一种语音识别方法和语音识别系统与流程
本发明涉及语音识别技术领域,尤其涉及一种语音识别方法和语音识别系统。
背景技术:
语音识别系统选择识别基元的要求是,有准确的定义,能得到足够数据进行训练,具有一般性。英语通常采用上下文相关的音素建模,汉语的协同发音不如英语严重,可以采用音节建模。系统所需的训练数据大小与模型复杂度有关。模型设计得过于复杂以至于超出了所提供的训练数据的能力,会使得性能急剧下降。
现有技术中,通过麦克风输入语音信息,如果输入错误只能删除重新输入,不利于语音信息快速识别,降低工作效率。
技术实现要素:
本发明所要解决的技术问题在于,提供一种在输入语音信息存在错误时,在不删除已经输入的语音信息的情况下,能够快速识别语音信息的语音识别方法。
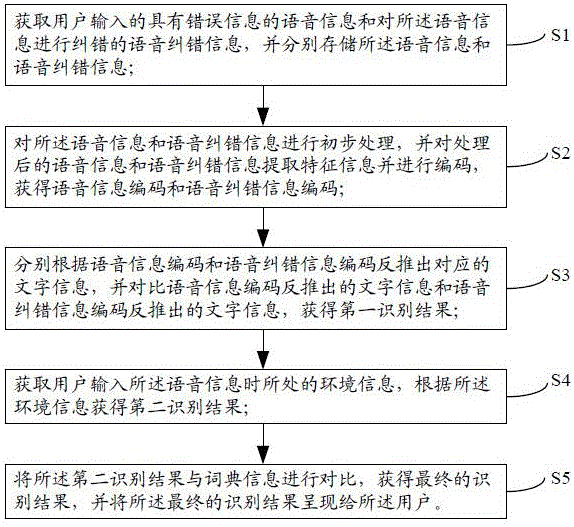
为了解决上述技术问题,本发明提供一种语音识别方法,该方法包括如下步骤:
s1、获取用户输入的具有错误信息的语音信息和对所述语音信息进行纠错的语音纠错信息,并分别存储所述语音信息和语音纠错信息;
s2、对所述语音信息和语音纠错信息进行初步处理,并对处理后的语音信息和语音纠错信息提取特征信息并进行编码,获得语音信息编码和语音纠错信息编码;
s3、分别根据语音信息编码和语音纠错信息编码反推出对应的文字信息,并对比语音信息编码反推出的文字信息和语音纠错信息编码反推出的文字信息,获得第一识别结果;
s4、获取用户输入所述语音信息的环境信息,根据所述环境信息获得第二识别结果;
s5、将所述第二识别结果与词典信息进行对比,获得最终的识别结果,并将所述最终的识别结果呈现给所述用户。
其中,所述步骤s2中对所述语音信息和语音纠错信息进行初步处理具体包括:
分别对所述语音信息和语音纠错信息进行滤波处理,并分别对滤波处理后的语音信息和语音纠错信息进行采样;
分别对采样后的语音信息和采样后的语音纠错信息进行编码,获得语音信息编码和语音纠错信息编码。
其中,在所述步骤s3具体包括:
将所述语音信息编码与现有的声学模型和语音模型进行对比,获得所述语音信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音信息编码对应的第一文字信息;
将所述语音纠错信息编码与现有的声学模型和语音模型进行对比,获得所述语音纠错信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音纠错信息编码对应的第二文字信息;
将所述第一文字信息和所述第二文字信息进行对比,获取相似度最高的第一文字信息和第二文字信息,并用所述第二文字信息替换第一文字信息中与所述第二文字信息相似的部分,形成第一识别结果。
其中,所述声学模型为隐马尔科夫模型。
其中,所述步骤s4具体包括:
采集用户输入所述语音信息所处环境的图像,并识别出图像中的环境信息,
根据所述环境信息获得所述用户的可能需求,根据所述可能需求筛选出第二识别结果。
其中,所述步骤s5具体包括:
将所述第二识别结果与词典信息进行对比,剔除不符合语言格式的第二识别结果,获得第三识别结果;
将第三识别结果与用户存储的识别结果进行相似度对比,并按照相似度从大到小的顺序进行排列,展示给用户。
本发明提供一种语音识别系统,所述系统包括:
获取单元,用于获取用户输入的具有错误信息的语音信息和对所述语音信息进行纠错的语音纠错信息,并分别存储所述语音信息和语音纠错信息;
处理单元,用于对所述语音信息和语音纠错信息进行初步处理,并对处理后的语音信息和语音纠错信息提取特征信息并进行编码,获得语音信息编码和语音纠错信息编码;
