基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法与流程
本发明涉及语音信号处理技术领域,具体地,涉及一种基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法。
背景技术:
在实际环境中,麦克风在拾取语音信号时,不可避免地会受到来自周围环境噪声、传输媒介噪声、通信设备内部电噪声、房间混响以及其它说话人的话音干扰,因此拾取语音的质量受到影响。语音增强技术是语音处理领域的核心技术之一,能够实现从带噪语音中提取干净的目标语音,以改善接收端语音质量,提高语音的清晰度、可懂度和舒适度,使人易于接受或提高语音处理系统的性能。
基于单个麦克风的语音增强技术的研究已经有四十多年的历史。但是实际情况中,噪声总是来自于四面八方,且其与语音信号在时间和频谱上常常是相互交叠的,再加上回波和混响的影响,利用单麦克风增强感兴趣的声音并有效抑制背景噪声和方向性强干扰是相当困难的。引入麦克风阵列技术后,语音增强技术取得了很大突破。相比传统的单一麦克风语音增强技术,麦克风阵列语音增强技术可以利用语音信号的空间信息来形成波束,实现对干扰噪声的消除,能够保证在语音信息损失最小的条件下实现噪声抑制(j.benesty,s.makino,andj.e.chen,speechenhancement.berlin,.germany:springer,2005.)。因此近十多年来,麦克风阵列语音增强技术已成为了语音增强技术的研究热点和关键技术。然而,目前大多数的麦克风阵列语音增强技术的性能都是正比于阵列所用麦克风数目的,因此该种技术的研究往往采用较多麦克风的阵列,有的麦克风阵列甚至使用数百个麦克风,而较多的麦克风数目造成麦克风阵列的体积也较大,最典型的案例是mit搭建的用于噪声消除和语音增强的麦克风阵列使用了1020个麦克风,其阵列孔径有几米长。因此麦克风阵列技术噪声抑制性能虽好,但由于其设备体积大,算法运算复杂度高,故在实际应用时受到了许多限制。
声学矢量传感器(acousticvectorsensor,avs)作为音频信号采集器。与常用的声压麦克风相比,avs在结构上具有其特殊性:一颗avs由2到3个正交放置的压力梯度传感器和1个全向压力传感器构成(a.nehoraiande.paldi,"vector-sensorarrayprocessingforelectromagneticsourcelocalization,"signalprocessing,ieeetransactionson,vol.42,pp.376-398,1994.),它的空间结构紧凑,传感器近似同位放置,各个传感器接收到的音频信号无时延差别。对于理想的avs,各通道接收信号存在三角函数关系,因此,仅单颗avs就能够实现单个或者多个的空间声源到达方向的估计。随着移动互联网和智能机器人等应用需求的不断增长,具有更小体积的avs,必将使之在众多场景中替代常规麦克风阵列技术,成为未来音频传感和噪声抑制的最佳解决方案之一。
为便于描述,以二维场景为例进行说明,即只利用avs中2个正交同位放置的压力梯度传感器采集音频信号的场景。实际应用中,可同理推广至三维场景或利用更多传感器的情形。在二维场景下,其梯度传感器输出的信号模型可表示为:
其中xavs(t)=[xu(t)xv(t)]t是avs的输出信号,navs(t)=[nu(t)nv(t)]t是传感器稳态背景噪声,s(t)是目标声源信号,ni(t)为干扰源信号,i为干扰源的数目。a(φs)=[usvs]t=[cosφssinφs]t是目标声源的导向矢量,同理干扰源的导向矢量为a(φi)=[uivi]t=[cosφisinφi]t。
基于avs的空间匹配波束形成器(spacialmatchedfilter,smf)的输出可表示为:
