二次分割聚类、自动语音识别和转录生成的系统及方法与流程
二次分割聚类、自动语音识别和转录生成的系统及方法
背景技术:
1.语音识别并生成转录(transcript)或可隐藏字幕是一项期望通过计算系统来部分或全部完成的任务。为了完成该任务,必须对说话人进行识别和划分。这被称为分割聚类(diarization)。这种执行分割聚类的过程的强度与所需的时间和处理能力有关。声音信号与说话人的数量、表达的繁简以及信号的长度有关,声音信号越复杂、越长,该过程越耗时。在许多场景中,用户期望更快速地处理和生成转录。
技术实现要素:
2.在一个实施例中,一种包括asr和分割聚类的转录生成方法,所述方法包括在平台模块接收音频文件以及将所述音频文件划分为多个块。所述方法还包括将所述多个块的每个实例(instance)发送到语音服务模块。所述方法还包括对所述多个块的每个实例进行语音到文本转换。所述方法还包括将所述多个块的每个实例的文本返回到所述平台模块。所述方法还包括在所述平台模块合并(merging)所述多个块的每个实例的文本,以产生音频文件转录。所述方法还包括将所述音频文件和所述多个块发送到分割聚类模块。所述方法还包括对所述多个块执行第一次分割聚类,以产生多个分割聚类块(chunk)。所述方法还包括对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述方法还包括合并所述音频文件转录和所述经分割聚类的音频文件,以产生最终转录。在一个可选方案中,所述第一次分割聚类与所述语音到文本转换同时进行。在一个可选方案中,所述方法还包括将所述音频文件转码成已知的代码。在另一个可选方案中,所述方法还包括将所述音频文件转录发送到后处理模块以及将标点符号和大小写(casing)应用到所述音频文件转录。可选择地,所述多个分割聚类块包括多个段,每个段具有说话人识别信息。在另一个可选方案中,所述说话人识别信息是i
‑
vector。可选择地,在所述多个分割聚类块中的每个中,将所述多个段中包括统计学相似的说话人识别信息的段聚簇为属于多个说话人中的相应说话人。在另一个可选方案中,所述第二次分割聚类包括给所述多个分割聚类块中的每个的多个说话人中的每个赋予唯一识别符。在另一个可选方案中,所述第二次分割聚类包括,针对所述多个段中与每个唯一识别符关联的关联段,对所述关联段的说话人识别信息求均值,以产生均值说话人识别信息。可选择地,所述第二次分割聚类包括,根据所述多个段中与每个唯一识别符关联的关联段的均值说话人识别信息之间的相关性,将所述多个块中的所有块的多个段中的经识别段分配到最终说话人。在另一个可选方案中,所述方法还包括以固定且有形的格式输出所述最终转录。
3.在一个实施例中,一种包括asr和分割聚类的转录生成系统,所述系统包括平台模块、与所述平台模块通信的语音服务模块以及与所述平台模块通信的分割聚类模块。所述平台模块、所述语音服务模块和所述分割聚类模块被配置成在所述平台模块接收音频文件以及将所述音频文件划分为多个块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述多个块的每个实例发送到所述语音服务模块。所述语音服务模块被进一步配置成对所述多个块的每个实例进行语音到文本转换。所述平台模块、所述语音
服务模块和所述分割聚类模块被进一步配置成将所述多个块的每个实例的文本返回到所述平台模块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成在所述平台模块合并所述多个块的每个实例的文本,以产生音频文件转录。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述音频文件和所述多个块发送到所述分割聚类模块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成对所述多个块执行第一次分割聚类,以产生多个分割聚类块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成合并所述音频文件转录和所述经分割聚类的音频文件,以产生最终转录。可选择地,所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述音频文件转码成已知的代码。在一个可选方案中,所述系统还包括后处理模块,其中,所述后处理模块、所述平台、所述语音服务模块和所述语音服务模块被配置成将所述音频文件转录发送到后处理模块以及将标点符号和大小写应用到所述音频文件转录。在一个可选方案中,所述多个分割聚类块包括多个段,每个段具有说话人识别信息。在一个可选方案中,所述说话人识别信息是i