反推识别单元,用于分别根据语音信息编码和语音纠错信息编码反推出对应的文字信息,并对比语音信息编码反推出的文字信息和语音纠错信息编码反推出的文字信息,获得第一识别结果;
环境识别单元,用于获取用户输入所述语音信息的环境信息,根据所述环境信息获得第二识别结果;
对比识别单元,用于将所述第二识别结果与用户存储的识别结果进行对比,获得最终的识别结果,并将所述最终的识别结果呈现给所述用户。
其中,所述反推识别单元包括:
第一对比反推单元,用于将所述语音信息编码与现有的声学模型和语音模型进行对比,获得所述语音信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音信息编码对应的第一文字信息;
第二对比反推单元,将所述语音纠错信息编码与现有的声学模型和语音模型进行对比,获得所述语音纠错信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音纠错信息编码对应的第二文字信息;
对比替换单元,将所述第一文字信息和所述第二文字信息进行对比,获取相似度最高的第一文字信息和第二文字信息,并用所述第二文字信息替换第一文字信息中与所述第二文字信息相似的部分,形成第一识别结果。
本发明实施例的有益效果在于:本发明通过对获取的语音信息和语音纠错信息进行编码,并根据语音信息编码和语音纠错信息编码分别获得反推文字信息,对比两者的反推文字信息,将相似度高的语音纠错信息编码对应的文字信息替换语音信息编码中的反推文字信息从而获得第一识别结果,获取用户输入语音信息所处的环境信息,并根据环境信息对第一识别结果进行筛选获得第二识别结果,通过将第二识别结果与词典信息进行对比从而获得最终的识别结果。本发明实施例的语音识别方法,在语音输入存在错误时,无需删除重新输入,有利于语音信息快速识别,提高工作效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例的一种语音识别方法的流程示意图。
图2是本发明实施例的一种语音识别系统的结构示意图。
具体实施方式
以下各实施例的说明是参考附图,用以示例本发明可以用以实施的特定实施例。
以下参照图1进行说明,本发明实施例一提供一种语音识别方法,该方法包括如下步骤:
s1、获取用户输入的具有错误信息的语音信息和对所述语音信息进行纠错的语音纠错信息,并分别存储所述语音信息和语音纠错信息。
具体地,通过语音录入选项进行语音录入,该录入的语音信息中存在错误信息,在录入过程中如果出现较小的差错,选择语音纠错录入选项进行纠错录入,纠错录入只需要录入错误的部位,纠错录入的信息为语音纠错信息,将语音信息和语音纠错信息分别进行存储。
举例说明,假设用于期望录入的语音信息为“寻找最近的加油站”,用户在录入的过程中,由于某种原因,录入的语音信息为“寻找近的加油站”,用户选择语音纠错录入选项,录入的语音纠错信息为“最近的”。
s2、对所述语音信息和语音纠错信息进行初步处理,并对处理后的语音信息和语音纠错信息提取特征信息并进行编码,获得语音信息编码和语音纠错信息编码。
具体地,对语音信息和语音纠错信息进行滤波处理,消除语音信息和语音纠错信息中的噪音和回声,增加语音信息和语音纠错信息的质量,对滤波后的语音信息和语音纠错信息进行采样,通过a/d转换器将模拟信号转换成数字信号,分别对语音信息转换后的数字信号和语音纠错信息转换后的数字信号进行编码并提取特征信息,获取语音信息编码和语音纠错信息编码。
