一种基于多进程线程并行运算的英语朗读练习系统的制作方法
本发明涉及英语朗读练习系统技术领域,尤其涉及一种基于多线程/进程并行运算的英语朗读练习系统。
背景技术:
现代语音技术高度发展,各种智能设备也十分普及,手机、台式电脑、手提电脑、平板电脑成为人们常用的物件;现有的英语朗读练习、口语学习软件系统或智能设备,一方面基本全是采用设定好的文本内容或音频数据进行指定范围内的练习训练,根据采用预设的试题文本进行朗读打分,所练习的文本内容范围被限定在一个狭窄范围,枯燥乏味且限定了练习的内容,用户难以自由选择适合自身学习练习的内容,无法根据用户自身学习练习的需求进行个性化调整,另外一方面,朗读完成一句或一小段后进行评分提示,并伴随用户许多操作,测评后在给于矫正,不及时,降低了学习矫正的效率,对英语的初学者尚且可以满足其学习练习的需要,但对进阶学习英语的用户来说,让用户在指定时间内解除更多的信息混杂在需要矫正的发音错误中,使得学习练习的效果大打折扣,而多句等较多内容进行连续评分朗读练习,因为涉多重语音处理运算,会造成延时卡顿。
技术实现要素:
为解决背景技术所述的问题,本发明创造了一种基于多线程/进程并行的英语朗读练习系统。采用预设各项语音任务,进行多线程/进程并算,主线程/进程根据需要调用辅助线程/进程的运算结果,克服可能存在的延时卡顿,并优化各个线程/进程唤醒的最佳起点,来均衡系统的运算负载,降低系统对运算能力的基本要求。
为实现上述目的,创造一种多线程/进程并行运算的英语朗读练习系统,具体的技术方案包含如下步骤和要素:
前期预备:设置数据库软硬件环境,创建数据及表格,用于记录各种参数、信息内容等。
语音接收模块:用户通过录音设备或智能设备上的录音传感器,进行录音,在系统中配置语音信号处理模块,由系统监听来自于用户的语音,接收分析监听到的语音信息。
用户模块,包含、用户注册、用户管理、系统用户中心、普通用户中心子模块,用于完成账户的注册,用户的管理、用户使用功能的现实,并配置相关界面、程式过程,和服务器的相对应的数据储存、读写、删除编辑映射对应。
朗读练习的文本内容模块;一种为系统内置文本内容、并配置对应的标准语音、声学特征参数、语音时长等相关信息;另外一种是自定义练习的文本模块,配置用户增加编辑练习的文本界面,文本分类,系统管理用户文本,并设置相应的数据库表格或指定服务器路径的存储空间。
知识库数据储存模块,包括各种音标音节发音规则,标准的音标发音的语音文件、容易朗读错误的知识点,所述知识库在英语朗读练习时候根据系统条件检索调用。
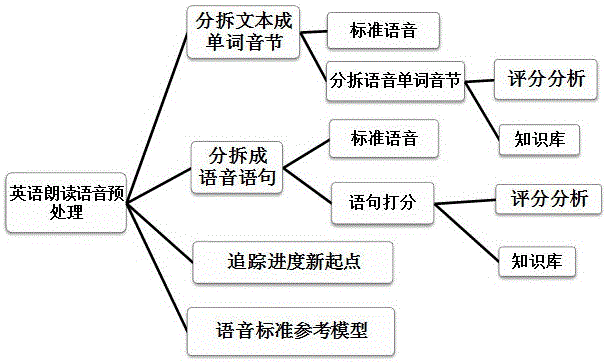
在系统对用户对英语文本朗读语音预处理后,根据上述英语朗读练习的核心模块,采用并行运算的多线程/进程来分布运算,并行启动任务处理的线程/进程包括:语音标准参考模型线程/进程、朗读进度起点追踪线程/进程、进度标识线程/进程、语句打分线程/进程、单词音节打分线程/进程、用户界面主线程/进程。
英语朗读练习系统中的多线程/进程并算,关键要素之一在于线程/进程之间的数据交换,不同程序语言都给于了相关的技术解决方案,vb语音进程通讯实施例:
为了进度标识、语音评分等进程不影响用户界面主进程,避免造成卡顿等不良的用户体验,分别将打分模块、进度标识模块等各自单独成可执行文件exe,通过同步通讯和主进程进行数据交换,进程之间的通讯具体实施:使用vb语言通过配置picture或text等控件的linktopic、linkmode参数使得适合于同步通讯,主进程序中使用控件的linkexecute命令将指定的信息传送给用户界面主线程序。主线程序、语音打分模块程序、进度标识程序分别首先配置好工程的名称及程序界面的相关属性,使得符合结合上述通讯的接收条件,通过form_linkexecute过程,接收通讯的信息内容。