‑
vector。可选择地,在所述多个分割聚类块中的每个中,将所述多个段中包括统计学相似的说话人识别信息的段聚簇为属于多个说话人中的相应说话人。在另一个可选方案中,所述第二次分割聚类包括给所述多个分割聚类块中的每个的多个说话人中的每个赋予唯一识别符。在另一个可选方案中,所述第二次分割聚类包括,针对所述多个段中与每个唯一识别符关联的关联段,对所述关联段的说话人识别信息求均值,以产生均值说话人识别信息。可选择地,所述第二次分割聚类包括,根据所述多个段中与每个唯一识别符关联的关联段的均值说话人识别信息之间的相关性,将所述多个块中的所有块的多个段中的经识别段分配到最终说话人。
4.在一个实施例中,一种对声音记录执行分割聚类的方法,所述方法包括接收声音记录以及将所述声音记录分成多个块。所述方法还包括对所述多个块执行第一次分割聚类,其中,对所述多个块执行第一次分割聚类包括将所述多个块中的每个分成多个段,对于所述多个段中的每个段生成描述所述段中的声音特征的统计学说话人信息,以及在所述多个块的每个块内,将具有相似的统计学说话人信息的段聚簇,以在所述多个块的每个块内生成根据所述相似的统计学说话人信息被分组的段组。所述方法还包括通过在所述多个块之间将根据经分组的相似的统计学说话人信息的所述多个段组聚簇来执行第二次分割聚类,所述经分组的相似的统计学说话人信息是所述段组中的每个组的语音特征。
5.在一个实施例中,一种固定的有形介质,所述固定的有形介质在由计算系统执行时执行包括以下项的步骤在平台模块接收音频文件以及将所述音频文件划分为多个块。所述步骤还包括将所述多个块的每个实例发送到语音服务模块。所述步骤还包括对所述多个块的每个实例进行语音到文本转换。所述步骤还包括将所述多个块的每个实例的文本返回到所述平台模块。所述步骤还包括在所述平台模块合并所述多个块的每个实例的文本,以产生音频文件转录。所述步骤还包括将所述音频文件和所述多个块发送到分割聚类模块。所述步骤还包括对所述多个块执行第一次分割聚类,以产生多个分割聚类块。所述步骤还包括对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述步骤还包括合并所述音频文件转录和所述经分割聚类的音频文件,以产生最
终转录。
附图说明
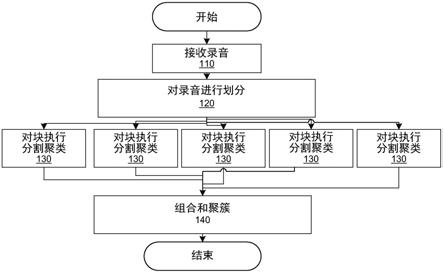
6.图1描绘了二次分割聚类的方法的一个实施例的流程图;
7.图2a示出了伪代码的流程图的一个实施例;
8.图2b示出了根据先前的聚簇(clustering)继续处理的流程图的一个实施例;
9.图3a示出了使用仅包括一次的分割聚类技术的系统的一个实施例;
10.图3b示出了利用对录音同步或同时进行分割聚类的系统的一个实施例;以及
11.图4是单次与二次分割聚类的cpu时间与音频长度的时间对比图。
具体实施方式
12.在本文中使用某些术语仅是为了方便,而不是作为对用于隐藏式字幕或转录创建目的的分段分割聚类的系统和方法的实施例的限制。在许多实施例中,声音记录由系统接收,该系统对声音记录进行处理,以确定录音的内容和录音中的说话人的身份。在许多实施例中,录音被分为多块,其被并行处理,并且在处理完成时被合并。在许多实施例中,录音首先被进行处理以进行语音识别。随后,录音被进行处理,以块格式进行分割聚类。用于分割聚类的块通常与用于语音识别的块相同。随后,在许多实施例中,对录音进行重新组合,并添加标点符号和文本格式。在许多实施例中,由于所有的块被并行处理,因此分割聚类所需的时间可以被保持相对恒定。
13.分割聚类是在音频轨道上找出谁在什么时候说话的任务。这会涉及到诸如归一化交叉似然比(nclr)之类的聚簇技术,并且可以包括以迭代的方式收集整个音频流的统计数据。虽然这提供了很好的准确性,但主要的缺点是随着音频长度的增加,执行操作所需的cpu时间会以非线性的方式增加,并大大增加了向最终用户提供最终结果的转换时间。尤其是当两个或更多个的说话人快速互动使得许多很短的语音段相互交错的情况下。参见图4,其示出了单次与二次分割聚类的cpu时间与音频长度的时间对比图。
