一种基于学习补偿的背景噪声去除方法与流程
本发明涉及智能会议领域,具体涉及一种基于学习补偿的背景噪声去除方法。
背景技术:
会议场景下的背景噪声因为其时变性、非稳定性、复杂性而很难勾勒出它的分布规律与特点,更不可能将它划分到某个具体的类中,况且会议噪声在不同规模的会议场景下,背景噪声之间的差异也特别大,这对于去除会议背景噪声带来了很大的困难。因而亟需发明一种能有效去除语音信号中会议背景噪声的方法。
技术实现要素:
本发明的目的是提供一种能有效去除语音信号中背景噪声的基于学习补偿的背景噪声去除方法。
为实现上述目的,本发明采用了如下技术方案:一种基于学习补偿的背景噪声去除方法,包括以下步骤:
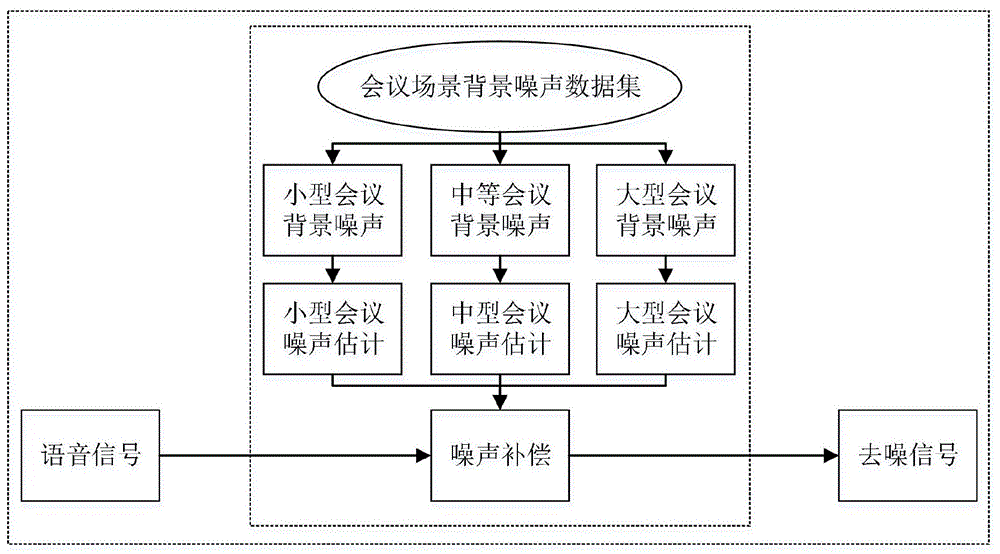
步骤(1):基于场景的噪声分类:按照会议规模,将会议场景背景噪声数据集分为小型会议背景噪声、中等会议背景噪声、大型会议背景噪声;
步骤(2):背景噪声估计,具体方法如下:
步骤(2.1):采用gmm模型学习背景噪声的特征,分别得出小型会议背景噪声、中等会议背景噪声、以及大型会议背景噪声的背景噪声分布;
步骤(2.2):通过gmm识别出采集的语音信号属于何种规模的背景噪声,最后根据识别结果,选择对应规模的背景噪声分布;
步骤(3):根据采集的语音信号所估计出的背景噪声分布,采用噪声学习补偿算法对采集的语音信号进行补偿,从而去除采集的语音信号中的背景噪声。
进一步地,前述的一种基于学习补偿的背景噪声去除方法,其中:在步骤(1)中,基于场景的噪声分类具体包括:先从会议场景背景噪声数据集中筛选出有代表性的、背景噪声分布均匀、易提取的部分样本,然后将这些样本按照会议规模分为小型会议背景噪声、中等会议背景噪声、大型会议背景噪声,接着再对这些分类后的背景噪声分别进行数据清洗,再从样本语音数据中分离出背景噪声信号,并将噪声信号拼接成多个时间长度一致的噪声文件,最后对这些噪声文件进行人工标注完成分类。
进一步地,前述的一种基于学习补偿的背景噪声去除方法,其中:在步骤(3)中,噪声学习补偿算法中,采集的语音信号中说话人信号的具体计算公式为:
其中,y(t)是采集的语音信号,x(t)是说话人信号,n(t)是步骤(2)中采集的语音信号所估计出的背景噪声,k是调节参数,是一个实验值。
通过上述技术方案的实施,本发明的有益效果是:能有效去除语音信号中的背景噪声。
附图说明
图1为本发明所述的一种基于学习补偿的背景噪声去除方法的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
如图1所示,所述的一种基于学习补偿的背景噪声去除方法,包括以下步骤:
步骤(1):基于场景的噪声分类:先从会议场景背景噪声数据集中筛选出有代表性的、背景噪声分布均匀、易提取的部分样本,然后将这些样本按照会议规模分为小型会议背景噪声、中等会议背景噪声、大型会议背景噪声,接着再对这些分类后的背景噪声分别进行数据清洗,再从样本语音数据中分离出背景噪声信号,并将噪声信号拼接成多个时间长度一致的噪声文件,最后对这些噪声文件进行人工标注,从而将会议场景背景噪声数据集分为小型会议背景噪声、中等会议背景噪声、大型会议背景噪声;
