自动确定经由自动助理界面接收到的口头话语的语音识别的语言的制作方法
自动确定经由自动助理界面接收到的口头话语的语音识别的语言
背景技术:
[0001]
人类可以参与与在本文中称为“自动助理”(也称为“数字代理”、“聊天机器人”、“交互式个人助理”、“智能个人助理”、“助理应用”、“谈话代理”等)的交互式软件应用的人机对话。例如,人类(其在他们与自动助理交互时可以被称为“用户”)可以使用在一些情况下可以被转换成文本然后被处理的口头自然语言输入(即,话语)和/或通过提供文本(例如,键入的)自然语言输入来向自动助理提供命令和/或请求。自动助理通过提供响应用户界面输出来对请求做出响应,该响应用户界面输出能够包括可听的用户界面输出和/或可视的用户界面输出。
[0002]
如在上文所提及的,自动助理可以将与用户的口头话语相对应的音频数据转换成对应的文本(或其它语义表示)。例如,可以基于经由客户端设备的一个或多个麦克风对用户的口头话语的检测来生成音频数据,该客户端设备包括用于使用户能够与自动助理进行交互的助理界面。自动助理可以包括语音识别引擎,该语音识别引擎尝试识别在音频数据中捕获的口头话语的各种特性,诸如由口头话语产生的声音(例如,音素)、所产生的声音的顺序、语音的节奏、语调等等。此外,语音识别引擎可以标识由此类特性表示的文本单词或短语。然后,该文本可以由自动助理进一步处理(例如,使用自然语言理解(nlu)引擎和/或对话状态引擎),以确定针对口头话语的响应内容。语音识别引擎可以由客户端设备和/或通过一个或多个自动助理组件来实现,所述一个或多个自动助理组件可以远离客户端设备但与客户端设备进行网络通信。
[0003]
然而,许多语音识别引擎被配置成仅以单一语言识别语音。对于使用多种语言的用户和/或住户,这样的单语言语音识别引擎可能无法令人满意,并且当以不是通过语音识别引擎支持的单一语言的附加语言接收到口头话语时,可能导致自动助理失效和/或提供错误的输出。这可以渲染自动助理不可用和/或导致计算资源和/或网络资源的过度使用。计算资源和/或网络资源的过度使用可能是由于当自动助理失效或提供错误的输出时用户需要提供进一步的口头话语(即,以所支持的单一语言提供)。这种另外的口头话语必须由对应的客户端设备和/或一个或多个远程自动助理组件另外处理,从而引起各种资源的额外使用。
[0004]
其它语音识别引擎可以被配置成识别多种语言的语音,但是要求用户明确指定在给定时间内以语音识别应该利用多种语言中的哪一种。例如,其它语音识别引擎中的一些可能要求用户手动指定在特定客户端设备处接收到的所有口头话语的语音识别中要利用的默认语言。欲将默认语言更改为另一种语言,可能要求用户与图形界面和/或可听界面进行交互以显式更改默认语言。这样的交互可能导致界面的渲染、经由界面提供的用户输入的处理等中的计算资源和/或网络资源的过度使用。此外,经常可能是用户忘记在提供当前不是默认语言的口头话语之前改变默认语言的情况。如上所述,这可能使渲染自动助理不可用和/或导致计算资源和/或网络资源的过度使用。
技术实现要素:
[0005]
本文所述的实施方式涉及用于自动确定用于经由自动助理界面接收到的口头话语的语音识别的语言的系统、方法和装置。本文所述的一些实施方式涉及标识用户请求的语言、使用所述语言处理请求、和/或以所述语言提供响应。在各种实施方式中,由第一用户向自动助理提交的请求可以是第一语言。处理此类请求可能需要自动助理确定第一个用户正在讲的是哪种语言。另外,第一用户可能优选自动助理也以第一语言提供其答复。可以以与第一语言不同的一种或多种另外的语言来重复相同的场景,并且可以由第一用户或由一个或多个另外的用户讲出。本文描述标识用户请求的语言、使用该语言处理请求和/或以该语言答复请求的技术。
[0006]
为了标识用户请求的语言,自动助理可以向多个机器学习模型提供指示用户请求的音频记录的数据(例如,音频记录本身、降维嵌入等),所述多个机器学习模型被配置成生成语音到文本(“stt”)输出。每个机器学习模型可以被设计成以特定语言执行stt处理。为此,这些机器学习模型中的每一个机器学习模型可以分析用户请求的音频记录(或指示其的数据),以提供与模型的相应语言的音频记录的潜在含义相对应的多个候选短语或“假设”的文本数据。
[0007]
