基于二值多频带能量分布的低信噪比声音事件检测方法与流程
本发明属于声音事件检测(soundeventdetection,sed)领域,尤其涉及一种基于二值多频带能量分布的低信噪比声音事件检测方法。
背景技术:
声音事件检测(soundeventdetection,sed)是将一个短的声音片段的音频内容分配到一组预先训练类之一中的任务。近20年来,声音事件检测的研究一直是声学分析领域的研究热点。声音事件检测已应用于声学监测,生物声学监测,环境声音,情境感知辅助机器人,音乐流派分类和多媒体存档等领域。
当前,对于声音事件的分类与检测的研究,可以归纳为特征表示、基于深度学习的声音事件分类与检测、和多音声音事件检测等三个方面。关于特征表示,主要包括音频特征常规表示(r.grzeszick,a.plinge,andg.a.fink,“bag-of-featuresmethodsforacousticeventdetectionandclassification,”ieee/acmtrans.audio,speech,lang.process.,vol.25,no.6,pp.1242-1252,jun.2017)、深度神经网络提取的深度音频特征(y.li,x.zhang,h.jin,x.li,q.wang,q.he,andq.huang,“usingmulti-streamhierarchicaldeepneuralnetworktoextractdeepaudiofeatureforacousticeventdetection,”multimedtoolsappl.,vol.77,pp.897–916,2018)、左奇异矢量提取的声谱图特征(manjunath.mands.g.koolagudi,“segmentationandcharacterizationofacousticeventspectrogramsusingsingularvaluedecomposition,”expertsystemsappl.,vol.120,pp.413-425,2019)、非线性时间归一化表示(i.m.morato,m.cobos,andf.j.ferri,“adaptivemid-termrepresentationsforrobustaudioeventclassification,”ieee/acmtrans.audio,speech,lang.process.,vol.26,no.12,pp.2381-2392,dec.2018)等。关于深度学习的声音事件检测,包括基于深度学习的声音事件分类与检测(x.xia,r.togneri,f.sohel,andd.huang,“auxiliaryclassifiergenerativeadversarialnetworkwithsoftlabelsinimbalancedacousticeventdetection,”ieeetrans.multimedia,vol.21,no.6,pp.1359-1371,jun.2019),大规模音频标注(q.kong,y.xu,w.wang,andm.d.plumbley,“audiosetclassificationwithattentionmodel:aprobabilisticperspective,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2018,pp.316-320)、异常声音事件检测(y.koizumi,s.saito,h.uematsu,y.kawachi,andn.harada,“unsuperviseddetectionofanomaloussoundbasedondeeplearningandtheneyman–pearsonlemma,”ieee/acmtrans.audio,speech,lang.process.,vol.27,no.1,pp.212-224,jan.2019)、弱标记声音事件检测(b.mcfee,j.salamon,andj.p.bello,“adaptivepoolingoperatorsforweaklylabeledsoundeventdetection,”ieee/acmtrans.audio,speech,lang.process.,vol.26,no.11,pp.2180-2193,nov.2018;q.kong,y.xu,i.sobieraj,w.wang,andm.d.plumbley,“soundeventdetectionandtime-frequencysegmentationfromweaklylabelleddata,”ieee/acmtrans.audio,speech,lang.process.,vol.27,no.4,pp.777-778,apr.2019)等。