一种基于麦克风阵列的室内声源跟随与增强方法与流程
本发明涉及语音信号处理技术,具体涉及一种基于麦克风阵列的室内声源跟随与增强方法。
背景技术:
室内会议或教学中,个人发言总会受限于现有语音系统,学习交流过程中十分不便。如采用无线麦克风或定点式麦克风的语音系统,虽然能够准确地采集目标声源的声音,但是其传输距离限制了发言人的位置,并且电池与麦克风的维护成本较高。基于麦克风阵列的语音系统,通过在室内不同位置安装麦克风扩大了收音范围,解除了发言人的位置限制,由于采用稳定的供电来源如插座等,其管理也更为方便安全。但是由于信号处理方式简单,其拾音容易受到各个方向上干扰源的干扰,无法专注于最主要的发言人,保证声音的真实度,并且没有自愈能力,如果其中任何一路麦克风被损坏,整个系统也会瘫痪。
技术实现要素:
本发明提出了一种基于麦克风阵列的室内声源跟随与增强方法。
实现本发明目的的技术解决方案为:一种基于麦克风阵列的室内声源跟随与增强方法,包括如下步骤:
步骤1、对每一路麦克风拾取的模拟声音信号进行抗混叠低通滤波,并对滤波后的模拟信号进行a/d采样和帧划分;
步骤2、对各路声音信号进行帧电平检测,将帧划分为声音帧信号和噪声帧信号,若为噪声帧,则进行存储,若为声音帧,则与上一噪声帧作谱对消;
步骤3、选取参考路信号,根据参考路声音帧估计波长,并将各路声音帧与当前参考路声音帧进行互相关操作,进而估计波达角;
步骤4、根据估计的波波长、达角,结合麦克风阵列的几何形状,确定各路声音帧对应的权系数;
步骤5、对各路声音帧进行加权求和确定增强的语音数字信号,并对得到的语音数字信号进行d/a转化,生成模拟信号后传递给扬声器;
步骤6、重复步骤1-5,进行下一帧声音信号处理,直至拾声结束。
本发明与现有技术相比,其显著优点在于:1)本发明在定位声源后进行了空域滤波和噪声谱对消处理,提升了系统的噪声抑制能力与声音保真性;2)本发明具有很强的自愈能力,在任何一路麦克风被损坏时,仍能继续正常工作,并且保证了系统的整体性能。
附图说明
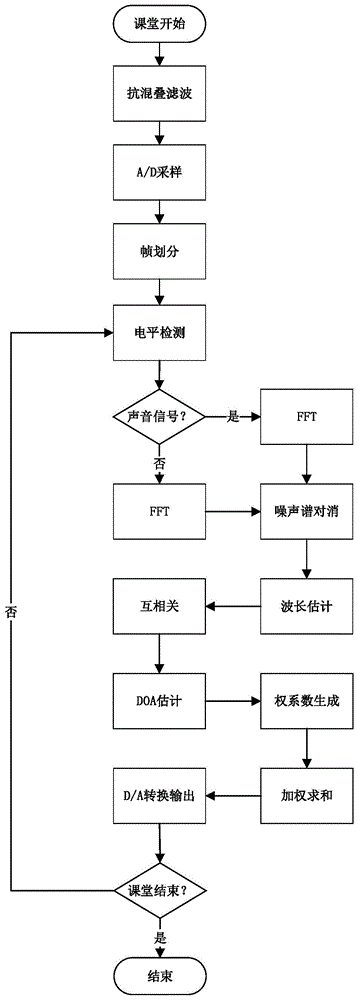
图1是本发明基于麦克风阵列的室内声源跟随与增强方法的流程图。
图2是室内四元线性麦克风阵列的语音系统图。
图3是图2的几何数学模型图。
图4是某一数字声音信号的分帧示意图。
图5是对某两路麦克风单元拾取的同一声音帧进行互相关的结果图。
图6是麦克风间声音信号时延δt与波达角θ的关系示意图。
图7是对某一例的波达角解算值与实际值之间的对比图。
图8是阵列增益方向图,其中(a)是采用0度权系数下的阵列增益方向图,(b)是采用30度权系数下的阵列增益方向图。
图9是该基于麦克风阵列的室内声源跟随与增强方法对室内某一声音的处理效果与普通方法的处理效果对比图。
具体实施方式
下面结合附图和具体实施例,进一步说明本发明的原理和方案。
基于麦克风阵列的室内声源跟随与增强的方法流程如图1所示,为了便于说明,以图2所示的4元线性麦克风阵列组成的语音系统为例进行说明,其中发言人位于阵列的左前方,扬声器对准麦克风前方的学生座位,本发明方法步骤如下:
步骤1、抗混叠滤波
一般而言,人耳能感知的声音频率最高为20khz,在进行采样之前要对高于该频段的声音进行滤波,避免采样引起频谱混叠。由于采样率只要满足满足奈奎斯特采样定律均可,本发明示例程序中可以取采样率40.96khz>2×20khz。