在各种实施方式中,可以确定应使用哪种模型,以及最终应使用哪种语言来处理请求和/或提供响应输出。在一些实施方式中,对于每个机器学习模型,可以计算熵得分,其中指示低熵的熵得分表示用户语言的良好候选,并且指示高熵的熵得分表示用户的语言的不良候选。如本文所使用的,熵得分通常是指多个候选stt短语之中的熵或多样性的水平。在一些实施方式中,熵得分可以基于与对应于特定语言的每个机器学习模型的每个候选短语和每个剩余的附加短语之间的平均和/或长度标准化的编辑距离。这可以基于任何两个给定短语之间的逐字符的差和/或逐单词的差来计算。另外或替代地,候选stt短语可以被嵌入到降维空间中,并且它们之间的语义距离可以例如基于欧几里得距离来计算。由该距离计算出的平均距离或一些其它值可以被用于确定针对该特定stt机器学习模型的熵得分。然后,自动助理可以基于每个模型的熵得分来选择目标语言。在一些实施方式中,自动助理可以进一步考虑其它因素,诸如针对各个候选短语的置信度得分、过去该助理已经使用的语言以及用户和该助理之间的交互场境(context),诸位位置。
[0008]
作为示例,假定dave和alice都希望使用自动助理。假定dave讲英语,而alice讲西班牙语。dave和alice希望轮流使用自动助理,并以他们的母语进行回复,而无需手动更改助理的设定。假定alice先来,并用西班牙语请求助理设置上午8:00的闹钟。助理将把她的请求(或指示器的其它数据)的音频记录馈送到多个机器学习模型中,以多种语言生成与她的请求相对应的候选短语,为所述各种语言模型中的每一个语言模型生成熵得分,并基于若干因素选择语言,所述因素包括基于具有最低熵得分的语言模型,在这种情况下其可能是西班牙语。然后,助理将以西班牙语处理alice的请求,并以西班牙语回复以告知她已设置了闹钟。接下来,dave可以用英语与助理交谈,并要求其调暗灯光。可能重复相同的过程,只是在这种情况下,具有最低熵得分的语言模型将会是英语,并且请求将被以英语处理,并且助理将以英语回复,以使dave知道灯光已变暗。
[0009]
本文所述的技术引起多种技术优势。通过处理用户请求以确定他们给出的语言使自动助理可以在多语言情况下(诸如多语言家庭或有国际旅行者的目的地)理解并响应,而
无需多个用户在助理的设置中手动切换助理的操作语言。这可以为用户节省时间,并且节省计算资源和手动切换助理的语言以与其通信所需的用户开销。
[0010]
在一些实施方式中,阐述了一种由一个或多个处理器实施的方法,该方法包括:在由用户操作以与自动助理进行接洽的计算设备的麦克风处接收来自用户的话音输入,其中,所述话音输入包括来自所述用户的请求;将指示所述话音输入的音频记录的数据作为输入应用于多个stt机器学习模型以生成多个候选语音识别输出,其中所述多个stt机器学习模型中的每个stt机器学习模型都以特定语言被训练;针对所述多个stt模型中的每个相应stt机器学习模型,分析所述多个候选语音识别输出以确定针对所述相应stt机器学习模型的熵得分;基于与所述多个stt机器学习模型相关联的熵得分,选择与所述多个stt机器学习模型中的至少一个stt机器学习模型相关联的所述语言作为目标语言;以及使所述自动助理使用所述目标语言来响应来自所述用户的请求。
[0011]
在各种实施方式中,可以基于所述相应stt模型的多个候选语音识别输出的计数来确定针对所述相应stt机器学习模型的熵得分。在各种实施方式中,可以基于所述相应stt模型的多个候选语音识别输出之间的差来确定针对所述相应stt机器学习模型的熵得分。在各种实施方式中,可以基于潜在空间中所述相应stt模型的多个候选语音识别输出之间的语义距离来确定针对所述相应stt机器学习模型的所述熵得分。
[0012]
在各种实施方式中,可以进一步基于下述内容中的一个或者多个来选择所述目标语言:所述计算设备的历史上下文、所述计算设备的当前上下文或为每个候选语音识别输出计算的置信度得分。在各种实施方式中,可以使用由所述相应stt机器学习模型生成的具有高于特定阈值的置信度得分的所述候选语音识别输出来计算针对每个相应的stt机器学习模型的所述熵得分。
[0013]
在各种实施方式中,所述方法进一步可以包括,如果针对所选择的stt机器学习模型的所述熵得分满足预先确定的阈值,则使所述自动助理在执行任何任务之前基于用户的请求提示用户进行确认。在各种实施方式中,所述使可以包括使所述自动助理提供对所述用户的请求的自然语言响应作为音频输出,其中所述自然语言响应以目标语言提供。
[0014]
在各种实施方式中,所述多个stt机器学习模型可以包括stt机器学习模型的超集的子集,并且所述方法可以进一步包括基于下述各项中的一个或多个从所述超集中选择所述子集:所述计算设备的历史上下文、所述计算设备的当前上下文或所述用户先前为所述自动助理设置的设定。