一种多线程并行的英语朗读练习系统同步响应用户指令的方法,多线程/进程处理不同的任务,提高语音模块内部进行并发运算,大大提升处理的效率以及降低延缓性,但却涉及同步相应用户指令的困难,本发明的解决方案:
a、为每一个线程/进程嵌入用户指令监视模块,在指定时间间隔监视特定数据库位置的数值变化或监视特定系统路径文件夹下特定类的文件,所述文件中包含指令代码、指令版本代码;
b、为每个监测结果,匹配一个线程/进程执行得指令模块。
c、根据监视的结果,执行相应的线程/进程执行指令。
d、优选地,用户指令监视模块每间隔600毫秒读取指定位置用户信息命令信息,并将其中的版本号和线程/进程内部记录的版本号对比,相同则不执行获得的用户指令的代号,否则就按照新获得的指令代号执行相应的运算指令,并将线程/进程内部记录的版本号更新为即时获得的版本号。
用户界面主线程/进程用户进入英语朗读练习核心模块;其中包括如下几个关键要素步骤:
步骤1、用户根据文本进行朗读练习,系统获得用户语音,并进行进行预加重、分帧加窗、解码、离散傅里叶变换、滤波、取对数、离散余弦变换,声学特征运算作为该英语口语发音预处理结果等待调用。
步骤2、开启语音标准参考模型线程/进程,设置不合格、合格、良好、优秀判定标准的阀值。
步骤3、开启朗读进度起点追踪线程/进程、进度标识进程、语句打分线程/进程、单词音节打分线程/进程,以hmm后验概率算法等打分算法,通过用户朗读分拆段和对应的语音标准参考模型之间的声学特征最高值作为其映射到文本、单词、音节的分值,并和上述阀值分别比对,并根据结果将对应的文本部分进行标识,改变字体、字体颜色、下划线,所述标识和系统设定的不合格、合格、良好、优秀预先设定的标识规则一致,成绩文本标示实施例:不合格对应的文本字体颜色为红色。
步骤4、将当前朗读语音所能对应的文本最末尾,作为朗读进度进行进度标识。
步骤5、进一步,将不合格、合格对应的文本标识分块分别链接到文本对应的标准语音文件播发模块、知识库中相关知识点显示模块;用户中断语音朗读,点击标识文本,系统唤醒该文本链接对应的程序模块。
步骤6、用户继续朗读练习,到文本结束,为指定位置显示结果分析标识,链接到朗读练习结果分析模块,包括,本次练习的综合得分,不及格发音的单词、句子并链接对应的标准语音模块、知识点模块、对用户的建议内容;为指定位置显示朗读练习,链接到文本练习模块。
语音标准参考模型线程/进程,则根据文本内容在数据中检索语音标准参考模型相关内容,检索到文本内容对应的标准参考模型为系统内置的记录,读取所述标准参考模型的相关数据,包括语音声学特征数据,标准语音存放在系统里的路径信息、语音时长、声学特征参数等,没检索到记录按照如下步骤创建语音标准参考模型;
系统内没有英语文本对应的标准参考模型时候,先根据文本内容获得对应的标准语音,获取的方式采用现有技术常用的手段,获取文本相关标准语音的实施例1:使用语音引擎或第三方语音api接口,通过pos提交,形成语音文件,再转化成标准参考模型。获取文本相关标准语音的实施例:a、服务器系统上安装语音引擎;b、通过createobject("sapi.spvoice")方法创建并返回一个对语音引擎对象;c、通过接口函数中的speak命令将指定的接收到文本转化成语音并播放出来;d、通过录音或数据转化储存语音文件。
