一种用于语音测谎的栈式去噪自编码器及深度神经网络结构的制作方法
本发明属于语音信号处理
技术领域:
,具体涉及到一种用于语音测谎的栈式去噪自编码器及深度神经网络结构。
背景技术:
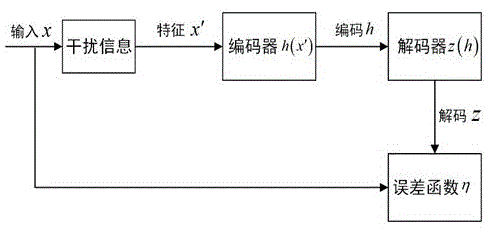
:长期以来,心理学家对人类的欺骗行为及其检测一直很感兴趣。社会心理学研究已经证实说谎是日常社会交往的一个共同特征,但人们并不善于对谎言进行鉴别。谎言的识别对于防止电话诈骗、辅助刑侦案件处理以及情报分析有着重要的意义,因此对于测谎的研究是目前的研究热点。在语音谎言检测领域,特征提取及分类识别是其核心步骤。目前,语音识别常采用的特征是组合特征,特征是否有效很大程度上依赖于经验和运气,而且组合特征的维数较大,直接使用会使识别器的计算量大大增加,还可能会遇到维数灾难和过拟合等问题。面对这些问题,常采用特征降维方法对特征进行预处理,常用的降维方法有主成分分析(principalcomonent,pca)、线性判别式分析(lineardiscriminiantanalysis,lda)、局部线性嵌入(locallylinearembedding,lle)。但以上的特征预处理方法对识别率虽有一定的提高,但还远远达不到人类识别的精度。因此,如何提高特征表征性并提高识别率,仍然亟待研究。因此本发明主要关注于提取了表征性更好的特征以实现更优秀的语音测谎工作。技术实现要素:由于dnn是高度非线性且非凸的,初始化点可能很大程度地影响最终网络的效果。输入到dnn的数据影响着最终的分类效果。针对单一dnn结构影响语音谎言识别率的问题,本文提出一种结合栈式去噪自编码器和深度神经网络的结构。原始特征经过栈式去噪自编码器后,最终得到的特征维度较小,更有表征性。在dnn之前经过训练好的sdae的处理,可看作对dnn进行预训练。也就是把sdae的最后一个去噪自编码器的编码权重矩阵当作dnn第一个隐藏层的权重矩阵,这样相当于把dnn权重调整到一个较好的初始点。并潜在的使用生成性预训练准则正则化dnn训练过程,从而加速训练过程,节约时间成本,优化dnn的识别效果。“sdae-dnn”结构中的栈式去噪自编码器是提前训练完成的。具体步骤可分为预训练和微调,前者为无监督贪婪逐层训练,该方式比随机初始化更加合理有效。提高了梯度传播的效率。后者根据标签及softmax分类器输出的结果对比进行有监督训练,进一步的,与语音情感识别的多分类不同,语音测谎只需要判断出该语音是真话还是谎言即可,这样在训练样本较小的情况下会产生过拟合,因此我们谨慎的在sdae的每层都加入一定比率的dropout使某些隐层神经单元以一定的概率暂停工作,达到防止过拟合的作用,这个改动对于正确率的提升也十分重要。此外,在网络中我们使用批归一化以达到加速训练的作用。利用反向传播算法进行权重矩阵w和偏置向量b参数的更新,完成微调获得更加强健的sdae结构。参数更新公式如下所示:其中α为学习率,为误差函数。该结构中的dnn的输入即为sdae的输出结果。dnn网络的目标是近似一个目标映射f,记为y=f(x,θ),对于分类神经网络来说,通过学习参数θ,使映射拟合各类别的边界。输入数据经过网络后,执行一系列的操作后,找到输出类概率,与真实标签比较,计算误差值,然后通过反向传播算法来最小化误差,以此更新参数,提高网络分类的准确率。利用dnn进行训练的过程分为前向传播和误差反向传播两个过程。前向传播时,每一层都可以表示为权重与神经元组成的向量相乘,再加偏差量。为了对高度非线性问题进行有效建模,需要对各层添加非线性激活函数。首先,计算加权输入信号和偏置的总和记为a。a=b+w1x1+w2x2然后用非线性激活函数h将a转化为输出y。y=h(a)反向传播时,采用随机梯度下降算法更新权重和偏差。不断提高结构的识别效果。附图说明:图1为一种用于语音测谎的去噪自编码器原理图,图2为“sdae-dnn”结构图。图3为“sdae-dnn”训练测试流程图。具体实施方式:为了验证我们所提出的模型的性能,我们在csc谎言语音库上进行试验。csc谎言语料库是第一个由语言科学家设计和收集的谎言语料库。研究对象被招募到一个“交流实验”中,并被告知在欺骗中取得成功的能力代表了某些可取的个人品质,且研究试图找出符合美国25位“顶级企业家”。这些演讲以16千赫的速率采样,并根据标签分为5412个有效的演讲片段,包括2209个谎言,并最终得到约7h的谎言语音样本。本文从csc库中剪切出5411条语音用于实验。步骤一:去掉音质较低的部分后,从该库剪切出5411条语音进行实验,每条语音时长2s左右,包含了2209条谎言语音,将剪切出的语音中的4328条语音作为训练集,剩下的1083条语音作为测试集。步骤二:语音特征是进行谎言识别的关键,我们使用的语音特征是2009年国际语音情感识别挑战赛的标准特征集。其中有2*16个低层描述子,如zcr,hnr,,mfcc(1-12)等,以及12个描述函数,有均值,最大最小值,均方误差等,总的特征维数为2*16*12=384维,这个特征集包含了声学特征中使用最为广泛的特征和函数。我们使用开源工具包opensmile从语音中提取这些特征,每条语音提取出的特征都为384维,共有5411条语音,因此数据总量为5411*384。步骤三:首先我们将系数为0.3的高斯噪声加入语音,作为模型的输入数据。sdae第一层网络神经单元数为120,第二层网络层数为30。预训练次数和学习率为300、0.001。通过与测试集标签对比,通过反向传播进行200次微调,其中反向传播学习率为0.001。我们选取正确率作为分类性能指标。这是语音测谎领域最常用的评价指标。对于每个模型,都进行10次试验并取这10次实验结果的平均值作为最终的结果。步骤四:将经过训练好的sdae重构的特征输入一层dnn进行网络识别。dnn隐层节点数为500,学习率为0.001,激活函数采用sigmoid函数。步骤五:为了进一步验证该算法的有效性。将所提算法与svm以及“sdae-svm”分类器作对比,其中svm的c值取1。每种算法都进行了10次实验并取平均值。各个分类器在不同谎言语料库的识别准确度如表1所示。表1在csc库上由不同分类器得到的平均正确率分类器cscsvm59.8%dnn60.3%sdae-svm61.4%sdae-dnn62.4%由表1可看出本文设计的基于栈式去噪自编码器及深度神经网络结构相较于svm、dnn以及“sdae-svm”算法在csc语料库上的识别准确度分别提高了2.6%,2.1%和1.0%。栈式去噪自编码器结构可以从原始特征中学习到鲁棒性更好的特征,后接dnn进一步学习特征,相比直接使用dnn网络能够得到表征性更好的特征,并且加速训练过程。最后通过微调网络提高识别准确度,可以达到比现有常用算法更好的谎言识别效果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1