关于多音声音事件检测,则主要包括用于多音声音事件检测的卷积神经网络(e.cakir,g.parascandolo,t.heittola,h.huttunen,t.virtanen,convolutionalrecurrentneuralnetworksforpolyphonicsoundeventdetection,”ieee/acmtrans.audio,speech,lang.process.,vol.25,no.6,pp.1291-1303,jun.2017)、利用线性动力系统的复音事件跟踪(e.benetos,g.lafay,m.lagrange,andm.d.plumbley,“polyphonicsoundeventtrackingusinglineardynamicalsystems,”ieee/acmtrans.audio,speech,lang.process.,vol.25,no.6,pp.1266-1267,jun.2017)和基于谱图的多任务音频分类(y.zeng,h.mao,hua;andd.peng,“spectrogrambasedmulti-taskaudioclassification,”multimedtoolsappl.,vol.78,2019,pp3705–3722)。上述研究表明,对于特定声音场景,如果信噪比合适,可以一定程度地分类与检测出相关的声音事件。
然而,在许多这样的应用中,声音事件发生在各种各样的具有挑战性的噪声条件下,并且信噪比(signal-to-noiseratio,snr)甚至可能接近-10分贝(z.feng,q.zhou,j.zhang,andp.jiang,“atargetguidedsubbandfilterforacousticeventdetectioninnoisyenvironmentsusingwaveletpackets,”ieeetrans.audio,speech,lang.process.,vol.23,no.2,pp361-372,feb.2015)。低信噪比声音事件检测的目标是检测与识别复杂声环境下的微弱声音事件。现实中,对于低信噪比复杂声场景下的声音事件检测,依然还是一项挑战性的问题。
在低信噪比及复杂声场景下,噪声包含不同的和非平稳的背景声。它们通常会降低分类与检测的性能。此外,多项研究(j.dennis,h.d.tran,ande.s.chng,“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification,”ieeetrans.audio,speech,lang.process.,vol.21,no.2,pp367-377,feb.2013;j.dennis,h.d.tran,andh.li,“spectrogramimagefeatureforsoundeventclassificationinmismatchedconditions,”ieeesignalprocess.lett.,vol.18,no.2,pp.130-133,feb.2011)表明,不同于结构化信号,环境音频可能包含较强的时间特征或宽的平谱。这种现象可能使传统采用的mfcc(f.zheng,g.zhang,andz.song,“comparisonofdifferentimplementationsofmfcc,”journalofcomputerscienceandtechnology,vol.16,no.6,pp.582-589,2001)、pncc(c.kimandr.m.stern,“featureextractionforrobustspeechrecognitionbasedonmaximizingthesharpnessofthepowerdistributionandonpowerflooring,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2010,pp.4574-4577)、lbp(t.kobayashiandj.ye,“acousticfeatureextractionbystaticticsbasedlocalbinarypatternforenvironmentalsoundclassification,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2014,pp.3052-3056)和hog(a.rakotomamonjyandg.gasso,“histogramofgradientsoftime-frequencyrepresentationsforaudiosceneclassification,”ieeetrans.audio,speech,lang.process.,vol.23,no.1,pp142-153,jan.2015)等几种特征,现有的spd-knn、sif-svm、elbp-hog(s.abidin,r.tognerir,andf.sohel,“enhancedlbptexturefeaturesfromtimefrequencyrepresentationsforacousticsceneclassification,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2017,pp.626-630)和mp-svm(j.wang,c.lin,andb.chen,“gabor-basednonuniformscale-frequencymapforenvironmentalsoundclassificationinhomeautomation[j].ieeetrans.autom.sci.eng.,vol.11,no.2,pp.607-613,apr.2014)等方法,不适用于低信噪比下的声音事件检测。此外,而基于深度学习的声音事件分类与检测,除了识别性能之外,还应该考虑现实生活应用程序的其他方面,比如使用精心录制的声音示例和系统的计算成本(s.sigtia,a.m.stark,s.krstulovi,andm.d.plumbley,“automaticenvironmentalsoundrecognition:performanceversuscomputationalcost,”ieee/acmtrans.audio,speech,lang.process.,vol.24,no.11,pp.2096–2107,nov.2016)。因此,如何为非结构化信号提供一种可行的特征提取及分类方法依然是人们关注的重点。