14.在一个实施例中,由于转换时间十分重要,因此减少了执行对整个音频文件进行分割聚类的时间。
15.执行单次分割聚类的系统可能如下。处理流水线可分三大部分完成:
16.1.分块模式的说话文字识别。
17.2.对整个音频文件运行的分割聚类流水线(当#1也被执行时,该流水线并行运行)。
18.3.在#1和#2完成后才开始的添加标点符号、文字格式等的后处理阶段。
19.在第一部分中,批量处理音频以进行说话文字识别,首先将原始音频文件分割成3分钟的块,并且对这些块中的每个块执行分割聚类处理,以识别这些3分钟中的哪一部分,如果可能的话,这些语音块中的每个属于哪个说话人。随后,对被识别为“语音”并按照被分割聚类流水线识别的“说话人”进行分组的块进行asr(自动语音识别)。
20.相比于#1相比,#2阶段会需要很长的时间,这使得这个系统差强人意,因为整个转换时间非常长,而且在一定程度上不可预测。
21.在文献中,很少讨论分割聚类算法的速度。唯一提出的使分割聚类加速的方法是
采用更快的算法(如i
‑
vector),或使用较少的统计数据(如二进制密钥)。
22.在行业内,没有专门处理该问题(转换时间长)。此外,在没有一些进一步的考量和先前未知的技术的情况下,将并行完成的块组合起来并非简单的过程。
23.在本公开的各个部分中,使用了术语“块(chunk)”。所使用的其它词语可包括“段”。在许多实施例中,块是指音频文件内某处的一定大小的窗口。各种长度的块是可能的,并且将块打散的方式的各种配置也是可能的。可以仅基于录音长度进行,或者可以基于各种其它可能性进行,例如语句的结束、对话的停顿等。并不旨在将块的形成限于任何一种技术。
24.在本公开的各个部分中,使用了术语“段(segment)”。段是指长度不确定的一部分音频,其被认为属于特定的说话人,并且包含代表语音的信号。
25.在本公开的各个部分中,使用了术语“簇(cluster)”。簇是指属于同一(被认定的)说话人的所有段的集合。换言之,簇是根据系统的统计和算法处理技术而被认为属于同一说话人的段的集合。
26.图1描述了一种二次分割聚类方法的一个实施例的流程图。在步骤110中,系统接收录音(recording)。在步骤120中,将录音划分成块。可以使用如本文所述的各种大小的块。对录音的这种划分使得能对块进行同时处理。在步骤130中,同时处理各个块。在该步骤中,执行分割聚类。换言之,对于每个块的每个段,基于该段的声音的特征分配说话人。在步骤140中,包括说话人身份信息的块被重新组合。作为该重新组合过程的一部分,块的段被根据说话人身份统计和信息进行聚簇(clustered)。换言之,在一个块中说话人已知的段被与所有其它块中的段进行比较。那些具有统计学相似的说话人信息的块被聚簇,并被认为是同一说话人。
27.下面是分割聚类服务自循环的关键部分的伪代码:新的二次分割聚类asr转录。这个特殊的伪代码是示例性的,存在许多可选的方案。
28.for each chunk diarization result:(对于每个块分割聚类结果:)
29.assign each detected speaker a unique name across all chunks(在所有的块中给每个被检测到的说话人分配唯一名字)
30.merge all chunk diarization results into one single diarization manifest(将所有的块分割聚类结果合并成单个分割聚类表)
31.for each cluster in that manifest(对于该表中的每个簇)
32.get an i
‑
vector mean for each cluster(获取每个簇的i
‑
vector均值)
33.perform i
‑
vector clustering using ilp linear optimization(利用ilp线性优化执行i
‑
vector聚簇)
34.relabel all segments according to the obtained speaker mapping(根据所获得的说话人映射对所有段进行重新标记)
