一种基于变分自编码器的多说话人语音合成方法与流程
[0001]
本发明涉及语音合成方法,特别涉及一种基于变分自编码器的多说话人语音合成方法。
背景技术:
[0002]
语音合成技术是将输入的文本转换为语音的重要技术,也是人机交互领域的一个重要研究内容。
[0003]
传统的语音合成算法需要录制单一说话人音素覆盖比较全面的音库来保证其可以合成各种文本的语音,但会引起录制成本高、效率低且只能合成单一说话人的语音的问题。而多说话人的语音合成支持不同说话人并行录制语音,且可以合成来自不同说话人的语音。传统的多说话人语音合成往往需要获得当前语音的说话人信息,并手动标注一个说话人标签,例如说话人的独热编码,属于一种有监督的学习,而这种方法在说话人数目很多的时候合成的语音往往有多个说话人的音色重叠。该方法引入一个变分自编码器网络,对该网络的输出进行采样获得说话人的标签。
技术实现要素:
[0004]
本发明的目的在于克服传统多说话人语音合成方法中存在的有监督学习、在说话人数量很多的时候合成的语音往往有多个说话人的音色重叠问题,通过引入一个变分自编码器网络,对该网络的输出进行采样获得说话人的标签,提出了一种基于变分自编码器的多说话人语音合成方法,该方法是一种无监督的学习说话人信息的方法。
[0005]
为实现上述目的,本发明提出了一种基于变分自编码器的多说话人语音合成方法,所述方法包括:
[0006]
提取一条待合成说话人干净语音的音素级别时长参数和帧级别声学参数并进行归一化,将归一化的音素级别时长参数输入第一变分自编码器,输出时长说话人标签;将归一化的帧级别声学参数输入第二变分自编码器,输出声学说话人标签;
[0007]
对待合成的包含多个说话人的语音信号提取帧级别语言学特征和音素级别语言学特征并进行归一化;
[0008]
将时长说话人标签和归一化的音素级别语言学特征输入时长预测网络,输出当前音素的预测时长;
[0009]
通过当前音素的预测时长获得该音素的帧级别语言学特征,将其与声学说话人标签输入声学参数预测网络,输出归一化的预测语音的声学参数;
[0010]
将归一化的预测语音的声学参数输入声码器,输出合成语音信号。
[0011]
作为上述方法的一种改进,所述第一变分自编码器/第二变分自编码器包含5层一维卷积层、1层长短时记忆层和1层全连接层,其中卷积层的卷积核大小为5,步长为2,数量为128,全连接层输出为预测的高斯分布的标准差和均值,长短时记忆层包含128个神经元,每个神经元的激活函数使用的是修正线性单元,其表达式为:
[0012]
f(x)=max(0,x)
[0013]
所述第一变分自编码器/第二变分自编码器的输入为归一化的音素级别时长参数/归一化的帧级别声学参数,输出为高斯分布的均值与标准差,计算预测的编码后的分布与真实分布之间的相对熵为:
[0014][0015]
其中,n为高斯分布的维度,σ
n
和u
n
分别为变分自编码器预测的高斯分布的σ(x)和u(x)第n维的标准差和均值,为隐向量真实分布,p
θ
(z)为变分自编码器预测的隐向量分布,并假定真实分布为标准高斯分布;
[0016]
隐向量通过重采样来实现:
[0017]
z
n
=u(x)+σ(x)
·
ε
n
[0018]
其中,z
n
为隐向量,x为归一化的音素级别时长参数/归一化的帧级别声学参数,ε
n
~n(0,i),为标准高斯采样获得的向量,所述变分自编码器输出回传的梯度计算为:
[0019][0020]
其中,e
n
为n维全1向量;隐向量z
n
通过一个包含256个神经元全连接层转换为128维的说话人标签,所述第一变分自编码器/第二变分自编码器的输出为时长说话人标签/声学说话人标签。
[0021]
作为上述方法的一种改进,所述时长预测网络包括全连接层和一层双向长短时记忆层;
[0022]
所述全连接层的输入为时长说话人标签和归一化的音素级别语言学特征;所述双向长短时记忆层的输出为预测的当前音素的时长,损失函数loss
mse
为归一化的预测语音的时长参数与真实语音的时长参数的最小均方误差:
[0023][0024]
其中,d为真实语音的时长参数,为归一化的预测语音的时长参数;
[0025]
所述全连接层与双向长短时记忆层的神经元数均为256;所有神经元的激活函数使用的是修正线性单元,其表达式为:
[0026]
f(x)=max(0,x)。
[0027]
