基于BP神经网络的电除尘火花放电识别方法与流程
本发明涉及声音识别
技术领域:
,具体涉及一种基于bp神经网络的电除尘火花放电识别方法。
背景技术:
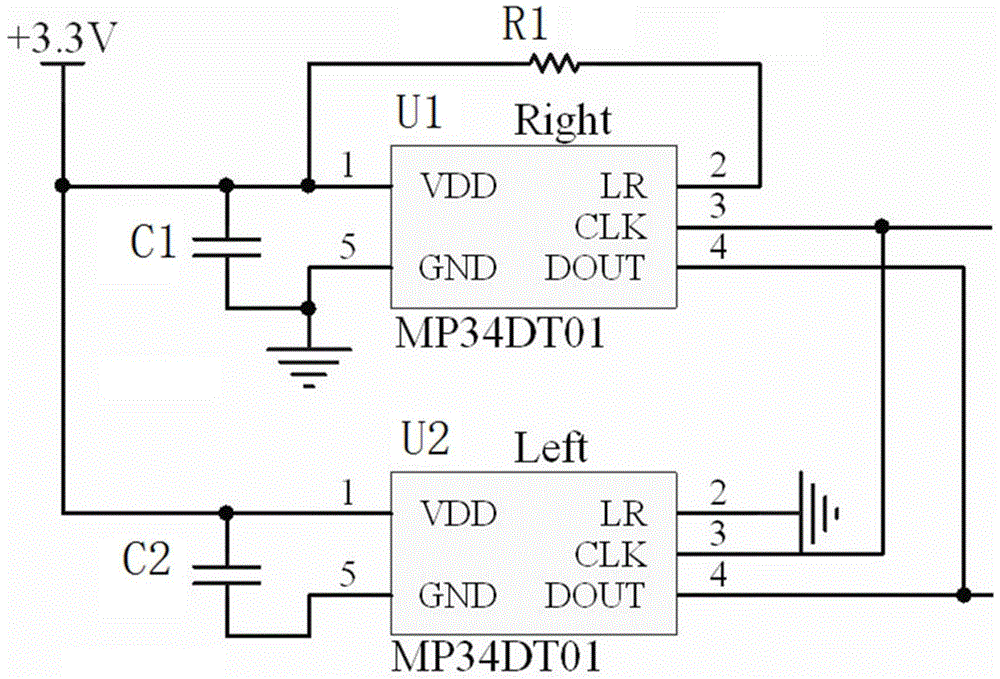
:目前,我国大气污染严重,已经严重影响人民的生活。相比布袋除尘、机械除尘等方法,静电除尘具有净化效率高、能耗低、处理废气量大等优势,应用最为广泛。实际工程中,为了获得更高的电压,往往都在直流高压的基础上叠加窄脉冲,但电压过高会在除尘本体里产生电场击穿,极板间近似短路,出现火花放电现象,有强烈的光亮并伴随着“啪啪”声。火花放电会导致电场电压瞬间下降,失去除尘效果,甚至可能会损坏设备。迫切需要一种能够检测火花放电的方案,以对除尘电源进行闭环反馈控制,减少火花放电次数。直接测量除尘电源的电压、电流的安全性差,图像识别法又会受到除尘本体遮挡视线的影响。技术实现要素:本发明所要解决的技术问题是针对上述现有技术的不足提供一种基于bp神经网络的电除尘火花放电识别方法,本基于bp神经网络的电除尘火花放电识别方法采用声音识别的方法,采集火花放电的声音信号,提取其时域特征和频域特征,并利用bp神经网络建立二分类模型来识别火花放电信号。为实现上述技术目的,本发明采取的技术方案为:基于bp神经网络的电除尘火花放电识别方法,包括以下步骤:步骤1:采集声音信号,得到pcm音频数据;步骤2:对音频数据进行预处理;步骤3:提取音频数据的mfcc、短时能量和短时过零率三种特征参数;步骤4:使用bp神经网络算法建立bp神经网络火花放电音频识别模型;步骤5:将采集多组的声音信号的三种特征参数作为声音样本,将声音样本的80%的样本作为训练集,剩余的20%的样本作为测试集;对bp神经网络火花放电音频识别模型进行训练和测试;步骤6:将采集的待识别声音信号进行三种特征参数的提取,将三种特征参数输入到已达到要求的bp神经网络火花放电音频识别模型中,完成电除尘火花放电声音的识别。作为本发明进一步改进的技术方案,所述的步骤1为:通过mp34dt01的数字mems麦克风采集声音信号,得到pdm格式音频数据,将pdm格式音频数据转换为pcm格式的音频数据。作为本发明进一步改进的技术方案,所述的步骤2为:对音频数据进行预处理,包括预加重、分帧和加窗处理。作为本发明进一步改进的技术方案,所述的步骤5中的声音样本包括火花放电声音样本和非火花放电声音样本;其中火花放电声音样本的采集方式为:采集多组火花放电声音信号,提取火花放电瞬间的两帧数据,将两帧数据的三种特征参数作为火花放电声音样本。作为本发明进一步改进的技术方案,所述mfcc为24维或36维。本发明的有益效果为:本发明采用声音识别的方法,采集火花放电的声音信号,提取其时域特征和频域特征,并利用bp神经网络建立二分类模型来识别火花放电信号,识别准确率高。附图说明图1为本发明实施例中声音采集电路结构示意图。图2为本发明实施例中pdm转pcm的流程图。图3为本发明实施例中火花放电声音的时域波形。图4为本发明实施例中强火花的短时能量的波形图。图5为本发明实施例中弱火花的短时能量的波形图。图6为本发明实施例中强火花的门限过零率的波形图。图7为本发明实施例中弱火花的门限过零率的波形图。图8为本发明实施例中mfcc特征提取流程图。图9为本发明实施例中bp神经网络的设计步骤流程图。具体实施方式下面根据图1至图9对本发明的具体实施方式作出进一步说明:本实施例提供一种基于bp神经网络的电除尘火花放电识别方法,包括以下步骤:步骤1:通过mp34dt01的数字mems麦克风采集声音信号,得到pdm格式音频数据,将pdm格式音频数据转换为pcm格式的音频数据。