smf波束形成器(k.t.wong,h.chi,"beampatternsofanunderwateracousticvectorhydrophonelocatedawayfromanyreflectingboundary,"ieeejournalofoceanicengineering,vol.27,no.33,pp.628-637,july2002)能够在目标方向形成波束,其权值矢量与目标信号源的导向矢量的指向是一致的。当对目标信源到达角度φs方向进行波束形成时,smf的权值ws通常的解表示为:
ws=a(φs)/(||ah(φs)||||a(φs)||)(3)
该波束形成器对任意角度φ的声源,波束响应可表示为:
由波束响应可知smf波束形成器能够一定程度抑制非目标方向的干扰声源,但是由于smf的目标波束较宽,对干扰方向的抑制效果十分有限,难以满足实际应用。
另外,目前现有技术中也有一些增强目标语音的方法,比如:中国专利号为201710336341.x,专利名称为“一种增强目标语音的装置及其方法”,其公开了利用高阶空间匹配波束形成器对空间波束进行收窄后,再通过零陷滤波器和后置维纳滤波器对非不目标方向的噪声或者干扰声源进行滤波,虽然这种方法也能在一定程度上增强目标语音。但是当目标语音处于比较多变的噪音环境时,特别是在阵列或目标声源角度估计失配的情况下,采用高阶空间匹配波束形成器这种固定波束形成技术时,性能下降很大;同时对于背景噪声等非相干噪声的抑制作用十分有限,难以满足实际应用。
技术实现要素:
本发明的目的在于克服现有技术的缺陷和不足,提供基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法,该方法通过自适应波束形成和深度神经网络技术,可有效抑制空间干扰声源和背景噪声,实现目标语音的增强。
为了达到上述目的,本发明提供一种基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法,所述方法包括以下步骤:
a1:对声学矢量传感器中的各梯度传感器输出数据加窗分帧,进行短时傅里叶变换,分别得到各通道传感器的时频谱数据;
a2:根据所述步骤a1中得到的各通道时频谱数据获得各通道传感器间的相互数据比isdr,并根据所得的isdr值求得任意时频点占支配地位的声源到达角度估计;
a3:根据所述步骤a1中所得的各通道时频谱数据和步骤a2中得到的声源到达角估计,计算声源功率谱的空间分布,并利用目标方向的功率谱与空间总功率谱的比率配置高阶空间匹配滤波阶数;
a4:在短时傅里叶变换域,根据所述步骤a2获得目标声源到达角度和各时频点处占支配地位的声源到达角度,以及根据所述步骤a3中获得的所述滤波阶数,计算空间匹配波束形成器的高阶系数,完成高阶空间匹配波束滤波器的设计;
a5:利用所述步骤a4中所得的高阶空间匹配波束滤波器,设计目标方向零陷滤波器,对步骤a1中所得各通道数据滤波后,获得自适应波束形成器权值;
a6:利用步骤a5所得的自适应波束形成器权值,对步骤a1中声学矢量传感器各通道原始数据进行波束形成,得到初步增强的单通道目标语音时频谱;
a7:利用步骤a4中所得的高阶空间匹配波束滤波器对步骤a6中所得的单通道数据进行滤波,再次增强目标语音;
a8:通过训练好的专用深度神经网络,对步骤a7所得的数据进行处理,得到最终增强目标语音时频谱;
a9:对步骤a8所得到的数据进行反傅里叶变换,用叠接相加法重建增强后的目标语音时域信号。
本发明相对于现有技术,具有以下有益效果:本发明增强目标语音的方法通过自适应波束形成和深度神经网络技术,可有效抑制空间干扰声源和背景噪声,实现目标语音的增强。就算是在阵列或目标声源角度估计失配的情况下,性能也一样优秀;同时对于背景噪声等非相干噪声的抑制作用也很好,能满足实际应用。
附图说明
