基于语音识别的声控提词器系统的制作方法
本发明属于提词器技术领域,尤其涉及一种基于语音识别的声控提词器系统。
背景技术:
近几年,随着人工智能的快速发展,依托人工智能的教育也迅速发展开来。随着人工智能与教育的融合发展,教育行业特别是特殊教育领域,对人工智能教育的关注都颇高。因为人工智能教育对学生个性化的学习、各方面素养和能力的获得、全球课堂的普及以及教师重复性劳动的减少等都有益处。要想实现人工智能教学,前期势必要依赖大量的知识点教学视频,这样才能为每一个孩子智能匹配个性化学习计划。而现阶段知识点教学视频的制作,主要分为四步:一是教研人员根据知识图谱撰写设计教学文稿,即知识点讲解文案,包括导入视频文稿、知识点讲解视频文稿、练习题目解析文稿等;二是出镜教师根据教学文稿进行视频录制,拍摄大量视频素材;三是视频编辑制作人员根据教学文稿剪辑制作视频;四是教研质检人员审核教学视频是否合格,审核通过安排网站上线。知识点教学视频的录制一般都在摄影棚内进行,录制时需要配备一个专门的工作人员操作提词器,主要包括:一配合用户的讲解速度操作提词器进行手工翻页,二核对用户的讲解内容是否与教学文稿相符,若出现讲解内容与教学文稿不一致的情况,需进行标记并提醒用户进行重新录制。
在摄影棚录制知识点教学视频时,由于用户需要在短时间内完成大量教学视频的录制而无法背下教学文稿,故而需要把教学文稿通过提词器显示出来。提词器与摄像机三脚架支撑在同一轴线上,从而产生了用户始终面向镜头的亲切感。但由于当下的提词器是手动式,所以录视频时需要配备一个专门的工作人员,配合用户操作计算机手工翻页,且需要时刻注意讲解内容与教学文稿不一致的情况,并进行人工干预。如若沟通不及时,就会导致录制暂停或重录,这样就会浪费人力、时间,还会干扰用户的心态,造成录制效率和质量低下,甚至会影响教学视频的教学效果。
因此,如何解决用户在录制视频时能够智能控制提词器,是亟需要解决的难题。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于语音识别的声控提词器系统,其避免了手动控制提词器翻页,能够使用户在录制视频时自行翻页。
为解决上述技术问题,本发明第一方面公开了一种基于语音识别的声控提词器系统,包括
显示模块,用于显示文稿内容数据;
语音接收模块,用于采集用户语音数据;
文稿存储模块,用于存储文稿内容数据;
比对模块,用于比对当前采集到的用户语音数据与当前显示的文稿内容数据的相似度s1,若s1≥q1,则文稿存储模块向显示模块发送下一条文稿内容数据进行显示,q1为阈值。
进一步地,所述相似度s1,0≤s1≤1,所述阈值q1,0.9≤q1≤1。
进一步地,还包括指令存储模块,用于存储内部语音数据及与内部语音数据对应的指令数据;比对模块,还用于比对当前采集到的用户语音数据与内部语音数据的相似度s2,若s2≥q2,则执行与该内部语音数据对应的指令数据;指令存储模块内至少存储有将一文稿内容数据发送至显示模块进行显示的指令数据。
进一步地,所述相似度s2,0≤s2≤1,所述阈值q2,0.9≤q2≤1。
进一步地,还包括提示模块,当s1<q1和\或s2<q2,提示模块发出提示数据。
本发明第二方面公开了一种基于语音识别的声控提词器系统,包括
显示模块,用于显示文稿内容数据;
语音接收模块,用于采集用户语音数据;
文稿存储模块,用于存储文稿内容数据;
指令存储模块,用于存储内部语音数据及与内部语音数据对应的指令数据;
比对模块,用于比对当前采集到的用户语音数据与内部语音数据的相似度s2,若s2≥q2,则执行与该内部语音数据对应的指令数据;指令存储模块内至少存储有将一文稿内容数据发送至显示模块进行显示的指令数据。
进一步地,所述相似度s2,0≤s2≤1,所述阈值q2,0.9≤q2≤1。
