一种利用深度学习模型对音频进行标注的方法与流程
本发明涉及语音识别技术领域,特别涉及一种利用深度学习模型对音频进行标注的方法。
背景技术:
在深度学习语音识别领域中,在进行训练前,需要足够充足的原始语料数据,并对语料数据中的关键字和无效语音进行标注。对关键字进行标注在语音识别、语音增强等语音信号处理系统中是重要的预处理流程。由于语料数据量的庞大,如果基于传统的语音标注手段,使得标注关键字的工作繁琐,并且耗费大量的人力和时间成本。同时,随着人工智能的快速发展,对语音识别带来了新的机遇和挑战,迫切需要一种能降低人力和时间成本的语音标注方法。
目前国内外的自动语音识别技术大多数都是依赖于大量的数据资源,而这些数据的资源都需要通过传统的手段对语音进行标注,在专利cn201811011859.7中,描述了一种针对低资源土家语的语言端到端的语音识别方法,该方法是通过卷积神经网络和bilstm提升设别率,该方法主要目的是提升语音识别的结果,即提升识别率,对于语音的识别,大多数是基于纯净语音,而对带有噪声的语音数据效果并不是很好。而本发明是结合深度神经网络和长短时记忆,并根据gammtone频率倒谱系数的语音特征,提升对关键字进行标注准确率,同时,针对带噪语音的关键字标注,可提高语音标注的准确率,降低人工标注所耗的人力和时间成本,具有重要的理论意义和应用价值。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种利用深度学习模型对音频进行标注的方法,具体是一种应用深度神经网络和长短时记忆单元对关键字标注的方法,可用于降低对大量语料进行标注时所造成的人力和时间成本。
为了达到上述的技术效果,本发明采取以下技术方案:
一种利用深度学习模型对音频进行标注的方法,包括以下步骤:
a.获取音频并对获取的音频进行语音预处理;
b.将经语音预处理的音频数据输入深度学习模型进行语音识别及语音标注,并根据语音标注对音频进行打标签;其中,所述深度学习模型包括深度神经网络和长短时记忆单元;
c.对深度学习模型输出的标签进行人工校对;
本发明的利用深度学习模型对音频进行标注的方法的大致工作流程为:先获取音频,并对音频进行相应的预处理,然后将预处理后的音频数据输入至深度学习模型,先由深度学习模型中具有自主学习功能的深度神经网络进行语音及非语音的初步识别及学习,深度神经网络根据学习结果不断更新判断标准,长短时记忆单元在参照深度学习模型的学习及判定结果对输入的音频数据进行实际判断,输出是否为语音,若是语音将进一步判别具体语音内容从而进行相应标注,并根据语音标注对音频进行打标签,最后由人工对标签结果进行校对,在上述过程中,只要将深度学习模型训练好,仅在最后的校正阶段需要人工处理,因此,可有效降低对大量语料进行标注时所造成的人力和时间成本。
进一步地,所述步骤a中具体是根据用户的音频使用需求获取音频,如包括以下需求场景:智慧家庭常使用的语音、语音的唤醒术语、用户提出的要求等,获取音频时可通过录音设备进行录音获取或通过公共网络爬取音频获取,且所述音频包括纯净语音的音频和带噪语音的音频。
进一步地,所述步骤a中对音频的预处理包括:将得到的音频数据分解成帧,并对语音特征向量进行提取,再将每一组的帧串联成语音帧序列。
进一步地,对语音特征向量进行提取时具体是根据gmmatone频率倒谱系数对语音特征向量进行提取,即使用gammatone滤波器得到64维的cochleagram,再对cochleagram进行离散余弦变换,并取前40维构成gammatone频率倒谱系数。
