一种基于辅助分类深度神经网络的主乐器识别方法与流程
本发明涉及深度学习、音乐信息检索技术,特别涉及针对复调音乐中的主乐器识别技术。
技术背景
由于数字格式的音乐文件越来越多,人们对音乐搜索的需求也越来越大。在音乐信息检索mir领域,人们往往希望知道音乐演奏使用的是什么乐器。如果能将乐器信息包含在音频标签中,人们就可以用他们关注的特定乐器类别搜索音乐。同时,乐器为描述音频内容提供了有效的手段。准确的乐器识别可以为许多与音乐信息相关的任务带来好处,例如,它可以用于定制特定的音频均衡和音乐推荐服务,还可用于提高mir其他任务的性能,例如,了解乐器的数量和类型可以显著提高声源分离、自动音乐转录和分类的性能。
复调音乐中多种乐器在一段音频中同时占主导地位时,人们可以很容易地识别出其中的乐器,然而对于计算机来说,从音质、演奏风格都有很大差异的复调音乐中识别出乐器并不是一件简单的事情。研究者们使用能够表征音色的特征,或者将多种类型的特征进行融合后输入分类器进行乐器识别,识别性能取决于输入特征对音色的表达能力以及分类器对特征的辨别能力,因此这两个方面是目前乐器识别问题中的研究重点。
技术实现要素:
本发明所要解决的技术问题是,提供一种通过乐器组的辅助分类训练来增强网络对乐器类别的主分类识别效果的方法。
本发明为解决上述技术问题所采用的技术方案是,一种基于辅助分类深度神经网络的主乐器识别方法,包括以下步骤:
1)数据预处理:
1-1)对各音频数据进行预处理与贴标签处理后形成数据集;标签包括各种乐器类型和人声;
1-2)将数据集中各音频数据分为训练集与测试集;
1-3)再对将训练集中各音频数据按起振类型进行辅助分类,起振类型包括硬起振组、软起振组和人声,对训练集中各音频数据进行辅助分类标签贴标;硬起振类型的乐器的起振点能量变化突然、强烈,软起振类型的乐器的起振点能量平稳;
2)数据特征提取:对数据集中的各音频数据进行音频特征提取,构造各音频数据的特征向量;
3)基于辅助分类的主乐器识别网络设置,包括4个卷积块,每个卷积块由一组卷积层-批归一化层-卷积层-批归一化层-池化层组成;卷积块依次连接,每个卷积块中卷积滤波器的数目分别为32、64、128和256,最后一个卷积块输出通过全局最大池化层和全连接层后输入至分类层,分类层包含两个用于2个分类任务的输出分支,一个分支为主分类的乐器类型分类,另一个分支为辅助分类的起振类型分类;设置网络训练时所使用的总损失函数loss为:loss=lpb+μlab+λlpc,其中lpb代表主分类的二分类交叉熵损失,lab代表辅助分类的二分类交叉熵损失,μ表示lab和lpb的比重参数,lpc代表主分类的中心损失,λ为lpc和lpb之间的比重参数;
4)训练步骤:将提取了特征向量的训练集输入至基于辅助分类的主乐器识别网络中完成网络训练;
5)测试步骤:将提取了特征向量的测试集输入至训练好的基于辅助分类的主乐器识别网络中,输出的主分类的分类结果为音频中主乐器识别结果。
本发明通过将乐器按照起振类型进行分组,在对具体乐器类别进行主分类的同时,对乐器组进行辅助分类,辅助分类能使得网络在训练过程中得到更优的参数。
本发明的有益效果是,在训练时按起振类型进行辅助分类,从反向传播角度来看,构建多任务学习网络结构,即使主分类中激活函数的梯度消失,辅助分类的梯度仍然存在,防止陷入局部最优,从而确保网络继续进行学习,帮助网络对乐器进行更精确的分类。另外,在网络设计损失函数时引入中心损失,减小类内间距,可更一步提升乐器识别效果。