本实施例采用型号为mp34dt01的数字mems(micro-electro-mechanicalsystem)麦克风,内置的电容传感器能够检测声波,体积小、功耗低,信噪比达到63db,全向灵敏度-26dbfs,且内置滤波器,对电磁干扰具有很高的免疫力,适合工业场合。其2脚lr接地代表选择左声道,通过10k电阻r1上拉代表选择右声道,即u2为左声道,u1为右声道。3脚clk为时钟引脚,需要主设备为其提供时钟。4脚dout为数据输出引脚,输出为pdm(pulsedensitymodulation)格式音频数据,抗干扰能力强。mp34dt01的3脚和4脚均用于连接主设备,主设备将pdm格式音频数据转换为pcm格式的音频数据。本实施例选取内核为arm—m7的stm32f769作为主设备,该芯片拥有内部dfsdm(digitalfilterforsigmadeltamodulator),支持pdm转pcm(pulsecodemodulation)音频数据,流程如图2所示,本质是通过了一个∑-δ数字抽取滤波器。pcm数据的采样率fs的计算公式如下:其中,fclk是给pdm提供的时钟频率,本实施例设为3.072mhz,fosr和iosr分别是滤波器和积分器的过采样率,本实施例分别设为64和1,可得到fs为48khz。pcm数据的分辨率sr由滤波器类型、fosr、iosr和右移位数共同决定。本实施例选用sinc3滤波器,其分辨率计算公式如下:sr=(±fosr3*iosr)>>dig(2);其中,dig为右移位数,本文设为3,最终可得16位有效数据。数字麦克风输出的pdm数据流经过dfsdm的转换,最终得到48khz、16位的pcm音频数据。步骤2:对pcm的音频数据进行预处理,包括预加重、分帧和加窗处理。本实施例对声音进行分帧加窗处理,把信号分为每帧时长为20ms的数据,即在48khz采样率下为960个采样点。在分析短时能量和过零率时加矩形窗,分析线性预测倒谱系数和梅尔频率倒谱系数时加海明窗。本实施例使用matlab软件读取采集的pcm音频数据并绘制火花放电声音的时域波形如图3所示,火花发生瞬间幅值很高,但持续时间只有几毫秒,瞬间就降到较低幅值,然后经过大约180ms才慢慢衰减结束。步骤3:提取音频数据mfcc、短时能量、短时过零率等三种特征参数;短时能量是一个度量声音信号幅度变化的参数,它体现的是信号在不同时刻的强弱程度,其计算公式如下:采集的声音可以分成很多帧,其中n表示数据帧号,m表示n数据帧中的某一数据点。本实施例根据公式(3)计算得到火花放电短时能量,如图4和图5所示,由于只有火花产生瞬间的幅度强,只有两帧数据包含此时间段,因此这两帧的短时能量特别高,其它都很低。比较图4和图5,强火花放电比弱火花放电的短时能量峰值高。因此,短时能量可以作为衡量火花放电强度的一个主要参数。本实施例设定一个阈值,若短时能量小于该阈值,则把该帧视为静音帧,不再进行后续处理,减小运算压力,提高系统的实时性。短时过零率是一帧信号中时域波形穿过零电平横轴的次数,它体现的是声音的频率特性,其计算公式如下:其中,t为门限值,加门限是为了消除本底噪声产生的虚假过零。本实施例根据公式(4)计算得到火花放电短时过零率,如图6和图7所示,把门限t的值设为0.005,非火花放电时短时过零率基本为0,达到了滤波的作用。当产生火花放电时,短时过零率突然增加到150以上,并且会维持一小段时间,最后下降时则相对缓慢。比较图6和图7,强火花放电比弱火花放电的短时过零率峰值高且维持时间长。