一种基于LLD和DSS融合特征的语音情感识别方法与流程
本发明属于人工智能和语音识别领域,尤其涉及一种基于lld和dss融合特征的语音情感识别方法。
背景技术:
近年来,随着计算机技术的发展,人机交互(hmi)技术也得到了长足的进步,但还远不能达到人机充分沟通的水平。因为机器很难理解隐含在语言中的一些副语言信息,情绪就是其中之一。语音情感识别(ser)的基本任务,旨在通过语音信号对讲话者情绪状态进行分类,使hmi更加自然和现实。尽管国内外科研人员对ser已经开展了广泛的研究,但迄今为止,ser系统的性能相对较低,仍然无法实际应用。
语音情感识别的主要工作分为语音情感特征提取和分类网络模型选择。当前国内外的研究对象多为分类网络模型选择,且在分类模型上已经取得较大进展。语音情感识别中最常用的分类模型是支持向量机[1](svm),人工神经网络[2](ann),k最近邻算法[3](knn),elman神经网络[4],长短时神经网络[5](lstm)等,这些模型大多采用interspeech知识竞赛所采用的底层描述符(lld)情感特征,很少有针对网络优化的情感特征。因此,如何挖掘潜在特征并提高识别率,仍待研究。
参考文献
[1]linyl,weig.speechemotionrecognitionbasedonhmmandsvm[c]//machinelearningandcybernetics,2005.proceedingsof2005internationalconferenceon.ieee,2005,8:4898-4901.
[2]hank,yud,tashevi.speechemotionrecognitionusingdeepneuralnetworkandextremelearningmachine[c]//fifteenthannualconferenceoftheinternationalspeechcommunicationassociation.2014.
[3]schullerb,rigollg,langm.speechemotionrecognitioncombiningacousticfeaturesandlinguisticinformationinahybridsupportvectormachine-beliefnetworkarchitecture[c]//acoustics,speech,andsignalprocessing,2004.proceedings.(icassp'04).ieeeinternationalconferenceon.ieee,2004,1:i-577.
[4]余伶俐,周开军,邱爱兵.基于elman神经网络的语音情感识别应用研究[j].计算机应用研究,2012,29(5):1809-1814.
[5]
[6]andénj,mallats.deepscatteringspectrum[j].ieeetransactionsonsignalprocessing,2014,62(16):4114-4128.
[7]dengj,zhangz,eybenf,etal.autoencoder-basedunsuperviseddomainadaptationforspeechemotionrecognition[j].ieeesignalprocessingletters,2014,21(9):1068-1072.
[8]zhengf,zhangg,songz.comparisonofdifferentimplementationsofmfcc[j].journalofcomputerscienceandtechnology,2001,16(6):582-589.
[9]guojm,markonih.driverdrowsinessdetectionusinghybridconvolutionalneuralnetworkandlongshort-termmemory[j].multimediatoolsandapplications,2018:1-29.
[10]morchidm,bousquetpm,khederwb,etal.latenttopic-basedsubspacefornaturallanguageprocessing[j].journalofsignalprocessingsystems,2018:1-21.
[11]hochreiters,schmidhuberj.longshort-termmemory[j].neuralcomputation,1997,9(8):1735-1780.
[12]burkhardtf,paeschkea,rolfesm,etal.adatabaseofgermanemotionalspeech[c]//nintheuropeanconferenceonspeechcommunicationandtechnology.2005.
[13]livingstonesr,peckk,russofa.ravdess:theryersonaudio-visualdatabaseofemotionalspeechandsong[c]//annualmeetingofthecanadiansocietyforbrain,behaviourandcognitivescience.2012:205-211.
[14]jacksonp,haqs.surreyaudio-visualexpressedemotion(savee)database[j].universityofsurrey:guildford,uk,2014.