进一步地,还包括提示模块,当s2<q2,提示模块发出提示数据。
本发明与现有技术相比具有以下优点:本发明采用语音识别技术将用户的语音信息,自动与文稿进行匹配,可自动实现提词器的自动翻页,无需依赖人工手动翻页,提高录制效率,减小人力的浪费。此外,该系统还能够在录制过程中自动判断是否出现了讲解内容与文稿不一致的情况,并且能够自动地实时提醒用户。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
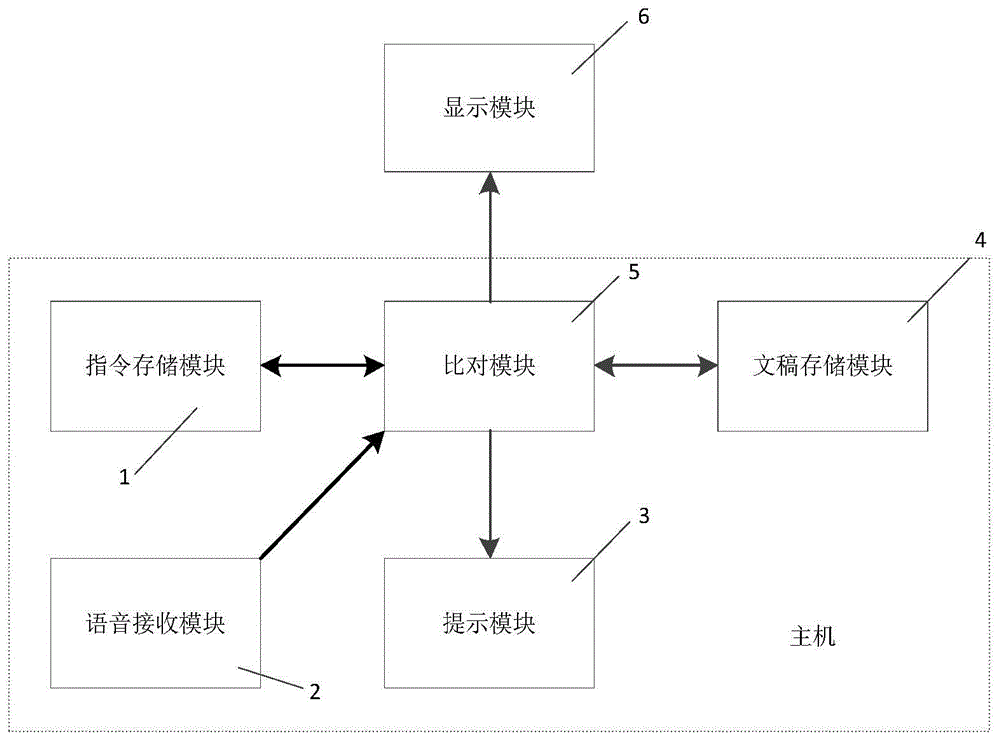
图1为本发明的电路原理框图。
图2为本发明实施例1的使用流程图。
图3为本发明实施例2的使用流程图。
附图标记说明:
1—指令存储模块;2—语音接收模块;3—提示模块;
4—文稿存储模块;5—比对模块;6—显示模块。
具体实施方式
实施例1
如图1所示,一种基于语音识别的声控提词器系统,包括显示模块6、和主机;所述显示模块6,用于显示文稿内容数据;所述主机包括语音接收模块2,用于采集用户语音数据;文稿存储模块4,用于存储文稿内容数据;比对模块5,用于比对当前采集到的用户语音数据与当前显示的文稿内容数据的相似度s1,若s1≥q1,则文稿存储模块4向显示模块6发送下一条文稿内容数据进行显示,q1为阈值。
所述相似度s1,0≤s1≤1,所述阈值q1,0.9≤q1≤1。
本实施例中,所述语音接收模块2为麦克风。
需要说明的是,当比对模块5对用户语音数据和文稿内容数据进行比对时,比对模块5先将用户语音数据转换为文字数据,然后将该文字数据与文稿内容数据进行比对。例如,当语音接收模块2采集到“春江花月夜张若虚”的用户语音数据时,比对模块5将该用户语音数据转换为“春江花月夜张若虚”的文字数据,并以此文字数据与当前显示模块6上显示的文稿内容数据进行比对,若相似度s1为1,则文稿存储模块4向显示模块6发送下一条文稿内容数据“春江潮水连海平海上明月共潮生”进行显示。
本实施例中,主机还包括指令存储模块1,用于存储内部语音数据及与内部语音数据对应的指令数据;比对模块5,还用于比对当前采集到的用户语音数据与内部语音数据的相似度s2,若s2≥q2,则执行与该内部语音数据对应的指令数据;指令存储模块内至少存储有将一文稿内容数据发送至显示模块进行显示的指令数据。
所述相似度s2,0≤s2≤1,所述阈值q2,0.9≤q2≤1。
需要说明的是,当比对模块5对用户语音数据和内部语音数据进行比对时,可以直接利用语音识别算法计算用户语音数据和内部语音数据的相似度;还可以预先将内部语音数据存储为文字格式的数据,在采集到用户语音数据时,比对模块5先将用户语音数据转换为文字数据,然后将该文字数据与文字格式的内部语音数据进行比对。例如,当语音接收模块2采集到“返回第一页”的用户语音数据时,比对模块5将该用户语音数据转换为“返回第一页”的文字数据,并以此文字数据在指令存储模块1查找对应的文字格式的“返回第一页”的内部语音数据,若查找到一内部语音数据与该用户语音数据的相似度s2为1,则执行该文字格式的“返回第一页”的内部语音数据对应的指令数据,将文稿存储模块4的第一条文稿内容数据送至显示模块6进行显示。
此处文稿存储模块4的一条文稿内容数据可在显示模块6上显示一页。文稿存储模块4内顺序存储有多条文稿内容数据。
本实施例中,主机还包括提示模块3,当s1<q1和\或s2<q2,提示模块3发出提示数据。
需要说明的是,提示模块3为喇叭或蜂鸣器,提示数据为提示音。且当s1<q1和s2<q2,显示模块6改变当前显示的文稿内容颜色。