35.图2a示出了解释该伪代码的流程图。图2a中描述的过程和上面的伪代码在对所有块进行分割聚类之后操作。在步骤210中,给块中的每个说话人分配唯一的识别符。实际上,这是很重要的,因为每个块被单独地分割聚类,给每个簇的默认名称可能在块之间交叠。在完成该步骤之后,在步骤220中,重命名的块被各自收集在单个数据集中,就好像它们是由对单个长的音频记录进行分割聚类而产生的那样。在分割聚类过程期间,针对块的每个段
执行i
‑
vector。随后,具有统计学相似的i
‑
vector的段被分组以形成簇(cluster)。在步骤230中,对簇中每个段的i
‑
vector求均值,以创建代表该簇的i
‑
vector。随后,每个簇的每个i
‑
vector均值被用于对簇进行聚簇(cluster the clusters)。这用ilp线性优化执行。可选择地,为了对簇进行聚簇,可以使用统计技术。一旦簇被聚簇,在步骤250中,将段全部相应地重新标记。因此,属于说话人的簇已经被分组并被识别为属于单个说话人。虽然这个逻辑是针对使用i
‑
vector来解释的,但是,其它技术也可以用来确定说话人并实现上述技术。
36.上述逻辑允许以几乎恒定的时间对任何音频文件进行分割聚类,这相对于目前已知的任何其它技术都有显著的优势。使用这种技术所损失的准确性可以忽略不计,而且对于任何与这种制作系统典型分布相匹配的音频文件长度来说,对速度的提升是非常显著的。这只是一种可能的逻辑的示例。许多实施例依赖于进行第一次分割聚类和第二次分割聚类。在这种实施例中,首先制作录音的块。随后,对块进行第一次分割聚类处理,以确定关于块的哪些段属于在块中识别的说话人的信息。随后,将在块中识别的说话人一起分析,以匹配各块之间的说话人。因此,可以通过对块执行分割聚类随后在块之间执行分割聚类来对整个录音完成分割聚类。
37.在音频文件实际上是由用户流传(stream)而不是已经完全提供给系统以进行处理的情况下,仍然可以应用本技术,新的块可以很容易在先前的块的背景/上下文(context)下进行处理,而不必再次对先前的块执行。仅需要对包括来自新块的信息再次运行第二次分割聚类步骤。图2b示出了根据先前的聚簇进行继续处理的流程图的一个实施例。图2b中描述的方法在许多配置中作为关于图2a描述的方法的附加功能。换言之,在发生初始的二次分割聚类之后,可以进行附加的二次分割聚类。在步骤250中,接收新录音,使其与已被分析的先前录音相对应。在步骤260中,随后根据图2a的方法对新录音执行分割聚类。随后,在步骤270中,给新的簇创建均值i
‑
vector。在步骤280中,将新录音的均值i
‑
vector与旧簇的均值i
‑
vector进行比较。随后,在步骤290中,如果存在相关性/匹配,则将新记录的簇重新标记为属于旧簇的相应簇。注意,在这一点上,可以给重新分组的簇生成新的i
‑
vector。在可选方案中,可以根据图2a的方法生成全新的分组,其中所有数据被收集在单个集合中,随后被重新分组。并且,虽然本方法和许多其它方法讨论了i
‑
vector,但可以使用块组的特征的任何类型的表示。
38.图3a示出了使用仅包括单次的分割聚类技术的系统的一个实施例。这突出了完整系统所提供的优势。图3a的表示可以被称为时序图。这种技术通常具有随着记录长度而在一定程度上线性增加的处理时间。这种系统提供了单次。如图所示,提供音频文件的用户305与平台310通信,以提供用于转录330的音频文件。在图中,用户可以包括使用计算机或如智能手机的其它计算设备的人员。通常,平台310是被设计成用于接收来自用户的请求的计算机或计算机系统。可选择地,平台310可以是计算系统内的模块。平台310可以是虚拟化的计算机,或者仅是整体代码库的一部分。这种交互有许多可能的表示,这在本公开的基础上对于本领域普通技术人员来说将是显而易见的。在许多情况下,音频文件的格式可能不是使用格式,因此,可选地,在步骤331中应用代码变换器。随后,在步骤332中,平台310可以将音频文件发送到分割聚类服务315。借此,分割聚类服务可以根据单次来识别说话人。在一些可选方案中,平台310随后可以将整个录音发送到语音服务320,以进行语音转文本分析。在实施例中示出,在步骤333中,平台310首先将音频样本划分成块。随后,在步骤334中,