作为上述方法的一种改进,所述声学参数预测网络包含全连接层和三层双向长短时记忆层;
[0028]
所述全连接层的输入为声学说话人标签和归一化的帧级别语言学特征;所述三层双向长短时记忆层的输出为归一化的预测语音的声学参数,损失函数loss
mse
为归一化的预测语音的声学参数与真实语音的声学参数的最小均方误差:
[0029]
[0030]
其中,x
j
为真实语音的声学参数的第j维的值,为归一化的预测语音的声学参数的第j维的值;
[0031]
所述连接层与双向长短时记忆层的神经元数均为256;所有神经元的激活函数使用的是修正线性单元,其表达式为:
[0032]
f(x)=max(0,x)。
[0033]
作为上述方法的一种改进,所述方法之前还包括:对已录制的包含多个说话人的语音信号提取帧级别声学参数、音素级别时长参数、帧级别语言学特征和音素级别语言学特征,并分别对其做归一化;
[0034]
所述帧级别声学参数包括:60维梅尔倒谱系数及其一阶和二阶差分、1维基频参数及其一阶和二阶差分、1维非周期参数及其一阶和二阶差分、1维元音辅音判决参数;
[0035]
所述音素级别时长参数包括1维的时长信息;
[0036]
所述帧级别语言学特征包含624维音素级别的语言学特征和4维的帧位置信息;所述音素级别语言学特征包括:477维的文本发音特征、177维的分词及韵律特征;
[0037]
所述帧级别声学参数和音素级别时长参数采用0均值归一化;所述帧级别语言学特征和音素级别语言学特征采用最大最小值归一化。
[0038]
作为上述方法的一种改进,所述方法之前还包括:对所述第一变分自编码器和时长参数预测网络进行训练的步骤,具体包括:
[0039]
将归一化的音素级别时长参数输入第一变分自编码器,计算所述变分自编码器的损失函数输出时长说话人标签;
[0040]
将归一化的音素级别语言学特征和时长说话人标签输入所述时长参数预测网络计算损失函数loss
mse
;
[0041]
对所述第一变分自编码器的损失函数及时长参数预测网络的损失函数加权求和得到的优化函数c1:
[0042][0043]
其中,ω(n)为编码器的损失函数的权重:
[0044][0045]
n为整个训练数据迭代次数;
[0046]
通过减小优化函数c1的值进行梯度回传并更新网络的参数,得到训练好的第一变分自编码器和时长参数预测网络。
[0047]
作为上述方法的一种改进,所述方法之前还包括:对所述第二变分自编码器和声学参数预测网络进行训练的步骤,包括:
[0048]
将归一化的帧级别声学参数输入第二变分自编码器,计算所述第二变分自编码器的损失函数输出声学说话人标签;
[0049]
将声学说话人标签和归一化的帧级别语言学特征输入所述声学参数预测网络计算损失函数loss
mse
;
[0050]
对所述第二变分自编码器的损失函数及声学参数预测网络的损失函数加权求和得到的优化函数c2:
[0051]
[0052]
其中,ω(n)为编码器的损失函数的权重:
[0053][0054]
n为整个训练数据迭代次数;
[0055]
通过减小优化函数c2的值进行梯度回传并更新网络的参数,得到训练好的第二变分自编码器和声学参数预测网络。
[0056]
作为上述方法的一种改进,所述提取一条待合成说话人干净语音的音素级别时长参数和帧级别声学参数并进行归一化,具体包括:
[0057]
提取一条待合成说话人干净语音的音素级别时长参数,所述音素级别时长参数包括1维的时长信息;
[0058]
提取一条待合成说话人干净语音的帧级别声学参数;所述帧级别声学参数包括:60维梅尔倒谱系数及其一阶和二阶差分、1维基频参数及其一阶和二阶差分、1维非周期参数及其一阶和二阶差分、1维元音辅音判决参数;
[0059]
所述帧级别声学参数和音素级别时长参数采用0均值归一化。
[0060]
作为上述方法的一种改进,所述对待合成的包含多个说话人的语音信号提取帧级别语言学特征和音素级别语言学特征并进行归一化;具体包括:
[0061]
对待合成的包含多个说话人的语音信号提取帧级别语言学特征,所述帧级别语言学特征包含624维音素级别的语言学特征和4维的帧位置信息;
[0062]
对待合成的包含多个说话人的语音信号提取音素级别语言学特征,所述音素级别语言学特征包括:477维的文本发音特征、177维的分词及韵律特征;
[0063]
所述帧级别语言学特征和音素级别语言学特征采用最大最小值归一化。
[0064]
