使用间隙置信度的背景噪声估计的制作方法
使用间隙置信度的背景噪声估计
[0001]
相关申请的交叉引用
[0002]
本申请要求于2018年4月27日提交的美国临时申请号62/663,302和2018年6月14日提交的欧洲专利申请号18177822.6的优先权,其中每个专利申请均通过引用其全部而并入本文。
技术领域
[0003]
本发明涉及用于估计音频信号回放环境中的背景噪声并使用噪声估计来处理音频信号(例如,对音频信号进行噪声补偿)以用于回放的系统和方法。在一些实施例中,噪声估计包括:确定间隙置信度值,并使用间隙置信度值来确定一系列背景噪声估计,每个间隙置信度值指示回放信号中(在对应时间处)存在间隙的置信度。
背景技术:
[0004]
便携式电子设备的普及意味着人们在许多不同的环境中每天都在与音频互动。例如,收听音乐、看娱乐内容、收听可听通知和指示以及参与语音呼叫。发生这些活动的收听环境可能经常会固有地嘈杂(具有恒定地变化的背景噪声条件),这损害了收听体验的享受性和清晰度。将用户置于响应于变化的噪声条件而手动调整回放水平的循环中使用户从收听任务分散注意力,并增加了进行音频收听任务所需的认知负担。
[0005]
噪声补偿媒体回放(ncmp)通过将正在播放的任何媒体的音量调整为适合于回放媒体的噪声条件来缓解此问题。ncmp的概念是众所周知的,并且许多出版物声称已经解决了如何有效实施ncmp的问题。
[0006]
尽管称为“主动噪声消除”的相关领域尝试通过声波的再现来物理消除干扰噪声,但ncmp调整回放音频的水平,以使得经调整的音频在存在背景噪声的情况下能够在回放环境中被听到并且是清晰的。
[0007]
在ncmp的任何实际实施方式中的主要挑战是自动确定收听者所经历的目前的背景噪声水平,尤其是在通过扬声器播放媒体内容的情况下,在这种情况下,背景噪声和媒体内容在声学上高度耦接。涉及麦克风的解决方案面临着媒体内容和噪声条件一起被观察(被麦克风检测到)的问题。
[0008]
图1示出了实施ncmp的典型音频回放系统。该系统包括内容源1,该内容源输出指示音频内容(在本文中有时被称为媒体内容或回放内容)的音频信号并将该音频信号提供给噪声补偿子系统2。音频信号旨在进行回放以(在环境中)生成指示音频内容的声音。音频信号可以是扬声器馈送(并且噪声补偿子系统2可以被耦接为并被配置为通过调整扬声器馈送的回放增益来对扬声器馈送施加噪声补偿),或者系统的另一元件可以响应于音频信号而生成扬声器馈送(例如,噪声补偿子系统2可以被耦接为并被配置为响应于音频信号而生成扬声器馈送,并通过调整扬声器馈送的回放增益来对扬声器馈送施加噪声补偿)。
[0009]
图1的系统还包括如图所示耦接的噪声估计系统5、用于对音频信号(或在子系统2中生成的音频信号的噪声补偿版本)进行响应的至少一个扬声器3(被耦接为并被配置为发
出指示媒体内容的声音)以及麦克风4。在操作中,麦克风4和扬声器3处于回放环境(例如房间)中,并且麦克风4生成指示环境中的背景(周围)噪声和媒体内容的回声两者的麦克风输出信号。噪声估计子系统5(在本文中有时被称为噪声估计器)耦接到麦克风4,并被配置为使用麦克风输出信号来生成对环境中的一个或多个当前背景噪声水平的估计(图1的“噪声估计”)。噪声补偿子系统2(在本文中有时被称为噪声补偿器)被耦接并被配置为通过响应于由子系统5产生的噪声估计而调整音频信号(例如,调整音频信号的回放增益)(或调整响应于音频信号而生成的扬声器馈送)来施加噪声补偿,从而生成指示经补偿的媒体内容(如图1所指示的)的噪声补偿音频信号。通常,子系统2调整音频信号的回放增益,使得发出的声音响应于经调整的音频信号在存在背景噪声(如由噪声估计子系统5所估计的)的情况下能够在回放环境中被听到并且是清晰的。
[0010]
如将在下文描述的,可以根据本发明的一类实施例来实施在实施噪声补偿的音频回放系统中使用的背景噪声估计器(例如,图1的噪声估计器5)。
[0011]
许多出版物已涉及噪声补偿媒体回放(ncmp)的问题,并且补偿背景噪声的音频系统可以在许多方面取得成功。
[0012]
已经提出了在没有麦克风的情况下并且替代地使用其他传感器(例如,在汽车的情况下为速度计)来执行ncmp。然而,这种方法不如实际上测量收听者所经历的干扰噪声的水平的基于麦克风的解决方案有效。还已经提出了依靠位于与指示回放内容的声音解耦的声学空间中的麦克风来执行ncmp,但是这种方法对于许多应用都受到严格限制。
[0013]
由于在由麦克风捕获的回放信号与噪声估计器所感兴趣的噪声信号混合时出现“回声问题”,因此,上一段中提到的ncmp方法没有尝试使用还捕获了回放内容的麦克风来准确地测量噪声水平。替代地,这些方法要么通过限制它们所施加的补偿以致不会形成不稳定的反馈回路,要么通过测量某种程度上预测收听者所经历的噪声水平的其他内容,来试图忽略该问题。
[0014]
还已经提出了通过尝试使回放内容与麦克风输出信号相关联,并且从麦克风输出中减去由麦克风所捕获的回放内容(被称为“回声”)的估计来解决从麦克风输出信号(指示背景噪声和回放内容两者)估计背景噪声的问题。麦克风捕获声音时生成的指示从一个或多个扬声器发出的回放内容x和背景噪声n的麦克风输出信号的内容可以表示为wx+n,其中,w是由发出指示回放内容的声音的一个或多个扬声器、麦克风以及该声音从该一个或多个扬声器传播到该麦克风的环境(例如,房间)确定的传递函数。例如,在学术上提出的用于估计噪声n的方法(将参考图2进行描述)中,线性滤波器w
’
被适配为促进对回声(由麦克风捕获的回放内容)wx的估计w
’
x,以用于从麦克风输出信号中减去。即使系统中存在非线性,滤波器w
’
的非线性实施方式也由于计算成本很少实施。
[0015]
图2是用于实施上述传统方法(有时被称为回声消除)的系统的图,上述方法用于估计在一个或多个扬声器发出指示回放内容的声音的环境中的背景噪声。回放信号x被呈现给环境e中的扬声器系统s(例如,单个扬声器)。麦克风m位于相同的环境e中。响应于回放信号x,扬声器系统s发出到达麦克风m的声音(连同在环境e中存在的任何环境噪声n)。麦克风输出信号为y=wx+n,其中,w表示传递函数,该传递函数是扬声器系统s、回放环境e和麦克风m的组合响应。由图2的系统实施的一般方法使用各种自适应滤波器方法中的任何方法从y和x自适应地推断传递函数w。如图2所示,将线性滤波器w
’
自适应地确定为传递函数w
’
的近似值。由麦克风信号m所指示的回放信号内容(“回声”)被估计为w
’
x,并且从y中减去w
’
x以得到对噪声n的估计y
’
=wx-w
’
x+n。如果估计中存在正偏置,则按与y
’
成比例地调整x的水平会产生反馈回路。y
’
的增大进而使x的水平增大,这使n的估计(y
’
)中引入向上偏置,从而进而增大x的水平,以此类推。这种形式的解决方案将严重依赖于自适应滤波器w
’
使得从y中减去w
’
x以从麦克风信号m中移除大量回声wx的能力。
[0016]
为了保持图2的系统的稳定,通常需要对信号y
’
进行进一步滤波。由于本领域中的大多数噪声补偿实施例都表现出较差的性能,因此大多数解决方案通常可能将噪声估计向下偏置并引入积极的时间平滑以保持系统稳定。这是以减少补偿行为和非常缓慢的补偿行为为代价的。
[0017]
声称用于实施上述用于噪声估计的学术方法的(参考图2所描述的类型的)系统的传统实施方式通常忽略伴随实施过程而发生的问题,包括以下中的部分或全部问题:
[0018]
·
尽管解决方案的学术模拟指示回声降低高达40db,但由于非线性、背景噪声的存在以及回声路径w的非平稳性,实际的实施方式被限制到20db左右。这意味着背景噪声的任何测量将因残留回声而产生偏置;
[0019]
·
有时,环境噪声和特定的回放内容导致这种系统中的“泄漏”(例如,当回放内容由于蜂鸣声、颤动(rattle)和失真而激发回放系统的非线性区域时)。在这些情况下,麦克风输出信号包含大量的残留回声,该残留回声将被错误地解释为背景噪声。在这种情况下,随着残留误差信号变大,滤波器w
’
的适配也可能变得不稳定。而且,当麦克风信号被高水平的噪声损害时,滤波器w
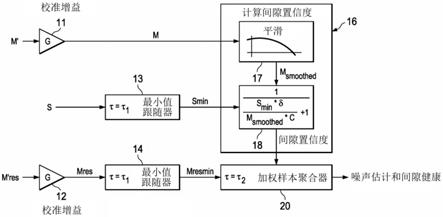
’
的适配可能变得不稳定;以及
[0020]
·
用于跨广泛的频率范围(例如,覆盖典型音乐的回放的频率范围)生成可用于执行ncmp操作的噪声估计(y
’
)所需的计算复杂度很高。
[0021]
用于补偿环境噪声条件的噪声补偿(例如,将扬声器回放内容自动校平)是众所周知并且期望的特征,但尚未令人信服地实施。使用麦克风来测量环境噪声条件还测量扬声器回放内容,呈现出对实施噪声补偿所需的噪声估计(例如,在线噪声估计)的重大挑战。本发明的典型实施例是噪声估计方法和系统,该方法和系统以改进的方式生成可用于执行噪声补偿的噪声估计(例如,以实施噪声补偿媒体回放的许多实施例)。由这种方法和系统的典型实施方式实施的噪声估计具有简单的公式。
