一种基于深度学习的多人语音分离方法与流程
本发明涉及语音分离技术领域,尤其涉及一种基于深度学习的多人语音分离方法。
背景技术:
说话人分离技术是从多个说话人的混合语音信号中,分别提取出每一个说话人的语音信号。该技术对目标说话人检测、语音识别等具有重要意义。
由于语音信号的复杂性和不稳定性,传统的分离方法达不到很好的分离效果,并且以往的分离中只对目标信号的频谱幅度进行估计。
技术实现要素:
本发明的目的在于解决现有技术存在的缺陷。
为达到上述目的,一种基于深度学习的多人语音分离方法,包括步骤:
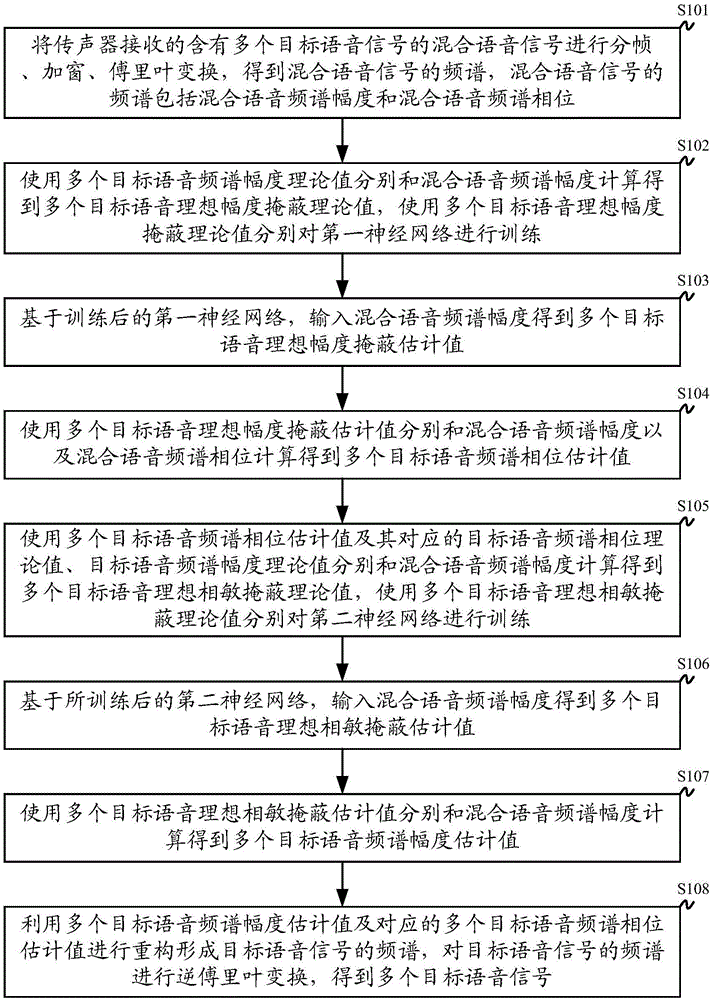
将传声器接收的含有多个目标语音信号的混合语音信号进行分帧、加窗、傅里叶变换,得到混合语音信号的频谱,混合语音信号的频谱包括混合语音频谱幅度和混合语音频谱相位;
使用多个目标语音频谱幅度理论值分别和混合语音频谱幅度计算得到多个目标语音理想幅度掩蔽理论值,使用多个目标语音理想幅度掩蔽理论值分别对第一神经网络进行训练;
基于训练后的第一神经网络,输入混合语音频谱幅度得到多个目标语音理想幅度掩蔽估计值;
使用多个目标语音理想幅度掩蔽估计值分别和混合语音频谱幅度以及混合语音频谱相位计算得到多个目标语音频谱相位估计值;
使用多个目标语音频谱相位估计值及其对应的目标语音频谱相位理论值、目标语音频谱幅度理论值分别和混合语音频谱幅度计算得到多个目标语音理想相敏掩蔽理论值,使用多个目标语音理想相敏掩蔽理论值分别对第二神经网络进行训练;
基于所训练后的第二神经网络,输入混合语音频谱幅度得到多个目标语音理想相敏掩蔽估计值;
使用多个目标语音理想相敏掩蔽估计值分别和混合语音频谱幅度计算得到多个目标语音频谱幅度估计值;
利用多个目标语音频谱幅度估计值及对应的多个目标语音频谱相位估计值进行重构形成目标语音信号的频谱,对目标语音信号的频谱进行逆傅里叶变换,得到多个目标语音信号。
优选的,将传声器接收的含有多个目标语音信号的混合语音信号进行分帧、加窗、傅里叶变换,得到混合语音信号的频谱的步骤,具体为,
取每32ms采样点为一帧信号,其中,若采样率8khz时对应256个采样点,若采样频率为16khz时对应为512个采样点,若长度不足32ms则先将采样点补零到256或512个;然后对每一帧信号进行加窗,加窗函数采用汉明窗或汉宁窗。
优选的,目标语音理想幅度掩蔽理论值为:
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,|xj(k,l)|为第j个目标语音频谱幅度理论值,|y(k,l)|为混合语音频谱幅度。
优选的,使用多个目标语音理想幅度掩蔽理论值分别对第一神经网络进行训练的步骤,具体为,
将混合语音频谱幅度输入未训练的第一神经网络,通过第一神经网络输出各目标语音理想幅度掩蔽估计值,目标语音理想幅度掩蔽估计值和目标语音理想幅度掩蔽理论值进行均方误差迭代,进而最小化均方误差,以此对第一神经网络进行训练,使第一神经网络输出目标语音理想幅度掩蔽理论值逼近于目标语音理想幅度掩蔽的理论值。
优选的,使用多个目标语音理想幅度掩蔽估计值分别和混合语音频谱幅度以及混合语音频谱相位计算得到多个目标语音频谱相位估计值的步骤,具体为,
a)多个目标语音理想幅度掩蔽估计值分别和混合语音信号的频谱合成,得到多个中介信号估计值的初始频谱:
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,
b)对各中介信号估计值的初始频谱进行逆傅里叶变换,得到多个中介信号估计值