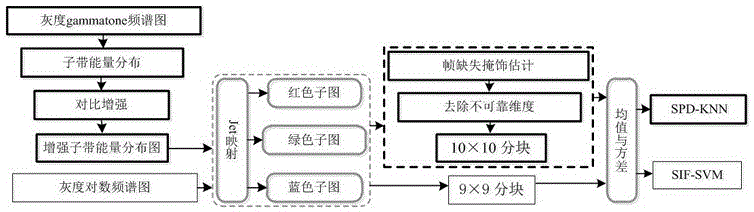
对于低信噪比声音事件,dennis等人在j.dennis,h.d.tran,ande.s.chng,“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification,”ieeetrans.audio,speech,lang.process.,vol.21,no.2,pp367-377,feb.2013和j.dennis,h.d.tran,andh.li,“spectrogramimagefeatureforsoundeventclassificationinmismatchedconditions,”ieeesignalprocess.lett.,vol.18,no.2,pp.130-133,feb.2011中,把spd图特征及谱图特征用于非匹配条件下声音事件分类。这两种方法分类检测声音事件的过程如说明书附图图1所示。其中,文献j.dennis,h.d.tran,andh.li,“spectrogramimagefeatureforsoundeventclassificationinmismatchedconditions,”ieeesignalprocess.lett.,vol.18,no.2,pp.130-133,feb.2011的过程如图1的下半部分的细线框所示,包括灰度对数频谱图、图像特征抽取,svm分类。采用这种方法,在0db的情况下,检测率达到79.4%。在该文献中,首先对图特征抽取是通过jet映射,把灰度对数谱图,映射成3张子图;然后,对每张子图进行9×9分块;再提取每一块均值与方差,得到486(2×3×9×9)维向量作为特征;最后用进行svm的训练与分类。
以文献“spectrogramimagefeatureforsoundeventclassificationinmismatchedconditions”的图像特征抽取方法为基础,如图1的上半部分的粗线框所示,文献“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification”在频谱、频谱分析及分类器的选择上进行了进一步的改进。其中,频谱及分析包括:灰度gammatone谱图、子带能量分布(spd)、对比增强形成增强的子带能量分布图。对图像特征的进一步处理包括:帧缺失掩饰估计,去除不可靠维度。然后再用基于hellinger距离的k近邻分类器(knn)分类。采用这种方法,在信噪比为0db情况下,对声音事件的检测率可以达到90.4%。在文献“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification”中,也是通过jet把子带能量分布图映射成3张子图;然后对每张子图进行10×10分块;再提取均值与方差,得到600(2×3×10×10)维向量作为特征;最后,对特征进行knn的建模与分类。
文献“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification”实现低信噪比声音事件分类的主要措施,是采用帧缺失掩饰估计与去除不可靠维度。最后,用保留的spd来表示相关声音事件的特征。
对spd进一步分析发现,对于更低信噪比的声音事件,如-5db或-10db采用文献“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification”的方法,可能存在问题。在更低信噪比的情况下,对增强的子带能量分布图,直接使用jet映射难以保证在每张子图中能尽量大地保留与声音事件相关的可靠区域。
jet映射的原理如说明书附图图2所示。横轴表示子带能量分布图的灰度值,范围是[0,1]。纵轴表示灰度值经jet映射后的值。其中,三张子图分别按图2中的rgb三条折线映射。子带能量分布图采用jet映射存在如下问题。
1)蓝色子图。在子带能量分布图中,灰度值为0的点,表示对应频带及对应能量等级的概率密度为0,即在该频带没有存在相应能量等级的能量。而按照jet的blue折线映射,该点在蓝色子图中被映射为0.5,相当于在蓝色子图中添加了额外的“噪声”。
2)红色子图。在子带能量分布图中,灰度值为1的点,表示对应频带及对应能量等级的概率密度大,与声音事件的低能量部分或背景噪声相关。在低信噪比环境下,声音事件的低能量部分受干扰大,易成为不可靠区域,而背景噪声部分更是需要进行抑制。按照jet映射的red折线映射,子带能量分布图为0.5的灰度值,被映射为0.5,而灰度值为1的点同样被映射为0.5,相当于在红色子图中增加了更多不可靠成分。
3)绿色子图。相对于blue折线和red折线,green折线映射不但没有引入额外的“噪声”,而且还在一定程度上抑制了原来的噪声。它的不足之处仅在于子带能量分布值只为[0.125,0.875]。
