音声识别装置、音声识别方法、存储音声识别程序的非暂时性计算机可读介质与流程
本发明涉及一种识别用户的发话音声的音声识别装置、一种音声识别方法以及一种存储音声识别程序的非暂时性计算机可读介质。
背景技术:
日本未审查专利申请公开第2013-019803号(jp2013-019803a)描述了一种声音对话装置,所述声音对话装置在开始音乐的输出或者维持音乐输出状态的同时,根据用户的发话音量的计算结果来调节音乐的音量,从而将用户的发话音量引导至期望的级别。
技术实现要素:
在使用音声识别装置的情况下,用户可能不期望诸如车辆的乘客的第三者听到发话内容。然而,在jp2013-019803a描述的声音对话装置中,因为音乐没有以妨碍第三者听到用户的发话内容的级别的音量再生,所以用户的发话内容有可能被第三者听到。
本发明提供一种音声识别装置、一种音声识别方法以及一种存储能够抑制第三者听到用户的发话内容的音声识别程序的非暂时性计算机可读介质。
本发明的第一方案涉及一种识别用户的发话音声的音声识别装置。所述音声识别装置包括控制器,所述控制器配置为:根据向所述用户要求的发话内容是否为不期望第三者听到的内容来控制任何干扰声的输出,并且响应于所述用户的发话的结束而停止所述干扰声的所述输出。
在根据本发明的第一方案的音声识别装置中,所述控制器可以被配置为:当在输出音乐时,将所述音乐的输出音量控制到干扰听到所述发话内容的级别。因此,能够抑制第三者听到用户的发话内容。
在根据本发明的第一方案的音声识别装置中,所述控制器可以被配置为:基于向所述用户要求所述发话的场景或情况以及来自所述用户的要求信号是否存在,来判定向所述用户要求的所述发话内容是否为不期望所述第三者听到的所述内容。因此,能够精确地判定向用户要求的发话内容是否为不期望第三者听到的内容。
在根据本发明的第一方案的音声识别装置中,所述控制器可以被配置为:从经由音声输入装置获取的音声数据去除所述干扰声,从而识别所述用户的发话音声。因此,即使在干扰声正在输出的状态下也能够精确地识别用户的发话音声。
本发明的第二方案涉及一种识别用户的发话音声的音声识别方法。所述音声识别方法包括:根据向所述用户要求的发话内容是否为不期望第三者听到的内容来控制任何干扰声的输出,并且响应于所述用户的发话的结束而停止所述干扰声的所述输出。
根据本发明的第二方案的音声识别方法还可以包括:判定向所述用户要求的所述发话内容是否为不期望所述第三者听到的所述内容,当所述发话内容为不期望所述第三者听到的所述内容时:当在输出音乐时,将所述音乐的输出音量控制到干扰听到所述发话内容的级别,以及当没有在输出所述音乐时则再生所述干扰声。
本发明的第三方案涉及一种非暂时性计算机可读介质,其存储使计算机实行识别用户的发话音声的处理的音声识别程序。所述处理包括:根据向所述用户要求的发话内容是否为不期望第三者听到的内容来控制任何干扰声的输出,并且响应于所述用户的发话的结束而停止所述干扰声的所述输出。
通过根据本发明的各个方案的音声识别装置、音声识别方法以及存储音声识别程序的非暂时性计算机可读介质,由于根据向用户要求的发话内容是否为不期望第三者听到的内容来控制任何干扰声的输出,所以能够抑制第三者听到用户的发话内容。
附图说明