c)计算混合语音信号与多个中介信号估计值之和的误差:
其中,y为混合语音信号,j为混合语音中所含目标语音的个数;
d)将误差平均分配到各中介信号估计值形成误差补偿后的中介信号估计值
e)对误差补偿后的中介信号估计值进行傅里叶变换得到误差补偿后的中介信号估计值的频谱,其中包含目标语音频谱相位估计值:
其中,stft[]为傅里叶变换,∠为取相位操作;
f)利用多个目标语音理想幅度掩蔽估计值及其对应的目标语音频谱相位估计值,分别和混合语音频谱幅度合成,得到多个中介信号估计值的频谱
用
优选的,目标语音理想相敏掩蔽理论值为:
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,|xj(k,l)|为第j个目标语音频谱幅度理论值,|y(k,l)|为混合语音频谱幅度,θj为第j个目标语音频谱相位理论值,
优选的,使用多个目标语音理想相敏掩蔽理论值分别对第二神经网络进行训练的步骤,具体为,
将混合语音频谱幅度输入未训练的第二神经网络,通过第二神经网络输出各目标语音理想相敏掩蔽估计值,目标语音理想相敏掩蔽估计值和目标语音理想相敏掩蔽理论值进行均方误差迭代,进而最小化均方误差,以此对第二神经网络进行训练,使第二神经网络输出目标语音理想相敏掩蔽理论值逼近于目标语音理想相敏掩蔽的理论值。
优选的,目标语音频谱幅度估计值为:
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,
本发明的优点在于:不仅对目标信号的频谱幅度进行了估计,同时还对目标信号的频谱相位进行估计,并且提出分别估计目标的理想幅度掩蔽和相敏掩蔽用于目标信号的相位估计和幅度恢复,以使幅度和相位估计的效果最优。用理想幅度掩蔽恢复相位比其它掩蔽效果更优;用相敏掩蔽估计幅度可对相位估计的误差进行补偿,在信号相位确定的情况下用相敏掩蔽估计幅度比其它掩蔽更优。同时进行频谱幅度估计和频谱相位估计比只估计频谱幅度效果更优。
附图说明
为了更清楚说明本发明实施例的技术方案,下面将对实施例描述中所需使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为一种基于深度学习的多人语音分离方法流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为一种基于深度学习的多人语音分离方法流程图。如图1所示,包括步骤:
步骤s101:将传声器接收的含有多个目标语音信号的混合语音信号进行分帧、加窗、傅里叶变换,得到混合语音信号的频谱,混合语音信号的频谱包括混合语音频谱幅度和混合语音频谱相位。
在一个具体实施例中,取每32ms采样点为一帧信号,其中,若采样率8khz时对应256个采样点,若采样频率为16khz时对应为512个采样点,若长度不足32ms则先将采样点补零到256或512个;然后对每一帧信号进行加窗,加窗函数采用汉明窗或汉宁窗。
步骤s102:使用多个目标语音频谱幅度理论值分别和混合语音频谱幅度计算得到多个目标语音理想幅度掩蔽理论值
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,|xj(k,l)|为第j个目标语音频谱幅度理论值,|y(k,l)|为混合语音频谱幅度。
使用多个目标语音理想幅度掩蔽理论值分别对第一神经网络进行训练。