技术实现要素:
本发明提出了一种新的声音事件检测框架,利用二值多频带能量分布(binarymulti-bandpowerdistribution,bmbpd)和随机森林(rf)的独特组合来提供优良的性能。其中,bmbpd将mbpd图中灰度小于一定阈值的像素二值化为1,其余为0,能够在mbpd图中突出与声音事件相关的像素,同时抑制噪声的影响,从而减少低信噪比环境中噪声对待测声音事件的影响。通过对bmbpd图分块离散余弦变换(dct),把dct系数的z编码的主要部分作为声音事件的特征,即bmbpd-dctz,并用随机森林(rf)分类器对bmbpd-dctz进行训练与检测。
本发明具体采用以下技术方案:
一种基于二值多频带能量分布的低信噪比声音事件检测方法,其特征在于,包括以下步骤:
步骤s1:将声音信号y(t)通过gammatone滤波器组滤波,得到yf[t];对yf[t]取对数,形成相应的gammatone谱图sg(f,t);
步骤s2:对每个声音信号的能量谱
步骤s3:对g(f,t)的多频带能量分布情况进行统计,得到mbpd图m(f,b);
步骤s4:对mbpd图m(f,b)进行二值化处理得到bmbpd图mr(f,b);
步骤s5:对bmbpd图mr(f,b)进行分块,并对子块进行dct(离散余弦变换);
步骤s6:对dct系数进行zigzag扫描,获得dct系数的1维排列,取前m个dct系数作为bmbpd-dctz;
步骤s7:采用bmbpd-dctz作为特征,以rf(随机森林)作为分类器,对bmbpd-dctz进行分类和/或识别。
优选地,在步骤s1中,
sg(f,t)=lg|yf[t]|(1);
其中,f表示gammatone滤波器的中心频率,t表示帧索引;
在步骤s2中,
优选地,在步骤s3中,设g(f,t)共有b个能量等级,采用基于统计的非参数法,对每个频率子带f的能量元素进行概率密度统计,得到各个频率子带的各个能量等级的概率分布m(f,b):
其中,w为声音信号的帧数,m(f,b)表示在频带f中能量等级为b的元素占该频带元素总数的比例(0≤m(f,b)≤1);ib(g(f,t))为指示函数,当g(f,t)属于能量等级b时,其值为1,否则为0;
在步骤s4中,
其中,阈值n的范围在[1,w]区间内。
优选地,在步骤s5中,对bmbpd图mr(f,b)进行8×8分块,对子块进行dct后,获得8×8的dct系数。
优选地,在步骤s6中,取64个1维zigzag排列的前5个系数作为bmbpd-dctz。
优选地,步骤s7对bmbpd-dctz进行识别具体包括以下步骤:
步骤s71:数据特征设置:将待测声音信号的bmbpd-dctz特征置于随机森林中所有nk棵决策树的根节点处;
步骤s72:决策树设置与决策:按照决策树的分类规则,由根节点依次向下传递直到到达某一叶节点,该叶节点对应的类标签便是这棵决策树对bmbpd-dctz特征所属类别所做的投票;
步骤s73:随机森林检测:随机森林的nk棵决策树对每一个待测声音信号的bmbpd-dctz特征的类别均进行投票;随机森林中nk棵决策树投票,其中票数最多的类标签便是最终确定的待测声音信号对应的类标。
优选地,所述bmbpd图为64能量等级×256频带。
本发明及其优选方案的最主要特征使用二值多频带能量分布来生成用于低信噪比声音事件检测的特征。与子带能量分布及jet映射的方案相比,二值化多频带能量分布提供了更好的分辨率控制,并且可以调优以更好地捕获低信噪比声音事件信息。然后对二值多频带能量分布图进行8*8分块并提取离散余弦变换的zigzag系数作为特征。最后将用随机森林对特征进行建模与检测。该方法在平稳噪声条件及非平稳噪声条件下的精度都明显优于常用的方法。尤其,在信噪比低于0db的情况下,本发明方法优势更加突出。基于本发明提供的mbpd、bmbpd和bmbpd-dctz等方法,在实际应用中,还可以把bmbpd图与深度学习技术相结合,进一步改善与提高低信噪比下的各种声音事件的检测率。
采用本发明提供的方案,在一系列具有挑战性的噪声条件下,对50类环境声音事件的数据库和11类办公室声音事件的dcase2016数据集进行了全面的实验。结果表明,该方法对声级适用范围广泛,在严重的非平稳噪声中具有较强的鲁棒性。
附图说明
下面结合附图和具体实施方式对本发明进一步详细的说明:
图1是现有技术中谱图特征用于非匹配条件的声音事件分类示意图;
图2是现有技术中jet映射规则(spd,mapping)示意图;
图3是本发明实施例低信噪比声音事件检测流程示意图;
图4是本发明实施例狐狸叫声的gammatone频谱图及mbpd示意图;
图5是本发明实施例bmbpd图的8×8分块示意图;
图6是本发明实施例bmbpd图的8×8分块当中黑框中的子块局部放大示意图;
图7是本发明实施例黑框中的子块的dct系数及zigzag扫描示意图;
图8是本发明实施例64个dct系数的zigzag排列以及排在前面的5个zigzag系数示意图;
图9是本发明实施例不同n值的检测率(precision,threshold)示意图;
图10是本发明实施例方法与现有其他方法的检测精度的比较(snr(db),precision(%))示意图;
图11是本发明实施例n=6和n=2时-10db风声、雨声环境下的平均检测结果示意图;
图12是本发明实施例狐狸叫声、雨声以及-10db雨声环境的狐狸叫声的gammatone频谱示意图(n=6和n=2的bmbpd.与图12(b)(c)相比,图12(h)(i)的绿框及红圈部分被一定程度的压缩)。
