基于卷积网格长短时记忆递归神经网络的自动语音识别加速方法与流程
本发明涉及一种自动语音识别加速方法。属于语音信号处理技术领域。
背景技术:
长短时记忆(longshort-termmemory,lstm)递归神经网络是自动语音识别任务中最常使用的模型。
近年来,随着lstm的不断发展,出现了一类增强版本的lstm,即二维lstm(twodimensionlongshort-termmemory,2d-lstm)。在这类lstm中,最具代表性的是网格长短时(gridlongshort-termmemory,grid-lstm)递归网络,其在频域和时域分别使用独立的lstm进行序列建模。网格长短时记忆递归神经网络已成为自动语音识别(automaticspeechrecognition,asr)系统的重要组成部分。然而,由于grid-lstm在时域和频域分别使用两个独立的长短时记忆(longshort-termmemory,lstm)递归网络对序列依赖关系进行建模,因此,grid-lstm在训练和推理过程中存在计算时间较长和计算量巨大的问题,即:由于grid-lstm使用两个独立的lstm针对输入频谱进行滤波操作,因此会导致巨大的计算代价。进一步,由于其自身的网格限制,使得模型无法并行运算。
在实际使用过程中,系统对于模型的实时推理能力要求较高,因此grid-lstm往往无法有效应用在实际任务中。目前的加速方法大多是在牺牲识别性能的条件下进行加速,并不能满足实际任务的需要。
技术实现要素:
本发明是为了解决目前的加速方法大多是在牺牲识别性能的条件下进行加速导致其不能满足实际任务的需要问题。
基于卷积网格长短时记忆递归神经网络的自动语音识别加速方法,包括以下步骤:
步骤1、时频块切分:
针对频谱x或者输入频谱x的多通道频谱子带x′进行时频块切分:
使用频率方向长度f,时间方向长度t的滑动窗,按照频域轴步长frestrip,时间轴步长timestrip,将频谱x或其多通道频谱子带x′切分为一系列时频块集合xblock=[x′1,1,x′2,1,…,x′t,k,…];x′t,k为一个时频块,t表示时域,k表示频域;
步骤2、局部特征提取:
首先,针对x′t,k进行卷积运算,提取当前时频块的局部频域特征
ft,k=x′t,k*wf
其中,wf为卷积核的第f个子卷积核矩阵;
然后,针对ft,k进行池化,pt,k为池化后的ft,k;
将pt,k归一化到指定维度
xt,k=pt,k×wl+b,
xt,k为归一化到指定维度后的pt,k,wl为权值矩阵,b为归一化到指定维度操作对应的偏置量;
步骤3、全局时频模式建模:
针对步骤2中得到的局部特征xt,k进行全局时频模式建模:
分别在频域和时域使用两个独立的lstm进行建模,具体流程如下:
其中,s∈(t,k),角标t,k表示时域、频域对应的参数;u∈(i,f,c,o),角标i,f,c,o分别表示输入、遗忘、记忆单元和输出对应的参数;
进一步地,输入频谱x的多通道频谱子带x′的确定过程如下:
针对频谱x,将其沿频域轴方向切分成n个子带,得到n个频域子带,且将n个频域子带之间的信息进行关联,将n个频域子带并排形成一个n通道的频域子带x′。
进一步地,所述的n=3。
有益效果:
本发明提出一种基于大频域步长的grid-lstm改进模型,即卷积网格长短时记忆(convolutionalgridlongshort-termmemory,convgrid-lstm)递归神经网络。该模型将卷积神经网络(convolutionalneuralnetwork,cnn)与grid-lstm相结合,弥补了grid-lstm在大频域步长情况下的精度损失。在此基础上,本发明进一步提出一种多通道频域子带的grid-lstm改进模型,即频域块卷积网格长短时(frequencyblockconvolutionalgridlongshort-termmemory,fbconvgrid-lstm)递归神经网络。在国际公开的数据集,与传统grid-lstm网络结构的方法进行了对比,本发明所提出的方法取得了最佳的性能表现。
