一种基于字典学习和低秩矩阵分解的说话人识别方法与流程
本发明涉及说话人识别领域,具体的说是一种用于用于对说话人识别系统的后端i-vector字典判别方法。
背景技术:
话人识别(Speaker Recognition,SR)又称声纹识别,是利用语音信号中含有的特定说话人信息来识别说话者身份的一种生物认证技术。近年来,基于因子分析的身份认证矢量(identity vector,i-vector)说话人建模方法的引入使得说话人识别系统的性能有了明显的提升。实验表明,在对说话人语音的因子分析中,通常信道子空间中会包含说话人的信息。因此,i-vector用一个低维的总变量空间来表示说话人子空间和信道子空间,并将说话人语音映射到该空间得到一个固定长度的矢量表征(即i-vector)。
在过去的几年里,稀疏信号表示已广泛应用于数字信号处理领域,例如:压缩感知和图像恢复。近年来,人们发现基于分类的稀疏表示的实验结果比较好,因此被广泛使用。稀疏编码是通过构建过完备字典对任意一个信号进行最紧凑的线性表示。构建稀疏编码字典的方法有两种,分别是标准的数据模型法和和数据驱动方法。
进入21世纪以来,稀疏信号表示在信号处理方向得到了较为广泛的运用,典型的使用案例包括压缩感知、损坏图像恢复。近年来人们又发现稀疏编码在分类方面有很大的拓展空间,它通过建立一个过完备字典,以达到对每个待分类信号做线性表示的目的。
稀疏表示已经在语音处理的部分研究领域起到一些显著的作用,例如互联网环境下基于移动终端的语音接入中采用稀疏表示的方法,可以大大节省通信传输的特征数据,除此之外,稀疏分解对语音信号去噪也有着一定的显著作用,其中,基于字典学习和稀疏分解算法已经在图像识别领域得到了较好的使用。在非约束条件下,算法的稳定性很难得到保障,特别是当噪声污染过大时,会使训练出的字典可识别能力下降。
技术实现要素:
本发明所要解决的技术问题是,在非约束条件下,算法的稳定性很难得到保障。特别是当噪声污染过大时,会使训练出的字典可识别能力下降,为了克服现有技术的不足而提供一种基于字典学习和低秩矩阵分解的说话人识别方法。
本发明提供一种基于字典学习和低秩矩阵分解的说话人识别方法,包括以下步骤:
步骤1,对说话人音频进行预加重、分帧、加窗、端点检测等处理;
步骤2,提取出对应每个说话人语句的MFCC特征,并训练GMM-UBM模型;
步骤3,通过联合因子分析(JFA)估算全局差异空间矩阵T,全局差异空间因子w;
步骤4,得到对应每个说话人语句的i-vector;
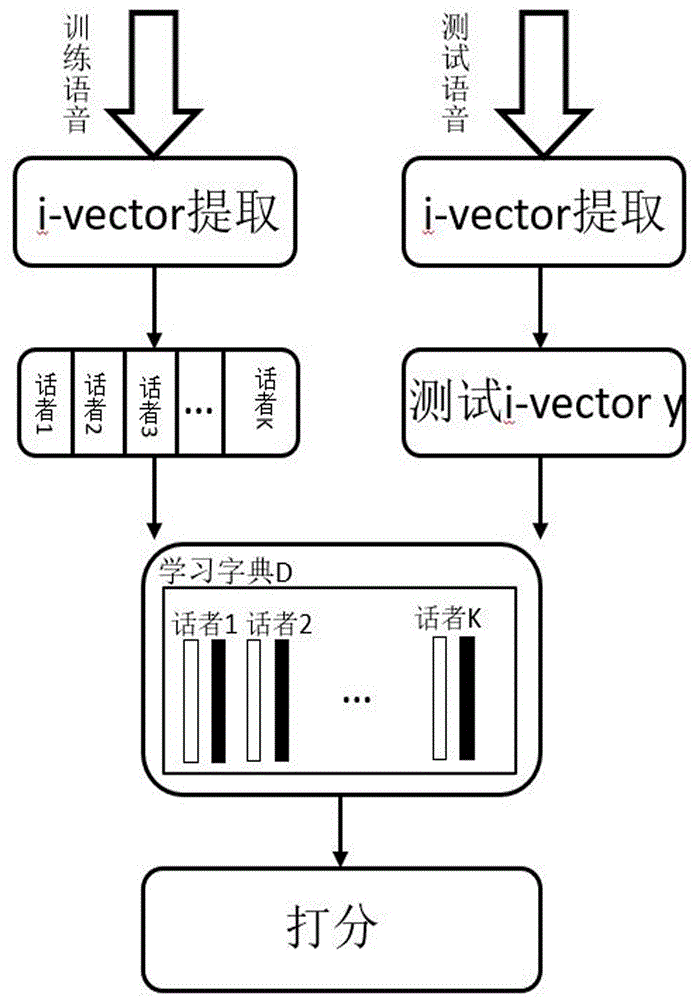
步骤5,从训练集中提取M维度的i-vector并生成特征矩阵,根据训练集和测试集,对判别字典进行生成,得到的字典将作为i-vector后端处理和打分模块,为最终判别提供依据。
作为本发明的进一步技术方案,所述步骤5的具体内容如下:设测试集的i-vector样本集合为Y,矩阵C含有说话人共性部分E和说话人个性部分DX,即Y=DX+E,那么对于训练样本Y,其在字典D上的最优稀疏表示系数应为一块对角阵,如下所示:
字典D包含c个类别的子字典,X是训练样本Y在字典D上的稀疏稀疏,其中Xi是对应子字典Di的稀疏系数;字典D具备可识别和重建的能力,从而低秩和稀疏稀疏表示,子字典Di为第i类训练样本的转悠字典,达到最好的识别率;第i类i-vector样本被第i类的子字典D很好表示;
字典Di(i≠j)对应的编码系数为0;结构化稀疏对应为Q=[q1,q2,.....,qi]∈RN×L,其中qi表示对应于训练样本yi的编码,N表示字典的尺寸大小,L表示训练样本总数;
设训练样本yi属于第M类,,结构化稀疏系数Q满足qi对应子字典Di的所有系数都为1,其余均为0,结构化系数系数Q与低秩矩阵的结合,可以对样本进行最优的分类。
作为本发明的进一步技术方案,所述步骤5的算法流程包括如下内容:给定训练样本,其中样本Y=[Y1,Y2,.....,Yi],包含c个类别的n个样本;表示第i类的样本,d表示每个样本向量的维数,ni表示第i类样本的样本个数;每类样本学习一个子字典,最终整合成字典D=[D1,D2,.....,Di],其中表示对第i类样本进行学习后得到的子字典,表示每个子字典原子的维数,表示第i类子字典的原子个数。