作为上述方法的一种改进,所述通过预测时长获得该音素的帧级别语言学特征,具体包括:通过预测时长获得当前帧相对于预测的时长的相对位置和绝对位置,从而获得该音素的帧级别语言学特征。
[0065]
本发明的优点在于:
[0066]
本发明通过变分自编码器无监督的学习说话人的标签信息,通过选取来自不同说话人语音来获得不同的隐向量分布,对隐向量采样获得说话人标签来来合成不同说话人的语音。
附图说明
[0067]
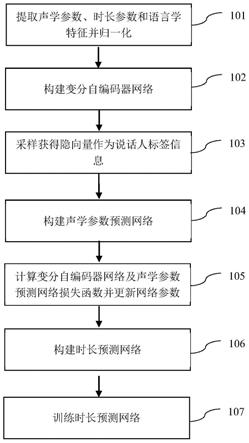
图1为本发明的基于变分自编码器的多说话人语音合成方法的流程图;
[0068]
图2为本发明的变分自编码器和声学参数预测网络的结构图;
[0069]
图3为本发明的变分自编码器和时长参数预测网络的结构图。
具体实施方式
[0070]
下面结合附图对本发明的技术方案作进一步的描述。
[0071]
本发明提出了一种基于变分自编码器的多说话人语音合成方法,该方法包括训练阶段和合成阶段;
[0072]
如图1所示,训练阶段包括:
[0073]
步骤101)对已录制的包含多个说话人的语音信号提取帧级别的声学参数、音素级别的时长参数和帧级别、音素级别的语言学特征,并分别对其做归一化。
[0074]
所述的帧级别的声学参数共187维,包括:60维梅尔倒谱系数及其一阶和二阶差分、1维基频参数及其一阶和二阶差分、1维非周期参数及其一阶和二阶差分、1维元音辅音判决参数。对所述的音素级别的语言学特征共624维,包括:477维的文本发音特征、177维的分词及韵律特征。所述的帧级别的语言学特征包含624维音素级别的语言学特征和4维的帧位置信息。对所述的时长参数包括1维的时长信息。
[0075]
其中,帧级别、音素级别的语言学特征采用最大最小值归一化,计算公式为:
[0076][0077]
其中为第i维特征归一化后的值,为为第i维特征归一化前的值,min
i
和max
i
分别为第i维特征的最大和最小值。
[0078]
声学参数和时长参数采用0均值归一化,计算公式为:
[0079][0080]
其中为第i维特征归一化后的值,为为第i维特征归一化前的值,u
i
和σ
i
分别为第i维特征的均值和方差。
[0081]
步骤102)构建变分自编码器网络,以归一化的帧级别声学参数作为输入,假定编码后的分布为高斯分布,网络的输出为高斯分布的均值与标准差,计算其与真实分布之间的相对熵,以此作为编码器的损失函数。
[0082]
编码器包含5层一维卷积层,以及1层长短时记忆网络(lstm层)和1层全连接层,其中卷积层的卷积核大小为5,步长为2,数量为128,全连接层输出为编码器预测的高斯分布的标准差和均值,lstm层包含128个神经元,每个神经元的激活函数使用的是修正线性单元,其表达式为:
[0083]
f(x)=max(0,x)
[0084]
计算预测的编码后的分布与真实分布之间的相对熵为:
[0085][0086]
其中,n为高斯分布的维度,σ
n
和u
n
分别为变分自编码器预测的高斯分布的σ(x)和u(x)第n维的标准差和均值,为隐向量真实分布,p
θ
(z)为变分自编码器预测的隐向量分布,并假定真实分布为标准高斯分布;以相对熵作为编码器的损失函数:
[0087][0088]
步骤103)基于步骤102)的分布采样获得隐向量作为声学说话人标签;
[0089]
为避免直接采样导致的梯度无法回传问题,隐向量通过重采样来实现,重采样的公式为:
[0090]
z
n
=u(x)+σ(x)
·
ε
n
[0091]
其中,n为高斯分布的维度,z
n
为隐向量,x为输入的归一化的帧级别声学参数,ε
n
~n(0,i),为标准高斯采样获得的向量,此时对于编码器输出回传的梯度可计算为:
[0092][0093]
其中e
n
为n维全1向量;
[0094]
隐向量z
n
通过一个包含256个神经元全连接层转换为128维的声学说话人标签。
[0095]
步骤104)构建声学参数预测网络,以归一化的帧级别语言学特征和声学说话人标签作为输入,网络的输出为预测的归一化的预测语音的声学参数,并计算其与真实的声学参数的最小均方误差,以此作为该网络的损失函数。
[0096]
如图2所示,所述声学参数预测网络包含全连接层和三层双向长短时记忆层;
[0097]
所述全连接层的输入为声学说话人标签和归一化的帧级别语言学特征;所述三层双向长短时记忆层的输出为归一化的预测语音的声学参数,损失函数loss