在一个具体实施例中,将混合语音频谱幅度输入未训练的第一神经网络,通过第一神经网络输出各目标语音理想幅度掩蔽估计值,目标语音理想幅度掩蔽估计值和目标语音理想幅度掩蔽理论值进行均方误差迭代,进而最小化均方误差,以此对第一神经网络进行训练,使第一神经网络输出目标语音理想幅度掩蔽理论值逼近于目标语音理想幅度掩蔽的理论值。
步骤s103:基于训练后的第一神经网络,输入混合语音频谱幅度得到多个目标语音理想幅度掩蔽估计值。
步骤s104:使用多个目标语音理想幅度掩蔽估计值分别和混合语音频谱幅度以及混合语音频谱相位计算得到多个目标语音频谱相位估计值。
在一个具体实施例中,包括:
步骤a)多个目标语音理想幅度掩蔽估计值分别和混合语音信号的频谱合成,得到多个中介信号估计值的初始频谱:
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,
步骤b)对各中介信号估计值的初始频谱进行逆傅里叶变换,得到多个中介信号估计值
步骤c)计算混合语音信号与多个中介信号估计值之和的误差:
其中,y为混合语音信号,j为混合语音中所含目标语音的个数;
步骤d)将误差平均分配到各中介信号估计值形成误差补偿后的中介信号估计值
步骤e)对误差补偿后的中介信号估计值进行傅里叶变换得到误差补偿后的中介信号估计值的频谱,其中包含目标语音频谱相位估计值:
其中,stft[]为傅里叶变换,∠为取相位操作;
步骤f)利用多个目标语音理想幅度掩蔽估计值及其对应的目标语音频谱相位估计值,分别和混合语音频谱幅度合成,得到多个中介信号估计值的频谱
用
步骤s105:使用多个目标语音频谱相位估计值及其对应的目标语音频谱相位理论值、目标语音频谱幅度理论值分别和混合语音频谱幅度计算得到多个目标语音理想相敏掩蔽理论值
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,|xj(k,l)|为第j个目标语音频谱幅度理论值,|y(k,l)|为混合语音频谱幅度,θj为第j个目标语音频谱相位理论值,
使用多个目标语音理想相敏掩蔽理论值分别对第二神经网络进行训练。
在一个具体实施例中,将混合语音频谱幅度输入未训练的第二神经网络,通过第二神经网络输出各目标语音理想相敏掩蔽估计值,目标语音理想相敏掩蔽估计值和目标语音理想相敏掩蔽理论值进行均方误差迭代,进而最小化均方误差,以此对第二神经网络进行训练,使第二神经网络输出目标语音理想相敏掩蔽理论值逼近于目标语音理想相敏掩蔽的理论值。
步骤s106:基于所训练后的第二神经网络,输入混合语音频谱幅度得到多个目标语音理想相敏掩蔽估计值;
步骤s107:使用多个目标语音理想相敏掩蔽估计值分别和混合语音频谱幅度计算得到多个目标语音频谱幅度估计值
其中,k为信号频谱的频率帧索引,l为信号频谱的时间帧索引,
步骤s108:利用多个目标语音频谱幅度估计值及对应的多个目标语音频谱相位估计值进行重构形成目标语音信号的频谱,对目标语音信号的频谱进行逆傅里叶变换,得到多个目标语音信号。
本发明提供了一种基于深度学习的多人语音分离方法。不仅对目标信号的频谱幅度进行了估计,同时还对目标信号的频谱相位进行估计,并且提出分别估计目标的理想幅度掩蔽和相敏掩蔽用于目标信号的相位估计和幅度恢复,以使幅度和相位估计的效果最优。用理想幅度掩蔽恢复相位比其它掩蔽效果更优;用相敏掩蔽估计幅度可对相位估计的误差进行补偿,在信号相位确定的情况下用相敏掩蔽估计幅度比其它掩蔽更优。同时进行频谱幅度估计和频谱相位估计比只估计频谱幅度效果更优。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!