作为本发明的进一步技术方案,所述算法流程中的模型具体包括如下内容:
a.生成初始字典D,将训练样本Yi降维,得到的新向量作为子字典Di的初始原子;
b.得到相关编码系数Xi(i=1,2,…,c),并保持xj(j≠i)不变,依序对编码系数进行更新,字典模型表达式为:
从式中可以得出,子字典已经能表征训练样本,其中,r(Yi,D,Xi)是样本重新构建后产生的偏差项,Di是第i类训练样本的子字典;||X||1为是稀疏分类的约束项,F(X)是K-SVD判别式;方程中的F(X)的类内离散度尽量减小,类间离散度尽量增大达到更好地识别效果;
由此可得出下式:
上式由迭代投影方法求得;
c.更新子字典Di(i=1,2,…,c):同时固定Dj(j≠i)、系数X,同步更新子字典Di(i=1,2,…,c)和样本Y在子字典上对应的编码系数Xii,得到简化后的字典模型方程为:
则
d.迭代:J(D,X)大于或等于阈值或者迭代次数已达上限,此时将自动输出稀疏编码X和字典D,否则返回步骤b。
e.分类:样本y的编码系数将根据结构化低秩矩阵D得出
式中:x=[x1;x2;x3……xc],xi是对应于子字典Di的编码系数,根据式计算出第i类的残差
作为本发明的进一步技术方案,所述步骤5中的训练阶段,既可以输入纯净语音的i-vector构成训练数据对并提取相应的语音特征,也可以将纯净语音和噪声数据混合的i-vector输入字典;在分别将不同信噪比和种类的含噪语音和的语音特征作为输入和标签数据训练判别字典时,得到的低秩部分E除了含有i-vector的共性字典外还含有噪声字典,也会被单独提取出来不参与分类过程。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:可以有效处理i-vector中的共性部分,将i-vector统计量中说话人共有的部分单独分离出来,并对字典中的说话人子字典都进行了低秩处理以尽可能降低说话人i-vector共性部分对最后打分结果的影响,从而使最后生成的字典识别力更强;适应字典学习准则的编码系数可以有效提升识别力,并通过结构化稀疏来进行最优分类。
附图说明
图1为本发明的系统结构图。
图2本发明中MFCC特征提取流程图。
图3为本发明中算法流程图。
具体实施方式
下面结合附图1-3对本发明的技术方案做进一步的详细说明:
本实施例提出了一种基于字典学习和低秩矩阵分解的说话人识别方法,包括以下步骤:
步骤1,对说话人音频进行预加重、分帧、加窗、端点检测等处理;
步骤2,提取出对应每个说话人语句的MFCC特征,并训练GMM-UBM模型;
步骤3,通过联合因子分析(JFA)估算全局差异空间矩阵T,全局差异空间因子w;
步骤4,得到对应每个说话人语句的i-vector;
步骤5,从训练集中提取M维度的i-vector并生成特征矩阵,根据训练集和测试集,对判别字典进行生成,得到的字典将作为i-vector后端处理和打分模块,为最终判别提供依据;
设测试集的i-vector样本集合为Y,矩阵C含有说话人共性部分E和说话人个性部分DX,即Y=DX+E,那么对于训练样本Y,其在字典D上的最优稀疏表示系数应为一块对角阵,如下所示:
字典D包含c个类别的子字典,X是训练样本Y在字典D上的稀疏稀疏,其中Xi是对应子字典Di的稀疏系数;字典D具备可识别和重建的能力,从而低秩和稀疏稀疏表示,子字典Di为第i类训练样本的转悠字典,达到最好的识别率;第i类i-vector样本被第i类的子字典D很好表示;
字典Di(i≠j)对应的编码系数为0;结构化稀疏对应为Q=[q1,q2,.....,qi]∈RN×L,其中qi表示对应于训练样本yi的编码,N表示字典的尺寸大小,L表示训练样本总数;
设训练样本yi属于第M类,,结构化稀疏系数Q满足qi对应子字典Di的所有系数都为1,其余均为0,结构化系数系数Q与低秩矩阵的结合,可以对样本进行最优的分类。