mse
为归一化的预测语音的声学参数与真实语音的声学参数的最小均方误差:
[0098][0099]
其中,x
j
为真实语音的声学参数的第j维的值,为归一化的预测语音的声学参数的第j维的值;
[0100]
所述连接层与双向长短时记忆层的神经元数均为256;所有神经元的激活函数使用的是修正线性单元,其表达式为:
[0101]
f(x)=max(0,x)。
[0102]
步骤105)对步骤102)中的变分自编码器的损失函数及步骤104)中的声学参数预测网络的损失函数加权求和作为优化函数,通过减小优化函数的值进行梯度回传并更新网络的参数,得到训练好的网络;
[0103]
对编码器的损失函数及声学参数预测网络的损失函数加权求和得到的优化函数计算为:
[0104][0105]
其中ω(n)为编码器的损失函数的权重关于整个训练数据迭代次数的表达式:
[0106][0107]
步骤106)搭建与步骤102)相同结构的变分自编码器网络,但以归一化的音素级别时长参数作为输入,输出为时长说话人标签,同时搭建时长预测网络,以时长说话人标签与音素级别语言学特征作为输入;输出为预测的时长参数;
[0108]
如图3所示,所述时长预测网络包括全连接层和一层双向长短时记忆层;
[0109]
所述全连接层的输入为时长说话人标签和归一化的音素级别语言学特征;所述双向长短时记忆层的输出为预测的当前音素的时长,损失函数loss
mse
为归一化的预测语音的时长参数与真实语音的时长参数的最小均方误差:
[0110][0111]
其中,d为真实语音的时长参数,为归一化的预测语音的时长参数;
[0112]
所述全连接层与双向长短时记忆层的神经元数均为256;所有神经元的激活函数使用的是修正线性单元,其表达式为:
[0113]
f(x)=max(0,x)。
[0114]
步骤107)对步骤106)的变分自编码器和时长参数预测网络进行训练;
[0115]
将归一化的音素级别时长参数输入变分自编码器,计算变分自编码器的损失函数输出时长说话人标签;
[0116]
将归一化的音素级别语言学特征和时长说话人标签输入时长参数预测网络计算损失函数loss
mse
;
[0117]
对变分自编码器的损失函数及时长参数预测网络的损失函数加权求和得到的优化函数c:
[0118][0119]
其中,ω(n)为编码器的损失函数的权重:
[0120][0121]
n为整个训练数据迭代次数;
[0122]
通过减小优化函数c2的值进行梯度回传并更新网络的参数,得到训练好的第二变分自编码器和声学参数预测网络。
[0123]
合成阶段包括:
[0124]
步骤201)提取一条待合成说话人干净语音的音素级别时长参数和帧级别声学参数并进行归一化,将归一化的音素级别时长参数输入步骤105)的变分自编码器,输出时长说话人标签;将归一化的帧级别声学参数输入步骤107)的变分自编码器,输出声学说话人标签;
[0125]
所述音素级别时长参数包括1维的时长信息;所述帧级别声学参数包括:60维梅尔倒谱系数及其一阶和二阶差分、1维基频参数及其一阶和二阶差分、1维非周期参数及其一阶和二阶差分、1维元音辅音判决参数;所述帧级别声学参数和音素级别时长参数采用0均值归一化。
[0126]
步骤202)对待合成的包含多个说话人的语音信号提取帧级别语言学特征和音素级别语言学特征并进行归一化;
[0127]
所述帧级别语言学特征包含624维音素级别的语言学特征和4维的帧位置信息;所述音素级别语言学特征包括:477维的文本发音特征、177维的分词及韵律特征;所述帧级别语言学特征和音素级别语言学特征采用最大最小值归一化。
[0128]
步骤203)将时长说话人标签和归一化的音素级别语言学特征输入步骤107)的时长预测网络,输出当前音素的预测时长;
[0129]
步骤204)通过当前音素的预测时长获得该音素的帧级别语言学特征,将其与声学说话人标签输入步骤105)的声学参数预测网络,输出归一化的预测语音的声学参数;
[0130]
通过预测时长获得当前帧相对于预测的时长的相对位置和绝对位置,从而获得该音素的帧级别语言学特征。
[0131]
步骤205)将归一化的预测语音的声学参数输入声码器,输出合成语音信号。
[0132]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1