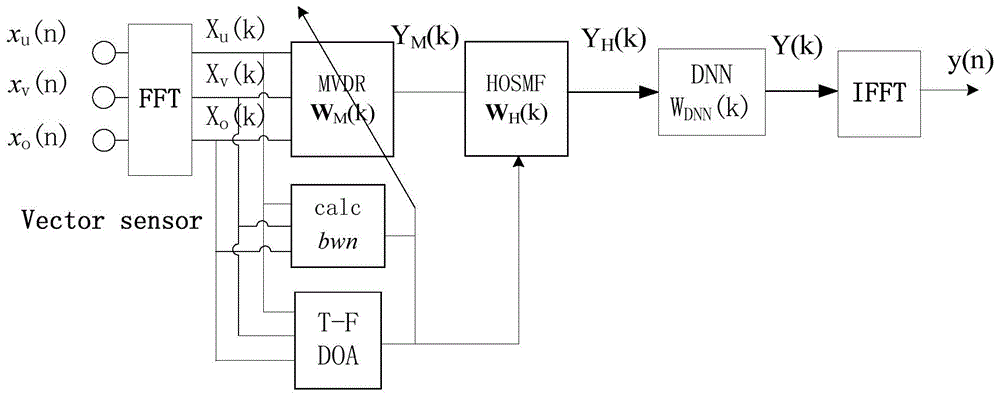
图1是本发明基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法示意图;
图2为本发明声学矢量传感器失去的混合语音信号;
图3为是采用本发明方法处理目标方向信号处理后的结果。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
与固定波束形成技术不同,自适应波束形成的滤波器权值是随着输入信号统计特性的变化而变化。当输入信号的统计特性未知,或者输入信号的统计特性变化时,自适应波束形成器能够自动地迭代调节自身的滤波器权值,以满足某种准则的要求,从而实现最优滤波输出。因此,自适应波束形成器具有自我调节和跟踪能力。以输出信噪比最大为准则设计的自适应波束形成器称为最小方差无失真响应(minimumvariancedistortionlessresponse,mvdr)波束形成器(j.capon.high-resolutionfrequency-wavenumberspectrumanalysis[j].proceedingsoftheieee,1969,57(8):1408-1418.)。这种波束形成器的权值系数选取准则是:在保证目标方向信号无失真通过的前提下,使阵列输出的噪声方差最小。
基于avs的mvdr波束形成器(m.e.lockwoodandd.l.jones.beamformerperformancewithacousticvectorsensorsinair[j].thejournaloftheacousticalsocietyofamerica,2006,119:608.)的输出在短时傅里叶变换域可表示为
其中,k为fft变换的频率指数,l是短时帧序号。wh(k,l)是波束形成器滤波权值系数,有
wh(k,l)=[wu(k,l)wu(k,l)wv(k,l)](2)
我们希望在保证目标方向信号无失真通过前提下最小化输出噪声的方差,于是mvdr波束形成器权系数向量的设计问题表述为
其中e[.]表示统计均值,可采用附近f帧的平均值。rn(k,l)为噪声的功率谱密度矩阵,为
rn(k,l)=e[n(k,l)nh(k,l)](4)
在实际应用中,语音与噪声是混合在一起的,因此噪声的功率谱密度矩阵往往是难以得到的。此时的解决办法通常是直接用阵列接收数据的功率谱密度矩阵来代替噪声的功率谱密度矩阵。以最小化输出功率为准则设计mvdr波束形成器权系数
其中
r(k,l)=e[x(k,l)xh(k,l)](6)
解得
本发明提供一种基于声学矢量传感器自适应波束形成和深度神经网络技术的目标语音增强方法,该方法包括以下步骤:
a1:对声学矢量传感器中的各梯度传感器输出数据加窗分帧,进行短时傅里叶变换,分别得到各通道传感器的时频谱数据;
a2:根据步骤a1中得到的各通道时频谱数据获得各通道传感器间的相互数据比isdr,并根据所得的isdr值求得任意时频点占支配地位的声源到达角度估计;
a3:根据步骤a1中所得的各通道时频谱数据和步骤a2中得到的声源到达角估计,计算声源功率谱的空间分布,并利用目标方向的功率谱与空间总功率谱的比率配置高阶空间匹配滤波阶数;
a4:在短时傅里叶变换域,根据步骤a2获得目标声源到达角度和各时频点处占支配地位的声源到达角度,以及根据步骤a3中获得的所述滤波阶数,计算空间匹配波束形成器的高阶系数,完成高阶空间匹配波束滤波器的设计;
a5:利用步骤a4中所得的高阶空间匹配波束滤波器,设计目标方向零陷滤波器,对步骤a1中所得各通道数据滤波后,获得自适应波束形成器权值;
a6:利用步骤a5所得的自适应波束形成器权值,对步骤a1中声学矢量传感器各通道原始数据进行波束形成,得到初步增强的单通道目标语音时频谱;