技术实现要素:
[0022]
在一类实施例中,本发明方法(例如,生成对回放环境中的背景噪声的估计的方法)包括以下步骤:
[0023]
在回放环境中发出声音期间,使用麦克风来生成麦克风输出信号,其中,该声音指示回放信号的音频内容,并且麦克风输出信号指示回放环境中的背景噪声和音频内容;
[0024]
响应于麦克风输出信号(例如,响应于麦克风输出信号的平滑水平)和回放信号而生成间隙置信度值(即,指示间隙置信度值的一个或多个信号或数据),其中,间隙置信度值中的每个间隙置信度值是针对不同的时间t(例如,包括时间t的不同时间间隔)的,并且指示在回放信号中在时间t处存在间隙的置信度;以及
[0025]
使用间隙置信度值来生成对回放环境中的背景噪声的估计。
[0026]
回放环境可以涉及在其中发出声音的声学环境或声学空间。例如,回放环境可以
是在其中发出声音(例如,响应于回放信号而通过扩音器发出声音)的那个声学环境。
[0027]
通常,对回放环境中的背景噪声的估计是或者包括一系列噪声估计,噪声估计中的每个噪声估计指示在不同的时间t处在回放环境中的背景噪声,并且噪声估计中的所述每个噪声估计是已通过针对包括时间t的不同时间间隔的间隙置信度值进行加权的候选噪声估计的组合。这样,使用间隙置信度值来生成对回放环境中的背景噪声的估计可以涉及:针对每个噪声估计,通过间隙置信度值对针对包括时间t的不同时间间隔的候选噪声估计进行加权,以及组合加权的候选噪声估计以获得相应的噪声估计。
[0028]
候选噪声估计可以具有不同的可靠性(例如,关于它们是否如实地表示要估计的噪声)。候选噪声估计的可靠性可以由相应的间隙置信度值指示。该方法可以考虑针对包括时间t的时间间隔(例如,包括时间t的滑动分析窗口)的候选噪声估计(其中,针对间隔内的每个时间具有一个候选噪声估计),并且利用每个候选噪声估计的相应的间隙置信度值(例如,针对间隔内的相应时间的间隙置信度值)对每个候选噪声估计进行加权。这样,使用间隙置信度值来生成对回放环境中的背景噪声的估计可以涉及:利用候选噪声估计的相应的间隙置信度值对候选噪声估计进行加权,并组合加权的候选噪声估计。换言之,针对每个时间t,考虑包括时间t的间隔(例如,滑动分析窗口)。针对间隔内的每个时间,该间隔可以包含候选噪声估计。然后,可以通过组合针对包括时间t的间隔的候选噪声估计(具体地通过组合加权的候选噪声估计)来获得针对时间t的实际噪声估计,每个候选噪声估计利用相应的候选噪声估计的针对时间的间隙置信度值来加权。
[0029]
例如,候选噪声估计中的每个候选噪声估计可以是(通过回声消除生成的)一系列回声消除噪声估计中的最小回声消除噪声估计m
resmin
,并且针对每个所述时间间隔的噪声估计可以是针对该时间间隔的最小回声消除噪声估计的组合,该最小回声消除噪声估计通过针对该时间间隔的间隙置信度值中的对应的间隙置信度值进行加权。最小回声消除噪声估计可以涉及一系列回声消除噪声估计的最小值。例如,最小回声消除噪声估计可以通过对该系列回声消除噪声估计执行最小值跟随(minimum following)来获得。最小值跟随可以使用给定长度/大小的分析窗口来操作。然后,最小回声消除噪声估计可以是分析窗口内的回声消除噪声估计的最小值。回声消除噪声估计通常是已经经过校准以使它们进入与回放信号相同的水平域的校准回声消除噪声估计。又例如,候选噪声估计中的每个候选噪声估计可以是一系列麦克风输出信号值中的最小校准麦克风输出信号值m
min
,并且针对所述每个时间间隔的噪声估计可以是针对该时间间隔的最小麦克风输出信号值的组合,该最小麦克风输出信号值通过针对该时间间隔的间隙置信度值中的对应的间隙置信度值进行加权。麦克风输出信号值通常是已经过校准以使它们进入与回放信号相同的水平域的校准麦克风输出信号值。
[0030]
在一类实施例中,在对一系列不同时间间隔中的每个时间间隔中的候选噪声估计执行最小值跟随器处理的意义上,在(间隙置信度加权样本的)最小值跟随器中处理候选噪声估计。最小值跟随器仅在相关联的间隙置信度高于预定阈值时,才在最小值跟随器的分析窗口中包括每个候选样本(针对时间间隔的候选噪声估计的每个值)(例如,如果候选样本的间隙置信度等于或大于该阈值,则最小值跟随器为该样本赋值权重一,并且如果候选样本的间隙置信度小于该阈值,则最小值跟随器为该样本赋值权重零)。在这类实施例中,生成针对每个时间间隔的噪声估计包括以下步骤:(a)识别针对该时间间隔的候选噪声估
计中的每个候选估计噪声,针对该时间间隔,间隙置信度值中的对应的间隙置信度值超过预定阈值;以及(b)生成针对该时间间隔的噪声估计作为步骤(a)中所识别的候选噪声估计中的最小候选噪声估计。
[0031]
在典型的实施例中,每个间隙置信度值(即,针对时间t的间隙置信度值)指示回放信号水平中的最小值(s
min
)与(时间t处的)麦克风输出信号的平滑水平(m
smoothed
)的差异程度。s
min
值距平滑水平m
smoothed
越远,在时间t处在回放内容中存在间隙的置信度越大,并且因此,针对时间t的候选噪声估计(例如,针对时间t的m
resmin
值或者m
min
值)指示回放环境中的背景噪声(在时间t处)的置信度越大。
[0032]
通常,该方法包括以下步骤:生成一系列间隙置信度值,以及使用间隙置信度值来生成一系列背景噪声估计。该方法的一些实施例还包括以下步骤:使用该系列背景噪声估计对音频输入信号执行噪声补偿。
[0033]
一些实施例(响应于麦克风输出信号和回放信号)执行回声消除以生成候选噪声估计。其他实施例生成候选噪声估计,而无需执行回声消除的步骤。
[0034]
本发明的一些实施例包括以下方面中的一个或多个方面:
[0035]
一个这种方面涉及:(使用指示存在间隙中的每个间隙的置信度的数据)确定回放内容中的间隙,以及(例如,通过实施与回放内容间隙相对应的采样间隙,以间隙置信度加权的候选噪声估计的形式)生成背景噪声估计。一些实施例生成候选噪声估计,利用间隙置信度数据值对候选噪声估计进行加权以生成间隙置信度加权的候选噪声估计,并使用间隙置信度加权的候选噪声估计来生成背景噪声估计。在一些实施例中,生成候选噪声估计包括执行回声消除的步骤。在其他实施例中,生成候选噪声估计不包括执行回声消除的步骤。
[0036]
另一个这种方面涉及一种采用根据本发明的任何实施例生成的背景噪声估计来对输入音频信号执行噪声补偿(例如,噪声补偿媒体回放)的方法和系统。
[0037]
另一个这种方面涉及一种估计回放环境中的背景噪声,从而生成可用于对输入音频信号执行噪声补偿(例如,噪声补偿媒体回放)的背景噪声估计的方法和系统。在一些这种实施例中,该方法和/或系统还在生成背景噪声估计中采用回声消除(aec)时执行自校准(例如,确定用于施加到回放信号、麦克风输出信号和/或回声消除残差值的校准增益,以实施噪声估计)和/或自动检测系统故障(例如,硬件故障)。
[0038]
本发明的各方面进一步包括一种被配置(例如,被编程)为执行本发明方法或其步骤的任何实施例的系统,以及一种实施数据的非暂态存储的有形非暂态计算机可读介质(例如,磁盘或其他有形存储介质),该有形非暂态计算机可读介质存储用于执行本发明方法或其步骤的任何实施例的代码(例如,能够执行代码,以执行本发明方法或其步骤的任何实施例)。例如,本发明系统的实施例可以是或者包括可编程通用处理器、数字信号处理器或微处理器,该可编程通用处理器、数字信号处理器或微处理器用软件或固件编程为和/或以其他方式被配置为对数据执行多种操作中的任何操作,包括本发明方法或其步骤的实施例。这种通用处理器可以是或者包括计算机系统,该计算机系统包括输入设备、存储器和处理子系统,该通用处理器被编程(和/或以其他方式被配置)为响应于向其断言(assert)的数据而执行本发明方法(或其步骤)的实施例。
附图说明
[0039]
图1是实施噪声补偿媒体回放(ncmp)的音频回放系统的框图。
[0040]
图2是用于根据被认为是回声消除的传统方法从麦克风输出信号生成噪声估计的传统系统的框图。麦克风输出信号通过捕获回放环境中的声音(指示回放内容)和噪声来生成。
[0041]
图3是用于针对麦克风输出信号的每个频带生成噪声水平估计的本发明系统的实施例的框图。通常,麦克风输出信号通过捕获回放环境中的声音(指示回放内容)和噪声来生成。
[0042]
图4是图4的系统的噪声估计生成子系统37的实施方式的框图。
[0043]
符号和术语
[0044]
遍及本公开,包括在权利要求中,回放信号中的“间隙(gap)”表示回放信号的时间(或时间间隔),在该时间(或时间间隔)处(或在该时间(或时间间隔)中)回放内容缺失(或具有低于预定阈值的水平)。
[0045]