附图说明
图1为实施例流程;
图2为1秒内10种乐器音乐信号能量变化;
图3为本发明的网络结构图;
图4为乐器侧识别效果;
图5为本发明与convnet识别结果对比。
具体实施方式
实施例使用irmas数据集。irmas数据集包含音乐音频摘录和音频主乐器的注释,音乐涵盖众多不同风格、演奏者、乐器类型等,同时录音片段跨度几十年,在音质上有很大差异。数据集分为训练和测试数据,所有音频文件为16位立体声,采样率为44100hz。涉及10种乐器及人声,分别为:大提琴(cel),单簧管(cla),长笛(flu),原声吉他(gac),电声吉他(gel),风琴(org),钢琴(pia),萨克斯(sax),小号(tru),小提琴(vio)及人声(voi)。
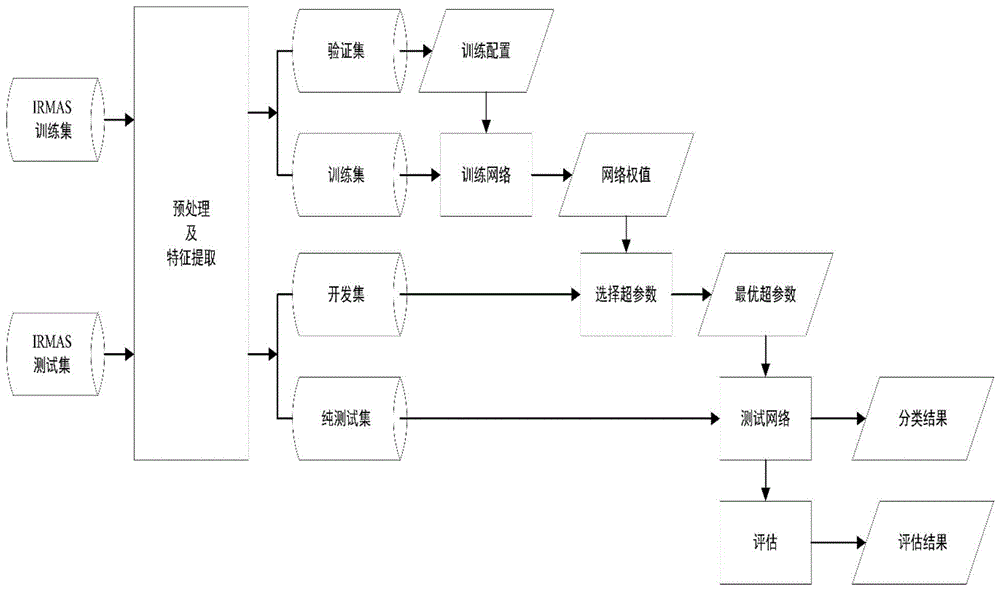
实施流程如图1所示:
1)数据预处理:
1-1)对原始的立体声音频做左右声道平均转换成单声道,将音频降采样至22050hz,11025hz的奈奎斯特频率足以覆盖乐器产生的大部分谐波同时过滤掉该频率以上的噪声。将音频按1秒帧长进行切割,每段分割使用相同的标签。完成预处理与贴标签处理后形成数据集;标签包括10种乐器类型和人声;
1-2)将数据集中各音频数据分为训练集与测试集;训练集进一步分为验证集与训练集,测试集进一步分为开发集与纯测试集;
1-3)再对将训练集中各音频数据按起振类型进行辅助分类,起振类型包括硬起振组、软起振组和人声,对训练集中各音频数据进行辅助分类标签贴标;硬起振类型的乐器的起振点能量变化突然、强烈,软起振类型的乐器的起振点能量平稳、软上升;起振点能量的显著变化使硬起振仪器的识别更加容易。我们从irmas数据集10种乐器的训练数据中随机选取爵士风格演奏音乐片段。音乐信号的能量变化如图2所示。(a)-(d)中大部分起振时刻均有显著峰值,(e)-(j)中平均起振强度相对较弱。这与起振类型吻合。
2)数据特征提取:对数据集中的各音频数据依次提取过零率、频谱质心、rms能量包络、谱滚降、mel频谱和mfcc,将这七种特征相连接,构造特征向量:
a、过零率:音乐信号波形的符号变化次数,是从信号直接计算得到的时域特征。该特征已广泛应用于语音识别和音乐信息检索领域:
其中n为帧内样本的个数,fn为第n个样本的振幅。sign()为符号函数。
b、频谱质心:表征声音信号频率和能量分布的重要信息,当频谱质心增大时,音乐的高频分量增多。通过计算频谱重心得到:
其中fk是第k个频率。k是频率盒的数量。p(fk)是第k个频率上的谱幅度值。
c、rms能量包络:音频帧随时间的能量分布,能够有效表征人耳听觉系统对音频信号强度变化的感知:
d、谱滚降:定义幅值下降至频谱总能量的pr%所对应的临界频率:
e、带宽:谱幅加权平均频率范围:
f、mel频谱:输入音频数据在mel-scale频率上的幅度谱图。melscale是一种基于人类听觉感知的非线性频率标度。将普通频率转换为mel-频率的公式如下:
g、mfcc:在自动语音识别中广泛使用的一种特征。在梅尔频率上得到的倒谱系数称为梅尔频率倒谱系数,简称为mfcc。