[0015]
其它实施方式可以包括一种非暂时性计算机可读存储介质,该非暂时性计算机可读存储介质存储指令,这些指令可由一个或多个处理器(例如,中央处理器(cpu)、图形处理单元(gpu)和/或张量处理单元(tpu))执行以执行诸如在下文描述和/或在本文中别处描述的方法中的一种或多种的方法。其它的实施方式仍然可以包括一个或多个计算机和/或一个或多个机器人的系统,所述一个或多个计算机和/或一个或多个机器人的系统包括一个或者多个处理器,所述一个或者多个处理器可操作来执行存储的指令以执行诸如在下文所描述的和/或在本文中别处描述的方法中的一种或多种的方法。
[0016]
应该领会,在本文中更详细地描述的前面的构思和附加构思的所有组合都被设想为是本文公开的主题的一部分。例如,在本公开结尾处出现的要求保护的主题的所有组合都被设想为是本文公开的主题的一部分。
附图说明
[0017]
图1图示用于选择用于自动助理与用户交互的语言的系统。
[0018]
图2图示根据各种实施方式的可以由自动助理实现的状态机。
[0019]
图3a和3b图示根据各种实施例的示例场景,其中可以采用本文所述的技术。
[0020]
图4描绘根据各种实施例的用于实践本公开的所选方面的示例方法。
[0021]
图5是示例计算机系统的框图。
具体实施方式
[0022]
图1图示用于选择用于自动助理104与用户130交互的语言的系统100。自动助理104可以部分经由在一个或多个客户端设备处提供的自动助理126,诸如客户端计算设备118(例如,便携式计算设备132),以及部分地经由一个或多个远程计算设备112,诸如服务器设备102(例如,可以形成通常被称为“云基础架构”或简称为“云”的一部分)操作。当在本文中使用“自动助理104”时,它可以指代104和126中的一个或指代这两者。用户130可以经由客户端计算设备118的助理界面128与自动助理104交互。助理界面128包括用户界面输入设备和用户界面输出设备,以用于由自动助理126在与用户130交互中使用。
[0023]
助理界面128接受指向自动助理104的用户130的用户界面输入,并渲染来自自动助理104的内容以呈现给用户130。助理界面128可以包括麦克风、扬声器、显示面板、相机、触摸屏显示器和/或客户端计算设备118的任何其它用户界面设备。助理界面128还可以包括显示器、投影仪、扬声器和/或客户端计算设备118的可以被用于渲染来自自动助理104的内容的任何其它用户界面输出设备。用户可以通过向助理界面128提供口头、文本或图形输入来使自动助理104执行功能(例如,提供数据、控制外围设备、访问代理等)来初始化自动助理104。在一些实施方式中,客户端计算设备118可以包括显示设备,该显示设备可以是包括触摸界面的显示面板,该触摸界面用于接收触摸输入和/或手势以允许用户经由该触摸界面来控制客户端计算设备118的应用。在一些实施方式中,客户端计算设备118可以缺乏显示设备,从而提供可听用户界面输出,而不提供图形用户界面输出。此外,客户端计算设备118可以提供用户界面输入设备,诸如(一个或多个)麦克风,用于从用户130(以及从另外的未图示的用户)接收口头自然语言输入。
[0024]
客户端计算设备118可以通过诸如互联网的一个或多个网络114与远程计算设备112通信。客户端计算设备118可以将计算任务卸载到远程计算设备112,以便例如节省客户端设备118处的计算资源和/或利用远程计算设备112处可用的更鲁棒的资源。例如,远程计算设备112可以托管自动助理104,并且客户端计算设备118可以将在一个或多个助理界面处接收到的输入发送到远程计算设备112。然而,在一些实施方式中,自动助理104可以由在客户端计算设备118处的自动助理126托管。在各种实施方式中,可以在客户端计算设备118处通过自动助理126实现自动助理104的所有或少于所有方面。在这样的实施方式中的一些实施方式中,自动助理104的各方面经由客户端计算设备118的本地自动助理126实现并与远程计算设备112对接,这实现了自动助理104的其它方面。
[0025]
远程计算设备112可以经由多个线程来任选地为多个用户及其相关联的助理应用服务。在经由客户端计算设备118的本地自动助理126实现自动助理104的所有方面或少于所有方面的实施方式中,本地自动助理126可以是与客户端设备118的操作系统分开的应用
(例如,被安装在操作系统的“之上”)
–
或者可以通过客户端设备118的操作系统直接实现(例如,被视为操作系统的应用,但与操作系统集成在一起)。