a7:利用步骤a4中所得的高阶空间匹配波束滤波器对步骤a6中所得的单通道数据进行滤波,再次增强目标语音;
a8:通过训练好的专用深度神经网络,对步骤a7所得的数据进行处理,得到最终增强目标语音时频谱;
a9:对步骤a8所得到的数据进行反傅里叶变换,用叠接相加法重建增强后的目标语音时域信号。
下面用实施例对上述本发明方法进行详细描述,采用16khz采样率对avs接收信号采样,并进行加窗分帧,分帧短时窗采用汉宁窗,窗长k=1024采样点,傅里叶变换点数也为k,帧移50%,得到各通道的时频谱数据
在(8)(9)和(10)中,k为fft变换的频率指数,l是短时帧序号。定义u通道传感器与o通道传感器间分量数据比(intersensordatarate,isdr)如下式
同理,v通道传感器与o通道传感器间分量数据比如下式
据研究(李波,基于信号稀疏性的声学矢量传感器doa估计方法研究,硕士学位论文,北京大学,2012),语音信号在短时傅里叶域具有较好的稀疏性。当一段语音有多个说话人出现时,仍会有某些语音片段只有一个说话人处于活跃状态而其他所有的说话人处于静音状态(短暂停顿或停歇)。即使在多个说话人同时处于活跃状态的片段,不同说话人的语音信号能量在频域仍有可能占据不同的离散频率。在某个具体的时频点,可以近似的认为至多只有一个信源占支配地位,其它信源的影响可以忽略。将此性质称作语音的时频域稀疏性。根据时频稀疏性假设,在时频数据点(k,l)处至多只有一个信源占支配地位,不妨用sd(k,l)表示该信源,导向矢量ad(φd)=[udvd1]t=[cosφdsinφd1]t。考虑传感器稳态噪声远小于各声源的情况,有
其中ε表示分量数据比误差分量,该误差由加性噪声引起,且均值为零。为求得360°范围的角度φd,当噪声水平较小时,可近似认为
φd(k,l)≈arctan2d(γvo(k,l),γuo(k,l))(14)
综上,对于任意信源的到达角度φ(k,l)在时频点(k,l)上的短时状态,可以用φd(k,l)来估计,
下面利用空间匹配波束形成器思想,设计目标零陷滤波器。一种高阶空间匹配波束形成器(high-orderspacialmatchedfilter,hosmf),其滤波器权值为(针对avs(2+1))
其对于任意时频点的滤波作用可表示为
进而设计目标零陷滤波器其权值系数为
其零陷波束的宽度仅与bwn有关,并随bwn的增大而变窄,通过设置不同bwn的值能够得到理想的波束宽度,进而抑制干扰噪声并增强目标语音。对于bwn的取值,当环境干扰声源较强时,可采取较大bwn值,但不宜过大,过大的值会导致目标声源的信息缺失。可利用φd(k,l)计算信源功率谱的空间分布,根据目标语音功率占空间总信号功率的比率的情况,配置高阶空间匹配滤波阶数。例如,采用如下方法
首先计算空间总信号功率
ew=sum(xu(k,l)x*u(k,l)+xv(k,l)x*v(k,l))(18)
下面计算目标语音功率,因为目标语音未知,所以用下式估计
其中ns为一个常数,与目标语音估计的精度有关,可设置为256。于是,目标语音功率占空间总信号功率的比率为
最后,求得bwn为
其中,a和b分别取值为4和16。
设计频域mvdr波束形成器权值为
为提升mvdr性能,对avs输出信号进行零陷滤波后用以估计计算噪声功率谱密度矩阵,代替通常使用阵列输出的功率谱密度矩阵。噪声估计如下
噪声的功率谱密度矩阵为
其中e[.]表示统计均值,可采用附近f帧的平均值。
于是改进的mvdr波束形成器权值为
利用(25)所得mvdr波束形成器对(8)(9)(10)各通道信号做波束形成处理,提取初步增强的目标语音时频谱,其输出为
再利用(15)所得hosmf滤波器对mvdr的输出信号(26)进行滤波处理,提取进一步增强的目标语音时频谱,其输出为
yh(k,l)=whosym(k,l)(27)
对yh(k,l)进行傅里叶反变换后,使用叠接相加法(overlapadd)重建时域语音信号yh(t)。