技术实现要素:
发明目的:本发明针对现有语音情感特征在进行分类识别时性能不佳的问题,提供一种基于lld和dss融合特征的语音情感识别方法。
技术方案:本发明提供一种基于lld和dss融合特征的语音情感识别方法,该方法包括如下步骤:
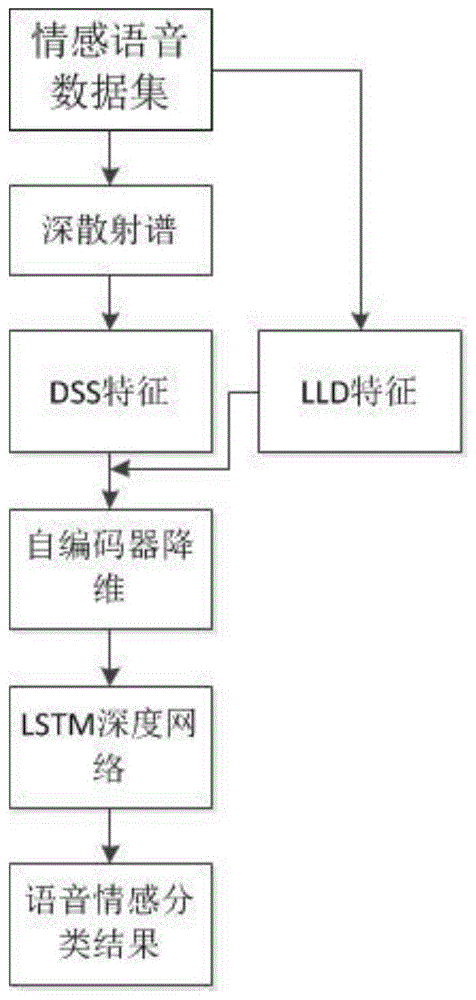
步骤1:提取情感语音数据集的lld特征和dss特征;
步骤2:将lld特征与dss特征作为自编码器的训练集,所述自编码器对lld特征和dss特征进行降维计算,得到降维后的lld+dss的融合特征;
步骤3:将步骤2中所述的lld+dss的融合特征依次输入至lstm深度网络中,由lstm深度网络识别每条融合特征对应的情感种类。
进一步的,所述步骤1中,采用dss算法对情感语音数据集进行dss特征的提取;所述dss算法的阶数设为2阶,即提取的dss特征包括情感语音数据集的零阶特征、一阶特征和二阶特征,各特征的获取方法为:将情感语音数据集作为输入信号通过第一低通滤波器获得零阶特征;将情感语音数据集作为输入信号依次通过第一小波带通滤波器和第二低通滤波器获得一阶特征;将情感语音数据集作为输入信号依次通过第一小波带通滤波器、第二小波带通滤波器和第三低通滤波器获得二阶特征,所述第二小波带通滤波器的频率高于第一小波带通滤波器的频率。
进一步的,所述步骤1中,情感语音数据集包括emodb数据集、ravdess数据集和surrey数据集。
进一步的,所述步骤3中,lstm深度网络具有β层网络层,该β层网络层中的前β-1层用于对输入的lld+dss的融合特征进行训练得到该条融合特征的隐含特征;最后一层为分类器,该分类器判断所述隐含特征所对应的情感种类,也即该条融合特征所对应的情感种类。
进一步的,所述分类器中的维度个数与共有情感种类的个数θ一致,一个维度对应共有情感种类中的一种情感种类;所述共有情感种类为emodb数据集、ravdess数据集和surrey数据集中共有的情感种类。
进一步的,所述分类器判断隐含特征所对应的情感种类的方法为:分类器将隐含特征映射到(0,1)的区间内,得到θ1个概率,该θ1个概率与θ个共有情感种类一一对应,θ1=θ;概率最大的情感种类为该隐含特征对应的情感种类。
进一步的,所述分类器为sofmax分类器。
进一步的,所述自编码器具有3层神经网络层,分别为输入层、隐含层和输出层,lld+dss的融合特征的维度等于输出层神经元的个数。
有益效果:本发明针对情感语音信号包含时序信息的特性,利用lstm深度网络在处理文本和语音数据的优势,提出一种基于lld和dss融合特征的语音情感分类方法,根据情感语音信号的非线性、非平稳特性,首先利用深散射谱提取dss特征,再通过自编码器将扩充后的特征集进行降维,得到lld+dss融合特征,再利用lstm深度网络进行语音的情感分类。相较于传统语音情感特征和分类识别算法,基于lld和dss融合特征的语音情感分类方法有着更好的综合性能,提高了语音情感分类的准确性。
附图说明
图1是本发明的流程图;
图2是dss特征提取图;
图3是fear语句dss的零阶(a)、一阶(b)、二阶(c)对数能量图;
图4是本发明的自编码器网络结构;
图5是lstm深度网络的内部基本结构;
图6是本发明的emodb数据集实验结果;
图7是本发明的ravdess数据集实验结果;
图8是本发明的savee数据集实验结果。
具体实施方式
构成本发明的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
如图1所示,本实施例在传统lld特征的基础上,增加了dss特征进行特征集扩充,再通过自编码器将扩充后的特征集进行降维,得到lld+dss融合特征。最后将lld+dss融合特征作为lstm深度网络的输入,由该lstm深度网络判定每条融合特征对应的情感种类。
本实施例中提取的情感语音数据集的lld特征为79维,具体维度如表1所示:
表1