特征信息为频率倒谱系数mfcc特征,频率倒谱系数mfcc特征是基于声音频率的非线性梅尔刻度(mel刻度)的对数能量线谱的线性变换,首先用fft将时域信号转化成频域,之后对其对数能量谱用依照mel刻度分布的三角滤波器组进行卷积,最后对各个滤波器的输出构成的向量进行离散余弦变换dct,取前n个系数,plp仍用德宾法去计算lpc参数,但在计算自相关参数时用的也是对听觉激励的对数能量谱进行dct的方法。对语音信息进行初步处理,从而能提升语音信息和纠错语音信息的质量,有助于提升后续识别的质量。
s3、分别根据语音信息编码和语音纠错信息编码反推出对应的文字信息,并对比语音信息编码反推出的文字信息和语音纠错信息编码反推出的文字信息,获得第一识别结果。
具体地,将所述语音信息编码与现有的声学模型和语音模型进行对比,获得所述语音信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音信息编码对应的第一文字信息;将所述语音纠错信息编码与现有的声学模型和语音模型进行对比,获得所述语音纠错信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音纠错信息编码对应的第二文字信息;将所述第一文字信息和所述第二文字信息进行对比,获取相似度最高的第一文字信息和第二文字信息,并用所述第二文字信息替换第一文字信息中与所述第二文字信息相似的部分,形成第一识别结果。
声学模型是语音识别系统中最为重要的部分之一,目前的主流系统多采用隐马尔科夫模型进行建模,隐马尔可夫模型的概念是一个离散时域有限状态自动机,隐马尔可夫模型hmm是指这一马尔可夫模型的内部状态外界不可见,外界只能看到各个时刻的输出值,语言模型是一个单纯的、统一的、抽象的形式系统,语言客观事实经过语言模型的描述,比较适合于电子计算机进行自动处理,因而语言模型对于自然语言的信息处理具有重大的意义,经过对比和分析,从而组合出符合的选项,每个音符都有相对的编码,与已经存储好的声学模型和语言模型进行对比,进而选择出所有相近的编码,完成初步识别,有助于提升初步识别的效率和质量,声学模型的输出值通常就是从各个帧计算而得的声学特征,这些特征就是声学的编码,而语言模型是根据语言客观事实而进行的语言抽象数学建模,而这些特征就是语言的编码,从而方便和采集到的语音编码进行交叉对比,从而得出的结果中在进行对比,选择相识度最高的,进而能根据编码反推出文字信息。
举例说明,以“寻找最近的加油站”为例,通过声学模型和语音模型获得了相似度最高的编码,从而能反推出多组文字信息,再通过语音纠错信息和语音信息之间的对比,进而能选择出相似度最高的语音信息和语音纠错信息,例如“寻找近的加油站”中“近的”和纠错语音信息中的“最近的”相似对最好,从而能进行替换,作为备选之一,当然也有可能识别成“训罩进德架游展”,而纠错语音信息识别成“嘴进德”,该组进行替换,则变成了“训罩嘴进德架游展”当成备选之一,当然也有可能出现“训罩嘴紧的加油站”这种备选,由此可见,该第一识别结果是“寻找近的加油站”或者“训罩嘴紧的加油站”或者“训罩嘴进德架游展”。
s4、获取用户输入所述语音信息时所处的环境信息,根据所述环境信息获得第二识别结果。
具体地,通过摄像设备拍摄用户输入所述语音信息时的周边情况的环境照片,摄像设备采用高清红外摄像器,从而识别出用于当时所处的环境,通过识别用户所处的环境位置,进而能大致判断出使用者的需求,举例说明,用户所处的环境位置可能是市区、公路、郊区,与市区关联度较大的名词可能是市区中的办公楼、小区或者酒店,与公路关联较大的名词可能是公路上的加油站、停车场、修车厂等,与郊区关联较大的可能是郊区村庄名称等。通过识别用户所在的位置信息,从而可以获得跟对应的位置信息关联较大的名词,根据关联较大的名词可以将第一识别结果中明显不符合的识别结果剔除。