下面进入深度学习语音增强过程。对yh(t)进行加床分帧,提取对数功率谱yhlps(k,l)特征和梅尔倒谱yhmfc(n,l)特征,其中n为梅尔倒谱特征维度,之后可以进入到深度学习单通道语音增强模型的推理过程,模型输入特征为yhlps(k,l)和yhmfc(n,l)的合并矩阵iyhlps+yhmfc(k+n,l),输出可得到干净语音对数功率谱的估计slps(k,l),结合原始输入信号的相位信息进行变换,得到干净语音时频谱估计,经过傅里叶反变换,采用叠接相加法(overlapadd)重建时域语音信号s'(t)。深度学习单通道语音增强过程详细描述如下:
步骤1:数据准备
本算法中基于深度学习的单通道语音增强所需大量训练数据全部来源于仿真,该数据仿真过程前提假设是语音s(t)和噪声n(t)的特征服高斯特性,二者相互独立,即带噪语音信号y(t)=s(t)+n(t);基本思想是构建带噪语音y(t)和干净语音s(t)的输入输出功率谱映射对,通过神经网络学习近似逼近该映射关系。
数据仿真需要的噪声集和不含噪声的干净语音数据集包括但不限于timit、thchs30、noisex-92等开源数据集和部分商业数据集。其中语音数据集语种为汉语、英语;噪声数据集约300个类别,包括但不限于广场、车站、餐厅、市场、机场、巴士、客厅、厨房等各种场景以及风格各异的不带歌词的音乐。总训练数据集时长不少于2000小时。
步骤2:特征提取
一般先对训练数据统一重采样至16khz,并进行加窗分帧,帧长可采用1024采样点,帧移50%。
对带噪语音y(t)提取对数功率谱特征ylps(k,l)和mfcc特征ymfc(n,l),对干净语音s(t)提取对数功率谱slps(k,l)和梅尔倒谱特征smfc(n,l),对噪声n(t)提取对数功率谱特征nlps(k,l);神经网络输入特征为ylps(k,l)、ymfc(n,l)的合并矩阵iylps+ymfc(k+n,l),输出特征为slps(k,l)、smfc(n,l)、nlps(k,l)的合并矩阵oslps+smfc+nlps(k+n+k,l);输入输出特征按帧进行全局零均值单位方差归一化,并按帧进行混淆,以增强泛化能力。
步骤3:模型构建
此模型主要由cnn/gru/dnn层和batchnorm层组成,cnn主要用于降低参数数量,gru用于学习时域序列特征,dnn用于特征平滑;损失函数为mse或者mae。
步骤4:模型训练、保存
设置、调整学习率和超参数,在避免过拟合的情况下反复迭代训练,训练时间根据硬件资源而有所差异,直至后续测试结果达到某种可接受程度为止。
步骤5:模型推理、测试
加载上述已经训练好的模型,再提取测试集语音信号的输入特征,经过推理得到输出特征ts'lps+s'mfc+n'lps(k+n+k,l),即slps(k,l)、smfc(n,l)、nlps(k,l)的估计值s'lps(k,l)、s'mfc(n,l)、n'lps(k,l)的合并矩阵,经过特定后处理并进行傅里叶反变换,采用叠接相加法(overlapadd)重建时域语音信号s'(t)。所述特定处理,可采用但不限于对推理得到的干净语音对数功率谱的估计slps(k,l)结合原始输入信号的相位特征进行变换,进而得到干净语音时频谱估计的方式。
综上所述,本发明增强目标语音的方法通过自适应波束形成和深度神经网络技术,可有效抑制空间干扰声源和背景噪声,实现目标语音的增强。就算是在阵列或目标声源角度估计失配的情况下,性能也一样优秀;同时对于背景噪声等非相干噪声的抑制作用也很好,能满足实际应用。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未违背本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!