因此,短时过零率可以和短时能量一起使用,作为衡量火花放电强度的指标。梅尔频率倒谱系数(mfcc)是依据人类的听觉机理提出的、按照临界频带分布的声音特征,其提取流程如图8所示,先将线性频谱映射到mel非线性频谱中,然后转换到频谱上,具体步骤如下:(1)对预处理过的每帧信号x(n)进行离散傅里变化得到线性频谱,其公式如下:(2)求x(k)的功率谱,再将功率谱通过mel滤波器组hm(k),得到mel频谱。(3)对(2)输出的mel域频谱取对数,得到mel频率下的对数功率谱,其公式如下:(4)对(3)输出的对数功率谱s(m)进行离散余弦变换(dct),得到mel频率倒谱系数,其公式如下:其中,0≤n≤m,m为mel滤波器的总个数,通常在24~40之间。实际使用时,通常不用直流分量c(0),取第2个到第13个系数作为mfcc系数,即n取1~12。通过以上步骤得到的mfcc系数体现的是声音信号的静态特征,而火花放电信号变化快,还需要体现其动态特征。因此我们引入mfcc的一阶差分和二阶差分系数来表征火花放电信号的动态特征,其公式如下:其中,dn表示第n个一阶差分系数,k表示一阶倒数的时间差,一般取1或2,q表示倒谱系数的阶数。将上式的结果再代入一次就可以得到mfcc二阶差分系数。本实施例采用24阶mel滤波器,倒数时间差k取2,求得mfcc系数及其一阶、二阶差分系数共36维。mfcc前后帧的区别也很大,前面几帧的mfcc幅度变化大,而后面则较为平稳。步骤4:使用bp神经网络算法建立bp神经网络火花放电音频识别模型;bp神经网络是一种多层的前馈神经网络,利用误差反向传播算法不断更新权值和阈值,以达到最小均方误差。本实施例利用matlab软件建立bp神经网络火花放电音频识别模型,步骤如图9所示,本实施例建立3层神经网络,输入层节点数为选用特征向量维数,隐藏层节点数设为12,输出层节点数设为2,学习函数设为“trainbfg”,学习率设为0.0001,均方误差设为0.0001,最大训练次数设为100次。网络各层节点实现全连接,神经元的数学模型如下:其中,xj为神经元的输入信号,wij为神经元之间的连接权重,θi为神经元的阈值,f为传递函数,yi为该层的输出。隐藏层的传递函数为tansig(n)=2/(1+exp(-2*n))-1,输出层的传递函数为purelin(n)=n。步骤5:将采集多组的声音信号的三种特征参数作为声音样本,将声音样本的80%的样本作为训练集,剩余的20%的样本作为测试集;对bp神经网络火花放电音频识别模型进行训练和测试;步骤5中的声音样本包括火花放电声音样本和非火花放电声音样本;其中火花放电声音样本的采集方式为:采集多组火花放电声音信号,提取火花放电瞬间的两帧数据,将两帧数据的三种特征参数作为火花放电声音样本。本实施例实验中,提取音频信号的每一帧的特征值作为样本,共2513个样本,其中火花样本有1430个,非火花样本有1083个。在两类中各取80%的样本作为训练样本,剩余20%作为测试样本。网络输出[10]代表火花放电,[01]代表非火花放电,但实际网络输出不会正好是0或1。本实施例定义:神经网络输出为[ab]。根据实验经验,火花放电条件选取为a-b>0.7,可以提高火花识别的准确度,以防非火花放电被识别为火花放电。若a-b>0.7,则认为是火花放电,否则为非火花放电。步骤5:将采集的待识别声音信号进行三种特征参数的提取,将三种特征参数全部输入到已达到要求的bp神经网络火花放电音频识别模型中,完成电除尘火花放电声音的识别。