[0026]
在一些实施方式中,远程计算设备112可以包括语音识别引擎134,该语音识别引擎134可以处理在助理界面128处接收到的音频数据,以确定该音频数据中体现的口头话语的文本和/或其它语义表示。语音识别引擎134可以在确定音频数据中体现的口头话语的文本和/或其它语义表示时利用一个或多个语音识别模型136,所述一个或多个语音识别模型136中的至少一些可以被称为“语音到文本”模型或者“stt”模型。如本文所述,可以提供多个语音识别模型136,并且每个语音识别模型可以用于对应的语言。例如,第一语音识别模型可以用于英语,第二语音识别模型可以用于法语,第三语音识别模型用于西班牙语,第四语音识别模型用于普通话,第五语音识别模型用于日语等等。在一些实施方式中,语言模型可以包括或指代声学模型、语音识别模型、调用短语模型、话音到文本模型、话音到语义表示模型、文本到语义表示模型和/或可以被用于将自然语言输入转变为可以由应用或设备处理的数据的任何其它模型。
[0027]
在一些实施方式中,语音识别模型136各自包括一个或多个机器学习模型(例如,神经网络模型)和/或用于确定文本(或其它语义表示)的统计模型,该文本对应于音频数据中体现的口头话语。在一些实施方式中,语音识别引擎134可以利用所述语音识别模型136中的一个来确定包括在音频数据中的用于对应语言的音素,并且然后基于所确定的音素来生成用于对应语言的文本。在一些实施方式中,语音识别模型例如以数字音频数据的形式接收话音输入的音频记录,并将该数字音频数据转换到一个或多个文本令牌(例如,stt处理)中。可以一起被认为是语音识别模型的由这种功能性使用的一个或多个模型通常对语言中的音频信号和音标单元之间的关系以及语言中的单词序列进行建模。在一些实施方式中,语音识别模型可以是声学模型、语言模型、发音模型等,以及结合一个或多个这样的模型的功能性的模型。例如,在一些实施方式中,语音识别模型可以被实现为包括多个路径或通路的有限状态解码图。
[0028]
此外,如本文所述,在音频数据的处理中可以利用用于多种不同语言的多个语音识别模型136以针对多种不同语言中的每一种语言生成多种候选语义和/或文本表示。例如,在那些实施方式中的一些中,每个语音识别模型可以生成多个候选语音识别输出或“假设”。针对给定语言的每个候选语音识别输出/假设可以构成关于用户所说的内容的“猜测”或“预测”。如果由用户使用的语言与训练特定模型的语言是不同的语言,则存在由该模型生成的多个候选语音识别输出在语义和/或句法上可能会彼此大大变化的可能性,这是因为没有训练特定的模型来处理该语言。相反,如果由用户使用的语言是所训练的特定模型所针对的语言,则存在多个候选语音识别输出将在语义和/或语法上相对相似的可能性。在各种实施方式中,语言模型的多个语音识别输出之间的语义和/或句法变化可以以在本文中被称为“熵”得分或“多样性”得分的方式来量化。
[0029]
在一些实施方式中,可以使用诸如以下等式来确定特定语言的熵得分:
[0030][0031]
在此,n是一个正整数,其表示由stt在计算熵得分时考虑的模型考虑下生成的假设总数,h
i
表示针对语言生成的第i个假设,d(h
i
,h
j
)表示在第i个假设和第j个假设(i和j均
为正整数)之间的编辑距离,并且|h
i
|代表第i个假设中的字符数h
i
。编辑距离d可以是两个假设彼此之间有多么不同的度量,并且在一些情况下,其范围可以从零(即,无不同)到每个假设中的字符数之和。因此,在采用以上等式的实施方式中,熵或分集得分可以是任意两对假设之间的平均值和长度归一化编辑距离,并且可以被认为是stt结果的不确定性的度量。由此等式输出的值可能与所讨论的stt模型产生的假设的实际交叉熵负相关。例如,通过此等式输出的值越低,熵越大,反之亦然。然而,这并不意味着是限制性的。可以将不同的公式用于熵近似。
[0032]
注意,在一些实施方式中,n不一定等于由特定语音识别模型136生成的假设的数量。例如,给定的语音识别模型136可能生成大量的假设。在一些这样的情况下,例如,基于对每个假设的晶格后验(例如,由于对识别图进行解码而产生的后验概率)的分析,可以将在确定熵得分时考虑的假设的实际数量限制为n。在一些实施方式中,每个假设h的晶格后验可以被包含在以上等式中,例如,作为对编辑距离d()的比例项。在一些实施方式中,在确定熵得分时考虑的假设的实际数量可以被限制为n(正整数)的值。在一些实施方式中,值n对于所有查询可以是恒定的。在一些实施方式中,n的值可以是动态的,例如基于将假设的概率与阈值进行比较而在查询到查询之间改变。
