身份矢量x-vector线性变换下的说话人识别方法与流程
本发明涉及本发明涉及生物识别中的说话人识别技术,更具体地说涉及一种身份矢量x-vector线性变换下的说话人识别技术。
背景技术:
语音是人类进行沟通交流的最直接方便的方式,它以其特有的方便性、经济性、准确性等各方面的优势引起了各个研究机构的注意。语音信号处理的研究对促进人机交互、人工智能发展有着重大意义。为此,语音信号处理的相关领域,例如语音识别、语音编码、语音合成、说话人识别等方向受到越来越多的关注与理论研究。说话人识别,又称声纹识别,其研究目标是根据每个说话人的独特发音进行身份认证。每个说话人的语音都有着独特的个人特色,这是因为每个说话人天生的发声器官不同,同时受后天所在的环境因素影响而培养成的属于自己的一个独特的嗓音。正是由于这种差异性,使得将语音作为一种生物特性作为识别目标成为可能,说话人识别也逐渐形成了自己的一套比较完善的识别体系。
说话人识别系统包括了预处理部分、特征提取部分、模型训练与匹配计算部分。说话人识别的关键技术包括特征参数提取算法,模型的选择和模型匹配算法,直接决定了识别系统的性能。说话人模型分为生成模型与判别模型。生成模型是学习各个类别各自的特征,即多个模型,识别数据映射到每个模型中,进而确定识别数据属于哪一类;判别模型是学习分类面,该分类面可用来区分不同的数据分别属于哪一类。这两个模型以基于全局差异模型(TotalVariabilityModeling,TVM) 的身份矢量i-vector、基于延时神经网络(Time-delayDeepNeuralNetwork,TDNN) 的身份矢量x-vector为代表,是目前使用最广泛的两个矢量模型。
x-vector的后端部分和i-vector后端部分一般均采用概率线性判别分析 (probabilisticlineardiscriminantanalysis,PLDA)的后端评分方法。x-vector模型下的结果与i-vector的结果在长时语音下相当,在短时语音下结果更好。不同的论文研究了如何提高x-vector模型下的系统性能,研究表明将i-vector和x-vector 的模型叠加或者PLDA得分融合可以提高系统性能,然而该种方法设计到两种系统,需要大量的内存需求,同时计算速度也会受到影响。随后,更多的研究通过数据扩充的方式来提高x-vector的鲁棒性,但是这种方法受识别环境影响。
技术实现要素:
本发明的目的是提供一种考虑在线识别目标说话人的内存量和计算时间的说话人识别方法。
为了达到上述目的,本发明的技术方案是提供了一种基于身份矢量x-vector 线性变换下的说话人识别方法,其特征在于,包括如下步骤:
步骤1、提取说话人的训练语音的梅尔频率倒谱系数作为说话人的特征;
步骤2、利用步骤1获得的特征采用深度神经网络结构训练x-vector模型,建立身份矢量x-vector模型,从而获得身份矢量x-vector;
步骤3、利用步骤1获得的特征基于EM算法训练i-vector模型,建立身份矢量i-vector模型,从而获得身份矢量i-vector;
步骤4、认为同一个说话人的i-vector和x-vector投影到同一个矢量中,基于EM算法训练得到平行因子分析器的参数,从而完成平行因子分析器的训练;
步骤5、通过线性变换器,在平行因子分析器的参数中保留x-vector对应的参数,在线性变换器基础上,将身份矢量xl-vector用x-vector的线性变换表达出来,从而建立身份矢量xl-vector模型,获得身份矢量xl-vector;
步骤6、利用身份矢量xl-vector采用EM算法对PLDA的参数模型进行更新,完成对PLDA模型的训练;