进一步地,所述步骤b具体为:
b1.将语音帧序列输入深度学习模型进行语音识别及语音标注;
b2.将语音的逐渐提取的语音特征向量与标注看作长度为n(n为正整数)的时间序列特征数据集,对时间序列特征数据集每次按固定的时间窗进行特征抽取,且时间窗按照步长移动;
b3.将抽取的某时刻的特征序列按时间顺序通过深度神经网络层与该时刻的长短时记忆网络进行计算并输出,并基于上下文信息的代价函数进行训练;
b4.将每个时刻的输出通过深度学习模型的预测层进行语音和非语音后验概率输出;
b5.输出音频帧序列即音频的关键字的标注,并基于所述音频帧序列的标注,为音频打标签。
进一步地,所述深度神经网络和长短时记忆单元的网络结构是由一个多层的深度神经网络加一层长短时记忆单元组成,且具体的该深度学习模型的输入是120维gfcc参数,是将当前帧和前后帧相邻俩帧合并的结果,该深度学习模型的输出层为2个神经元的softmax层,模型的代价计算是使用基于上下文信息的代价函数,该方法可以使在低信噪比的环境下也有很好的鲁棒性。
进一步地,所述步骤b3中进行计算时具体是深度神经网络层和长短时记忆单元分别通过反向传导和延时反向传导算法进行梯度计算,具体计算方式为现有技术,此处不再赘述,其中,网络参数更新使用批量训练与自适应梯度调整结合,所述步骤b4中进行后验概率输出时将具体输出每个音频帧序列的各标注的概率值,通过后验概率输出对应的概率值是现有技术,此处不再赘述。
进一步地,所述步骤b5中为音频打标签时具体是将步骤b4中得到的音频帧序列的标签中值最大的标签作为为音频的标注。
进一步地,所述深度神经网络一共有四层,各层的神经元数目依次为150、100、80、60;且每层都采用漏整流线性单元作为激活函数。
进一步地,所述长短时记忆单元层的神经元数位为30,采用tanh作为输出与记忆单元的激活函数。
本发明与现有技术相比,具有以下的有益效果:
本发明的利用深度学习模型对音频进行标注的方法,可以实现对原始语料的标注,将繁冗的人工听音、人工标注、人工校对工作转变为仅需人工校对,其他均由系统模型自动进行,能极大节约人力和时间成本,并且保障有效性。
附图说明
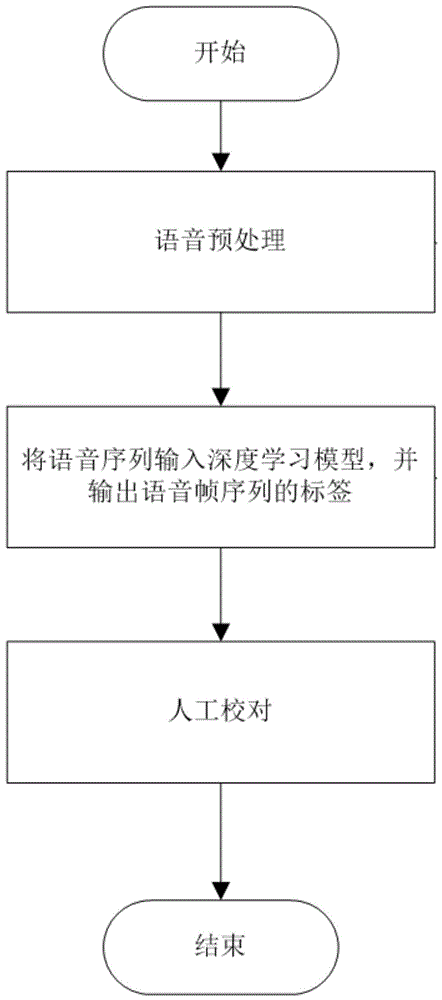
图1是本发明的利用深度学习模型对音频进行标注的方法的流程示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
实施例一:
一种利用深度学习模型对音频进行标注的方法,本发明的利用深度学习模型对音频进行标注的方法的大致工作流程为:先获取音频,并对音频进行相应的预处理,然后将预处理后的音频数据输入至深度学习模型,先由深度学习模型中具有自主学习功能的深度神经网络进行语音及非语音的初步识别及学习,深度神经网络根据学习结果不断更新判断标准,长短时记忆单元在参照深度学习模型的学习及判定结果对输入的音频数据进行实际判断,输出是否为语音,若是语音将进一步判别具体语音内容从而进行相应标注,并根据语音标注对音频进行打标签,最后由人工对标签结果进行校对,在上述过程中,只要将深度学习模型训练好,仅在最后的校正阶段需要人工处理,因此,可有效降低对大量语料进行标注时所造成的人力和时间成本。
如图1所示,本实施例的利用深度学习模型对音频进行标注的方法具体包括以下步骤:
步骤1.获取音频并对获取的音频进行语音预处理;包括:将得到的音频数据分解成帧,并对语音特征向量进行提取,再将每一组的帧串联成语音帧序列。
具体的,获取音频时需根据用户的音频使用需求获取音频,如包括以下需求场景:智慧家庭常使用的语音、语音的唤醒术语、用户提出的要求等。同时,获取音频时可通过录音设备进行录音获取或通过公共网络爬取音频获取,且所述音频包括纯净语音的音频和带噪语音的音频。
具体的,本实施例中,对语音特征向量进行提取时具体是根据gmmatone频率倒谱系数对语音特征向量进行提取,即使用gammatone滤波器得到64维的cochleagram,再对cochleagram进行离散余弦变换,并取前40维构成gammatone频率倒谱系数。
步骤2.将经语音预处理的音频数据输入深度学习模型进行语音识别及语音标注,并根据语音标注对音频进行打标签。
其中,所述深度学习模型包括深度神经网络和长短时记忆单元,网络事件展开长度为20语音特征向量序列,具体的,本实施例中,所述深度神经网络和长短时记忆单元的网络结构是由一个多层的深度神经网络加一层长短时记忆单元组成,且具体的该深度学习模型的输入是120维gfcc参数,是将当前帧和前后帧相邻俩帧合并的结果,该深度学习模型的输出层为2个神经元的softmax层,模型的代价计算是使用基于上下文信息的代价函数,该方法可以使在低信噪比的环境下也有很好的鲁棒性。
具体的,本实施例的所述深度神经网络一共有四层,各层的神经元数目依次为150、100、80、60;且每层都采用漏整流线性单元作为激活函数。长短时记忆单元层的神经元数位为30,采用tanh作为输出与记忆单元的激活函数。
本实施例中,步骤2具体包括:
步骤2.1.将语音帧序列输入深度学习模型进行语音识别及语音标注;
步骤2.2.将语音的逐渐提取的语音特征向量与标注看作长度为n的时间序列特征数据集,对时间序列特征数据集每次按固定的时间窗进行特征抽取,且时间窗按照步长移动;
其中,n为正整数,且深度学习模型的叠加帧的数目也是n,具体将帧号记为i,i大于等于1,并且小于等于n。
步骤2.3.将抽取的某时刻的特征序列按时间顺序通过深度神经网络层与该时刻的长短时记忆网络进行计算并输出,并基于上下文信息的代价函数进行训练;其中,进行计算时具体是深度神经网络层和长短时记忆单元分别通过反向传导和延时反向传导算法进行梯度计算,具体计算方式为现有技术,此处不再赘述,其中,网络参数更新使用批量训练与自适应梯度调整结合。
步骤2.4.将每个时刻的输出通过深度学习模型的预测层进行语音和非语音后验概率输出;具体的,进行后验概率输出时将具体输出每个音频帧序列的各标注的概率值,通过后验概率输出对应的概率值是现有技术,此处不再赘述。
步骤2.5.输出音频帧序列即音频的关键字的标注,并基于所述音频帧序列的标注,为音频打标签,具体是将步骤2.4中得到的音频帧序列的标签中值最大的标签作为为音频的标注。
步骤3.对深度学习模型输出的标签进行人工校对,即对模型所输出的音频的标注进行人工检阅,保证标注的准确性。
综上可知,本发明的利用深度学习模型对音频进行标注的方法,可以实现对原始语料的标注,将繁冗的人工听音、人工标注、人工校对工作转变为仅需人工校对,其他均由系统模型自动进行,能极大节约人力和时间成本,并且保障有效性。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!