[0033]
本文也设想其它等式。例如,在一些实施方式中,除了编辑距离之外或代替编辑距离,可以考虑两个假设的两个嵌入之间的距离,例如在潜在语义(或句法)空间中。在一些这样的实施例中,所有假设(或其潜在嵌入)之间的成对距离的平均值可以被用作该语音识别模型的熵得分。
[0034]
返回参考图1,自动助理104可以同时根据一种或多种语言模型进行操作,以便于响应于来自用户130的自然语言输入和/或向用户130提供响应内容。在一些实施方式中,自动助理104可以同时使用调用短语模型和使用与特定语言相关联的语音识别模型来进行操作。以此方式,自动助理可以处理体现调用短语和以特定语言提供的一个或多个命令的音频数据,并且响应于调用短语和一个或多个命令两者。从音频数据转换的文本和/或文本的语义表示可以由文本解析器引擎110解析,并且可以作为文本数据或语义数据对自动助理104可用,其可以被用于生成和/或标识来自用户130和/或第三方应用的命令短语。
[0035]
当用户130与客户端计算设备118处的自动助理126进行通信时,用户130可以将口头自然语言输入提供给客户端计算设备118的助理界面128。口头自然语言输入可以被转换成音频数据,该音频数据可以由客户端语言模型124处理,诸如用于标识音频数据是否体现用于调用自动助理126的调用短语的调用短语模型。在一些实施方式中,可以在客户端计算设备118处采用调用短语模型以确定用户130是否打算调用自动助理104。当用户向助理界面128提供自然语言输入,并且该自然语言输入包括用于调用自动助理104的调用短语时,客户端计算设备118可以使服务器设备102处的自动助理104从用户130接收自然语言输入和/或随后的自然语言输入。
[0036]
例如,响应于确定用户130打算在客户端计算设备118处调用自动助理104,可以在客户端计算设备118和服务器设备102之间建立一个或多个通信信道。其后,当用户继续向助理界面128提供自然语言输入时,自然语言输入将被转换成数据,然后该数据通过网络114被发送并由服务器设备102处理。此后,多个语音识别模型136可以是被用于处理本文所述的自然语言输入中的每一个自然语言输入。基于熵/多样性得分,可以为每个自然语言输
入选择一个或多个语音识别模型136作为适当的模型。在一些实施方式中,由该模型生成的具有最高置信度得分的候选语音识别可以由自动助理104处理,以便确定执行哪个响应动作。
[0037]
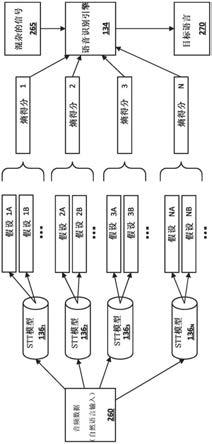
图2图示例证可以如何处理指示在一个或多个麦克风处捕获的口头自然语言输入的音频数据260以确定用于下游处理的语言模型的图。音频数据260可替代地采取口头自然语言输入的记录、从这种记录生成的嵌入、具有从记录和/或嵌入提取的特征的特征向量等形式。
[0038]
首先,音频数据260作为跨多个stt模型136
1-136
n
(在本文中也称为“语音识别模型”)的输入被应用。可以基于各种因素来选择所采用的模型的数量n。例如,住在多语种家庭中或在多语种工作场所中工作的用户可以操作自动助理104的图形用户界面或语音界面来选择与用户期望在处理中使用的语言一样多的语言。例如,如果用户住在讲英语和西班牙语的双语种的家庭中,则用户可以选择这两种语言,并且可以使用两个对应的stt模型136来处理语音输入。在一些实施方式中,可能存在针对特定语言的多种方言。在这种情况下,用户可以选择那些方言中的一种或多种方言,诸如卡斯蒂利亚西班牙语和加泰罗尼亚西班牙语。
[0039]
图2中的每个stt模型136生成至少一个假设,并且在大多数情况下生成多个假设。例如,stt模型136
1
生成第一假设1a、第二假设1b、stt模型136
2
生成第一假设1a、第二假设1b,依此类推。对于每个stt模型136,例如,使用先前阐述的等式或另一等式,基于由该stt模型136生成的多个假设来计算熵得分。然后可以将熵得分提供给语音识别引擎134。可以至少部分地基于熵得分来选择目标语言270。例如,可以选择为其生成最低熵得分的语言作为目标语言270。在各种实施方式中,通过对话状态引擎,可以在下游处理中(诸如在解析、自然语言处理、语义处理、自然语言生成等中)使用目标语言270。例如,如果基于具有最低熵得分的意大利语来选择意大利语,则可以在下游采用意大利语自然语言处理模型和/或以意大利语进行训练的语义处理模型。响应于音频数据260中体现的自然语言输入而由自动助理104提供的自然语言输出可以是以意大利语。