举例说明,仍然以“寻找最近的加油站”为例,通过获取用户输入语音信息的照片,可知用户当时处于公路上,根据与公路关联最大的名词可能是公路上的加油站、停车场、修车厂等,因而可以将第一识别结果中的“训罩嘴进德架游展”剔除,从而获得第二识别结果“寻找近的加油站”或者“训罩嘴紧的加油站”。
s5、将所述第二识别结果与存储的词典信息进行对比,获得最终的识别结果,并将所述最终的识别结果呈现给所述用户。
通过将第二识别结果与存储的词典信息进行对比,将明显不符合语言规则的识别结果信息进行删除,从而获得最终识别结果,将最终识别结果与用户存储的过往识别信息进行对比,获得每一个最终识别结果的相似度,按照相似度从大到小的顺序向用户展示所述最终识别结果,便于用户对所述最终的识别结果进行查询,从而选择用户预期的识别结果,提高识别的效率和质量。
当用户选择了最终的识别结果后,通过扬声器进行播放,将正确的识别结果进行存储,方便提醒其他人员,从而再次确定识别结果,将识别结果进行存储,从而便于进行扩充,方便使用者下次使用。
本发明实施例的一种语音识别方法,通过对获取的语音信息和语音纠错信息进行编码,并根据语音信息编码和语音纠错信息编码分别获得反推文字信息,对比两者的反推文字信息,将相似度高的语音纠错信息编码对应的文字信息替换语音信息编码中的反推文字信息从而获得第一识别结果,获取用户输入语音信息所处的环境信息,并根据环境信息对第一识别结果进行筛选获得第二识别结果,通过将第二识别结果与词典信息进行对比从而获得最终的识别结果。本发明实施例的语音识别方法,在语音输入存在错误时,无需删除重新输入,有利于语音信息快速识别,提高工作效率。
基于本发明实施例一,本发明实施例二提供一种语音识别系统,如图2所示,该系统1包括:
获取单元11,用于获取用户输入的语音信息和对输入的语音信息进行纠错的语音纠错信息,并分别存储所述语音信息和语音纠错信息;
处理单元12,用于对所述语音信息和语音纠错信息进行初步处理,并对处理后的语音信息和语音纠错信息提取特征信息并进行编码,获得语音信息编码和语音纠错信息编码;
反推识别单元13,用于分别根据语音信息编码和语音纠错信息编码反推出对应的文字信息,并对比语音信息编码反推出的文字信息和语音纠错信息编码反推出的文字信息,获得第一识别结果;
环境识别单元14,用于获取用户输入所述语音信息的环境信息,根据所述环境信息剔除所述初步识别结果中与所述环境信息不相关的识别结果,获得第二识别结果;
对比识别单元15,用于将所述第二识别结果与用户存储的识别结果进行对比,获得最终的识别结果,并将所述最终的识别结果呈现给所述用户。
其中,所述反推识别单元13包括:
第一对比反推单元,用于将所述语音信息编码与现有的声学模型和语音模型进行对比,获得所述语音信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音信息编码对应的第一文字信息;
第二对比反推单元,将所述语音纠错信息编码与现有的声学模型和语音模型进行对比,获得所述语音纠错信息编码与所述声学模型和语音模型的相似编码,并根据相似编码反推出所述语音纠错信息编码对应的第二文字信息;
对比替换单元,将所述第一文字信息和所述第二文字信息进行对比,获取相似度最高的第一文字信息和第二文字信息,并用所述第二文字信息替换第一文字信息中与所述第二文字信息相似的部分,形成第一识别结果。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!