遍及本公开,包括在权利要求中,“扬声器”和“扩音器”同义地用于表示由单个扬声器馈送驱动的任何发声换能器(或换能器组)。典型的耳机包括两个扬声器。扬声器可以被实施为包括多个换能器(例如,低音扬声器和高音扬声器),该多个换能器全部由单个公共扬声器馈送驱动(扬声器馈送可以在耦接到不同换能器的不同电路分支中经历不同的处理)。
[0046]
遍及本公开,包括在权利要求中,对信号或数据执行操作(例如,对信号或数据进行滤波、缩放、变换或施加增益)的表达在广义上用于表示直接对信号或数据执行操作或对信号或数据的经处理的版本(例如,在对其执行操作之前已经经历初步滤波或预处理的信号的版本)执行操作。
[0047]
遍及本公开,包括在权利要求中,表达“系统”在广义上用于表示设备、系统或子系统。例如,实施解码器的子系统可以被称为解码器系统,并且包括这种子系统的系统(例如,响应于多个输入而生成x个输出信号的系统,其中,该子系统生成输入中的m个输入,并且其他x-m个输入从外部源接收)也可以被称为解码器系统。
[0048]
遍及本公开,包括在权利要求中,术语“处理器”在广义上用于表示可编程或以其他方式可配置(例如,利用软件或固件)为对数据(例如,音频、或视频或其他图像数据)执行操作的系统或设备。处理器的示例包括现场可编程门阵列(或其他可配置集成电路或芯片组)、被编程和/或以其他方式被配置为对音频或其他声音数据执行流水线式处理的数字信号处理器、可编程通用处理器或计算机,以及可编程微处理器芯片或芯片组。
[0049]
遍及本公开,包括在权利要求中,术语“耦接”或“被耦接”用于指直接或间接连接。因此,如果第一设备耦接到第二设备,则该连接可以是通过直接连接或者通过经由其他设备和连接的间接连接的。
具体实施方式
[0050]
本发明的许多实施例在技术上是可能的。对于本领域普通技术人员而言,根据本公开将显而易见的是如何实施这些实施例。本文参考图3和图4描述了本发明系统和方法的一些实施例。
[0051]
图4的系统被配置为生成对回放环境28中的背景噪声的估计,并使用噪声估计对输入音频信号执行噪声补偿。图3是图4的系统的噪声估计子系统37的实施方式的框图。
[0052]
根据本发明的噪声估计方法的实施例,图4的噪声估计子系统37被配置为生成背景噪声估计(通常是一系列噪声估计,每个噪声估计对应于不同的时间间隔)。图4的系统还包括噪声补偿子系统24,该噪声补偿子系统被耦接并被配置为使用从子系统37输出的噪声估计(或者这种噪声估计的后处理版本,该后处理版本在后处理子系统39进行操作以修改从子系统37输出的噪声估计的情况下从后处理子系统39输出)对输入音频信号23执行噪声补偿以生成输入信号23的噪声补偿版本(回放信号25)。
[0053]
图4的系统包括内容源22,该内容源被耦接并被配置为输出音频信号23,并将该音频信号提供给噪声补偿子系统24。信号23指示音频内容(在本文中有时被称为媒体内容或回放内容)的至少一个通道,并且旨在经历回放以(在环境28中)生成指示音频内容的每个通道的声音。音频信号23可以是扬声器馈送(或在多通道回放内容的情况下为两个或更多个扬声器馈送),并且噪声补偿子系统24可以被耦接并被配置为通过调整扬声器馈送的回放增益来对每个这种扬声器馈送施加噪声补偿。可替代地,系统的另一元件可以响应于音频信号23而生成扬声器馈送(或多个扬声器馈送)(例如,噪声补偿子系统24可以被耦接并被配置为响应于音频信号23而生成至少一个扬声器馈送,并通过调整扬声器馈送的回放增益来对每个扬声器馈送施加噪声补偿,以使得回放信号25由至少一个噪声补偿的扬声器馈送构成)。在图4的系统的操作模式中,子系统24不执行噪声补偿,以使得回放信号25的音频内容与信号23的音频内容相同。
[0054]
扬声器系统29(包括至少一个扬声器)被耦接并被配置为响应于回放信号25而(在回放环境28中)发出声音。信号25可以由单个回放通道构成,或者信号25可以由两个或更多个回放通道构成。在典型的操作中,扬声器系统29中的每个扬声器接收指示信号25的不同通道的回放内容的扬声器馈送。作为响应,扬声器系统29响应于一个或多个扬声器馈送而(在回放环境28中)发出声音。该声音作为输入信号23的回放内容的噪声补偿版本(在环境28中)被收听者31感知。
[0055]
下面将描述图4的系统的其他元件。
[0056]
本公开将涉及以下三种类型的背景噪声:
[0057]
分散性噪声(例如,突发(impulsive)和偶发事件(例如,持续时间少于0.5秒),例如门砰地关上、汽车鸣笛、在道路突出物上行驶);
[0058]
扰乱性噪声(干扰回放内容的短事件,例如头顶的飞机经过、驾驶通过短隧道、在新路面的一部分上驾驶);以及
[0059]
普遍性噪声(可以开始和停止但通常保持稳定的持续/恒定的噪声,例如空调、风扇、都市环境噪声、雨水、厨房用具)。
[0060]
基于发明人的实验,按照重要性的顺序,成功的噪声补偿的特性包括以下:
[0061]
稳定性(噪声估计不应被在麦克风处测量的回放内容破坏。噪声估计以及因此的补偿增益不应由于回放内容的变化而以明显的方式波动。任何噪声估计都不应跟踪比“扰乱性”噪声源更快的任何事物。噪声估计应忽略“分散性”突发事件);
[0062]
快速反应时间(良好的噪声估计将仅跟踪“普遍性”噪声源。然而,杰出的噪声估计还将能够可靠地跟踪“扰乱性”噪声源。对噪声条件的变化做出快速反应对用户体验至关重
要);以及
[0063]
舒适的补偿量(噪声补偿应确保在存在噪声的情况下保持清晰度和音质。补偿过低或过高使用户体验不令人满意。补偿是在多带的意义上执行的,具有比大音量调整更高的保真度)。
[0064]
使用最小值跟随滤波器来跟踪平稳噪声的噪声估计是一种既定技术。为了执行这种估计,最小值跟随器滤波器将输入样本累积到被称为分析窗口的滑动的固定大小的缓冲区中,并输出该缓冲区中的最小样本值。针对短分析窗口和长分析窗口两者,最小值跟随移除突发的扰乱性噪声源。由于最小值跟随器将保持在回放内容中的间隙期间以及在麦克风附近的任何用户的语音之间的间隙期间出现的最小值,因此,长分析窗口(持续时间约为10秒)可有效地定位平稳的本底噪声(普遍性噪声)。分析窗口越长,将发现间隙的可能性越大。然而,此方法将跟随最小值,而不管最小值实际上是否是回放内容中的间隙。此外,长分析窗口使系统花费较长时间来向上跟踪以增加背景噪声,这对于噪声补偿而言是明显的缺点。长分析窗口通常将最终跟踪普遍性噪声源,但错过跟踪扰乱性噪声源。
[0065]
本发明的典型实施例的一个重要方面是使用回放信号的知识来决定何时条件最有利于测量来自麦克风输出(并且可选地,还有来自通过对麦克风输出执行回声消除而生成的回声消除噪声估计)的噪声估计。在时频域中查看的真实的回放信号将通常包含信号能量低的点,这隐含时间和频率中的这些点是测量周围噪声条件的良好时机。本发明的典型实施例的一个重要方面是一种量化这些时机的良好程度(例如,通过对时机中的每个时机赋值被称为“间隙置信度”值或“间隙置信度”的值)的方法。以这种方式解决问题使噪声补偿(或噪声估计)对许多类型的内容是可能的,而无需回声消除器(以生成回声消除噪声估计),并且降低了对回声消除器的性能的要求(当使用回声消除器时)。
[0066]
接下来,参考图3和图4,我们描述了用于为回放内容的多个不同频带中的每个带计算对背景噪声水平的一系列估计的本发明方法和系统的实施例。图4是系统的框图,并且图3是图4的系统的子系统37的实施方式的框图。应当理解,图4的元件(不包括回放环境28、扬声器系统29、麦克风30和收听者31)可以在处理器中或作为处理器来实施,其中这种元件中的执行信号(或数据)处理操作的那些元件(包括在本文中被称为子系统的那些元件)以软件、固件或硬件来实施。
[0067]
麦克风输出信号(例如,图4的信号“mic”)是使用占用与收听者(例如,图4的收听者31)相同的声学空间(图4的环境28)的麦克风(例如,图4的麦克风30)来生成的。可以使用两个或更多个麦克风(例如,将其各个输出组合)来生成麦克风输出信号是可能的,并且因此,术语“麦克风”在本文中在广义上用于表示单个麦克风或者被操作用于生成单个麦克风输出信号的两个或更多个麦克风。麦克风输出信号指示声学回放信号(从图4的扬声器系统29发出的声音的回放内容)和竞争性背景噪声两者,并且被变换(例如,通过图4的时频变换元件32)为频域表示,从而生成频域麦克风输出数据,并且频域麦克风输出数据被带划分(banded)(例如,通过图4的元件33)到功率域中,从而产生麦克风输出值(例如,图3和图4的值m
’
)。对于每个频带,使用(例如,由图3的增益级11施加的)校准增益g来调整值中的对应值(值m
’
之一)的水平,以产生经调整的值m(例如,图3的值m之一)。需要施加校准增益g来校正数字回放信号(值s)和数字化麦克风输出信号水平(值m
’
)的水平差。下面讨论用于自动并且通过测量来确定(针对每个频带的)g的方法。
[0068]