[0040]
在一些实施方式中,除了熵得分以外,语音识别引擎134还可以使用一个或多个其它信号265以选择目标语言270。可以考虑诸如针对单独假设的置信度得分的信号、基于音频的说话者识别、基于视觉的说话者识别(例如,面部识别、徽章或其它标记的识别、通过由说话者携带的设备发射的无线信号的检测等)、一天中的时间、过去自动助理104已经使用的语言、在用户和自动助理104之间的交互的场境,诸如根据位置坐标传感器(例如,gps、无线三角测量)确定的用户的位置。在一些实施方式中,还可以考虑通过自动助理交互(例如,汽车共享服务、食品订购服务等)来满足用户的请求的第三方应用。附加地或替代地,在一些实施方式中,可以采用来自用户的在线简档120(见图1)的信息,该信息可以包括一个或多个以上提及的信号或附加信号。例如,用户的个人简档120可以指示她所讲的语言、她要去哪儿、她的偏好等。
[0041]
在一些这样的实现中,这些其它因素可以用作具有相似熵得分的两个stt模型136的平局决胜者。例如,假定音频数据260包含意大利语的请求。因为意大利语和西班牙语二者都是浪漫的语言,所以基于它们相应的假设计算出的熵得分可能会相似。在这种情况下,用户位于意大利而不是诸如西班牙或墨西哥这样的讲西班牙语的国家的事实可以被用于
打破僵局。作为另一个示例,假定用户具有在线个人简档,该在线个人简档指示他或她讲西班牙语。这样的信号可以被用作平局决胜者以决定所选择的目标语言应该是西班牙语而不是意大利语。
[0042]
图3a和3b图示示例,在该示例中,实施本文所述的技术以促进两个用户101a和101b与至少部分在客户端计算设备318上操作的自动助理104之间的谈话。在该示例中,客户端计算设备318采用独立式交互式扬声器的形式,但这并不是限制性的。如前所述,客户端计算设备318可以采用其它形式(包括助理设备),诸如车辆计算系统、智能电视、配备有可用于与自动助理104接洽的联网钥匙的“哑”电视、智能手表、智能手机、配备助理的智能电器等。
[0043]
在图3a中,第一用户101a询问“ok assistant,how do i enable fingerprint authentication on my smart watch?(好的,助理,如何在我的智能手表上启用指纹认证?)”自动助理104可以使用或可以不使用本文所述的技术来确定第一用户101a讲英语。例如,自动助理104可以通过第一用户101a设置的母语(在该示例中为英语)来处理每个请求,并行使用在本文描述的技术来识别说话者可能已经使用的其它语言。如果英语stt输出的置信度量大于一些阈值,或者足够大于使用本文所述技术选择的语言的最高置信度量,则可以选择英语。替选地,在一些实施方式中,本文所述的技术可以被用于处理捕获每个话语的音频数据。或者,在一些实施方式中,一个或多个混杂的信号265(例如,位置、使用讲话者识别确定的讲话者身份等)可以被使用来确定是否应使用默认语言(例如,图3a中的英语)、是否应仅使用本文所述的技术来选择目标语言、或者默认语言是否应与本文所述技术并行使用。
[0044]
图3b描绘对话可以如何继续的示例。在图3b中,另一个用户101b以中文询问问题“那么双因素授权呢?”。这用英语转变成“what about two-factor authentication?”。在并行采用本文所述的英语stt模型和技术的一些实施方式中,来自英语stt模型的输出可能具有低置信度量(例如,低于阈值)。相比之下,使用本文所述的技术所选择的中文stt模型-即,该模型可能具有最低的熵得分-可能具有更大的置信度量。因此,可以替代地采用中文stt模型的输出,并且下游处理可以同样或可以不同样采用中文模型和/或元素。如图3b中所示,自动助理104回答“相同的菜单,但选择
’
双因素”。用英语将其转变为“same menu,but select
‘
two-factor
’”
。
[0045]
在一些实施方式中,自动助理104可以基于所选择的语言来选择自然语言输出的各种属性。例如,假设用中文提出诸如“法兰克福肯塔基到路易斯维尔有多远?(how far from louisville kentucky is frankfort kentucky?)”的问题。中国是通常采用公制的国家。因此,在各种实施方式中,可以以公里(和中文)提供答案。另一方面,如果用英语提出相同的问题,则自动助理104可以替代地用英制单位(和英语)响应。
[0046]