步骤7、测试阶段的说话人识别
将注册语音已经对应的待识别语音进行特征提取后通过身份矢量x-vector 模型获得身份矢量x-vector,将身份矢量x-vector输入训练后的线性变换器得到新的身份矢量xl-vector,最后将身份矢量xl-vector输入到训练后的PLDA模型,从而得到说话人识别结果。
优选地,步骤4中,考虑到不同身份矢量可以映射到同一个矢量空间,采用平行因子分析的方法得到这个共同的矢量。
优选地,步骤4中,第l个说话人的身份矢量i-vector表示为φi(l,1),...,φi(l,k),身份矢量x-vector表示为φx(l,1),...,φx(l,k),其中,k表示该说话人的输入语音的数量,φi(l,k)表示第l个说话人的身份矢量的第k段语音的身份矢量i-vector,φx(l,k)表示第l个说话人的身份矢量的第k段语音的身份矢量x-vector,同一个说话人的身份矢量i-vector和身份矢量x-vector可以投影到同一个矢量中,因此可以表示为其中,μi表示身份矢量i-vector 的平均向量;μx表示身份矢量x-vector的平均向量;Fi表示i-vector对应的投影矩阵;Fx表示x-vector对应的投影矩阵;h(l)表示第l个说话人的隐变量;εi(l,k) 表示第l个说话人的身份矢量的第k段语音的身份矢量i-vector在线性变换后的残余矢量,εi~N(0,∑i),∑i表示i-vector的协方差矩阵,N(0,∑i)表示εi满足矩阵为0,协方差为∑i的正态分布;εx(l,k)表示表示第l个说话人的身份矢量的第k段语音的身份矢量x-vector在线性变换后的残余矢量,εx~N(0,∑x),∑x表示残差εx的协方差矩阵,N(0,∑x)表示εx满足矩阵为0,协方差为∑x的正态分布;通过EM算法,得到平行因子分析器的参数θ={μi,Fi,∑i,μx,Fx,∑x}。
优选地,步骤6中,根据x-vector对应的参数θx={μx,Fx,∑x}上,将线性变换后的身份矢量xl-vector表示为其中,表示xl-vector 的后验协方差将其进一步写成φxl=Aφx-b的形式,A、b 为线性参数,从而将身份矢量xl-vector表示成x-vector的线性变换方式。
本发明考虑到i-vector的生成模型的信息是对x-vector模型系统有所帮助的,在训练阶段引入i-vector,得到适用于x-vector的线性变换矩阵,并提出一种 x-vector线性变换下的说话人识别方法。
本发明所述步骤4中,采用x-vector和i-vector训练平行因子分析器,这样这个分析器既包含了x-vector的信息,又包含了i-vector的信息,因此在此分析器基础上得到的x-vector的线性变换器较好地保留了i-vector的信息,从而使得新的身份矢量xl-vector具有i-vector信息,最终提高系统的识别性能。
本发明步骤在1-6的训练阶段的步骤完成后,在步骤7的测试阶段不需要再进行i-vector身份矢量提取,同时平行因子分析器在训练阶段得到后,只需要保留x-vector的线性变换器,因此测试阶段的内存需求没有增大,同时线性变换对实际的运算几乎没有影响。
本发明方法在于说话人识别中采用一种对x-vector线性变换后的身份矢量进行身份识别。通过在测试过程中合理采用i-vector信息,达到提高识别性能的效果。具体来说就是在测试阶段,通过利用同一个说话人的x-vector和i-vector 进行平行因子分析器训练,选取平行因子分析器中x-vector对应的参数,在此参数基础上对身份矢量x-vector进行线性变换得到xl-vector;在测试阶段,将待测试语音进行特征提取以及x-vector提取,将其输入到训练阶段得到的线性变换器得到新的身份矢量xl-vector,最后将其输入到训练阶段得到的PLDA模型,从而得到最终结果。
