一种基于深度稀疏展开的单信道语音分离方法与流程
本发明涉及的是一种单信道语音分离方法。
背景技术:
语音分离起源于“鸡尾酒会效应(cocktailpartyeffect)”,指人类能够通过控制自身感官方法来传达专注特定的任务谈话或者音乐,而不受环境中其他对话或者噪音干扰为目的。因此,语音分离技术就是指通过运用一定的方法从接收到的混合语音信号中计算出个体信号的信号处理技术。
在信号处理领域,时常需要解决被称为盲源分离(blindsourceseparation,bbs)的问题。盲源分离就是在位置混合参数的情况下,仅仅根据观测到的混合信号恢复出源信号的过程。因此,按照源信号与观测数量的关系,盲语音分离又称为欠定(under-determined)和过定(over-determined)盲分离问题。该分类依据待求解方程中未知参数与观测数量之间的关系而定。其中,欠定盲分离表示观测信号数量(或接受端数量)少于待分离源信号数,而过定盲分离则与此相反。在欠定盲语音分离中,最具代表性的就是单信道和双信道语音分离。
单信道语音分离(single-channelspeechseparation,scss)指无法预知声源先验信息的情况下,仅根据观测到的单路混合信号恢复声源的过程。一般而言,单信道语音分离算法最主要分三大类,包含单信道盲源分离,基于模型方法和计算场景听觉分析。在上述的三大类中,每一类都有一种或几种不同的分离算法或建模方法。
技术实现要素:
本发明的目的在于提供一种能够有效地提高单信道语音分离的效果的基于深度稀疏展开的单信道语音分离方法。
本发明的目的是这样实现的:
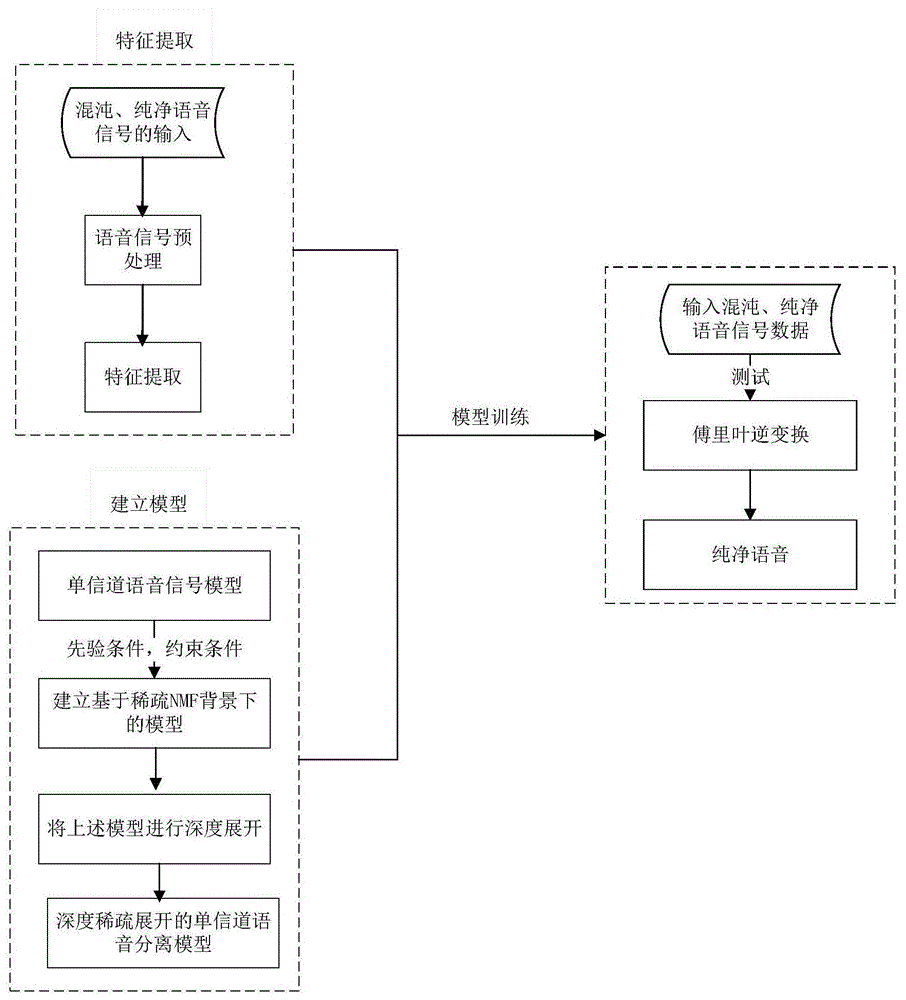
步骤一、将输入的混沌、纯净语音进行信号预处理,进行特征的提取;
步骤二、结合稀疏nmf和深度展开对单信道语音语音分离问题进行模型建立;
步骤三、将建立好的模型与提取的特征进行模型训练,得到基本系数;
步骤四、再次输入混沌、纯净语音信号数据进行测试,经过傅里叶逆变换后,最终得到纯净语音。
所述的结合稀疏nmf和深度展开对单信道语音语音分离问题进行模型建立具体包括:
第一、对单信道语音分离问题进行数学建模,具体描述为:
(1)从观测到的若干个混合信号中分离出各个未知的源信号,对典型的语音分离问题描述为:
其中y(t)表示第t时刻的观测信号,xi(t)表示第i个源信号在该时刻的值,n(t)表示扰动噪声,r为待处理信号的总和;
(2)不考虑n(t),简化为:
第二、将单信道语音分离模型转化为基于稀疏nmf表示的单信道语音分离模型,其转化过程如下:
(1)通过稀疏非负矩阵分离的方法对单信道语音去分离问题进行建模分析,描述如下,设:
m=wh
m表示待处理信号矩阵,其中每一列是一个d维向量,
(2)设混合信号是由r个待处理信号的总和,其目标函数为:
(3)将目标函数分解优化得:
其中,
(4)将w和h式进行不断的更新,描述如下:
其中更新次数k∈{1,...,k},r=wh,·表示点乘和除法;
(3)过k次迭代更新后,使用维纳滤波过滤的方法,将所有源估算sl,k计算为混合的约束:
其中,对于l个源信号,每个源信号l∈{1,...,l}都代表使用包含rl非负基列向量的矩阵表示;
(4)对训练基的优化,具体描述如下:
β1控制底层分析目标的鉴别,β2控制顶层分析目标的鉴别,权重γl计算依赖源信号l;
(5)优化为:
第三、将模型进行深度展开,具体描述为:
(1)对于k=1,...,k,将各层的参数展开为wk,并称这个新的分解方式为深度稀疏非负矩阵分解,转化为一般描述:
(2)对每一个wk作相同的深度展开:
(3)通过反向传播训练对模型进行训练,得到基于深度稀疏展开的单信道语音分离模型,具体描述为:
其中
