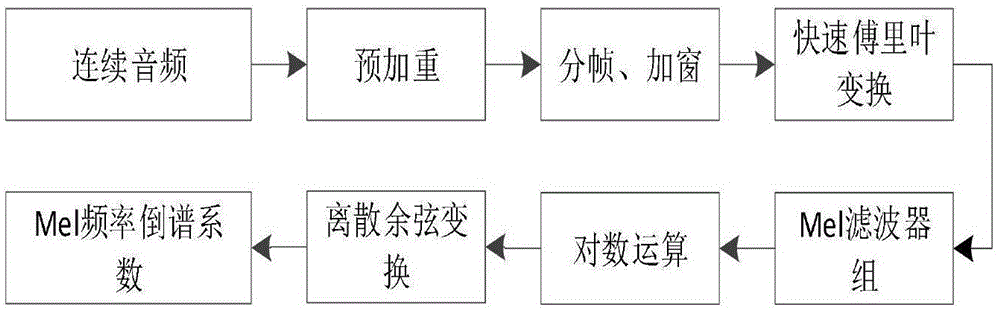
所述的音频特征提取具体为:对音频采用的特征提取技术为mel频率倒谱系数,mel频率倒谱系数是在mel标度频率域提取出来的倒谱参数,倒谱和梅尔频率倒谱之间的差别是在mel频率倒谱系数中,频带在梅尔刻度上是等间隔的,这种参数比基于声道模型的线性预测倒谱系数相比具有更好的鲁棒性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。mel频率倒谱系数特征提取流程图如图1所示。
标准的倒谱参数mel频率倒谱系数只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述。在声音的特征参数中结合表征动态特性的差分参数,能有效的改善系统的识别率、识别精度、识别范围。因此本发明采用的mel频率倒谱系数参数的全部组成为:n维mel频率倒谱系数参数(n/3mel频率倒谱系数+n/3一阶差分参数+n/3二阶差分参数)+帧能量。离散余弦变换的阶数取13,经一阶和二阶差分后即为39维,加上帧能量,最后用于分类的音频特征为40维的mel频率倒谱系数特征向量。
所述的无监督分类步骤如下:采用的无监督分类方法为k均值算法。对提取的mel频率倒谱系数进行标准差归一化的预处理后,进行无监督的聚类方法进行分类,主要包括以下四步:
第一步:随机选择k个初始中心点;
第二步:遍历所有样本,把每个样本划分到最近的中心点;
第三步:计算每个聚类的平均值,并作为新的中心点;
第四步:重复第二步、第三步、至这k个点不再变化,即算法收敛。
与现有技术相比,本发明的优势在于:本发明提供了一种基于大规模养殖场厂哺乳动物异常声音监测方法,该方法是一种简便实用的无监督的声音识别方法,能够自动的对音频分割且无需手工标注。通过采用无监督的音频分割技术和k均值的分类方法,结合频谱、时频谱分析技术,音频降噪技术,mel频率倒谱系数特征提取技术,实现了对大规模养殖场动物无监督的声音识别。
附图说明
图1为mel频率倒谱系数特征提取流程图;
图2为本发明的整体流程图;
图3为降噪前的声谱图;
图4为降噪后的声谱图;
图5为音频切割示意图;
图6为对特征向量进行k-means聚类并对结果进行pca(主成分分析)降维可视化的效果图。
具体实施方式
下面结合附图与实施例对本发明作进一步的说明:
本发明的整体框图如图2所示。首先对采集到的音频进行时频谱、频谱分析,选取了三种状态下的声音。分别为动物在正常状态时的叫声,看到食物的叫声及受到惊吓时的叫声的谱图,包括时频谱和频谱。通过谱图分析,确定了不同状态下声音的频谱、时频谱有明显差异,利用这些差异性,确定音频识别方案的可行性。图3为降噪前音频的声谱图,图4为降噪后的声谱图。图5为音频切割示意图,支持向量机预测出一系列概率值,并确定了合适的平滑系数(smoothing,0.5)和概率阈值系数(weight,0.3)进行切分。切分得到音频用于特征提取及分类识别。图6为对特征向量进行k-means聚类,并对结果进行pca(主成分分析)降维可视化的效果图。
本发明中,在大型养殖场采集到不同状态下的动物声音,经过谱图分析和降噪、无监督的音频分割等预处理后,对得到的音频段进行mel频率倒谱系数特征提取,对提取得到的多维特征向量进行标准差归一化后,采用k均值聚类的方式进行分类。
实施例:
第一步:采集音频,得到动物正常状态时的叫声,看到食物的叫声及受到惊吓时的叫声的音频段。音频采样频率为16khz、mono单通道。
第二步:对不同状态下的音频进行频谱、时频谱分析,确定谱图信息的差异性。
第三步:对音频进行降噪处理,首先获取背景噪声的特征,进而应用到待处理的整段音频上来除去背景噪声,防止大型养殖场嘈杂背景的干扰。
第四步:对音频采用无监督的分割方法,简化音频处理过程,无需手动切分即可得到包含所需声音事件的音频段。首先提取短时特征。对每个帧长为25ms短时窗口进行特征提取,得到34维的特征向量,包括3维时域特征(过零率、短时能量、能量熵值)和31维的频域特征(频谱质心、频谱熵、mel频率倒谱系数等)。然后训练支持向量机。支持向量机模型被训练区分高能帧和低能帧,用10%的最低能帧和10%的最高能帧训练支持向量机模型。之后把支持向量机分类器应用到整段音频,输出一系列概率值,这些概率值对应于各个短时帧属于音频事件的置信水平。最后通过动态阈值处理,检测分割出音频事件。在本实验中选择的合适的平滑系数(smoothing)为0.5,概率阈值系数(weight)为0.3来对音频进行切分。
第五步:对分割后的音频进行mel频率倒谱系数特征提取。
第六步:对mel频率倒谱系数特征进行标准差归一化处理。
第七步:用k均值聚类的方法进行分类处理。
第八步:对聚类结果进行pca降维,在三维空间可视化。
- 还没有人留言评论。精彩留言会获得点赞!