由此可产生这样的有益效果:
(1)采用x-vector和i-vector训练平行因子分析器,这样这个分析器既包含了x-vector的信息,又包含了i-vector的信息,因此在此分析器基础上得到的 x-vector的线性变换器较好地保留了i-vector的信息,从而使得新的身份矢量 xl-vector具有i-vector信息,最终提高系统的识别性能;
(2)测试阶段不需要再进行i-vector身份矢量提取,同时平行因子分析器在训练阶段得到后,只需要保留x-vector的线性变换器,因此测试阶段的内存需求没有增大,同时线性变换对实际的运算几乎没有影响。
附图说明
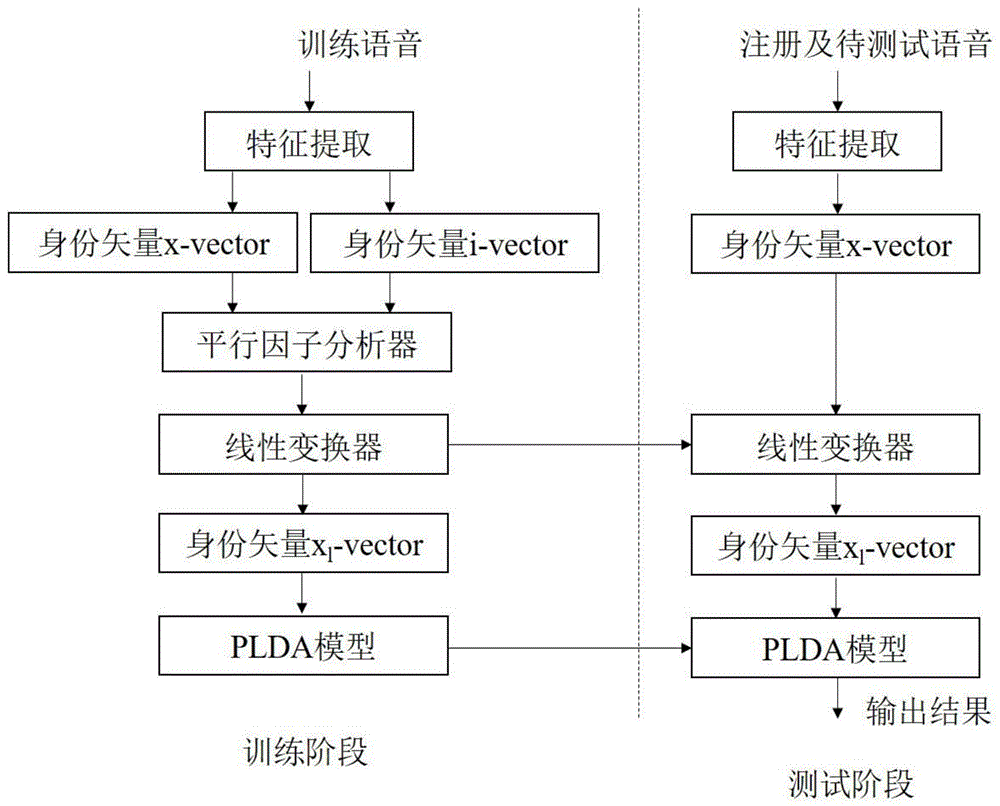
图1是本发明实施身份矢量x-vector线性变换下的说话人识别流程图;
图2是x-vector神经网络架构中帧数层的参数设置情况。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明实施例公开的一种身份矢量x-vector线性变换下的说话人识别技术的方法,如图1所示,包括以下步骤:
步骤1、特征提取——本发明采用梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)作为说话人的特征。梅尔频率尺度大体对应于实际频率的对数分布关系:Mel(f)=2595lg(1+f/700),式中,Mel(f)表示梅尔频率, f表示普通频率。按照下列操作方式可以得到MFCC特征:(1)预处理,包括预加重、分帧加窗、端点检测,设语音信号x(m)经预处理后为xi(m),i表示帧数; (2)快速傅里叶变换X(i,k)=FFT[xi(m)],X(i,k)表示频谱信号;(3)谱线能量计算E(i,k)=[X(i,k)]2;(4)计算梅尔滤波器能量其中Hm(k)为梅尔滤波器函数,M表示滤波器的个数;(5)DCT变换以及求对数。
步骤2、身份矢量x-vector模型建立——x-vector模型训练基于深度神经网络结构。前5层是帧级别,TDNN总的输入是一段语音,每次TDNN取固定帧数,前五层的网络参数设定见图2。然后池化层把每个TDNN的输出矢量积累下来后,计算均值和标准差作为池化层的输出。池化层之后接着两层全向连接层最后加一个softmax层为输出。输出的神经元个数和我们训练集中说话人个数保持一致,神经网络的输出是一个后验概率。基于该神经网络通过多次迭代训练使用第六层输出作为x-vector模型。
步骤3、身份矢量i-vector模型建立——给定一个说话人s的语音序列为 O={o1,o2,...,oT},可以将第c个高斯分量在t时刻的语音序列表示成 oc,t=μc+Tcx+ε,oc,t表示第c个高斯分量在t时刻的语音序列,μc表示第c个高斯分量的均值,Tc表示第c个高斯分量的投影矩阵,x表示该说话人的隐变量,ε表示残差部分,选用EM算法训练i-vector模型。其中E步骤(求期望值)中,一阶统计量Fc和二阶统计量Sc的定义分别为:Fc=∑tγc(t)(oc,t-μc),Sc=∑tγc(t)(oc,t-μc)(oc,t-μc)T,γc(t)表示第t帧语音在第c个高斯分量占有率, x的后验均值表示为φ=L-1TT∑-1F,其中,L-1表示身份矢量i-vector的后验协方差,Nc表示第c个高斯分量的零阶统计量,,I表示单位向量,T表示所有高斯分量Tc组成的矩阵,F表示一阶统计量,∑表示残差ε的协方差矩阵。M步骤(最大化)主要目的是优化矩阵T和矩阵∑,通过对求导得到这两个矩阵的最优解,F(s)表示第s段语音的一阶统计量,x(s)表示第s段语音的的隐变量, N(s)表示第s段语音的零阶统计量。通过对E和M步骤依次迭代更新的过程建立i-vector模型。