对回放内容(其通常是多通道回放内容)的每个通道(例如,图4的噪声补偿信号25的每个通道)进行频率变换(例如,通过图4的时频变换元件26,优选地使用由变换元件32执行的相同变换),从而生成频域回放内容数据。对(针对所有通道的)频域回放内容数据进行下降混合(在信号25包括两个或更多个通道的情况下),并且所得到的单个频域回放内容数据流被带划分(例如,通过图4的元件27,优选地使用由元件33执行的相同的带划分操作来生成值m
’
)以产生回放内容值s(例如,图3和图4的值s)。还应在时间上延迟值s(在值s根据本发明的实施例处理之前,例如,通过图3的元件13),以考虑硬件中的任何时延(例如,由于a/d和d/a转换)。该调整可以被认为是粗略调整。
[0069]
图4的系统包括:回声消除器34,该回声消除器被耦接并被配置为通过对从元件26和32输出的频域值执行回声消除来生成回声消除噪声估计值;以及带划分子系统35,该带划分子系统被耦接并被配置为对从回声消除器34输出的回声消除噪声估计值(残差值)执行频率带划分,以生成经带划分的回声消除噪声估计值m
’
res(包括针对每个频带的值m
’
res)。
[0070]
在信号25是多通道信号(包括z个回放通道)的情况下,回声消除器34的典型实施方式(从元件26)接收多个频域回放内容值流(针对每个通道一个流),并为每个回放通道适配滤波器w
’
i
(对应于图2的滤波器w
’
)。在这种情况下,麦克风输出信号y的频域表示可以表示为w1x+w2x+...+w
z
x+n,其中,每个w
i
是z个扬声器中的不同扬声器(第“i”个扬声器)的传递函数。回声消除器34的这种实施方式从麦克风输出信号y的频域表示中减去每个w
’
i
x估计(每个通道一个估计),以生成与图2的回声消除噪声估计值y
’
对应的单个回声消除噪声估计(或“残差”)值流。
[0071]
通常,通过向麦克风输出信号施加回声消除(其中,回声是由回放信号的声音/音频内容引起的或与之相关)来获得回声消除噪声估计。这样,可以说通过从麦克风输出信号中消除由声音引起的或与之相关的回声(或者换言之,由回放信号的音频内容引起的或与之相关的回声)来获得回声消除噪声估计(回声消除噪声估计值)。这可以在频域中完成。
[0072]
由回声消除器34采用以生成回声消除噪声估计值的每个自适应滤波器(即,由回声消除器34实施的、对应于图2的滤波器w
’
的每个自适应滤波器)的滤波器系数在带划分元件36中进行带划分。从元件36向子系统43提供经带划分的滤波器系数,以供子系统43使用来生成供子系统37使用的增益值g。
[0073]
可选地,回声消除器34被省略(或不进行操作),并且因此不向带划分元件36提供自适应滤波器值,并且不从36向子系统43提供经带划分的自适应滤波器值。在这种情况下,子系统43在不使用经带划分的自适应滤波器值的情况下以(下述)方式之一生成增益值g。
[0074]
如果使用回声消除器(即,如果图4的系统包括并使用如图4所示的元件34和35),则对从回声消除器34输出的残差值进行带划分(例如,在图4的子系统35中)以产生经带划分的噪声估计值m
’
res。将(由子系统43生成的)校准增益g施加(例如,通过图3的增益级12)于值m
’
res(即,增益g包括一组特定于带的增益,针对每个带一个增益,并且将特定于带的增益中的每个增益施加到对应的带中的值m
’
res),以使(由值m
’
res指示的)信号进入到与(由值“s”指示的)回放信号相同的水平域中。对于每个频带,使用校准增益g(通过图3的增益级12施加)来调整值m
’
res中的对应值的水平,以产生经调整的值mres(即,图3的值mres中的一个值)。
[0075]
如果未使用回声消除器(即,如果回声消除器34被省略或不进行操作),则将(在图3和图4的本文的描述中的)值m
’
res替换为值m
’
。在这种情况下,将经带划分的值m
’
(来自元件33)断言为增益级12的输入(代替图3所示的值m
’
res)以及增益级11的输入。(通过图3的增益级12)将增益g施加于值m
’
以生成经调整的值m,并且由子系统20(利用间隙置信度值)以与经调整的值mres相同的方式(并且代替经调整的值mres)来处理经调整的值m(而不是如图3所示的经调整的值mres),以生成噪声估计。
[0076]
在典型的实施方式中(包括图3所示的实施方式),噪声估计生成子系统37被配置为对回放内容值s执行最小值跟随,以在噪声估计值m
’
res的经调整的版本(mres)中定位(即,由经调整的版本确定)间隙。优选地,这以将参考图3描述的方式来实施。
[0077]
在图3所示的实施方式中,子系统37包括一对最小值跟随器(13和14),该对最小值跟随器中的两个最小值跟随器以相同大小的分析窗口来操作。最小值跟随器13被耦接并被配置为在值s上运行以产生指示值s(在每个分析窗口中)的最小值的值s
min
。最小值跟随器14被耦接并被配置为在值mres上运行以产生指示值mres(在每个分析窗口中)的最小值的值m
resmin
。发明人已经认识到,由于在回放内容中的间隙中值s、m和mres至少是大致地时间对准(由回放内容值s与麦克风输出值m的比较指示),因此:
[0078]
可以确信地认为值mres(回声消除器残差)中的最小值指示对回放环境中的噪声的估计;并且
[0079]
可以确信地认为值m(麦克风输出信号)中的最小值指示对回放环境中的噪声的估计。
[0080]
发明人还已经认识到,在除回放内容中的间隙期间之外的时间处,值mres(或值m)中的最小值可能不指示对回放环境中的噪声的准确估计。
[0081]
响应于麦克风输出信号(m)和s
min
的值,子系统16生成间隙置信度值。样本聚合器子系统20被配置为使用m
resmin
的值(或者,在没有执行回声消除的情况下,使用m的值)作为候选噪声估计,并且使用(由子系统16生成的)间隙置信度值作为对候选噪声估计的可靠性的指示。
[0082]
更具体地,图3的样本聚合器子系统20进行操作以将候选噪声估计(m
resmin
)以通过间隙置信度值(该间隙置信度值已在子系统16中生成)加权的方式组合在一起,以为每个分析窗口(即,聚合器20的分析窗口,具有如图3所指示的长度τ2)产生最终噪声估计,其中,对与指示低间隙置信度的间隙置信度值对应的加权候选噪声估计未赋值权重,或者比与指示高间隙置信度的间隙置信度值对应的加权候选噪声估计赋值较少的权重。因此,子系统20使用间隙置信度值来输出一系列噪声估计(一组当前噪声估计,包括针对每个分析窗口、针对每个频带一个噪声估计)。
[0083]
子系统20的一个简单示例是(间隙置信度加权样本的)最小值跟随器,例如,只有在相关联的间隙置信度高于预定阈值时才在分析窗口中包括候选样本(m
resmin
的值)的最小值跟随器(即,如果样本的间隙置信度等于或大于阈值,则子系统20对样本m
resmin
赋值权重一,并且如果样本的间隙置信度小于阈值,则子系统20对样本m
resmin
赋值权重零)。子系统20的其他实施方式以其他方式聚合(例如,确定其平均值或以其他方式聚合)间隙置信度加权样本(m
resmin
的值,每个m
resmin
的值在分析窗口中通过间隙置信度值中的对应的间隙置信度值来加权)。聚合间隙置信度加权样本的子系统20的示例性实施方式是(或者包括)线性插
值器/单极平滑器,该线性插值器/单极平滑器具有由间隙置信度值控制的更新速率。
[0084]
子系统20可以在输入样本(m
resmin
的值)低于当前噪声估计(由子系统20确定)时的时间处采用忽略间隙置信度的策略,以便即使没有可用的间隙也跟踪噪声条件中的下降。
[0085]
优选地,子系统20被配置为在低间隙置信度的间隔期间有效地保持噪声估计,直到由间隙置信度确定的新的采样时机出现为止。例如,在子系统20的优选实施方式中,当子系统20确定当前噪声估计(在一个分析窗口中)并且然后,(由子系统16生成的)间隙置信度值指示回放内容中存在间隙的低置信度(例如,间隙置信度值指示低于预定阈值的间隙置信度)时,子系统20继续输出该当前噪声估计,直到(在新的分析窗口中)间隙置信度值指示回放内容中存在间隙的较高置信度(例如,间隙置信度值指示高于阈值的间隙置信度)为止,在该时间处,子系统20生成(并输出)更新的噪声估计。根据本发明的优选实施例,通过这样使用间隙置信度值来生成噪声估计(包括通过在低间隙置信度的间隔期间保持噪声估计,直到由间隙置信度确定的新的采样时机出现为止),而不是仅依赖于从最小值跟随器14输出的候选噪声估计值作为一系列噪声估计(不进行确定和使用间隙置信度值)或以其他方式以传统方式生成噪声估计,所有采用的最小值跟随器分析窗口的长度(即,最小值跟随器13和14中的每个最小值跟随器的分析窗口长度τ1,以及在聚合器20被实施为间隙置信度加权样本的最小值跟随器时聚合器20的分析窗口长度τ2)可以比传统方法减少大约一个数量级,从而提高了当确实出现间隙时噪声估计系统可以跟踪噪声条件的速度。下面给出了分析窗口大小的典型默认值。