本实施例采用的情感语音数据集包括三种情感语音数据集,为emodb数据集、ravdess数据集、surrey数据集,这三种数据集的具体的情感种类、表演人数和语句数如表2所示;本实施例中对emodb数据集,取10名说话人(5男5女)的情感语句,每种情感各20句;对ravdess数据集,取16名说话人(8男8女)的情感语句,每种情感各50句;对surrey数据集,取4名说话人的情感语句,每种各20句。其中80%的语句作为训练集,20%的语句作为测试集进行实验。进行10次实验,实验结果以10次实验识别率的平均值作为评估指标。将lld+dss融合特征进行语音情感分类识别。
表2
深散射谱(dss)于2014年由joakimandén和stéphanemallat提出,lld特征集中常用的mfcc特征,与dss特征在高频部分是不同的。当低通滤波器使用卷积时,mfcc特征几乎不包含频率细节信息并丢失高频特征部分。而dss特征可以用于补偿mfcc特性无法表示的高频特征。dss特征在语音和音乐分类上取得了优于mfcc特征的效果[6]。dss特征通过scatnat进行提取,并且dss包含比lld更丰富的频域能量分布和时延分量。
在大多数实验中,dss特征分解到二阶的散射系数足以用于语音情感分类的应用中,因为零到二阶散射系数占据信号中绝大部分能量。因此,本实施例中dss算法的阶数为2阶,dss算法提取情感语音数据集的零到二阶的特征,得到该情感语音数据集的dss特征,本实施例中该dss特征为600维。
dss特征提取过程如图2所示:情感语音数据集作为输入信号通过第一低通滤波器获得零阶特征;情感语音数据集作为输入信号连续通过第一小波带通滤波器和第二低通滤波器,获得一阶特征;情感语音数据集作为输入信号连续通过第一小波带通滤波器、第二小波带通滤波器和第三低通滤波器,获得二阶特征。第二小波带通滤波器的频率应高于第一小波带通滤波器,具体高出的数值视实验情况而定,该第二小波带通滤波器的带通为恢复高频段信号的带通;输入信号的零阶、一阶和二阶特征均为dss特征。
输入信号的零阶特征表示为
s0(x)=x*φ
式(1)中,s0(x)表示零阶特征,x为输入信号,φ为低通滤波器传输函数。
式(2)中,s1(x)为一阶特征,ψλ1为基于morlet小波λ1的带通滤波器传输参数。
式(3)中,s2(x)为二阶特征,ψλ2为基于morlet小波λ2的带通滤波器传输参数。
本实施例中选择emodb数据集中的一段fear情感语音进行dss特征提取,得到的零阶、一阶、二阶特征分别如图3的(a)、(b)、(c)所示。
将从情感语音数据集中提取的79维lld特征和600维dss特征的集合输入自编码器,进行特征降维,得到一定维度的lld+dss融合特征。lld+dss融合特征的维度等于该自编码器输出层的神经元个数。
本发明采用的自编码器是一种用于数据降维的人工神经网络[7],由三层神经网络构成,结构如图4所示。从输入层到隐含层可看作编码过程,表示为:
h=σh(w1x1+b1)
h为隐含层的输出,σh为隐含层的激活函数,x1为输入的79维lld特征和600维dss特征的集合,w1和b1为隐含层权重和偏置参数。
从隐含层到输出层可看作解码过程,表示为:
y=σy(w2h+b2)
y为输出层的输出,σy为输出层的激活函数,w2和b2为输出层权重和偏置参数。
自编码器通过损失函数进行优化,损失函数选择交叉熵,表示为:
j为损失函数,w、b为整个网络的权重和偏置参数,yi和y’i分别表示样本的标签值和网络的输出值。
lstm深度网络能够将信息按照时序存储在存储器单元中,并且可以学习与分类任务相关的上下文信息。lstm深度网络与rnn网络相似,只是非线性隐藏单元被替换为特殊类型的存储器块。该lstm深度网络中每个存储块包含一个或多个周期性连接的存储单元和三个乘法单元(输入、输出和遗忘门)。乘法门允许存储单元在长输入序列上存储和访问信息。本实施中使用五个帧长(每帧20ms)的语音段作为数据单元来预训练lstm深度网络。