将在下文中参照附图描述本发明的示例性实施例的特征、益处以及技术和工业方面的重要性,其中相同的附图标记表示相同的元件,并且其中:
图1为图示出根据本发明的一个实施例的音声识别装置的配置的框图;
图2a为图示出根据本发明的一个实施例的音声识别处理的流程的流程图;以及
图2b为图示出根据本发明的一个实施例的音声识别处理的流程的流程图。
具体实施方式
在下文中,将参照附图描述根据本发明的一个实施例的音声识别装置的配置和操作。
音声识别装置的配置
首先,将参照图1描述根据本发明的一个实施例的音声识别装置的配置。
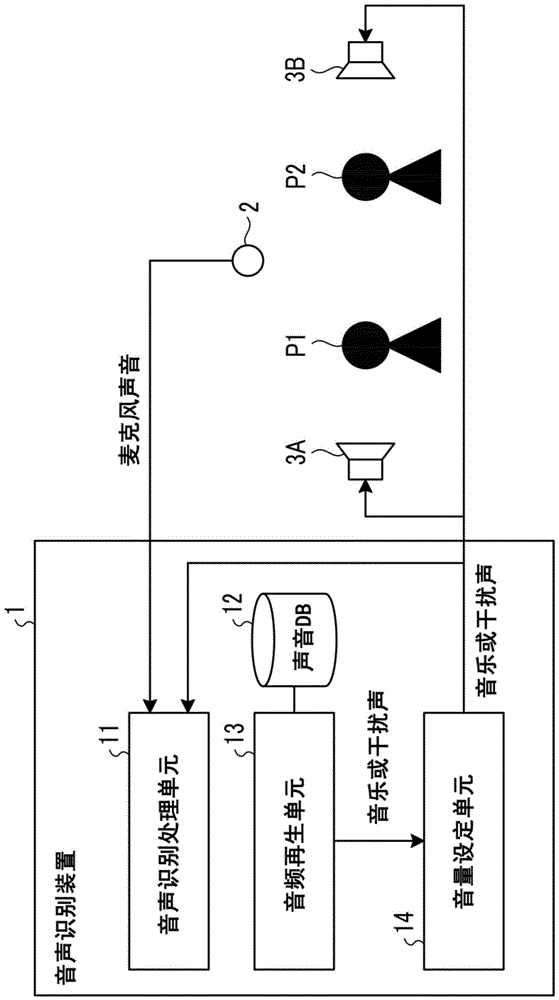
图1为图示出根据本发明的一个实施例的音声识别装置的配置的框图。如图1所示,根据本发明的一个实施例的音声识别装置1被配置为包括处理器和存储单元的、诸如工作站的通用信息处理装置,所述处理器诸如中央处理单元(cpu)、数字信号处理器(dsp)或者现场可编程门阵列(fpga),所述存储单元诸如随机存取存储器(ram)和只读存储器(rom),并且包括音声识别处理单元11、声音数据库(声音db)12、音频再生单元13以及音量设定单元14。音声识别处理单元11、音频再生单元13以及音量设定单元14的功能由执行存储在存储单元中的计算机程序的处理器实现。音声识别单元11、音频再生单元13以及音量设定单元14可以用作控制器。
音声识别处理单元11经由诸如麦克风的音声输入装置2获取用户p1的发话音声,并且识别获取的发话音声的内容。如将在下文中详细描述的,在本实施例中,音声识别处理单元11从经由音声输入装置2获取的音声(麦克风声音)数据去除音乐或干扰声的数据,并且使用去除处理之后的音声数据在再生音乐或干扰声的环境下识别用户p1的发话音声的内容。
声音db12存储音乐或者干扰声的数据。在此,干扰声的示例能够包括适于干扰听到用户p1的发话内容的专用音声(例如,没有令人不快并且没有无声状态的噪声音乐),以及用户所拥有的音乐。
音频再生单元13从声音db12获取音乐或者干扰声的数据,并且再生获取的数据并输出已经再生的获取的数据。
音量设定单元14调节由音频再生单元13再生的音乐或者干扰声的音量,并且从安装在用户p1附近的扬声器3a或者安装在第三者(例如,车辆的乘客)p2附近的扬声器3b输出音乐或干扰声。
上述计算机程序能够被记录在诸如cd-rom、软盘、可记录光盘(cd-r)以及数字多功能光盘(dvd)的计算机可读记录介质中,并且提供为可安装格式或者可执行格式的文件。而且,上述计算机程序可以被存储在连接至电气通信线路的计算机中,并且通过经由电气通信线路下载来提供。而且,上述计算机程序可以经由电气通信线路提供或分布。
具有这样的配置的音声识别装置1执行如下的音声识别处理,由此抑制第三者p2听到用户p1的发话内容。在下文中,将参照图2a和图2b描述执行音声识别处理时的音声识别装置1的操作。
音声识别处理
图2a和图2b为图示出根据本发明的一个实施例的音声识别处理的流程的流程图。每次音声识别装置1向用户p1要求发话,则开始图2a和图2b所示的流程图,并且音声识别处理进行到步骤s1的处理。