附图说明
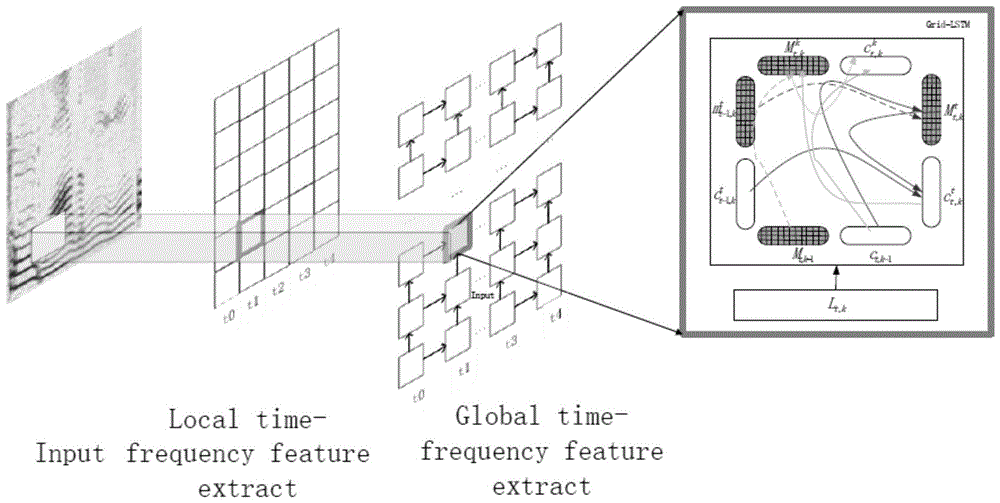
图1为本发明处理模型示意图,从左向右依次分为频谱输入(input),时频块划分与局部特征提取(localtime-frequencyfeatureextract)和全局时频结构建模(globaltime-frequencyfeatureextract);
图2为具体实施方式一中局部时频结构建模的具体过程;
图3为多通道频域子带的构建方式;
图4为具体实施方式二中局部时频结构建模的具体过程。
具体实施方式
具体实施方式一:
本实施方式所述的基于卷积网格长短时记忆递归神经网络的自动语音识别加速方法,包括以下步骤:
步骤1、时频块切分:
针对频谱x,使用频率方向长度f=16,时间方向长度t=1的滑动窗,按照频域轴步长frestrip=16,时间轴步长timestrip=1,将频谱x切分为一系列时频块集合xblock=[x′1,1,x′2,1,…,x′t,k,…];x′t,k为一个时频块,t表示时域,k表示频域;
步骤2、局部特征提取:
对每个时频块x′t,k进行如图2所示的局部特征提取操作:
首先,针对x′t,k进行卷积运算,提取当前时频块的局部频域特征ft,k
ft,k=x′t,k*wf
其中,wf为卷积核的第f个子卷积核矩阵;
然后,针对ft,k进行池化,消除频率偏移带来的影响:
pt,k=meanpooling(ft,k),
meanpooling表示平均池化;pt,k为池化操作后的ft,k;
接下来,将pt,k归一化到指定维度
xt,k=pt,k×wl+b,
xt,k为归一化到指定维度后的pt,k,wl为权值矩阵,b为归一化到指定维度操作对应的偏置量;
步骤3、全局时频模式建模:
针对步骤2中得到的局部特征xt,k进行全局时频模式建模:
分别在频域和时域使用两个独立的lstm进行建模,具体流程如下:
其中,s∈(t,k),角标t,k表示时域、频域对应的参数;u∈(i,f,c,o),角标i,f,c,o分别表示输入、遗忘、记忆单元和输出对应的参数;
具体实施方式二:
本实施方式所述的基于卷积网格长短时记忆递归神经网络的自动语音识别加速方法,包括以下步骤:
步骤1、时频块切分:
为了能够更好的利用cnn的并行处理能力,对输入频谱x进行多通道频谱子带x′处理:频谱x多通道频谱子带x′为三通道频谱子带,通过多通道频谱子带切分过程实现:为了能够更好的利用cnn的并行处理能力,针对频谱x,将其沿频域轴方向切分成三个子带,且将三个子带之间的信息进行关联,将三个频域子带按照如图3所示的方法并排形成一个三通道的频域子带x′;
使用频率方向长度f=16,时间方向长度t=1的滑动窗,按照频域轴步长frestrip=16,时间轴步长timestrip=1,将其多通道频谱子带x′切分为一系列时频块集合xblock=[x′1,1,x′2,1,…,x′t,k,…];x′t,k为一个时频块,t表示时域,k表示频域;
步骤2、局部特征提取:
对每个时频块x′t,k进行如图4所示的局部特征提取操作:
首先,针对x′t,k进行卷积运算,提取当前时频块的局部频域特征ft,k
ft,k=x′t,k*wf
其中,wf为卷积核的第f个子卷积核矩阵;
然后,针对ft,k进行池化,消除频率偏移带来的影响:
pt,k=meanpooling(t,k),
meanpooling表示平均池化;pt,k为池化操作后的ft,k;
接下来,将pt,k归一化到指定维度
xt,k=pt,k×wl+b,
xt,k为归一化到指定维度后的pt,k,wl为权值矩阵,b为归一化到指定维度操作对应的偏置量;
步骤3、全局时频模式建模:
针对步骤2中得到的局部特征xt,k进行全局时频模式建模:
分别在频域和时域使用两个独立的lstm进行建模,具体流程如下:
其中,s∈(t,k),角标t,k表示时域、频域对应的参数;u∈(i,f,c,o),角标i,f,c,o分别表示输入、遗忘、记忆单元和输出对应的参数;
- 还没有人留言评论。精彩留言会获得点赞!