[0086]
在一类实施方式中,样本聚合器20被配置为不仅向前报告(即输出)当前噪声估计,而且还向前报告在每个频带中噪声估计有多新的指示(在本文中被称为“间隙健康(gap health)”)。在典型的实施方式中,间隙健康是无单位的测量,(在一种典型的实施方式中)被计算为:
[0087][0088]
其中,n是整数,索引i的范围从1到n,并且gapconfidence
i
值是由子系统16提供给样本聚合器20的最近的n个间隙置信度值。通常,为每个频带确定间隙健康值(例如,值gh),子系统16为最小值跟随器13的每个分析窗口生成(并向聚合器20提供)一组间隙置信度值(针对每个频带一个间隙置信度值)(以便在gh的上述示例中的n个最近的间隙置信度值是针对相关带的n个最近的间隙置信度值)。
[0089]
在一类实施方式中,间隙置信度子系统16被配置为处理(从最小值跟随器13输出的)s
min
值和(从增益级11输出的)m值的平滑版本(即,从子系统16的平滑子系统17输出的平滑值m
smoothed
),例如,通过比较s
min
值与m
smoothed
值,以便生成一系列间隙置信度值。通常,子系统16为最小值跟随器13的每个分析窗口生成(并向聚合器20提供)一组间隙置信度值(针对每个频带一个间隙置信度值),并且本文的描述涉及(从针对带的值s
min
和m
smoothed
)为特定频带生成间隙置信度值。
[0090]
每个间隙置信度值(在一个时间处针对一个频带)指示m
resmin
值中的对应值(即针对相同带和相同时间的m
resmin
值)如何指示回放环境中的噪声条件。由最小值跟随器14(其对mres值进行操作)(在回放内容中的间隙期间)识别的每个最小值(m
resmin
)可以被确信地认为指示回放环境中的噪声条件。当在回放内容中不存在间隙时,则由最小值跟随器14(其
对mres值进行操作)识别的最小值(m
resmin
)不能被确信地认为指示回放环境中的噪声条件,因为该最小值可能替代地指示回放信号(s)中的最小值(s
min
)。
[0091]
子系统16通常被实施为生成指示在时间t处s
min
与由麦克风检测到的平滑(平均)水平(m
smoothed
)的差异程度的每个间隙置信度值(针对时间t的值gapconfidence)。s
min
距由麦克风检测到的平滑(平均)水平(m
smoothed
)越远,在时间t处在回放内容中存在间隙的置信度越大,并且因此,值m
resmin
表示回放环境中的噪声条件(在时间t处)的置信度越大。
[0092]
针对每个频带,每个间隙置信度值(即,例如针对最小值跟随器13的每个分析窗口,针对每个时间t的间隙置信度值)的计算是基于在时间t处的最小值跟随回放内容能量水平s
min
和在同一时间t处的平滑麦克风能量水平m
smoothed
的。在优选实施例中,从子系统16输出的每个间隙置信度值是与以下项成比例的无单位值:
[0093][0094]
其中*表示乘法,所有能量值(s
min
和m
smoothed
)在线性域中,并且δ和c是调节参数。通常,c的值与由对麦克风输出进行操作的回声消除器(例如,图4的元件34)提供的回声消除的量相关联。如果未采用回声消除器,则c的值为一。如果使用回声消除器,则可以使用对消除深度的估计来确定c。
[0095]
δ的值设置回放内容的观察到的最小值与平滑麦克风水平之间的所需距离。该参数权衡误差和稳定性与系统的更新速率,并且将取决于噪声补偿增益的积极程度。
[0096]
使用m
smoothed
作为比较的点意味着在给定当前条件的情况下,当前间隙置信度值考虑在噪声的估计中产生误差的严重性。通常,如果选择足够大的δ,则噪声估计器的操作将利用以下场景。对于固定的s
min
的值,增大的m
smoothed
的值隐含间隙置信度应增大。如果m
smoothed
由于实际噪声条件显著增大而增大,则由于误差将相对于噪声条件的大小较小,因此可以在噪声估计中允许更多的由残留回声引起的误差。如果m
smoothed
由于回放内容的水平增大而增大,则任何误差在噪声估计中产生的影响也会减小,因为噪声补偿器将不会执行很多补偿。对于固定的s
min
的值,降低的m
smoothed
的值隐含间隙置信度应降低。在这种情况下,通过麦克风输出信号中的残留回声引入的任何误差将对补偿体验产生重大影响,因为该误差将相对于回放内容将很大。因此,在这些条件下,噪声估计器在计算间隙置信度时更为保守是合适的。
[0097]
在大量采用回声消除(“aec”)的应用中,在产生误差的成本较低的情况下,可以放宽(降低)δ,以使得(从子系统20输出的)噪声估计指示更频繁的间隙。在无aec的应用中,可以增大δ,以便使(从子系统20输出的)噪声估计仅指示更高质量的间隙。
[0098]
下表是本发明的噪声估计器的图3的实施方式的调节参数的总结(其中,表的右侧的两列指示在采用回声消除(“aec”)的情况下和不采用回声消除的情况下,调节参数(δ、c和最小值跟随器13和14的分析窗口长度τ1以及样本聚合器20的分析窗口长度τ2,其中聚合器20被实施为间隙置信度加权样本的最小值跟随器)的典型默认值):
[0099][0100]
调节参数中的所有调节参数会影响系统的更新速率,这与系统的噪声估计的准确性保持平衡。通常,只要稳定性维持,则存在一些误差的较快响应的系统优于依赖于高质量的间隙的保守的、较慢响应的系统。
[0101]
所描述的用于计算间隙置信度(例如,图3的子系统16的输出)的方法不同于尝试计算当前信噪比(snr),即回声水平与当前噪声水平的比率。通常,任何依赖于当前噪声估计的间隙置信度计算都将无法工作,因为只要存在噪声条件的变化,该间隙置信度计算将要么过于自由地采样,要么过于保守地采样。尽管了解当前的snr可能是确定间隙置信度的最佳方式(在学术意义上),但这将需要噪声条件的知识(正是噪声估计器正在尝试确定的事情),从而导致了在实际中无法工作的循环依赖性。
[0102]
再次参考图4,我们更详细地描述了根据本发明的典型实施例的噪声估计系统的实施方式(图4所示)的附加元件。如上所述,使用由噪声估计器子系统37(如上所述,如图3中所实施的)产生的噪声估计频谱(通过子系统24)对回放内容23执行噪声补偿。在回放环境(环境28)中,噪声补偿回放内容25通过扬声器系统29播放给收听者(例如,收听者31)。在与收听者相同的声学环境(环境28)中的麦克风30接收环境(周围)噪声和回放内容(回声)两者。
[0103]
噪声补偿回放内容25被变换(在元件26中),并且被下降混合和频率带划分(在元件27中)以产生值s。麦克风输出信号被变换(在元件32中)并被带划分(在元件33中)以产生值m
’
。如果采用回声消除器(34),则来自回声消除器的残留信号(回声消除噪声估计值)被带划分(在元件35中)以产生值mres
’
。
[0104]
子系统43根据麦克风到数字的映射来确定(针对每个频带的)校准增益g,该麦克风到数字的映射捕获每个频带在数字域中的在点处(在该点处回放内容被分接并提供给噪声估计器)的回放内容(例如,时频域变换元件26的输出)与由麦克风接收到的回放内容之间的水平差。增益g的每组当前值从子系统43提供给噪声估计器37(以由噪声估计器37的图3的实施方式的增益级11和12来施加)。
[0105]
子系统43可以访问以下三个数据源中的至少一个:
[0106]
出厂预设增益(存储在存储器40中);
[0107]
在先前的会话期间(由子系统43)生成(并存储在存储器41中)的增益g的状态;
[0108]
在存在并使用aec(例如,回声消除器34)的情况下经带划分的aec滤波器系数能量(例如,确定由回声消除器实施的对应于图2的滤波器w
’
的自适应滤波器的那些aec滤波器系数能量)。这些经带划分的aec滤波器系数能量(例如,在图4的系统中从带划分元件36提供到子系统43的那些aec滤波器系数能量)用作增益g的在线估计。
[0109]
如果不采用aec(例如,如果采用图4的系统的不包括回声消除器34的版本),则子系统43从存储器40或41中的增益值生成校准增益g。
[0110]
因此,在一些实施例中,子系统43被配置为使得图4的系统通过确定由子系统37施加到回放信号、麦克风输出信号和回声消除残差值的校准增益(例如,根据从带划分元件36提供的经带划分的aec滤波器系数能量)以实施噪声估计来执行自校准。
[0111]
再次参考图4,可选地(在子系统39中)对由噪声估计器37产生的一系列噪声估计进行后处理,包括通过对该系列噪声估计执行以下中的一个或多个操作:
[0112]
从部分更新的噪声估计估算缺失的噪声估计值;
[0113]
限制当前噪声估计的形状以保持音质;以及
[0114]
限制当前噪声估计的绝对值。
[0115]