步骤(2):背景噪声估计,具体方法如下:
步骤(2.1):采用gmm模型学习背景噪声的特征,分别得出小型会议背景噪声、中等会议背景噪声、以及大型会议背景噪声的背景噪声分布,这些分布描述出了对应会议背景噪声的特点以及规律,可以通过它预测在某一时刻背景噪声信号对应的幅值;
步骤(2.2):通过gmm识别出采集的语音信号属于何种规模的背景噪声,最后根据识别结果,选择对应规模的背景噪声分布,所选择的背景噪声分布就是采集的语音信号的背景噪声估计结果;
步骤(3):根据采集的语音信号所估计出的背景噪声分布,采用噪声学习补偿算法对采集的语音信号进行补偿,从而去除采集的语音信号中的背景噪声;
其中,噪声学习补偿算法中,采集设备采集到的语音信号是由说话人信号和背景噪声信号组成的,它们的关系如公式1.1所示,其中y(t)是采集到的语音信号,x(t)是说话人信号,n(t)是步骤2估计出的背景噪声,w是自适应调节背景噪声参数;以往的补偿算法是没考虑过自适应调节的,它们一般都直接将y(t)-n(t)从而得到说话人信号,这种做法可能会带来补偿过多或补偿过少的后果,这将直接导致背景噪声去除的不够干净或者连带说话人的部分信号也被一并去除了,为了改善这种情况,本发明设计了自适应调节背景噪声参数;
y(t)=x(t)+n(t)·w(1.1)
经过研究表明:通过背景噪声估计出的n(t)是与y(t)不相关的信号,没有考虑到y(t)分布的特性,只能代表平均条件下会议场景噪声的分布情况,采集设备放在会议场景的不同位置,采集到的背景噪声幅值都是不同的,所以基于此,设计出w的求解过程如公式(1.2)所示,w的选取充分考虑到t时刻前的k个时刻的时域分布,并根据幅值越大,噪声补偿越多的原则进行补偿,能很好的自适应调整不同环境下的背景噪声参数;
因此,所采集的语音信号中说话人信号的具体计算公式为:
其中,y(t)是采集的语音信号,x(t)是说话人信号,n(t)是步骤(2)中采集的语音信号所估计出的背景噪声,k是调节参数,是一个实验值,根据具体的会议场景特点而灵活选用k的值;
从公式(1.3)可以看出,只要已知n(t)、y(t)就可以求出任一时刻去除背景噪声后的说话人信号。
本发明具有能有效去除语音信号中的背景噪声的优点。
技术特征:
技术总结
本发明公开了一种基于学习补偿的背景噪声去除方法,包括以下步骤:步骤(1):按照会议规模将会议场景背景噪声数据集分为小型会议背景噪声、中等会议背景噪声、大型会议背景噪声;步骤(2):背景噪声估计具体为:步骤(2.1):采用GMM模型学习背景噪声的特征,分别得出小型会议背景噪声、中等会议背景噪声、以及大型会议背景噪声的背景噪声分布;步骤(2.2):通过GMM识别出采集的语音信号属于何种规模的背景噪声,最后根据识别结果选择对应规模的背景噪声分布;步骤(3):根据所估计出的背景噪声分布,采用噪声学习补偿算法对采集的语音信号进行补偿,去除采集语音信号中的背景噪声。本发明具有有效去除背景噪声的优点。
技术研发人员:张晖;高财政;赵海涛;孙雁飞;朱洪波
受保护的技术使用者:南京邮电大学
技术研发日:2019.03.11
技术公布日:2019.06.04
- 还没有人留言评论。精彩留言会获得点赞!