如图2所示,本发明使用时,语音接收模块2采集用户语音数据,比对模块5调取该用户语音数据与指令存储模块1中的内部语音数据进行比对,若s2≥q2,则执行该内部语音数据对应的指令数据,例如指令数据的指令为“返回第一页”,比对模块5将该指令数据发送至文稿存储模块4,文稿存储模块4调取第一条文稿内容数据发送至显示模块6进行显示。若s2<q2,则比对模块5调取当前显示的文稿内容数据与该用户语音数据进行比对,若s1≥q1,则比对模块5向文稿存储模块4发送调取下一条文稿内容数据的指令,文稿存储模块4调取下一条文稿内容数据发送至显示模块6进行显示。当s2<q2,比对模块5控制提示模块3发出短促的提示音。当s1<q1,比对模块5控制提示模块3发出连续的提示音,并控制显示模块6改变当前显示的文稿内容颜色。
利用本发明相比现有提词器在使用时具有以下优点:
1、用户在录制视频时,如果显示模块的文稿已经讲解完毕,系统会自动地将后面要录制的文稿翻到显示模块,无需依赖人工手动翻页。
2、用户在录制视频时,如果出现口误、发音不准、表达错误等情况,系统会自动地实时提醒用户,由用户自行判断是否需要重新录制,无需配备一个专门的工作人员在旁时刻注意讲解内容与教学文稿是否一致。
3、视频录制完毕后,若用户对此不满意,想重新录制,可发出指令“返回第一页”,系统会自动翻到第一页,无需配备一个工作人员手动翻页,减少了人力的浪费,又提高了工作效率。
实施例2
如图1所示,一种基于语音识别的声控提词器系统,包括
显示模块6,用于显示文稿内容数据;
语音接收模块2,用于采集用户语音数据;
文稿存储模块4,用于存储文稿内容数据;
指令存储模块1,用于存储内部语音数据及与内部语音数据对应的指令数据;
比对模块5,用于比对当前采集到的用户语音数据与内部语音数据的相似度s2,若s2≥q2,则执行与该内部语音数据对应的指令数据;指令存储模块内至少存储有将一文稿内容数据发送至显示模块进行显示的指令数据。
所述相似度s2,0≤s2≤1,所述阈值q2,0.9≤q2≤1。
还包括提示模块3,当s2<q2,提示模块3发出提示数据。
需要说明的是,提示模块3为喇叭或蜂鸣器,提示数据为提示音。
本实施例中,所述语音接收模块2为麦克风。
需要说明的是,当比对模块5对用户语音数据和内部语音数据进行比对时,可以直接利用语音识别算法计算用户语音数据和内部语音数据的相似度;还可以预先将内部语音数据存储为文字格式的数据,在采集到用户语音数据时,比对模块5先将用户语音数据转换为文字数据,然后将该文字数据与文字格式的内部语音数据进行比对。例如,当语音接收模块2采集到“返回第一页”的用户语音数据时,比对模块5将该用户语音数据转换为“返回第一页”的文字数据,并以此文字数据在指令存储模块1查找对应的文字格式的“返回第一页”的内部语音数据,若查找到一内部语音数据与该用户语音数据的相似度s2为1,则执行该文字格式的“返回第一页”的内部语音数据对应的指令数据,将文稿存储模块4的第一条文稿内容数据送至显示模块6进行显示。此处文稿存储模块4的一条文稿内容数据可在显示模块6上显示一页。文稿存储模块4内顺序存储有多条文稿内容数据。
如图3所示,本发明使用时,语音接收模块2采集用户语音数据,比对模块5调取该用户语音数据与指令存储模块1中的内部语音数据进行比对,若s2≥q2,则执行该内部语音数据对应的指令数据,例如指令数据的指令为“返回第一页”,当比对模块5将该指令数据发送至文稿存储模块4时,文稿存储模块4调取第一条文稿内容数据发送至显示模块6进行显示。当s2<q2,比对模块5控制提示模块3发出短促的提示音。
以上所述,仅是本发明的较佳实施例,并非对本发明作任何限制,凡是根据本发明技术实质对以上实施例所作的任何简单修改、变更以及等效结构变化,均仍属于本发明技术方案的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!