本发明提供了一种能够有效的提高单信道语音分离的效果,实现网络可推导性,提高对问题的描述能力的基于深度稀疏展开的单信道语音分离方法。
本发明所涉及的是在模型中基于深度稀疏展开的单信道语音分离的方法,该方法将稀疏非负矩阵分离与深度展开方法相结合,对语音分离具有一定效果。
附图说明
图1本发明的方法流程图。
具体实施方式
下面举例对本发明做更详细的描述。
如图1所示,将输入的混沌、纯净语音进行信号预处理,进行特征的提取;其次,对单信道语音分离问题结合稀疏nmf和深度展开进行模型的建立,具体描述如下:
1、对单信道语音分离问题进行数学建模,具体描述为:
(1)从观测到的若干个混合信号中分离出各个未知的源信号,对典型的语音分离问题进行描述:
其中y(t)表示第t时刻的观测信号,xi(t)表示第i个源信号在该时刻的值,n(t)表示扰动噪声。
(2)在不考虑n(t)的情况下,将1(1)式简化为:
2、将单信道语音分离模型转化为基于稀疏nmf表示的单信道语音分离模型,其转化过程如下:
(1)通过稀疏非负矩阵分离的方法对单信道语音去分离问题进行建模分析。具体描述如下:
m=wh
m表示待处理信号,其中每一列是一个d维向量,
(2)根据步骤2中(1),假定混合信号是r个待处理信号的总和,其目标函数定义为:
(3)将目标函数分解优化得:
其中,
(4)任何一种方法优化2(3)式都可以看作式是给定高斯似然函数和h上的单边指数先验分布情况下的计算最大后验估计。稀疏非负性矩阵分解计算可以通过将m和h根据步骤2(4)式规则进行不断的更新进行求解。具体描述如下:
其中更新次数k∈{1,...,k},r=wh,·表示点乘和除法。
(5)过k次迭代更新后,为了重建每个语音源,通常使用类似维纳滤波过滤的方法,它将所有源信号估算sl,k计算为混合的约束:
其中,对于l个源信号,每个源信号l∈{1,...,l}都代表使用包含rl非负基列向量的矩阵表示。
(6)一般情况下,nmf的基在组合之前都是单独训练每一个语音源信号,在混合信号中,这种组合并不能通过训练进行有效的语音判别。最近,判别方法已经应用在基于这些方法稀疏字典,并在特定的任务中产生良好的效果。以类似的方式,我们可以判别地通过训练nmf的基进行信号源的分离。因此,提出了以下针对训练基的优化问题,称为判别nmf(dnmf),具体描述如下:
β1控制底层分析目标的鉴别,β2控制顶层分析目标的鉴别,权重γl计算依赖源信号l。例如,在语音去噪方面,专注于重建语音信号。
步骤2的(4)式中,第一个式子表示给定最小化重建误差
(7)根据步骤(4)式子,将步骤(3)的式子给定判别准则优化为:
即该模型为在稀疏nmf背景下,提出建立一种基于深度稀疏展开的单信道语音分离的第一步。
3、基于以上框架,将模型进行深度展开,具体描述为:
(1)对于k=1,...,k,将各层的参数展开为wk,并称这个新的分解方式为深度稀疏非负矩阵分解,通过定义,将其转化为一般描述:
(2)通过步骤式3(2)式,对每一个wk作相同的深度展开:
为了在符合非负性约束的同时训练这个网络,递归地推导出通过反向传播正和负之间的分裂来定义乘法更新方程梯度的一部分。在非负矩阵分解中(nmf),乘法更新通常使用启发式方法导出,它使用负部分与正部分的比率作为倍增因子来更新该变量的值。
(3)通过反响传播训练对模型进行训练,由此得到基于深度稀疏展开的单信道语音分离模型。具体描述为:
其中
(4)一种基于深度稀疏展开的单信道语音分离模型由此建立。
最后,将建立好的模型与提取的特征进行模型训练,得到基本系数。再次输入混沌、纯净语音信号数据进行测试,经过傅里叶逆变换后,最终得到纯净语音。
一种基于深度稀疏展开的单信道语音分离模型将传统的单信道语音分离方法与深度稀疏展开方法相结合,能够提高模型的可解释性和可推导性,有效的提高语音分离的效果。
- 还没有人留言评论。精彩留言会获得点赞!