平台310将块发送到语音服务320。如所表示的,这样做使得每个块是不同的实例,其可以由语音服务320同时处理,或者至少在语音服务320的容量允许的范围内由语音服务320同时处理。在步骤335中,转录被提供回到平台。在步骤336中,转录被合并。随后,在步骤337中,可以将转录发送到后处理服务325。随后,在步骤338中,后处理服务325可以对文本施加标点符号和大小写(casing)或其它细化。在步骤339中,带有标点和大小写的转录被返回。由于在这种配置中速率受限的步骤是分割聚类,因此在步骤340中,分割聚类结果被返回到平台310。在步骤341中,实施对分割聚类结果和转录的合并,随后,在步骤342中,将结果返回给用户305。如上所述,用户305、平台310、分割聚类服务315、语音服务320、后处理325的配置可以是实际的或者虚拟的,即它们实际上可以是不同的平台,或者可以是代码中的模块或没有明显划分的分区。此外,可以在这些构造之间概念性地调整步骤以及许多步骤的时间。
39.图3b示出了利用对录音同步或同时进行分割聚类的系统的一个实施例。如图所示,提供音频文件的用户305与平台310通信,以提供用于转录350的音频文件。在图中,用户可以包括使用计算机或如智能手机的其它计算设备的人员。通常,平台310是被设计成用于接收来自用户的请求的计算机或计算机系统。可选择地,平台310可以是计算系统内的模块。平台310可以是虚拟化的计算机,或者仅是整体代码库的一部分。这种交互有许多可能的表示,这在本公开的基础上对于本领域普通技术人员来说将是显而易见的。在许多情况下,音频文件的格式可能不是使用格式,因此,可选地,在步骤351中应用代码变换器。在步骤352中,平台可以将音频文件划分为固定长度的块。在一些情况下中,块的长度可以变化,例如在长时间沉默提供策略性划分的情况下,或者其它因素有助于可变长度的场景。随后,在步骤353中,平台310将块发送到语音服务320。如所表示的,这样做使得每个块是不同的实例,其可以在步骤354中由语音服务320同时处理,或者至少在语音服务320的容量允许的范围内由语音服务320同时处理。在步骤355中,转录被提供回到平台。在步骤356中,转录被合并。随后,在步骤357中,可以将转录发送到后处理服务325。随后,在步骤358中,块和整个音频文件可以被发送到分割聚类服务。块被作为实例同时处理。在此期间,后处理服务325随后可以在步骤359中对文本施加标点符号和大小写或其它细化。在步骤360中,带有标点和大小写的转录被返回。随后,在步骤361中,执行第二次分割聚类。随后,在步骤363中,将整个分割聚类结果返回。在步骤364中,合并所有结果,并且在步骤365中,可以将转录返回给用户。在此描述的一些步骤可以以不同的顺序执行。例如,可以在流程中较早地开始对块的分割聚类,在一些情况下,在语音转文本发生的同时开始。如上所述,用户305、平台310、分割聚类服务315、语音服务320、后处理325的构造可以是实际的或者虚拟的,即它们实际上可以是不同的平台,或者可以是代码中的模块或没有明显划分的分区。此外,可以在这些构造之间概念性地调整步骤以及许多步骤的时间。
40.系统的设计的一个方面包括音频记录的块的形成。在许多情况下,期望将系统设计成创建特定大小的块并对其操作。尽管实施例可以对各种大小的块工作,并且本发明在其许多实施例中并不被限于一定长度的块,但设计的一些创造性方面包括特定长度的块。创建特定长度的块背后的一个概念涉及到快速处理这些块的能力,并且还使块足够长以使得能进行说话人识别。虽然不是绝对的,但在许多情况下,长度必须足够长,以便建立语音的区分特征。通常情况下,这意味着几秒钟的块长度不足以识别说话人。此外,一个小时的
块长度过长而无法快速处理,并且对于许多音频录音来说,可能会导致只有很少的块。因此,一个启发是,块的长度在几分钟左右。这不是绝对的,仅是指引。在一些实施例中,大约三分钟的块长度在提供允许快速处理的块长度同时提供识别说话人的能力之间实现了良好的平衡。基本上,这是在处理速度和拥有足够的信息来识别说话人并拥有关于这些说话人的有价值的统计数据之间的权衡。在许多实施例中,1至15分钟的长度是合适的。同样,这仅是指引。
41.在一个实施例中,使用了3分钟(180秒)的块,并且确定这给整个asr系统提供了最佳的速度/准确性权衡。减小块的大小提高了系统的整体处理量(在一定程度上),初始化的固定成本越来越突出,但也降低了分割聚类和asr输出的准确性。增加块的大小可以稍微提高asr和分割聚类准确性,但会增加转换时间。分割聚类部分所需的时间随着音频长度的增加而以非线性方式增加。该时间不能被精确地表征,因为该时间过于依赖音频内容,但从图4的图表中可以看出,该时间有时会变得非常大。