图4描绘根据各种实施例的用于实践本公开的所选方面的示例方法400。为了方便起见,参考执行操作的系统来描述该流程图的操作。该系统可以包括各种计算机系统的各种组件,所述组件包括图1中所描绘的组件。此外,尽管以特定顺序示出方法400的操作,但这并不意味着是限制性的。可以会重新排序、省略或添加一个或多个操作。
[0047]
在框402处,系统可以例如在由用户操作以与自动助理(例如,104)接洽的计算设备的麦克风(例如,118)处或在与计算设备通信地耦合的另一个麦克风处接收来自用户的
话音输入。话音输入可以包括来自用户的请求,诸如对信息(例如,天气)的请求、执行一些响应性动作例如,呼叫乘车共享车辆、启动计时器、操作智能设备等)的请求(等等。
[0048]
在框404处,系统可以将指示话音输入的音频记录的数据(诸如音频记录本身、嵌入、特征向量等)作为输入应用于多个stt机器学习模型(例如,136)以生成多个候选语音识别输出(或“假设”)。可以用特定语言来训练所述多个stt机器学习模型中的每个stt机器学习模型。如前所述,这些模型可以采用各种形式,诸如神经网络、隐马尔可夫模型等。
[0049]
在框406处,系统可以针对所述多个stt模型中的每个相应stt机器学习模型分析多个候选语音识别输出,以确定相应stt机器学习模型的熵得分。可以采用各种等式和/或试探法,诸如上述等式。例如,上述等式依赖于归一化编辑距离(即,假设之间的差)。其它实施方式可能依赖于潜在空间中多个候选语音识别输出的降维嵌入的距离。另外或替代地,在计算熵得分时可以考虑的其它因素包括但不限于由给定的stt模型生成的假设的计数、由给定的stt模型生成的满足一些准则的假设的计数(例如,置信度阈值)、假设之间的语义差(例如,可以通过将其嵌入到语义潜在空间来确定)等等。
[0050]
如前所述,对于许多不同的语言,可能存在许多不同的stt模型。从计算资源的角度来看,在所有情况下都应用所有模型可能是浪费的。因此,在各种实施方式中,诸如一个或多个混杂的信号265的各种因素可以被用于选择使用哪种stt模型。例如,在一些实施方式中,最终使用的多个stt机器学习模型可以是stt机器学习模型的超集的子集。可以基于各种信号(诸如计算设备的历史上下文、计算设备的当前上下文、由用户先前为自动助理设置的设定等)、一天的时间、历史使用情况、用户的简档120(例如,在通过用户的视觉外观或语音识别用户时可以进行查阅)等等从超集中选择实际上使用的stt模型的子集。
[0051]
在框408处,系统可以至少部分地基于与多个stt机器学习模型相关联的熵得分来选择与所述多个stt机器学习模型的至少一个stt机器学习模型相关联的语言(例如,被用于训练的语言)作为目标语言。如前所述,在一些实施方式中,其它混杂的信号(例如,265)也可以被认为是例如作为平局决胜者。在一些实施例中可以是具有最高置信度量的一个或多个假设的所选stt模型的输出可以被用于下游处理。在一些实施方式中,熵得分本身可以被用于确定stt输出的置信度量。假定特定的stt模型具有最低的熵得分,并且因此被选中。然而,例如当说话者没有清楚地表达请求时,该stt模型的熵得分可能仍然相对较大。在一些实施方案中,此相对较大的熵得分可能影响针对从该stt模型生成的每一假设而计算的置信度得分。如果那些置信度不能满足一些阈值,则自动助理104可以寻求来自用户的进一步确认和/或歧义消除。
[0052]
在框410处,系统可以使自动助理使用目标语言来相应来自用户的请求。例如,在一些实施方式中,可以利用针对所选目标语言量身定制下游组件(诸如,自然语言处理器、语义处理器、对话状态引擎、自然语言生成器等)来处理用户的请求。附加地或替代地,在一些实施方式中,用户的请求可以被嵌入到语义潜在空间中,在该语义潜在空间中,或多或少地忽略或丢弃请求的语法,从而有利于语义丰富的特征表示。在一些这样的实施方式中,至少一些用于处理用户请求的下游组件可以是与语言无关的。在一些情况下,响应用户的请求可以包括生成和提供自然语言输出,其可以被可听地(例如,通过语音合成器)和/或视觉地呈现。在一些这样的情况下,用于生成自然语言输出的语言可以是所选择的目标语言,并且在适用的情况下,可以基于该目标语言来选择语音合成器。
[0053]
图5是示例计算机系统510的框图。该计算机系统510通常包括至少一个处理器514,其经由总线子系统512与多个外围设备通信。这些外围设备可以包括存储子系统524,包括例如,存储器525和文件存储子系统526;用户界面输出设备520;用户界面输入设备522以及网络接口子系统516。输入和输出设备允许用户与计算机系统510交互。网络接口子系统516提供到外部网络的接口,并被耦合到其它计算机系统中的对应接口设备。