步骤2、a/d采样并进行帧划分
利用人耳的前向掩蔽效应,系统只要在规定的时间内完成数据处理并播放出增强的声音信号,人耳就无法察觉直接来自讲话人的声音,而只能感知到扬声器播放的声音,不会影响会场的体验。
这也注定了系统处理数据的时间不能太长,必须以帧为信号处理的单位,划分的帧时长不应超过掩蔽效应时间。例如,一般人耳前向掩蔽效应最短为5ms,若记采样率为fs,则能效应持续时间内能采到fs/200个点,考虑到快速傅立叶变换点数要求,可以取
此外,帧间隔应小于帧长避免因各路声音帧不同步而导致有用信号被严重丢失。一个帧长为200,帧间隔为100的帧划分的例子如图4所示,其中实线框内数据点为上一数据帧,虚线框内数据点为当前数据帧。
步骤3、帧类型判定
由于噪声帧信号的电平幅度较小,而声音帧的电平幅度较大,所以以电平值进行划分,直观简单又准确。具体判断方式为对每一帧信号按一定的规则运算,生成一个判断电平,与阈值电平进行比较从而将该帧划分为声音帧或噪声帧。噪声帧仅作fft并进行存储,声音帧则进入步骤4。
运算规则与阈值电平的选择方式自由且多样,本发明示例程序可以采用的运算规则为对帧内所有点取绝对值平均,阈值电平取声音采集系统满量程电平的1/10。
步骤4、谱对消
对于随机噪声,由于其随机性,各路帧信号间的叠加操作不会对该类噪声产生明显的增强;对于相干噪声,由于其相干性,相加操作在增强声音信号的同时,也会对相干噪声产生同等程度的增强,所以应采取措施来抑制相干噪声。
由于相干噪声有相对固定的频谱,将声音帧信号fft与最近一段的噪声帧信号fft作减法,即可对阵列波束指向空间内的相干噪声进行抑制。
步骤5、波长估计
人的声音信号是短时平稳信号,且在会议或者教学环境下,人正常说话时声音信号可以被视作窄带信号。因此对声音信号帧的fft结果进行分析,选取fft结果中超过设定阈值的频带范围中心点作为主要频率fest,根据声速c反推波长λest:
λest=c/fest
步骤6、互相关操作
互相关函数描述了两个时间序列的相关程度。定义两个数字声音信号序列f[n]与g[n]的互相关函数为:
其中rf,g[m]表示将序列g[n]向左滑动m点后与f[n]逐点相乘并求和所得的结果。如果g[n]是f[n]的时延序列,g[n]滑动j点后与f[n]对齐,此时两个序列最相似,互相关函数也在该点达到峰值。
通常,互相关与卷积因计算量较大,在信号处理系统中均不会直接进行计算,而是转换到频域以保证处理速度。因此,本发明在对互相关函数作傅立叶变换后,再作逆傅立叶变换,故互相关操作在信号处理系统中实际由下式计算:
rf,g[n]=ifft{f[n]g*[n]}
其中f[n]与g[n]为f[n]与g[n]的离散傅立叶变换,g*[n]表示对序列g[n]取共轭,ifft{}表示逆傅立叶变换操作。
由于当序列相似时函数达到峰值,当得到互相关结果的峰值位置后,即可反解得到序列间时延差。例如,对于帧长为n的两声音帧信号f[n]与g[n],其互相关函数rf,g[m]在点m=l有最大值,即g[n]左移l点后与f[n]序列最相似,一个采样点对应的时隙为1/fs,从而解得两序列时延:
δt=l/fs
图5展示了两个帧长为512,采样率为40.96khz的声音序列互相关结果,其实际时延差为δt=1.2489×10-4s,通过算法解得的时延δts为:
可知实际结果与解算结果吻合得很好。
步骤7、doa估计
由于声音信号到达各路麦克风的延时差取决于讲话人的位置与麦克风阵列的几何形状,得到延时差、已知麦克风阵列几何形状后便可估计doa。
设r为声源到阵列中心的距离,l为阵列长度,人正常说话的最高频率fmax在4khz左右,则波长约为λ=c/fmax=85cm。由阵列天线相关知识,若要实现低旁瓣或深零陷复杂波束,需要满足r≥10l2/λ。实际应用场景中,r在2m至10m之间,可算得阵列长度在0.13m至0.29m之间,由于阵列间距相比r非常小,故可采用远场模型,认为每一个麦克风的doa是相等的,如图7所示。
由图6可知,相邻麦克风之间声音信号的时延差δt=dsinθ/c,由于其可通过互相关操作解得具体值,且阵元间距d、声速c也已知,便可解得各个阵元的波达角θ=arcsin(cδt/d),最后取平均即可。
图7展示了实际doa(相对阵列几何中心)为20.2度时,该算法解得的波达角为20.6度。解算值与实际值之间的偏差很小,证明了算法的可靠性。
步骤8、权系数生成
解得波达角后,由阵列天线相关知识,要使得波束对准该角度上的信号而抑制其他方向到来的信号,就需要通过加权对阵元上的每个信号进行相位补偿。现有的数字波束形成技术中,有许多生成权系数实现空域滤波的方式,如lcmv滤波算法,可以增强某一方向上信号的同时在另一干扰方向上生成零陷;又如自相关矩阵求逆(smi)法等等,因此,权系数生成方式的选择非常自由。
下面对基础阵列天线空域滤波算法进行详细说明。
当波达角为θ时,均匀线阵每一阵元k与参考阵元声音信号的相位差为:
图8展示了示例算法下θ分别取0度、30度时所采用的权系数对阵列方向增益效果的影响。可见预测与实际能很好地吻合。
此例下,4元线阵的宽主瓣弥补了波长估计的偏差。会议或教学场景中,同时只能有一个发言人讲话,对于其附近的噪声环境而言,讲话人的音量是最大的,所以宽主瓣不会影响到空域滤波效果。如果采用更多元的阵列拾音效果更佳,但对于会议或课堂环境而言意义并不大。
步骤9、加权求和
根据步骤8算得的每个阵元的权系数,对每一阵元的声音帧信号进行加权,然后相加求和即可。
图9对比了加权求和与直接求和效果的差异,声音信号源自由matlab提供的,人的笑声采样点。左列为信号的时域图,右侧为完整信号的频谱图;最上一行代表原始数字信号,中间一行代表本发明提出的基于麦克风阵列的课堂发言人声音跟随增强系统处理后的数字信号,最后一行代表采用相同麦克风阵列,不经任何处理直接相加后的数字信号。从图中明显可见本发明提出的系统能有效地对信号进行增强,同时保持了声音信号频谱的原始形状;不经任何处理直接相加的系统虽然也加强了信号,但声音信号的频谱产生了明显的畸变,扬声器放出的声音效果很差。
此外,由于系统采用了麦克风阵列,最终结果是各个阵元的加权求和,所以整个系统不会因为单个麦克风损坏而直接瘫痪,具有很强的自愈能力。
步骤10、d/a转换
将加权求和后的数字信号转换为模拟信号,输出到给扬声器,实现对发言人声音的增强播放。
步骤11、根据会话状况决定是否关闭系统
若会话尚未结束,系统紧接着处理下一帧信号;若会话结束,管理人员可关闭系统电源,停止系统运作。
- 还没有人留言评论。精彩留言会获得点赞!