42.一般来说,在技术中,说话人识别系统可以使用至少由三部分组成的i
‑
vector类系统。
43.一个部分包括特征提取。在许多配置中,说话人识别系统中使用mfcc(梅尔倒频谱系数(mel
‑
frequency cepstral coefficients))或plp(感知线性预测(perceptual linear prediction))特征。在许多配置中,该步骤通过使用频率分析技术(例如fft、快速傅里叶变换)来创建更紧凑且有效的语音样本表示。
44.另一部分包括i
‑
vector提取。尽管这被称为i
‑
vector提取,但这可能与将段的特征与模型或预期特征进行比较的任何类型的向量或任何类型的系统有关。术语i
‑
vector涉及对说话人的身份进行向量表示:i
‑
vector或身份向量。根据i
‑
vector模型,创建包括mfcc特征的语句模型。在许多配置中,这可以通过因子分析来(factor analysis)完成,但是其它技术也是可能的。借助因子分析,给诸如通用高斯混合模型之类的通用化模型的特征创建各种顺序统计。高斯混合模型可以是通用背景模型(ubm),但也可以使用其它模型。i
‑
vector描述了语段与ubm的接近程度,并且基于这种分析,可以开发出语段中特定说话人的特征。换言之,开发出通用语音声音的模型,并将某一特定语段的声音与该模型进行比较,从而对其进行表征。
45.为了比较两个段(或一组段)的i
‑
vector,以确定它们是否应该被合并,i
‑
vector评分被用作说话人识别的又一部分。向量评分的步骤,或者更具体地说,i
‑
vector评分的步骤,提供了基于大量实例集的两个i
‑
vector的“亲密度”比较。一种评分模型是plda(概率线性判别分析(probabilistic linear discriminant analysis));其允许使用说话人之间和说话人内部的分布来计算两个i
‑
vector之间的“距离”(似然比)。其它一些可能性包括使用隐藏马尔可夫模型(hidden markov model)(hmm)或最大似然高斯混合模型(或最小持续时间高斯混合模型)。
46.在许多配置中,第二次分割聚类可以依赖于修改后的i
‑
vector评分。在一些这种配置中,基于每个块内特定说话人的被聚簇的段,这些段的i
‑
vector可以被求均值,随后与其它均值i
‑
vector进行比较。可以比较两个(或多个)均值i
‑
vector的接近程度,随后可以对这些i
‑
vector以及与之对应的段进行聚簇。
47.在许多实施例中,该系统的优点包括,能够以恒定的时间对任意长的音频文件进
行分割聚类的能力,该程序不需要为了速度而牺牲准确性;其可以将任何说话人聚簇技术用于分割聚类流水线的任何阶段,并且该系统可以以完全离线/批量处理模式使用,也可以以半离线/流模式使用。
48.在一个实施例中,一种用于对声音记录进行分割聚类的系统,包括分块(chunking)模块,所述分块模块被配置成从声音记录中创建多个块。所述系统还包括第一次分割聚类模块,所述第一次分割聚类模块接收来自所述分块模块的多个块,所述第一次分割聚类模块被配置成创建多个第一次分割聚类表,所述多个第一次分割聚类表中的每个对应于所述多个块中的具体一个,所述多个第一次分割聚类表包括用于所述多个块中的每个块的段的说话人识别信息。所述系统还包括第二次分割聚类模块,所述第二次分割聚类模块接收所述多个第一次分割聚类表,并且利用所述多个块中的每个块的段的说话人识别信息在所述多个块之间对说话人进行匹配,从而得出所述声音记录的统一说话人识别。
49.在一个实施例中,一种用于对声音记录进行分割聚类的方法,包括接收声音记录,以及在分块模块处将所述声音记录分成多个块。所述方法还包括在第一分割聚类模块处对所述多个块中的每个块进行处理,以产生多个块表,所述多个块中的每个块对应于所述多个块表中的一个块表,所述多个块表中的每个包括多个段以及针对所述多个段中的每个段分配的说话人。所述方法还包括组合所述多个块表以产生多个声音记录段,所述多个声音记录段中的每个包括分配的说话人。所述方法还包括基于分配相同来针对所述多个声音记录段中的每个确定最终的分配说话人。