本实施例首先选用不同的特征参数作为bp神经网络的输入,结果如表1所示,火花识别率为火花识别数与火花样本数的百分比,非火花识别率为非火花识别数与非火花样本数的百分比,在实际应用中,火花识别率更为重要。12维的mfcc只能体现声音信号的静态特征,故本实施例对12维的mfcc未做研究。表1中,非火花识别率几乎为百分之百,这是由于本实施例定义的界限偏向非火花放电,可减少误识别为火花放电的几率。24维的mfcc和36维的结果相差无几,且火花识别率都达到了0.95以上,mfcc结合短时能量(ste)和短时过零率(zcr)后,火花识别率都上升到了0.96以上。可见采用时域特征和频域特征结合的方法能提高识别率。表1:不同特征参数的识别率特征向量火花识别率非火花识别率mfcc(24)0.95101mfcc(36)0.95451mfcc(24)+ste+zcr0.96501mfcc(36)+ste+zcr0.96150.9954表1使用的样本是在实验环境下采集的,而实际环境下往往火花放电声音信号也会包含很多其他声音。本实施例为了测试识别系统的鲁棒性,把纯净的火花放电和非火花放电样本各自的20%改为混合样本,按照10db的衰减进行混合,结果如表2所示,相比使用纯净样本,火花识别率下降了百分之10以上,鲁棒性较差,而非火花识别率仍然很高。因此我们应该重点关注如何提高火花识别率,提高系统的鲁棒性。表2:混合样本的识别率为了提高火花放电的识别率,本实施例提出用火花放电产生瞬间的两帧数据来表征火花放电,这两帧数据能量高,不易受其他信号干扰,而其它帧能量较低,直接舍弃。样本经过改善后的识别率如表3所示,火花识别率提升了百分之10左右,火花识别率达到了百分之92以上,提高了系统的鲁棒性,效果很好。表3:改善后混合样本的识别率tab.3improvedrecognitionrateofmixedsamples特征向量火花识别率非火花识别率mfcc(24)+ste+zcr0.92861mfcc(36)+ste+zcr0.95241本实施例针对高电压除尘中产生的火花放电,提出了使用音频检测的方法,分析了火花放电音频的特征,发现火花放电瞬间有幅值高、频率快的特点,并提取短时能量、短时过零率和mfcc系数作为特征向量。本实施例还利用bp神经网络进行建模实验,对比了不同特征组合的识别率,研究结果如下:(1)24维和36维的mfcc效果较好且相差无几,考虑运算量的话,可以使用24维mfcc。(2)采用mfcc结合ste和zcr作为特征向量,比单独使用mfcc,识别率有明显提升。(3)把整段火花放电信号作为样本,bp神经网络的鲁棒性很低,而只把火花放电瞬间的两帧数据作为火花样本时,bp网络的抗干扰能力很强,可以很好地识别出包含其他声音的火花放电信号。综上所述,本实施例提出根据火花放电造成的声音进行火花识别,利用mems(micro-electro-mechanicalsystem)数字麦克风采集声音信号,分析了火花放电声音的短时能量、短时过零率、梅尔频率倒谱系数(mfcc)。建立bp神经网络识别系统,选用不同特征向量进行实验,研究结果表明:使用mfcc系数结合短时能量和短时过零率能提高识别率,对纯净样本的识别率高达96%,且用火花放电瞬间两帧数据作为火花样本进行bp神经网络训练能大幅度提高识别系统的鲁棒性,对非纯净样本的识别率高达95%。本发明的保护范围包括但不限于以上实施方式,本发明的保护范围以权利要求书为准,任何对本技术做出的本领域的技术人员容易想到的替换、变形、改进均落入本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1