所述步骤5的算法流程包括如下内容:给定训练样本,其中样本Y=[Y1,Y2,.....,Yi],包含c个类别的n个样本;表示第i类的样本,d表示每个样本向量的维数,ni表示第i类样本的样本个数;每类样本学习一个子字典,最终整合成字典D=[D1,D2,.....,Di],其中表示对第i类样本进行学习后得到的子字典,表示每个子字典原子的维数,表示第i类子字典的原子个数。
所述算法流程中的模型具体包括如下内容:
a.生成初始字典D,将训练样本Yi降维,得到的新向量作为子字典Di的初始原子;
b.得到相关编码系数Xi(i=1,2,…,c),并保持xj(j≠i)不变,依序对编码系数进行更新,字典模型表达式为:
从式中可以得出,子字典已经能表征训练样本,其中,r(Yi,D,Xi)是样本重新构建后产生的偏差项,Di是第i类训练样本的子字典;||X||1为是稀疏分类的约束项,F(X)是K-SVD判别式;方程中的F(X)的类内离散度尽量减小,类间离散度尽量增大达到更好地识别效果;
由此可得出下式:
上式由迭代投影方法求得;
c.更新子字典Di(i=1,2,…,c):同时固定Dj(j≠i)、系数X,同步更新子字典Di(i=1,2,…,c)和样本Y在子字典上对应的编码系数得到简化后的字典模型方程为:
则
d.迭代:J(D,X)大于或等于阈值或者迭代次数已达上限,此时将自动输出稀疏编码X和字典D,否则返回步骤b。
e.分类:样本y的编码系数将根据结构化低秩矩阵D得出
式中:x=[x1;x2;x3……xc],xi是对应于子字典Di的编码系数,根据式计算出第i类的残差
训练阶段,既可以输入纯净语音的i-vector构成训练数据对并提取相应的语音特征,也可以将纯净语音和噪声数据混合的i-vector输入字典;在分别将不同信噪比和种类的含噪语音和的语音特征作为输入和标签数据训练判别字典时,得到的低秩部分E除了含有i-vector的共性字典外还含有噪声字典,也会被单独提取出来不参与分类过程。
本发明中,选择TIMIT语音开源数据库的100个说话人来进行相关实验。TIMIT语音库共有630个说话人(192个女性说话人和438个男性说话人),来自美国8个方言地区。每个说话人10条语音,每条语音平均时长为3秒。数据采样频率为16kHz,采样精度为单通道16bits。
每个说话人选取其中的10条语音,用来训练UBM、生成相应的i-vector以及训练字典。其中,每个说话人的9句语音作为注册语音,1句语音作为测试语音,加起来共10000句语音。
特征提取阶段,说话人语音段经过VAD去除静音、预加重处理、加汉明窗分帧(帧长为25ms,帧移10ms)后,分别提取22维的MFCC和GFCC静态特征。
测试语音的特征维数为39,MFCC特征帧长为25ms、帧移为10ms。高斯背景模型的混合数为512。i-vector维度为400,PCA子空间矩阵维度为200,帧长为25ms、帧移为10ms。
选取1000条纯净语音的i-vector作为判别字典的训练集,100条纯净语音的i-vector作为测试集。在未加噪声条件下,我们将LRSDL与FDDL方法进行数据对比,通过多次实验得到的平均系统识别率(acc)表现表1所示:
表1 FDDL与LRSDL方法在测试纯净语音环境下的性能表现
Acc代表该方法在该实验条件下的识别率,我们通过多次实验取均值,结果发现FDDL识别率的均值要略优于LRSDL。将Noise92X噪声库中的babble(嘈杂的人群)噪声按不同信噪比添加进语音信号中。
表2 FDDL与LRSDL方法在babble噪声环境下的性能表现(0dB)
表3 FDDL与LRSDL方法在babble噪声环境下的性能表现(5dB)
表4 FDDL与LRSDL方法在babble噪声环境下的性能表现(15dB)
从上表中发现,在噪声环境下,LRSDL的识别率要明显优于FDDL,其原因是低秩部分包含了噪声字典,系统最后打分时会将噪声字典部分单独抛离进行打分,因此结果有明显优。
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!