进一步,将根据文本内容获取的标准语音,和所述的声学特征参数、语音时长、存储在系统的路径等信息一并记录到系统中,等待系统调用;所述文本内容包括文本的语句、单词、音节字符组。
朗读进度起点追踪线程/进程,一种英语朗读训练系统中朗读进度起点追踪的方法,根据语句之间的停顿静音分句,实时检测朗读的进度,追踪朗读的新起始点。
设置静音判定阀值,设置判定语句间隔静音时长值t,以时间为循环运算的递增参数,依次在通过预处理的用户语音信息流上取t长度段,计算平均声强,并和静音判定阀值进行比对。
以上比对结果为:所述语音段声强均值大于静音判定阀值,则按照上步骤以时间递增为起点,取过预处理的用户语音信息流上取t长度段,继续上述判定的运算。
比对结果为:所述语音段声强均值小于或等于静音判定阀值,记录该语音段的起点时间t1,则将t1作为语音中前面语句的结尾时间点,开始监视朗读进度起点运算,继续所述递增循环运算,将t1之后的第一个比对结果为“语音段声强均值大于静音判定阀值”的语音段起始时间t2记录;则将t2作为语音中当前语句的开始的起始时间点,。
设置文本语句首部单词或音节字符组对应语音识别打分的识别阀值k。
将文本句子中第一个单词或音节对应的语音标准参考模型及时长排队罗列,依次被用于取语音段中t2为起始点,以当年所用的标准参考模型所对应的时长为长度,语音长度不够取段时,等待语音进度推进到足够取段,然后进行打分运算,并获得分值;当分值比对获得最高分值大于等于k时,对应的标准参考模型q,将q所映射的文本字符组作为句子的起点,设定为当前朗读进度的起点,并进行标识,最高分值小于k时,根据英语文本的标点符号,将当前进度标识焦点所在的文本语句第一个字符的下一句设定为新进度起点,并进行标识。
记载所述t1、t2极其对应的文本字符位置,得到用户语音时间段和文本内容的映射对应关系。
进度标识进程,采用一种实时引导朗读语音速度的进度标识的方法,英语文本句子、单词、音节等文本单元对应的标准语音段的标准时长,将这时长平均分配到文本的字符上形成相对时间戳(timestamp),所述字符可以为字母、数字、符号等。
时间戳信息包括文本句子、单词、音节开时被朗读的时间点以及字符持续被朗读的时间;因为标准时长和用户朗读时长存在误差,确保保证进度标识在当前朗读的对应的文本单元内的一个位置,系统识别到新的文本对应语音的单元时候,跨越式将进度标识移动该文本单元。
在具备时间戳的文本单元,进度条匀速推进标识的算法为:
进度标识在字符上的速度speed=文本单元对应的标准语音时长/文本单元字符长度。
其中文本单元字符长度为第一个字符的起点位置到最后一个字符末端位置的距离。
进一步,通过进程通讯或进行数据实时数据交换,获得朗读进度起点追踪线程/进程所得到的文本上的新起点时,进度标识线程/进程终止原有进行的任务,并以所述新起点为起点,重新开始进度标识进行的任务,通过进度标识线程/进程和朗读进度起点追踪线程/进程数据交换配合,进度标识在文本单元上以用户语音实际对应的文本单元段为起点标准,在文本单元内以标准语音进度为依据,从而对用户朗读的语速具有一定的引导作用。
语句打分线程/进程,即对英语的语句进行整体比对打分,根据朗读进度起点追踪线程/进程中对用户语音进行分句分拆的方法及用户语音语句和文本的映射对应方法、获得该用户语音中句子所对应的语音标准参考模型线程/进程中创建的语音标准参考模型,通过声学特征参数进行打分,而语音打分的方法有hmm对数似然度打分、段分打分、对数后验概率打分、持续时间打分等,优选地,本发明申请采用持续时间打分,将标准参考模型统计出句子持续时间的离散概率分布进行语句打分,用户语音该句子的打分a值采用如下算式:
其中
单词音节打分线程/进程,即语句打分线程/进程的进一步,对语音语句分拆成单词音节打分的现有技术有hermankamper,arenjansen和sharongoldwater提出的无监督贝叶斯模型,能将未标记的语音进行分割然后聚类成虚拟词组进行打分分析。
优选地,采用循环递推分拆打分法。
根据朗读进度起点追踪线程/进程中对用户语音进行分句分拆的方法及用户语音语句和文本的映射对应方法、获得该用户语音中句子的分拆,因此获得英语朗读打分指定的文本的范围局限在很小的范围,将所述英语语句文本分拆成单词组,通过检索获得单词、音节字符组所映射对应的语音标准参考模型线程/进程中创建的语音标准参考模型。
先假设单词被朗读的时长为所对应的语音标准参考模型记录的时长,在被测语音上依次分拆该时长的语音段,和对应的语音标准参考模型进行比对获得最高分值的语音段,然后进行向前向后的加减时长的修正,获得单词分值最高所匹配的语音段,并将最高分值设定为当前单词或音节字符组。
进一步,根据单词、音节字符组映射的语音分值进行标识,给用户明确的朗读水平的精准理解。
一种英语练习系统程序内部均衡运算分布的方法,在英语朗读练习系统中,涉及语音的多重分析运算,需要一定的硬件运算能力;上述多线程/进程技术方案虽然逼近于同步地分析打分,过于集中在同一时间段并行运算有时会造成系统运算能力不够,任务的不同,难以均衡使用硬件系统的运算能力,有明显的波峰波谷效应。
为了不将所有线程/进程几种在一个时间点高峰运算,增加系统运算的负担,本发明采用预判线程/进程运算,在时间上尽量错开运算负荷,具体实施为:上述多线程/进程技术方案的任务为:朗读语音预处理后开启线程/进程:程语音标准参考模型线程/进程、朗读进度起点追踪线程/进程、进度标识进程、语句打分线程/进程、单词音节打分线程/进程;将其中的语音标准参考模型线程/进程在设置文本时,进行预先开启,错开朗读时打分分析运算的运算高峰,获得用户朗读语音时候唤醒朗读进度起点追踪线程/进程、进度标识进程、语句打分线程/进程、单词音节打分线程/进程。
附图说明
图1为一种基于多线程/进程并行运算的英语朗读练习系统初步的整体逻辑框架图。
图2为一种基于多线程/进程并行运算的英语朗读练习系统经过内部均衡分布任务改进的整体逻辑框架图。
通过以上完整的技术方案,用户就可以在基于英语文本朗读练习的系统中,自定义英语文本进行连续的练习,并在练习过程中实时学习矫正英语朗读错误,强化学习和用户朗读错误相关的英语朗读知识点,进行高效有针对性的学习英语朗读,提高英语朗读学习的效率。
特别申明:在本说明书中所述的“实施例”等,指的是结合该实施例描述的具体特征、要素或者特点包括在本申请概括性描述的实施例中。在说明书中多个地方出现同种表述并非限定特指的是同一个实施例。也就是说,结合任一实施例描述一个具体特征、要素或者特点时,所要主张的是结合其他实施例来实现这种特征、要素或者特点被包含于本发明申请保护的权利要求范围中;实施例是参照本发明逻辑架构及思路的多个解释性实施例对本发明进行了描述,但本发明的保护范围并不局限于此,本领域技术人员在本发明技术方案框架下可以设计出很多其他的修改和实施方式,可以对技术方案的要点变换组合/或布局进行多种非本质性变型和改进,对于本领域技术人员来说,其他的用途也将是明显的,可轻易想到实施的非实质性变化或替换,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 还没有人留言评论。精彩留言会获得点赞!