50.在一个实施例中,一种用于确定说话人的方法,包括将声音记录划分为多个块,所述多个块中的每个具有多个语音段。所述方法还包括,针对所述多个块中的每个块的多个语音段中的每个语音段确定说话人,从而针对所述多个块中的每个块创建块说话人识别信息。所述方法还包括,组合所述多个块的块说话人识别信息,并且针对所述多个块中的每个块的多个语音段中的每个语音段确定何种情况使得某一语音段应被分配为与另一语音段相同的说话人,从而根据相关的说话人将同一说话人分配给一组多个块。
51.在一个实施例中,一种方法,包括将声音记录划分为多个块,所述多个块中的每个块具有多个语音段。所述方法还包括,对所述于多个块中的每个块中的多个语音段中的每个语音段,确定说话人,从而给所述多个块中的每个块创建块说话人识别信息。所述方法还包括,所述多个块的块说话人识别信息,并且针对所述多个块中的每个块的多个语音段中的每个语音段确定何种情况使得某一语音段应被分配为与另一语音段相同的说话人,从而根据相关的说话人将同一说话人分配给一组多个块。
52.在一个实施例中,一种用于对声音记录进行分割聚类的方法,包括接收声音记录并将所述声音记录划分为多个块。所述方法还包括对所述多个块进行分割聚类,以产生多个分割聚类块。所述方法还包括组合多个分割聚类块。所述方法还包括在多个分割聚类块之间进行确定,何种情况下与在多个分割聚类块中的第一块中识别的第一段相关的第一说话人与多个分割聚类块中的第二块中的第二段中的第二说话人在统计上相似,使得第一说话人和第二说话人被认为是同一说话人,并将所述多个分割聚类块中的第一块中的第一段与所述多个分割聚类块中的第二块中的第二段分配为同一说话人。
53.在一个实施例中,一种用于对声音记录进行分割聚类的方法,包括接收声音记录。所述方法还包括将声音记录划分为多个块。所述方法还包括对多个块进行分割聚类,以产
生多个分割聚类块,所述多个分割聚类块中的每个包括多个段,所述多个段中的每个段具有在分割聚类过程中确定的被分配的说话人,所述被分配的说话人包括说话人识别符以及关于被分配的说话人的特征的统计信息。所述方法还包括组合多个分割聚类块。所述方法还包括,基于在被分配的说话人上具有足够的统计相似性的多个同一说话人段的分配说话人,对多个分割聚类块的多个段的多个同一说话人段进行聚簇。所述方法还包括,在多个分割聚类块之间进行确定,何种情况下与在多个分割聚类块中的第一块中识别的第一段相关的第一说话人与多个分割聚类块中的第二块中的第二段中的第二说话人在统计上相似,使得第一说话人和第二说话人被认为是同一说话人,并将所述多个分割聚类块中的第一块中的第一段与所述多个分割聚类块中的第二块中的第二段分配为同一说话人。
54.在一个实施例中,一种确定声音记录的说话人的方法,包括接收声音记录。所述方法还包括将声音记录分段成第一块和第二块。所述方法还包括对所述第一块和所述第二块进行分割聚类,其中,对所述第一块和所述第二块进行分割聚类包括将第一块分成至少第一段和第二段,确定所述第一段属于第一说话人,所述第二段属于第二说话人,以及将所述第二块分成至少第三段和第四段,确定所述第三段属于第三说话人,所述第四段属于第四说话人。所述方法还包括组合分割聚类的结果,其中,组合分割聚类的结果包括根据所述第一说话人和所述第三说话人具有统计学相似的语音特征对所述第一段和所述第三段进行聚簇,以及将所述第一说话人和所述第三说话人分配为同一说话人。
55.在一个实施例中,一种对声音记录进行分割聚类的方法,包括接收声音记录以及将声音记录分成多个块。所述方法还包括对所述多个块执行第一次分割聚类,其中,对所述多个块执行第一次分割聚类包括将所述多个块中的每个分成多个段,对所述多个段中的每个段生成描述所述段中的声音特征的统计学说话人信息,以及在所述多个块的每个块内将具有相似的统计学说话人信息的段聚簇,以在所述多个块的每个块内生成根据所述相似的统计学说话人信息进行分组的段组。所述方法还包括根据分组相似的统计学说话人信息通过在所述多个块之间进行聚簇来对段组进行第二次分割聚类,所述分组相似的统计学说话人信息是所述段组的每个组的语音特征。