具体实施方式
为让本专利的特征和优点能更明显易懂,下文特举实施例,作详细说明如下:
如图3所示,本发明实施例提供的检测方法流程可以归纳为:按照灰度gammatone谱图、bmbpd图、8×8分块及dct、zigzag编码和rf分类器的顺序步骤检测声音事件。
具体地,在本实施例中,bmbpd通过统计信号中256个频带内的64个能量等级的概率密度,将声音数据转化为bmbpd图。其中,形成bmbpd图的步骤如下:
1)gammatone频谱图。声音信号y(t)通过gammatone滤波器组滤波,得到yf[t]。对yf[t]取对数,即对yf[t]进行动态压缩,形成相应的gammatone谱图sg(f,t)。图4(a)所示的是狐狸叫声对应的gammatone谱图。
sg(f,t)=lg|yf[t]|(1)
其中,f表示滤波器的中心频率,t表示的帧索引。
2)归一化能量谱。对每个声音信号的能量谱
如图4所示,提供了狐狸叫声的gammatone频谱图及mbpd的展示。
3)多频带能量分布。对g(f,t)的能量分布情况进行统计,得到m(f,b),即图4(b)所示的mbpd图。如果共有b个能量等级,那么采用基于统计的非参数法,对每个频率子带f的能量元素进行概率密度统计,可以得到各个频率子带的各个能量等级的概率分布m(f,b)。
其中,w为声音片段的帧数。对于本实施例声音样本而言,w=198,m(f,b)表示在频带f中能量等级为b的元素占该频带元素总数的比例(0≤m(f,b)≤1)。ib(g(f,t))为指示函数,当g(f,t)属于能量等级b时,其值为1,否则为0。
4)二值化。对m(f,b)进行二值化处理得到mr(f,b)。
其中,阈值n的范围在[1,w]区间内。经过二值化处理,可以把图4(b)的mpbd转化成图5所示的bmbpd图。
之后是生成离散余弦变换与二值多频带能量分布图的步骤:
对一幅图像进行离散余弦变换(dct),可以将图象的重要可视信息都集中到dct的少部分系数中(g.a.papakostas,d.e.koulouriotis,ande.g.karakasis,“efficient2-ddctcomputationfromanimagerepresentationpointofview,”london,uk,intchopen,pp.21-34,2009)。一般情况下,dct系数矩阵中,沿左上至右下的方向,dct系数大小是依次递减的。左上角的第一个系数,被称为dct的直流系数,是图像像素的均值。其它系数被称为交流(ac)系数。ac系数越靠近左上角,包含着越多的图像信息。利用图像dct的这些特性,对由mb(f,b)构成的bmbpd图进行分块,然后对子块进行dct。
受图像处理中8×8的子块编码具有较高的效率的启发,本实施例对64×256大小的bmbpd图进行8×8分块,即把图5所示的bmbpd图分为8×32=256个的8×8子块。其中,每个子块及其像素,都携带着声音信号在相应频带及能量等级的分布情况。如,图6对应的5中箭头所指的黑框子块,是bmbpd图中频带从129至136、能量等级从23至30的能量分布。对子块进行dct后,可以得到如图7所示的8×8的dct系数列表。
之后是进行zigzag扫描的步骤:
通过图7中箭头所示的zigzag扫描(j.a.layandl.guan,“imageretrievalbasedonenergyhistogramsofthelowfrequencydctcoefficients,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,1999,pp.3009-3012),可以得到图像信息的重要性排序。图7中的8×8的dct系数经过zigzag扫描,可以得到如图8(a)的64个dct系数的1维排列。这1维排列的64个dct系数对可视信息的重要程度,按从左到右顺序排列。在图像处理中,只要1维排列左边的一部分系数即可表征图像的主要信息。在本实施例中,采用1维排列左边的一部分系数表征8×8子块的主要信息,即声音信号特定频带的能量分布。通过综合实验分析,如图8(b)所示,取64个1维zigzag排列的前5个系数作为该8×8子块的特征。这个特征,即为bmbpd子块的dct系数经过zigzag扫描的特征,简称为bmbpd-dctz。
之后是采用随机森林分类器的步骤:
进行初步实验表明,采用bmbpd-dctz作为特征,svm、gmm和dnn作为分类器,在低信噪比及可用数据有限的情况下与rf比较没有性能优势。因此,采用rf对bmbpd-dctz进行分类。
随机森林(rf,l.breiman,“randomforests,”machinelearning,vol.45,no.1,pp.5-32,2001)是一种利用多个决策树分类器来对数据进行判别的集成分类器算法。随机森林检测声音事件的步骤为:(1)数据特征设置。将待测声音数据的bmbpd-dctz特征置于随机森林中所有nk棵决策树的根节点处。(2)决策树设置与决策。按照决策树的分类规则,由根节点依次向下传递直到到达某一叶节点。该叶节点对应的类标签便是这棵决策树对bmbpd-dctz特征所属类别所做的投票。(3)随机森林检测。随机森林的nk棵决策树均对每一个待测声音信号的bmbpd-dctz特征的类别进行了投票。统计森林中nk棵决策树投票,其中票数最多的类标签便是最终待测样本对应的类标。