由子系统43执行的用于确定增益值g的麦克风到数字的映射捕获(每个频带)在数字域中的在点处(在该点处回放内容被分接并提供给噪声估计器)的回放内容(例如,时频域变换元件26的输出)与由麦克风接收到的回放内容之间的水平差。映射主要由扬声器系统和麦克风的物理分离和特性以及在声音的再现和麦克风信号放大中使用的电放大增益来确定。
[0116]
在最基本的情况下,麦克风到数字的映射可以是在对设备的样本生产设计期间进行测量,并且重新用于所有正在生产的这种设备的预存储的出厂调节。
[0117]
当使用aec(例如,图4的回声消除器34)时,可以对麦克风到数字的映射进行更复杂的控制。可以通过采用(由回声消除器确定的)自适应滤波器系数的大小并将自适应滤波器系数带划分在一起,来确定对增益g的在线估计。对于足够稳定的回声消除器设计,以及在对估计的增益(g
’
)进行足够的平滑的情况下,此在线估计可以与离线的预先准备的出厂校准一样好。这使得可以使用估计的增益g
’
来代替出厂调节。计算估计的增益g
’
的另一个益处是,可以测量并考虑每个设备与出厂默认值的任何偏差。
[0118]
虽然估计的增益g
’
可以取代出厂确定的增益,但用于确定针对每个带的增益g的鲁棒方法(该方法将出厂增益和在线估计的增益g
’
结合在一起)如下:
[0119]
g=max(min(g',f+l),f-l)
[0120]
其中,f是针对带的出厂增益,g
’
是针对带的估计的增益,并且l是与出厂设置的最大允许偏差。所有增益以db为单位。如果值g
’
长时间段超出指示的范围,则可以指示硬件故障,并且噪声补偿系统可以决定退回到安全行为。
[0121]
可以使用对根据本发明的实施例生成(例如,通过图4的系统的元件37)的一系列噪声估计执行(例如,通过图4的系统的元件39)后处理步骤来维持较高质量的噪声补偿体验。例如,迫使噪声频谱符合特定形状以便移除峰值的后处理可以帮助防止补偿增益以不
愉快的方式使回放内容的音质失真。
[0122]
本发明的噪声估计方法和系统的一些实施例的重要方面是后处理(例如,由图4的系统的元件39的实施方式执行),例如,实施估算策略以更新(针对一些频带的)由于回放内容中缺少间隙而已经过时的旧噪声估计的后处理,尽管已经对针对其他带的噪声估计进行了足够的更新。
[0123]
在一些这种实施例中,由噪声估计器报告的间隙健康(例如,由本发明的噪声估计器的图3的实施方式的子系统20生成的针对每个频带的间隙健康值,例如,如上所述)确定(当前噪声估计的)哪些带是“过时”或“最新”的。采用(由噪声估计器37针对每个频带生成的)间隙健康值来估算噪声估计值的示例性方法(由图4的系统的元件39的实施方式执行)包括以下步骤:
[0124]
从第一个带开始,通过检查针对该带的间隙健康是否高于预定阈值α
healthy
,定位足够最新的带(健康带);
[0125]
一旦找到健康带,检查后续带以获得由不同的阈值α
stale
确定的低间隙健康,并再次检查后续带以获得由阈值α
healthy
确定的最新带;
[0126]
如果找到第二个健康带,并且第二个健康带与第一个健康带之间的所有带都是过时的,则在两个健康带之间执行线性插值操作以生成至少一个插值噪声估计。在两个健康带之间的对数域中对(针对两个健康带之间的所有带的)噪声估计进行线性插值,从而为过时的带提供新的值;并且然后,
[0127]
从下一个带开始,继续该过程(即,从第一步骤重复该过程)。
[0128]
在足够数量的间隙恒定可用并且带很少过时的实施例中,过时值估算可以不是必需的。下表给出了用于简单估算算法的默认阈值:
[0129]
参数:默认值α
healthy
0.5α
stale
0.3
[0130]
当然,对间隙健康和噪声估计值进行操作的其他方法是可能的。
[0131]
在一些实施例中,图4的系统的元件39被实施为当在生成背景噪声估计中采用回声消除(aec)时,例如使用由噪声估计器37针对每个频带生成的间隙健康值来执行自动检测系统故障(例如,硬件故障)。
[0132]
根据如本文所公开的本发明的典型实施例的间隙置信度确定(和使用所确定的间隙置信度数据来执行噪声估计)能够(利用使用间隙置信度值来确定的噪声估计)实现跨媒体回放场景中遇到的音频类型的范围的可行的噪声补偿体验,而不需要回声消除器。根据本发明的一些实施例,包括回声消除器以执行间隙置信度确定可以(利用使用所确定的间隙置信度数据来确定的噪声估计)改善噪声补偿的响应性,从而移除了对回放内容特性的依赖性。间隙置信度确定的典型实施方式以及使用所确定的间隙置信度数据来执行噪声估计降低了对回声消除器(也用于执行噪声估计)的要求以及优化和测试中所涉及的大量精力。
[0133]
从噪声补偿系统移除回声消除器:
[0134]
由于回声消除器需要大量的时间和研究来调节以确保消除性能和稳定性,因此节省了大量的开发时间,;
[0135]
由于(用于实施回声消除的)大型自适应滤波器组通常消耗大量资源,并且经常需要高精度算法来运行,因此节省了计算时间;并且
[0136]
移除了对麦克风信号与回放音频信号之间的共享时钟域和时间校准的需要。回声消除依赖于待在同一音频时钟上同步的回放信号和记录信号。
[0137]
(例如,在没有回声消除的情况下,根据本发明的典型实施例中的任何典型实施例实施的)噪声估计器可以以增加的块比率/较小的fft大小来运行,以进一步节省复杂性。在频域中执行的回声消除通常需要窄频率分辨率。
[0138]
根据本发明的典型实施例,当使用回声消除(和间隙置信度确定)来生成噪声估计时,可以(在用户收听使用根据本发明的典型实施例生成的噪声估计来实施的噪声补偿回放内容时)在不损害用户体验的情况下减小回声消除器性能,因为回声消除器仅需要执行足够的消除以揭示回放内容中的间隙,并且不需要为回放内容峰值维持高erle(“erle”在这里表示回声回波损耗增强,即,对由回声消除器移除了多少回声(以db为单位)的测量)。
[0139]
本发明方法的示例性实施例包括以下内容:
[0140]
e1.一种方法,包括以下步骤:
[0141]
在回放环境中发出声音期间,使用麦克风来生成麦克风输出信号,其中,所述声音指示回放信号的音频内容,并且所述麦克风输出信号指示所述回放环境中的背景噪声和所述音频内容;
[0142]
响应于所述麦克风输出信号和所述回放信号,(例如,在图3的系统的元件16中)生成间隙置信度值,其中,所述间隙置信度值中的每个间隙置信度值是针对不同的时间t的,并且指示在所述回放信号中在所述时间t处存在间隙的置信度;以及
[0143]
使用所述间隙置信度值来(例如,在图3的系统的元件20中)生成对所述回放环境中的所述背景噪声的估计。
[0144]
e2.如e1所述的方法,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,所述噪声估计中的每个噪声估计是对在不同的时间t处所述回放环境中的背景噪声的估计,并且所述噪声估计中的所述每个噪声估计(例如,从图3的系统的作为图4的元件37的实施方式的元件20输出的每个噪声估计)是已通过针对包括所述时间t的不同时间间隔的所述间隙置信度值进行加权的候选噪声估计的组合。
[0145]
e3.如e2所述的方法,其中,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且生成针对每个所述时间间隔的所述噪声估计包括以下步骤:
[0146]
(a)(例如,在图3的系统的元件20中)识别针对所述时间间隔的所述候选噪声估计中的每个候选噪声估计,针对所述时间间隔,所述间隙置信度值中的对应的一个间隙置信度值超过预定阈值;以及
[0147]
(b)生成针对所述时间间隔的所述噪声估计作为步骤(a)中所识别的所述候选噪声估计中的最小的一个候选噪声估计。
[0148]
e4.如e2所述的方法,其中,所述候选噪声估计中的每个候选噪声估计是一系列回声消除噪声估计中的最小回声消除噪声估计(例如,从图3的系统的元件14输出的值之一m
resmin
),所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小回声消除噪声估计的组合,所述最小回声消除噪声估计通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信
度值进行加权。
[0149]
e5.如e2所述的方法,其中,所述候选噪声估计中的每个候选噪声估计是一系列麦克风输出信号值中的最小麦克风输出信号值(例如,在系统的元件12接收麦克风输出值m
’
而不是值m
’
res的实施方式中,从图3的系统的元件14输出的值m
min
),所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小麦克风输出信号值的组合,所述最小麦克风输出信号值通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0150]