步骤4、训练平行因子分析器——第l个说话人的身份矢量i-vector表示为φi(l,1),...,φi(l,k),身份矢量x-vector表示为φx(l,1),...,φx(l,k),其中,k表示该说话人的输入语音的数量,φi(l,k)表示第l个说话人的身份矢量的第k段语音的身份矢量i-vector,φx(l,k)表示第l个说话人的身份矢量的第k段语音的身份矢量 x-vector,同一个说话人的身份矢量i-vector和身份矢量x-vector可以投影到同一个矢量中,因此可以表示为其中,μi表示身份矢量i-vector的平均向量;μx表示身份矢量x-vector的平均向量;Fi表示i-vector对应的投影矩阵;Fx表示x-vector对应的投影矩阵;h(l)表示第l个说话人的隐变量;εi(l,k)表示第l个说话人的身份矢量的第k段语音的身份矢量i-vector在线性变换后的残余矢量,εi~N(0,∑i),∑i表示i-vector的协方差矩阵,N(0,∑i)表示εi满足矩阵为0,协方差为∑i的正态分布;εx(l,k)表示表示第l个说话人的身份矢量的第k段语音的身份矢量x-vector在线性变换后的残余矢量,εx~N(0,∑x),∑x表示残差εx的协方差矩阵,N(0,∑x)表示εx满足矩阵为0,协方差为∑x的正态分布;通过EM算法,得到平行因子分析器的参数θ={μi,Fi,Σi,μx,Fx,Σx}。
步骤5、线性变换器——在训练阶段得到的平行因子分析器包含了i-vector 和x-vector的参数,在实际在线操作中,只需要x-vector对应的参数θx={μx,Fx,∑x}。在此参数上得到线性变换后的身份矢量xl-vector模型。
步骤6、身份矢量xl-vector模型建立——在x-vector对应的参数θx={μx,Fx,∑x}上,将线性变换后的身份矢量xl-vector表示为表示身份矢量x-vector的后验协方差将其进一步写成φxl=Aφx-b的形式,A、b为线性参数,从而将身份矢量xl-vector表示成x-vector的线性变换方式。
步骤7、PLDA模型训练——假设训练数据语音由i个说话人的语音组成,其中每个说话人有j段自己不同的语音。那么,我们定义第i个说话人的第j条语音为xij。然后,根据因子分析定义xij的生成模型为:xij=μ+Fhi+Gwij+εij,μ表示均值矢量,F表示说话人信息矩阵,hi表示第i个说话人的隐变量,G表示信道信息矩阵,wij表示第i个说话人的第j条语音的在信道的隐变量,εij表示第 i个说话人的第j条语音的残差部分。采用EM算法对PLDA的参数模型进行更新。
步骤8、测试阶段的说话人识别——将注册语音已经对应的待识别语音进行特征提取以及x-vector提取,将其输入到训练阶段得到的线性变换器得到新的身份矢量xl-vector,最后将其输入到训练阶段得到的PLDA模型,从而得到最终结果。
下面对本发明方法进行仿真并分析。