本实施例利用以上提供的方案进行了具体的验证试验。
如表1所示,实验数据使用两个数据集,动物声音事件集和办公室声音事件集。其中,50种动物声音事件来自freesound声音数据库(f.font,g.roma,p.herrera,andx.serra,"characterizationofthefreesoundonlinecommunity,"inproc.3rdint.workshopcognitiveinf.process.,may2012,pp.1-6),包括不同鸟鸣声和哺乳动物叫声。每种声音事件有30个样本。11种办公室中常见的声音事件,来自dcase2016task2(a.mesaros,t.heittola,e.benetos,p.foster,m.lagrange,t.virtanen,andm.d.plumbley,“detectionandclassificationofacousticscenesandevents:outcomeofthedcase2016challenge,”ieeetrans.audio,speech,lang.process.,vol.26,no.2,pp379-393,feb.2018)。每一类声音事件共有20个样本。实验中,以50种动物声音事件为主,11种办公室声音事件作为进一步的辅助验证。实验用到的6种噪声环境可分为两类,即平稳噪声和非平稳噪声。平稳噪声为粉噪声(pink),非平稳噪声包括模拟真实场景声音的流水声、风声、公路声、海浪声和雨声。噪声样本与声音事件的格式为单声道“.wav”格式,采样率为44.1khz。
表1声音事件样本集
实验中,相关参数为:帧长为25ms,帧移为10ms,滤波器组数目为256,中心频率在50hz到fs/2之间。综合考虑本实施例实验样本和特征维度以及文献(l.breiman,“randomforests,”machinelearning,vol.45,no.1,pp.5-32,2001)的建议,对于随机森林分类器中决策树的个数,取k=800用于动物声音事件集和k=500用于办公室声音事件集。决策树中,非叶节点分裂时,预选特征成分的数量为m=11。为了验证本实施例方法的检测性能,进行4个实验。它们包括:1)二值多频带能量分布阈值选择;2)bmbpd-dctz特征与rf分类器相结合的性能检测;3)bmbpd-dctz特征与常用特征性能的比较;4)mbpd-dctz-rf与现有方法的比较。在评价上采用简单的分类精度,即tp/(tp+fp),其中,tp真阳性,fp是假阳性.实验中,通过与经典及现有方法在分类精度的比较,来说明本实施例方法的有效性。
以下是实验结果与分析:
1)bmbpd阈值n的选取。分别选取n=2,4,6,8,10,12,14,16,18,20进行实验。在-10db、-5db、0db和5db四种信噪比的六种噪声环境中,三次交叉验证下,随机森林的平均检测结果如图9所示。
从图9可以看出,阈值n的大小,对不同信噪比条件下的检测率,影响程度不同。对于较低信噪比条件,如-5db、0db和5db三种情况,n的影响不太明显。然而,对于极低信噪比条件,如-10db情况,随着n的增加,检测率先有所提高,然后持续下滑。其中,当n=6时,-10db情况下检测率达到最高。因此,在后面的实验中,选取n=6。
2)bmbpd-dctz与rf的有效性。为说明bmbpd-dctz与rf分类器结合的有效性,对动物声音事件集进行了交叉验证实验。在-10db、-5db、-0db和5db等四种不同信噪比,及流水、粉噪声、风声、海浪、公路和雨声等六种背景噪声条件下,三次交叉验证实验的平均检测结果如表2所示。由表2可知,不论在平稳噪声条件下,还是在非平稳噪声条件下,bmbpd-dctz特征都表现出了良好的性能。在-5db低信噪比时,达到90.2±2.1%的平均检测率。尤其,在信噪比低至-10db时,依然达到66.3±12.2%的平均检测率。
表2bmbpd-dctz特征的交叉验证结果(%)
3)bmbpd-dctz的优越性。为了进一步说明bmbpd-dctz特征表征低信噪比声音事件的性能,采用rf分类器进行bmbpd-dctz特征与mfcc(f.zheng,g.zhang,andz.song,“comparisonofdifferentimplementationsofmfcc,”journalofcomputerscienceandtechnology,vol.16,no.6,pp.582-589,2001)、pncc(c.kimandr.m.stern,“featureextractionforrobustspeechrecognitionbasedonmaximizingthesharpnessofthepowerdistributionandonpowerflooring,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2010,pp.4574-4577)、glcm-sdh(j.weiandy.li,“rapidbirdsoundrecognitionusinganti-noisetexturefeatures,”actaelectronicasinica,2015,43(1):185-190)、lbp(t.kobayashiandj.ye,“acousticfeatureextractionbystaticticsbasedlocalbinarypatternforenvironmentalsoundclassification,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2014,pp.3052-3056)、hog(a.rakotomamonjyandg.gasso,“histogramofgradientsoftime-frequencyrepresentationsforaudiosceneclassification,”ieeetrans.audio,speech,lang.process.,vol.23,no.1,pp142-153,jan.2015)等几种特征的比较。