3)基于辅助分类的主乐器识别网络设置,如图3所示,包括4个卷积块,每个卷积块由一组卷积层-批归一化层-卷积层-批归一化层-池化层组成;其中,引入批归一化层,以保证在深度神经网络的训练过程中,每个卷积层的输出保持相同的分布。卷积块依次连接,每个卷积块中卷积滤波器的数目分别为32、64、128和256,最后一个卷积块输出通过全局最大池化层和全连接层后输入至分类层。在池化层和全连接层之后添加dropout层,防止训练过拟合。dropout率在每个最大值池化层之后设置为0.25,在全连接层之后设置为0.5。最后一层是分类层,使用sigmoid函数,分类层包含两个用于2个分类任务的输出分支,一个分支为主分类的乐器类型分类,另一个分支为辅助分类的起振类型分类;包含两个用于不同分类任务的输出分支。根据所采用的分组策略,主分类支包含11个神经元,辅助分类支包含3个神经元。
设置网络训练时所使用的总损失函数loss为:loss=lpb+μlab+λlpc,其中lpb代表主分类的二分类交叉熵损失,lab代表辅助分类的二分类交叉熵损失,μ表示lab和lpb的比重参数,lpc代表主分类的中心损失,λ为lpc和lpb之间的比重参数;λ和μ通过一系列实验选取最优值。
将中心损失引入主分类中以减小类内间距并增强特征的可辨别力。它被定义为:
其中,m是部分增量更新mini-batch的大小。xi是输入全连接层的特征,yi表示第i个特征的标签,
其中t为迭代次数。α为标量步长,可以帮助防止由离群值引起的中心振动。
其中,δ(·)为狄拉克函数。
4)训练步骤:将提取了特征向量的训练集输入至基于辅助分类的主乐器识别网络中完成网络训练;本实施例训练时使用adam作为优化器,使用glorot统一初始化函数进行网络权值初始化。学习率设置为0.001,mini-batch大小设置为64。如果验证集的评估参数在10个epoch后没有得到优化,则将学习率乘0.5,直到达到设置的学习率最小值5×10-5。在硬件上,使用1080ti的gpu和128gb的内存。训练集中15%的训练数据用作验证集。
5)测试步骤:将提取了特征向量的测试集输入至训练好的基于辅助分类的主乐器识别网络中,输出的主分类的分类结果为音频中主乐器识别结果。选用乐器识别任务中常用的评估参数,计算精度p、召回率r和f1测度f1来评估网络对乐器的识别性能。精度计算正确检索项与所有实际检索项的比例。召回率计算正确检索的所有项与应该检索的所有项的比例。f测度是精度和召回率的加权调和平均值。f1测度认为精度和查全率同等重要。它们分别定义为:
其中l是标签,tpl为真正值,fpl为假正值,fnl为假负值。
同时,由于irmas数据集中11种乐器演奏的音乐片段数量不同,研究还计算了精度、召回率和f1测度的微观平均及宏观平均。宏观平均认为每个类具有相同的权重,而微观平均认为每个实例样本具有相同的权重,数量最大的类影响最大。如果每个类别的样本大小几乎相同,那么宏观平均macro和微观平均micro之间的差异就很小。它们的定义如下:
其中l是类别数量。
本发明在irmas数据集上获得0.685的微观f1测度和0.597的宏观f1测度,乐器侧的识别效果如图4所示。
han等人提出了同类数据集上的主乐器识别方法,“deepconvolutionalneuralnetworksforpredominantinstrumentrecognitioninpolyphonicmusic,”ieee/acmtransactionsonaudio,speechandlanguageprocessing,vol.25,no.1,pp.208–221,may.2016.,该方法使用的convnet网络识别结果与本发明识别结果对比如图5所示。
- 还没有人留言评论。精彩留言会获得点赞!