e6.如e1所述的方法,其中,生成所述间隙置信度值的步骤包括:包括通过以下操作来生成针对每个时间t的间隙置信度值:
[0151]
(例如,在图3的系统的元件13中)处理所述回放信号以确定针对所述时间t的回放信号水平中的最小值;
[0152]
(例如,在图3的系统的元件11和17中)处理所述麦克风输出信号以确定针对所述时间t的所述麦克风输出信号的平滑水平;以及
[0153]
(例如,在图3的系统的元件18中)确定针对所述时间t的所述间隙置信度值,以指示针对所述时间t的回放信号水平中的所述最小值与针对所述时间t的所述麦克风输出信号的所述平滑水平的差异程度。
[0154]
e7.如e1所述的方法,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,并且还包括以下步骤:
[0155]
使用所述一系列噪声估计,(例如,在图4的系统的元件24中)对音频输入信号执行噪声补偿。
[0156]
e8.如e7所述的方法,其中,对所述音频输入信号执行噪声补偿的步骤包括生成所述回放信号,并且其中,所述方法包括以下步骤:
[0157]
利用所述回放信号驱动至少一个扬声器以生成所述声音。
[0158]
e9.如e1所述的方法,包括以下步骤:
[0159]
对所述麦克风输出信号执行时域到频域变换,从而生成频域麦克风输出数据;以及
[0160]
响应于所述回放信号生成频域回放内容数据,并且其中,所述间隙置信度值响应于所述频域麦克风输出数据和所述频域回放内容数据而生成。
[0161]
本发明系统的示例性实施例包括以下内容:
[0162]
e10.一种系统,包括:
[0163]
麦克风(例如,图4的麦克风30),所述麦克风被配置为在回放环境中发出声音期间生成麦克风输出信号,其中,所述声音指示回放信号的音频内容,并且所述麦克风输出信号指示所述回放环境中的背景噪声和所述音频内容;以及
[0164]
噪声估计系统(例如,图4的系统的元件26、27、32、33、34、35、36、37、39和43),所述噪声估计系统被耦接为接收所述麦克风输出信号和所述回放信号,并且被配置为:
[0165]
响应于所述麦克风输出信号和所述回放信号,生成间隙置信度值,其中,所述间隙置信度值中的每个间隙置信度值是针对不同的时间t的,并且指示在所述回放信号中在所述时间t处存在间隙的置信度;以及
[0166]
使用所述间隙置信度值来生成对所述回放环境中的所述背景噪声的估计。
[0167]
e11.如e10所述的系统,其中,所述噪声估计系统被配置为生成对所述回放环境中的所述背景噪声的估计,使得对所述回放环境中的所述背景噪声的所述估计是或者包括一系列噪声估计,所述噪声估计中的每个噪声估计是对在不同的时间t处所述回放环境中的背景噪声的估计,并且所述噪声估计中的所述每个噪声估计(例如,从图4的元件37的图3的实施方式的元件20输出的每个噪声估计)是已通过针对包括所述时间t的不同时间间隔的所述间隙置信度值进行加权的候选噪声估计的组合。
[0168]
e12.如e11所述的系统,其中,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且所述噪声估计系统被配置为包括通过以下操作来生成针对每个所述时间间隔的所述噪声估计:
[0169]
(a)(例如,在图3的元件20中)识别针对所述时间间隔的所述候选噪声估计中的每个候选噪声估计,针对所述时间间隔,所述间隙置信度值中的对应的一个间隙置信度值超过预定阈值;以及
[0170]
(b)生成针对所述时间间隔的所述噪声估计作为步骤(a)中所识别的所述候选噪声估计中的最小的一个候选噪声估计。
[0171]
e13.如e12所述的系统,其中,所述候选噪声估计中的每个候选噪声估计是一系列回声消除噪声估计中的最小回声消除噪声估计(例如,从图3的系统的元件14输出的值之一m
resmin
),所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小回声消除噪声估计的组合,所述最小回声消除噪声估计通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0172]
e14.如e12所述的系统,其中,所述候选噪声估计中的每个候选噪声估计是一系列麦克风输出信号值中的最小麦克风输出信号值(例如,在系统的元件12接收麦克风输出值m
’
而不是值m
’
res的实施方式中,从图3的系统的元件14输出的值m
min
),所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小麦克风输出信号值的组合,所述最小麦克风输出信号值通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0173]
e15.如e10所述的系统,其中,所述间隙置信度值包括针对每个时间t的间隙置信度值,并且所述噪声估计系统被配置为包括通过以下操作来生成针对每个时间t的所述间隙置信度值:
[0174]
(例如,在图4的系统的元件37的图3的实施方式的元件13中)处理所述回放信号以确定针对所述时间t的回放信号水平中的最小值;
[0175]
(例如,在图4的系统的元件37的图3的实施方式的元件11和17中)处理所述麦克风输出信号以确定针对所述时间t的所述麦克风输出信号的平滑水平;以及
[0176]
(例如,在图4的系统的元件37的图3的实施方式的元件18中)确定针对所述时间t的所述间隙置信度值,以指示针对所述时间t的回放信号水平中的所述最小值与针对所述时间t的所述麦克风输出信号的所述平滑水平的差异程度。
[0177]
e16.如e10所述的系统,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,所述系统还包括:
[0178]
噪声补偿子系统(例如,图4的系统的元件24),所述噪声补偿子系统被耦接为接收
所述一系列噪声估计,并且被配置为使用所述一系列噪声估计对音频输入信号执行噪声补偿,以生成所述回放信号。
[0179]
e17.如e10所述的系统,其中,所述噪声估计系统被配置为:
[0180]
(例如,在图4的系统的元件32和33中)对所述麦克风输出信号执行时域到频域变换,从而生成频域麦克风输出数据;
[0181]
响应于所述回放信号,(例如,在图4的系统的元件26和27中)生成频域回放内容数据;以及
[0182]
响应于所述频域麦克风输出数据和所述频域回放内容数据,生成所述间隙置信度值。
[0183]
本发明的各方面包括一种被配置(例如,被编程)为执行本发明方法的任何实施例的系统或设备,以及一种存储用于实施本发明方法或其步骤的任何实施例的代码的有形计算机可读介质(例如,磁盘)。例如,本发明系统可以是或者包括可编程通用处理器、数字信号处理器或微处理器,该可编程通用处理器、数字信号处理器或微处理器利用软件或固件编程为和/或以其他方式被配置为对数据执行多种操作中的任何操作,包括本发明方法或其步骤的实施例。这种通用处理器可以是或者包括计算机系统,该计算机系统包括输入设备、存储器和处理子系统,该通用处理器被编程(和/或以其他方式被配置)为响应于向其断言的数据而执行本发明方法(或其步骤)的实施例。
[0184]
本发明系统的一些实施例(例如,图3的系统的一些实施方式,或者图4的系统的元件24、26、27、34、32、33、35、36、37、39和43的一些实施方式)被实施为可配置(例如,可编程)数字信号处理器(dsp),该数字信号处理器被配置(例如,被编程并以其他方式被配置)为对一个或多个音频信号执行所需的处理,包括执行本发明方法的实施例。
[0185]
可替代地,本发明系统的实施例(例如,图3的系统的一些实施方式,或者图4的系统的元件24、26、27、34、32、33、35、36、37、39和43的一些实施方式)被实施为通用处理器(例如,可以包括输入设备和存储器的个人计算机(pc)或其他计算机系统或微处理器),该通用处理器利用软件或固件被编程和/或以其他方式被配置为执行包括本发明方法的实施例的多种操作中的任何操作。可替代地,本发明系统的一些实施例的元件被实施为被配置(例如,被编程)为执行本发明方法的实施例的通用处理器或dsp,并且该系统还包括其他元件(例如,一个或多个扩音器和/或一个或多个麦克风)。被配置为执行本发明方法的实施例的通用处理器通常将通常耦接到输入设备(例如,鼠标和/或键盘)、存储器和显示设备。
[0186]
本发明的另一方面是一种计算机可读介质(例如,磁盘或其他有形存储介质),该计算机可读介质存储用于执行本发明方法或其步骤的任何实施例的代码(例如,可执行的用于执行本发明方法或其步骤的任何实施例的编码器)。