在步骤s1的处理中,音声识别处理单元11判定向用户p1要求的发话内容(要求用户p1提供的发话的内容)是否为不期望第三者p2听到的内容。具体地,音声识别处理单元11基于向用户p1要求发话的场景或状况(例如,在进行车辆中的全部乘客参与的智力游戏的状况下识别向用户p1要求不能被其他人听到的答案的情况)以及来自用户p1的要求信号是否存在,来判定向用户p1要求的发话内容是否为不期望第三者p2听到的内容。作为判定的结果,当向用户p1要求的发话内容为不期望第三者p2听到的内容时(步骤s1:是),音声识别处理单元11中的音声识别处理进行到步骤s2的处理。另一方面,当向用户p1要求的发话内容并非不期望第三者p2听到的内容时(步骤s1:否),音声识别处理单元11中的音声识别处理进行到步骤s5的处理。
应当注意到的是,不期望第三者p2听到的发话内容可以由音声识别处理单元11根据向用户p1要求发话(回答)的内容来提前定义。定义可以被划分为多个级别以指示内容不能被听到的程度,诸如要设定的目的地定义为级别1、姓名被定义为级别1、地址被定义为级别2、电话号码被定义为级别2、银行账号被定义为级别3并且智力游戏的答案被定义为级别3,或者可以被二值化定义(不可以被听到或者可以被听到)。当定义被划分为多个级别时,可以为每个用户p1设定阈值,该阈值指示在哪个级别以上的情况下不期望内容被听到。在该情况下,当使用户p1以超过阈值的级别的内容发话时,音声识别装置1执行听取发话内容和引导向第三者的干扰声的控制。而且,当不存在第三者p2时,音声识别装置1可以自动地判定阈值是无效的(设定为零)。不存在第三者p2的情况的示例能够包括就坐传感器判定驾驶座以外的座椅中没有乘客的情况,以及厢内摄像机没有检测到驾驶员以外的乘客的情况。
在步骤s2的处理中,音量设定单元14判定音频再生单元13是否在再生音乐。作为判定的结果,当音频再生单元13在再生音乐时(步骤s2:是),音量设定单元14中的音声识别处理进行到步骤s3的处理。另一方面,当音频再生单元13并非在再生音乐时(步骤s2:否),音量设定单元14中的音声识别处理进行到步骤s4的处理。
在步骤s3的处理中,音量设定单元14将从设置在第三者p2附近的扬声器3b输出的音乐的音量增加至第三者p2不能听到用户p1的发话音声的音量(继续音乐再生)。在该情况下应当注意到的是,可以增加用户p1和第三者p2所在的车厢等的全部空间的音量或者只在用户p1周围的音量。而且,不仅执行简单的音量调节,而且可以应用使用户p1的发话音声难以被听到的均衡器。因此,步骤s3的处理完成,并且音声识别处理进行到步骤s5的处理。
在步骤s4的处理中,音量设定单元14控制音频再生单元13,使得音频再生单元13再生存储在声音db12中的干扰声。音量设定单元14将从设置在第三者p2附近的扬声器3b输出的干扰声的音量控制到第三者p2不能听到用户p1的发话音声的音量。由此,完成步骤s4的处理,并且音声识别处理进行到步骤s5的处理。
在步骤s5的处理中,音声识别处理单元11执行音声识别,同时执行从经由音声输入装置2获得的音声数据中去除(消除)在再生的音乐或干扰声的去除处理,以等待用户p1发话。由此,完成步骤s5的处理,并且音声识别处理进行到步骤s6的处理。