其中,mfcc特征采用256个滤波器的三角滤波器组,提取12维dct系数。用32阶的gammatone滤波器和12维的dct系数来提取pncc特征。
表3六种噪声环境下不同特征对动物声音事件的平均检测率(%)
表4不同特征对办公室声音事件的检测率(%)
在流水、粉噪声、风声、海浪、公路和雨声等六种背景噪声下,几种特征对动物声音事件的检测结果如表3所示。办公室声音事件的原声的检测结果,以及信噪比为5db、0db和-5db的粉噪声的检测结果,如表4所示。从表3和表4可知,采用bmbpd-dctz特征,明显优于常用特征。尤其,对-5db粉噪声的信噪比,办公室声音事件依然达到58.8±3.7%的平均检测率。
4)与常规方法的比较。为了进一步说明bmbpd-dctz特征表征低信噪比声音事件的性能,把本实施例方法与snet(a.t.yusufaytar,carlvondrick,anda.torralba,“soundnet:learningsoundrepresentationsfromunlabeledvideo.”2016.[来源:互联网].可用网址:https://github.com/cvondrick/soundnet)、mbpd(y.liandl.wu.“detectionofsoundeventunderlowsnrusingmulti-bandpowerdistribution,”journalofelectronics&informationtechnology,2018,40(12):2905-2912)、elbp-hog(s.abidin,r.tognerir,andf.sohel,“enhancedlbptexturefeaturesfromtimefrequencyrepresentationsforacousticsceneclassification,”inproc.ieeeint.conf.acoust.,speech,signalprocess.,2017,pp.626-630)、mp-svm(j.wang,c.lin,andb.chen,“gabor-basednonuniformscale-frequencymapforenvironmentalsoundclassificationinhomeautomation[j].ieeetrans.autom.sci.eng.,vol.11,no.2,pp.607-613,apr.2014)、sif-svm(j.dennis,h.d.tran,andh.li,“spectrogramimagefeatureforsoundeventclassificationinmismatchedconditions,”ieeesignalprocess.lett.,vol.18,no.2,pp.130-133,feb.2011.)和spd-knn(j.dennis,h.d.tran,ande.s.chng,“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification,”ieeetrans.audio,speech,lang.process.,vol.21,no.2,pp367-377,feb.2013)等进行比较。采用三折交叉验证的方式,表5是动物声音事件在六种噪声环境及四种不同信噪比下的平均检测精度。图10则是各个种噪声环境下对四种信噪比声音事件的检测精度。表6则是不同方法对办公室声音事件的检测精度。
表5不同方法对动物声音事件的检测精度(%)
表6不同方法对办公室声音事件的检测率(%)
需要注意的是,snet方法是一种当前最先进的基于深度学习的方法,该方法使用预先训练的soundnetcnn(snet)(y.aytar,c.vondrick,anda.torralba,“soundnet:learningsoundrepresentationsfromunlabeledvideo,”inproc.adv.neuralinf.process.syst.,2016,pp.892–900)内部层的输出作为特征。具体来说,使用作者建议的pool5层的特性,使用他们在(a.t.yusufaytar,carlvondrick,anda.torralba,“soundnet:learningsoundrepresentationsfromunlabeledvideo.”2016.[来源:互联网].可用网址:https://github.com/cvondrick/soundnet)中提供的代码。然而,从表5和图10可以看出,本实施例方法在低信噪比条件下的检测率都好于现有方法,尤其在极低信噪比的情况下优势更为显著。