[0054]
用户界面输入设备522可以包括键盘;诸如鼠标、轨迹球、触摸板或图形输入板的指向设备;扫描仪;并入到显示器的触摸屏;诸如语音识别系统的音频输入设备;麦克风;和/或其它类型的输入设备。通常,术语“输入设备”的使用旨在包括将信息输入到计算机系统510中或输入到通信网络上的所有可能类型的设备和方式。
[0055]
用户界面输出设备520可以包括显示子系统、打印机、传真机或诸如音频输出设备的非可视显示器。显示子系统可以包括阴极射线管(crt)、诸如液晶显示器(lcd)的平板设备、投影设备或用于创建可视图像的某种其它机制。显示子系统还可以诸如经由音频输出设备来提供非视觉显示。通常,术语“输出设备”的使用旨在包括从计算机系统510向用户或另一台机器或计算机系统输出信息的所有可能类型的设备和方式。
[0056]
存储子系统524存储提供本文所述的一些或全部模块的功能性的编程和数据构造。例如,存储子系统524可以包括用于执行方法400的所选方面和/或实现以下各项中的一个或多个的逻辑:服务器设备102、客户端计算设备118、便携式计算设备132、以及/或者本文讨论的任何其它设备或者操作。
[0057]
这些软件模块通常由处理器514单独或与其它处理器结合执行。存储子系统524中使用的存储器525可以包括多个存储器,包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)530以及存储有固定指令的只读存储器(rom)532。文件存储子系统526可以为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、cd-rom驱动器、光盘驱动器或可移动介质盒。实现某些实施方式的功能性的模块可以由文件存储子系统526存储在存储子系统524中,或者存储在可由一个或多个处理器514访问的其它机器中。
[0058]
总线子系统512提供一种机制,其用于使计算机系统510的各种组件和子系统按照预期彼此通信。尽管总线子系统512被示意性地示出为单条总线,但是总线子系统的替代实施方式可以使用多条总线。
[0059]
计算机系统510能够是各种类型,包括工作站、服务器、计算集群、刀片服务器、服务器场、或任何其它数据处理系统或计算设备。由于计算机和网络的不断变化的性质,图5中描绘的计算机系统510的描述仅旨在作为用于图示一些实施方式的目的的特定示例。计算机系统510的许多其它配置可能具有比图5中描绘的计算机系统更多或更少的组件。
[0060]
在本文描述的系统收集关于用户(或者在本文中经常被称为“参与者”)的个人信息或可以使用个人信息的情况下,可以向用户提供机会来控制程序或特征是否收集用户信息(例如,关于用户的社交网络、社会行为或者活动、职业、用户的偏好、或者用户的当前地理位置的信息),或者控制是否和/或如何从内容服务器接收可能与用户更加相关的内容的机会。另外,某些数据可以在被存储或使用之前被以一种或多种方式处理,使得个人可识别信息被移除。例如,可以处理用户的身份,使得无法针对该用户确定任何个人可识别信息,或者可以在获得地理位置信息的情况下使用户的地理位置(诸如城市、邮政编码或州级别)
一般化,使得无法确定用户的特定地理位置。因此,用户可以控制如何收集有关用户的信息和/或如何使用信息。
[0061]
虽然本文已经描述和图示若干实施方式,但是可以利用用于执行功能和/或获得结果的各种其它手段和/或结构和/或本文所述的一个或多个优点,并且这些变化和/或修改中的每一个被认为是在本文所述的实施方式的范围内。更一般地,本文所述的所有参数、尺寸、材料和配置旨在是示例性的,并且实际参数、尺寸、材料和/或配置将取决于使用这些教导的一个或多个特定应用。本领域的技术人员将认识到或者能够使用不超过常规的实验确定本文所述具体实施方式的许多等同物。因此,要理解,前述实施方式仅作为示例呈现,并且在所附权利要求书及其等同物的范围内,可以以不同于具体描述和要求保护的方式实践实施方式。本公开的实施方式涉及本文所述的每个单独的特征、系统、物品、材料、套件和/或方法。此外,如果这些特征、系统、物品、材料、套件和/或方法不相互矛盾,则两个或更多个这样的特征、系统、物品、材料、套件和/或方法的任何组合被包括在本公开的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1