[0187]
虽然本文已描述了本发明的具体实施例和本发明的应用,但是对于本领域普通技术人员而言将显而易见的是,在不脱离本文所描述的并要求保护的发明的范围的情况下,对本文所描述的实施例和应用的许多变型是可能的。应当理解,虽然已经示出和描述了本发明的某些形式,但是本发明不限于所描述和示出的具体实施例或所描述的具体方法。
[0188]
可以从以下枚举的示例实施例(eee)来理解本发明的各方面:
[0189]
1.一种方法,包括以下步骤:
[0190]
在回放环境中发出声音期间,使用麦克风来生成麦克风输出信号,其中,所述声音
指示回放信号的音频内容,并且所述麦克风输出信号指示所述回放环境中的背景噪声和所述音频内容;
[0191]
响应于所述麦克风输出信号和所述回放信号,生成间隙置信度值,其中,所述间隙置信度值中的每个间隙置信度值是针对不同的时间t的,并且指示在所述回放信号中在所述时间t处存在间隙的置信度;以及
[0192]
使用所述间隙置信度值来生成对所述回放环境中的所述背景噪声的估计。
[0193]
2.如eee 1所述的方法,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,所述噪声估计中的每个噪声估计是对在不同的时间t处所述回放环境中的背景噪声的估计,并且所述噪声估计中的所述每个噪声估计是已由针对包括所述时间t的不同时间间隔的所述间隙置信度值进行加权的候选噪声估计的组合。
[0194]
3.如eee 2所述的方法,其中,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且生成针对每个所述时间间隔的所述噪声估计包括以下步骤:
[0195]
(a)识别针对所述时间间隔的所述候选噪声估计中的每个候选噪声估计,针对所述时间间隔,所述间隙置信度值中的对应的一个间隙置信度值超过预定阈值;以及
[0196]
(b)生成针对所述时间间隔的所述噪声估计作为步骤(a)中所识别的所述候选噪声估计中的最小的一个候选噪声估计。
[0197]
4.如eee 2或3所述的方法,其中,所述候选噪声估计中的每个候选噪声估计是一系列回声消除噪声估计中的最小回声消除噪声估计m
resmin
,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小回声消除噪声估计的组合,所述最小回声消除噪声估计通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0198]
5.如eee 2或3所述的方法,其中,所述候选噪声估计中的每个候选噪声估计是一系列麦克风输出信号值中的最小麦克风输出信号值m
min
,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小麦克风输出信号值的组合,所述最小麦克风输出信号值通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0199]
6.如eee 1、2、3、4或5所述的方法,其中,生成所述间隙置信度值的步骤包括:包括通过以下操作来生成针对每个时间t的间隙置信度值:
[0200]
处理所述回放信号以确定针对所述时间t的回放信号水平中的最小值;
[0201]
处理所述麦克风输出信号以确定针对所述时间t的所述麦克风输出信号的平滑水平;以及
[0202]
确定针对所述时间t的所述间隙置信度值,以指示针对所述时间t的回放信号水平中的所述最小值与针对所述时间t的所述麦克风输出信号的所述平滑水平的差异程度。
[0203]
7.如eee 1、2、3、4、5或6所述的方法,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,并且还包括以下步骤:
[0204]
使用所述一系列噪声估计对音频输入信号执行噪声补偿。
[0205]
8.如eee 7所述的方法,其中,对所述音频输入信号执行噪声补偿的步骤包括生成所述回放信号,并且其中,所述方法包括以下步骤:
[0206]
利用所述回放信号驱动至少一个扬声器以生成所述声音。
[0207]
9.如eee 1、2、3、4、5、6、7或8所述的方法,包括以下步骤:
[0208]
对所述麦克风输出信号执行时域到频域变换,从而生成频域麦克风输出数据;以及
[0209]
响应于所述回放信号生成频域回放内容数据,并且其中,所述间隙置信度值响应于所述频域麦克风输出数据和所述频域回放内容数据而生成。
[0210]
10.一种系统,包括:
[0211]
麦克风,所述麦克风被配置为在回放环境中发出声音期间生成麦克风输出信号,其中,所述声音指示回放信号的音频内容,并且所述麦克风输出信号指示所述回放环境中的背景噪声和所述音频内容;以及
[0212]
噪声估计系统,所述噪声估计系统被耦接为接收所述麦克风输出信号和所述回放信号,并且被配置为:
[0213]
响应于所述麦克风输出信号和所述回放信号,生成间隙置信度值,其中,所述间隙置信度值中的每个间隙置信度值是针对不同的时间t的,并且指示在所述回放信号中在所述时间t处存在间隙的置信度;以及
[0214]
使用所述间隙置信度值来生成对所述回放环境中的所述背景噪声的估计。
[0215]
11.如eee 10所述的系统,其中,所述噪声估计系统被配置为生成对所述回放环境中的所述背景噪声的估计,使得对所述回放环境中的所述背景噪声的所述估计是或者包括一系列噪声估计,所述噪声估计中的每个噪声估计是对在不同的时间t处所述回放环境中的背景噪声的估计,并且所述噪声估计中的所述每个噪声估计是已通过针对包括所述时间t的不同时间间隔的所述间隙置信度值进行加权的候选噪声估计的组合。
[0216]
12.如eee 11所述的系统,其中,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且所述噪声估计系统被配置为包括通过以下操作来生成针对每个所述时间间隔的噪声估计:
[0217]
(a)识别针对所述时间间隔的所述候选噪声估计中的每个候选噪声估计,针对所述时间间隔,所述间隙置信度值中的对应的一个间隙置信度值超过预定阈值;以及
[0218]
(b)生成针对所述时间间隔的所述噪声估计作为步骤(a)中所识别的所述候选噪声估计中的最小的一个候选噪声估计。
[0219]
13.如eee 11或12所述的系统,其中,所述候选噪声估计中的每个候选噪声估计是一系列回声消除噪声估计中的最小回声消除噪声估计m
resmin
,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小回声消除噪声估计的组合,所述最小回声消除噪声估计通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0220]
14.如eee 11或12所述的系统,其中,所述候选噪声估计中的每个候选噪声估计是一系列麦克风输出信号值中的最小麦克风输出信号值m
min
,所述一系列噪声估计包括针对每个所述时间间隔的噪声估计,并且针对每个所述时间间隔的所述噪声估计是针对所述时间间隔的所述最小麦克风输出信号值的组合,所述最小麦克风输出信号值通过针对所述时间间隔的所述间隙置信度值中的对应的间隙置信度值进行加权。
[0221]
15.如eee 10、11、12、13或14所述的系统,其中,所述间隙置信度值包括针对每个时间t的间隙置信度值,并且所述噪声估计系统被配置为包括通过以下操作来生成针对每
个时间t的所述间隙置信度值:
[0222]
处理所述回放信号以确定针对所述时间t的回放信号水平中最小值;
[0223]
处理所述麦克风输出信号以确定针对所述时间t的所述麦克风输出信号的平滑水平;以及
[0224]
确定针对所述时间t的所述间隙置信度值,以指示针对所述时间t的回放信号水平中的所述最小值与针对所述时间t的所述麦克风输出信号的平滑水平的差异程度。
[0225]
16.如eee 10、11、12、13、14或15所述的系统,其中,对所述回放环境中的所述背景噪声的估计是或者包括一系列噪声估计,所述系统还包括:
[0226]
噪声补偿子系统,所述噪声补偿子系统被耦接为接收所述一系列噪声估计,并且被配置为使用所述一系列噪声估计对音频输入信号执行噪声补偿,以生成所述回放信号。
[0227]
17.如eee 10、11、12、13、14、15或16所述的系统,其中,所述噪声估计系统被配置为:
[0228]
对所述麦克风输出信号执行时域到频域变换,从而生成频域麦克风输出数据;
[0229]
响应于所述回放信号,生成频域回放内容数据;以及
[0230]
响应于所述频域麦克风输出数据和所述频域回放内容数据,生成所述间隙置信度值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1