同时,在表6中,对于办公室声音事件的原声,snet的检测精度最高。然而,对于0db,及更低信噪比的声音事件,本实施例方法则有明显的优势。尤其,在-5db的情况下,本实施例方法平均检测率为58±3.7%,优于snet的48±6.6%,也优于mbpd中的54.6±5.4%。说明本实施例方法对各种低信噪比声音事件,有较强的鲁棒性,对噪声带来的影响有一定的抑制能力。
在进一步的研究中,考虑不同环境影响低信噪比声音事件的检测率:
进一步观察图10,可以看出,对于-10db的声音事件,图10(c)的风声环境和图10(f)的雨声环境检测率比较低。其中,风声环境下的检测率为51.0±5.2%,略高于雨声环境下的50.0±4.3%。如图11(a)和图11(c)所示,进一步对风声环境和雨声环境具体检测情况进行分析。其中,图11(a)和图11(c)分别是风声环境和雨声环境下,本实施例方法对50类动物声音事件的检测率。图中,坐标为(x,y)的点的颜色值是属于x类的声音事件被检测为y类的数量。这里x与y值是表1中动物声音的顺序编号。进一步分析,发现如下变化。
1)不同n影响低信噪比声音事件检测率
为了分析n的变化可能对检测结果的影响,也分析了n=2时的情况。结果如图11(b)和图11(d)所示。通过图11,可以看出,n=6和n=2时,它们对声音事件的检测率是有区别的。其中,在风声环境下,n=2时的检测率为46.5±5.3%,低于n=6时的51.0±5.2%。而在雨声环境下,n=2时的检测率为54.5±4.7%,则高于n=6时的50.0±4.3%。
因此,对于不同的声音环境,如果采用适当的n值,可以进一步提高本实施例方法的检测率。
2)环境声影响低信噪比声音事件的检测率
通过图11,可以进一步发现,在风声环境下,声音事件的检测错误主要集中在被误检测为第4类和第7类。而在雨声环境下,声音事件的检测错误主要集中在被误检测为第4类、第10类和第16类。其中,当n=2时,风声环境下,被误检测为第4类和第7类的错误率分别为19.6%和14.8%,高于n=6时的9.9%和14.4%。而雨声环境下,当n=2时,被误识别为第4类、第10类和第16类的错误率分别为7.5%,18.1%和7.8%。雨声环境下,虽然总体与n=6时的9.1%,14.3%和9.3%情况相当,但不同的n值,影响着不同声音事件的检测率。
造成这种错误的原因是低信噪比声音事件的bmbpd类似于错误类别的声音事件的bmbpd。因此,如果能针对不同的环境,对低信噪比声音事件进行与环境声音相关的特定增强及适当地调整n的取值,将进一步改善与提高低信噪比声音事件的检测性能。
考虑bmbpd图与低信噪比:
图12给出狐狸叫声、雨声和雨声环境下-10db狐狸叫声的gammatone频谱图,以及这三种声音在n=6和n=2的bmbpd图。从图12可以看出,低信噪比时,声音事件的bmbpd图存在3种主要情况。
1)声音事件的大部分bmbpd被环境声覆盖。如图12(g),(h)和(i)的蓝线框部分所示,在-10db雨声环境中,声音事件的bmbpd大部分被雨声bmbpd所覆盖。
2)特定频带的高能部分得以保留。如图12中绿色长框及红圈部分,声音事件的bmbpd中,人类听觉系统赖以感知的特定频带依然存在。本实施例中,把文献(j.dennis,h.d.tran,ande.s.chng,“imagefeaturerepresentationofthesubbandpowerdistributionforrobustsoundeventclassification,”ieeetrans.audio,speech,lang.process.,vol.21,no.2,pp367-377,feb.2013)中提供方案的频带划分数从50增加到256,就是为了突出与增强这部分的存在。
3)声音事件高能及相关部分可能被压缩。低信噪比,意味着环境声的能量高。如图12的蓝线框、绿色长框及红圈部分所示,在环境声音高能部分高于声音事件的情况下,与声音事件相关的bmbpd的高度被压缩。但如图12(h)(i)所示,关键的绿色长框及红圈部分依然清晰。
4)n的取值影响关键部分的清晰度。如图12(h)(i)所示,当n=6与n=2时,bmbpd中声音事件与环境声的黑点所占的比率不同。声音事件的占比高,意味关键部分更突出。如,在雨声环境下,n=2时,图12(i)绿色框中的黑点在bmbpd中占比更高,更有利于声音事件的检测。
因此,在低信噪比环境下,图12(h)(i)中的绿框及红色圆圈部分是低信噪比声音事件检测的关键依据。在音频数据中,声音事件只要有不同于背景噪声的频带及能量存在,用本实施例方法,在bmbpd图中都可以体现出来。本实施例把mbpd划分成256个频带和对bmbpd图8×8分块。在实际应用中可以根据具体待测声音事件的音域变化做调整。如表5与表6所示,对于-10db的动物声音事件和-5db的办公室声音事件,由于非平稳环境声音的影响,本实施例方法的检测率不够理想。这种情况,可以通过对n值的调整,对特定的声音事件进行更细致的频带及能量等级划分,提取更有效的bmbpd-dctz来改善检测率。
本专利不局限于上述最佳实施方式,任何人在本专利的启示下都可以得出其它各种形式的基于二值多频带能量分布的低信噪比声音事件检测方法,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本专利的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!