在步骤s6的处理中,音声识别处理单元11基于音声识别结果判定是否存在用户p1的发话。作为判定的结果,当存在用户p1的发话时(步骤s6:是),音声识别处理单元11中的音声识别处理进行到步骤s7的处理。另一方面,当不存在用户p1的发话时(步骤s6:否),音声识别处理单元11使音声识别处理进行到步骤s8的处理。
在步骤s7的处理中,音声识别处理单元11对用户p1的发话内容执行音声识别。由此,完成步骤s7的处理,并且音声识别处理进行到步骤s8的处理。
在步骤s8的处理中,音声识别处理单元11基于用户p1的发话内容、来自用户p1的要求信号是否存在等,判定是否可以结束音声识别。作为判定的结果,当音声识别可以结束时(步骤s8:是),音声识别处理单元11中的音声识别处理进行到步骤s9的处理。另一方面,当音声识别处理单元11不可以结束音声识别时(步骤s8:否),音声识别处理单元11中的音声识别处理返回步骤s5的处理。
在步骤s9的处理中,音声识别处理单元11结束等待用户p1的发话的处理。由此,完成步骤s9的处理,并且音声识别处理进行到步骤s10的处理。
在步骤s10的处理中,音量设定单元14判定在等待用户p1的发话的处理开始之前音频再生单元13是否在再生音乐。作为判定的结果,当音频再生单元13在再生音乐时(步骤s10:是),音量设定单元14中的音声识别处理进行到步骤s11的处理。另一方面,当音频再生单元13没有再生音乐时(步骤s10:否),音量设定单元14中的音声识别处理进行到步骤s12的处理。
在步骤s11的处理中,音量设定单元14使音乐再生音量返回至音声识别处理开始之前的音量。由此,完成步骤s11的处理,并且一系列音声识别处理结束。
在步骤s12的处理中,音量设定单元14控制音频再生单元13以停止干扰声的再生。由此,完成步骤s12的处理,并且一系列音声识别处理结束。
如从以上描述中明白易懂的,在根据本发明的一个实施例的音声识别处理中,音声识别装置1根据向用户p1要求的发话内容是否为不期望第三者p2听到的内容来控制音乐或干扰声的输出,并且根据用户p1的发话的结束来结束干扰声的输出。因此,能够抑制第三者p2听到用户p1的发话内容。
而且,在根据本发明的一个实施例的音声识别处理中,当音声识别装置1在再生音乐时,音声识别装置1将音乐的音量控制到干扰听到用户p1的发话内容的级别。因此,能够抑制第三者p2听到用户p1的发话内容。
而且,在根据本发明的一个实施例的音声识别处理中,由于音声识别装置1基于向用户p1要求发话的场景或情况以及来自用户的要求信号是否存在来判定向用户p1要求的发话内容是否为不期望第三者p2听到的内容,能够精确地判定向用户p1要求的发话内容是否为不期望第三者p2听到的内容。
而且,在根据本发明的一个实施例的音声识别处理中,由于音声识别装置1通过从经由音声输入装置2获取的音声数据去除干扰声来识别用户p1的发话音声,所以即使在输出干扰声的状态下也能够精确地识别用户p1的发话音声。
虽然以上已经描述了应用了本发明人的发明的实施例,但本发明并不被形成根据本实施例的本发明的公开的一部分的描述和附图所限制。即,由本领域技术人员基于本实施例实现的其他实施例、示例、操作技术等全部包括在本发明的范围中。
- 还没有人留言评论。精彩留言会获得点赞!