本实施例中的lstm深度网络内部基本结构如图5所示,该网络模型具有β个网络层。为了控制信息的流动,在lstm深度网络的内部节点中专门设计了记忆单元(memorycell),并通过门结构来控制信息的删除或增加。门是一种对信息进行选择通过的方法,lstm深度网络的节点中有输入门(inputgate)、遗忘门(forgetgate)和输出门(outputgate)三种门结构来保护和控制节点的状态。设xt为lstm深度网络某节点t时刻的输入、ht为t时刻的输出、wxk(k=i、f、c、o)为输入对应的权值、whk(k=i、f、c、o)为输出对应的权值、wck(k=i、f、c、o)为时刻t记忆单元的值ct对应的权值、bk(k=i、f、c、o)为偏置对应的权值,σ为激活函数,则lstm神经网络模型通过门结构控制信息更新的流程分为四个步骤[11]:
a.计算输入门t时刻的值it,输入门控制的是当前输入对记忆单元状态值的影响,计算表达式如下所示:
it=σ(wxixt+whiht-1+wcict-1+bi)
其中ht-1为某节点t-1时刻的输出,ct-1为t-1时刻记忆单元的值
b.计算遗忘门t时刻的值ft,遗忘门控制的是历史信息对记忆单元状态值的影响,计算表达式如下所示:
ft=σ(wxfxt+whfht-1+wcfct-1+bf)
c.计算t时刻时记忆单元的值ct,计算表达式如下所示
ct=ft·ct-1+it·tanh(wxcxt+whcht-1+bc)
d.计算t时刻时输出信息ht,该信息由输出门输出ot决定,计算方法如式下所示:
ht=ot·tanh(ct)
其中ot=σ(wxoxt+whoht-1+wcoct-1+bo)。
将降维后lld+dss融合特征矩阵作为lstm深度网络的输入,lstm深度网络中的前β-1层围绕着输入的lld+dss的融合特征进行训练得到该融合特征的隐含特征。
该lstm深度网络中的最后一层为softmax分类器[10],由于emodb数据集、ravdess数据集、surrey数据集这三种数据集共有的5种相同的情感种类(生气/愤怒、厌恶/讨厌、害怕/恐惧、高兴、悲伤),所以本实施例中softmax分类器具有五个维度,每个维度对应一种情感种类。
softmax分类器将隐含特征映射到(0,1)的区间内,并得到5个概率,该5个概率与5个情感种类一一对应;概率最大的情感种类为该融合特征对应的情感种类;
softmax分类器将多个神经元的输出即隐含特征映射到(0,1)区间内,可以看作是对每一个样本进行所属类别进行估计,具体计算如下所示:
其中k为所有类别总数,j为当前预测的类别。x为神经元输出,wj为对应与j类的权重系数。
本实施例将lld特征、dss特征和lld+dss融合特征均采用knn、lvq、svm、bp和lstm等五种网络进行情感分类对比。图6、7、8分别为应用emodb、ravdess、savee数据集的分类结果。图6、7、8可知,lld+dss融合特征在几乎所有的分类方法中的识别率都优于仅使用lld特征时的识别率,且在lstm网络的得到最优识别率。
图6为emodb数据集实验结果,knn、lvq、svm和bp四种网络采用lld特征的识别率均高于dss特征;dss特征在lstm网络中的识别率稍高于lld特征;而五种网络采用lld+dss融合特征的识别率均高于lld特征和dss特征,其中,lstm网络采用lld+dss融合特征的识别率相对最高。
图7为ravdess数据集实验结果,svm网络采用lld+dss特征与lld特征几乎相同;knn、lvq、bp和lstm四种网络采用lld+dss融合特征的识别率高于lld特征和dss特征;lstm网络采用lld+dss融合特征的识别率相对最高。
图8为savee数据集实验结果,svm网络采用lld+dss融合特征的识别率稍低于lld特征(svm对高维特征识别性能不佳的结果);knn、lvq、bp和lstm四种网络采用lld+dss融合特征的识别率均高于lld特征和dss特征;lstm网络采用lld+dss融合特征的识别率相对最高。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。
- 还没有人留言评论。精彩留言会获得点赞!