在NIST SRE 2010测试集中,对线性变换后x-vector身份矢量下的说话人识别性能进行了仿真验证。该测试集包含9个场景(common condition,CC)的测试任务,包含采访(interview),麦克风(microphone)和电话信道(telephone) 的数据,其中电话信道还对于说话人风格上面引入了不同的音量,主要包括高音量(high vocal effort),平常音量(normal vocal effort)和低音量(low vocal effort)。本发明采用第5个场景(CC’5),即平常音量下基于不同电话信道的场景。测评标准采用等错误率(Equal Error Rate,EER)以及检测损失函数(Detection Cost Function,DCF)来衡量说话人识别系统的性能。
在NIST SRE 2010的coreext-coreext、core-10sec、10sec-10sec三个任务测试集合上进行实验,其中,coreext和core指长时语音,10sec指短时语音。仿真中用到Switchboard2,Switchboard Cellular,以及NIST SRE 2004到2008 的语音数据作为训练数据。实验以x-vector和i-vector系统作为基线模型。男女声UBM一起训练,x-vector模型采用声学特征为20维的MFCC特征,i-vector 模型采用同样的20维mfcc的静态特征参数及其一阶和二阶差分,即60维特征。对每一段语音段,分别得到600维i-vector矢量及512维x-vector矢量。在基线系统中用LDA的方法将身份矢量降维到400维,接着训练一个说话人空间秩为200维,信道空间秩为0维,以及全方差矩阵的PLDA模型。本发明提出的 xl-vector在设计过程中已经考虑说话人变量类间距离最大、类内距离最小的因素,因此不采用LDA步骤。
表1是在coreext-coreext、core-10sec、10sec-10sec三个任务中,不同系统在EER评价标准和DCF评价标准的对比,xl-vector的维数为512。其中i-vector 和x-vector是两个基线系统,融合系统为i-vector和x-vector的PLDA模型的得分进行相加得到的系统。在coreext-coreext、core-10sec、10sec-10sec三个任务中,本发明提出的xl-vector在EER评价标准中均好于两个基线系统,在DCF评价标准中10sec-10sec任务中相对x-vector系统稍有降低,其他两个任务均好于两个基线系统。xl-vector系统相较于融合系统在coreext-coreext任务上的EER 优势比较明显,xl-vector和x-vector所需的内存以及计算速度相似,然而融合系统需要考虑x-vector和i-vector,因此运算时需要更多的内存,计算速度也变慢。综上,本发明的xl-vector相较于两个基线系统和融合系统都有着明显的优势。
表1
表2是在coreext-coreext、core-10sec、10sec-10sec三个任务中,新的身份矢量xl-vector在不同维度下EER评价标准和DCF评价标准的对比。可以发现在coreext-coreext任务中随着维数的增大,EER的性能越来越好,在维数为500 时,性能达到最优值,在维数为512时,基本保持最优值;DCF的性能基本维持不变。在core-10sec和10sec-10sec任务中随着维数的增大,EER的性能越来越差,在维数为200时,性能达到最优值;DCF的变换范围维持在10%以内。综上,在测试语句为长时语句时,维数越高性能越好,在测试语句为短时语句时,维数越低性能越好。
表2
由此可见,发明人提出的xl-vector模型通过x-vector和i-vector在训练阶段的平行因子分析器,得到一个对x-vector的线性变换算法,提高了说话人识别系统的性能,并保持内存需求量和计算速度不受影响的优点。
- 还没有人留言评论。精彩留言会获得点赞!