56.在一个实施例中,一种包括asr和分割聚类的转录生成方法,所述方法包括在平台模块接收音频文件以及将所述音频文件划分为多个块。所述方法还包括将所述多个块的每个实例发送到语音服务模块。所述方法还包括对所述多个块的每个实例进行语音到文本转换。所述方法还包括将所述多个块的每个实例的文本返回到所述平台模块。所述方法还包括在所述平台模块合并所述多个块的每个实例的文本,以产生音频文件转录。所述方法还包括将所述音频文件和所述多个块发送到分割聚类模块。所述方法还包括对所述多个块执行第一次分割聚类,以产生多个分割聚类块。所述方法还包括对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述方法还包括合并所述音频文件转录和所述经分割聚类的音频文件,以产生最终转录。在一个可选方案中,所述方法还包括将所述音频文件转码成已知的代码。在另一个可选方案中,所述方法还包括将所述音频文件转录发送到后处理模块以及将标点符号和大小写应用到所述音频文件转录。可选择地,所述多个分割聚类块包括多个段,每个段具有说话人识别信息。在另一个可选方案中,所述说话人识别信息是i
‑
vector。可选择地,在所述多个分割聚类块中的每个中,将所述多个段中包括统计学相似的说话人识别信息的段聚簇为属于多个说话人中的相应说
话人。在另一个可选方案中,所述第二次分割聚类包括给所述多个分割聚类块中的每个的多个说话人中的每个赋予唯一识别符。在另一个可选方案中,所述第二次分割聚类包括,针对所述多个段中与每个唯一识别符关联的关联段,对所述关联段的说话人识别信息求均值,以产生均值说话人识别信息。可选择地,所述第二次分割聚类包括,根据所述多个段中与每个唯一识别符关联的关联段的均值说话人识别信息之间的相关性,将所述多个块中的所有块的多个段中的经识别段分配到最终说话人。在另一个可选方案中,所述方法还包括以固定且有形的格式输出所述最终转录。
57.在一个实施例中,一种包括asr和分割聚类的转录生成系统,所述系统包括平台模块、与所述平台模块通信的语音服务模块以及与所述平台模块通信的分割聚类模块。所述平台模块、所述语音服务模块和所述分割聚类模块被配置成在所述平台模块接收音频文件以及将所述音频文件划分为多个块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述多个块的每个实例发送到所述语音服务模块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成对所述多个块的每个实例进行语音到文本转换。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述多个块的每个实例的文本返回到所述平台模块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成在所述平台模块合并所述多个块的每个实例的文本,以产生音频文件转录。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述音频文件和所述多个块发送到所述分割聚类模块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成对所述多个块执行第一次分割聚类,以产生多个分割聚类块。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成合并所述音频文件转录和所述经分割聚类的音频文件,以产生最终转录。可选择地,所述平台模块、所述语音服务模块和所述分割聚类模块被进一步配置成将所述音频文件转码成已知的代码。在一个可选方案中,所述系统还包括后处理模块,其中,所述后处理模块、所述平台、所述语音服务模块和所述语音服务模块被配置成将所述音频文件转录发送到后处理模块以及将标点符号和大小写应用到所述音频文件转录。在一个可选方案中,所述多个分割聚类块包括多个段,每个段具有说话人识别信息。在一个可选方案中,所述说话人识别信息是i
‑
vector。可选择地,在所述多个分割聚类块中的每个中,将所述多个段中包括统计学相似的说话人识别信息的段聚簇为属于多个说话人中的相应说话人。在另一个可选方案中,所述第二次分割聚类包括给所述多个分割聚类块中的每个的多个说话人中的每个赋予唯一识别符。在另一个可选方案中,所述第二次分割聚类包括,针对所述多个段中与每个唯一识别符关联的关联段,对所述关联段的说话人识别信息求均值,以产生均值说话人识别信息。可选择地,所述第二次分割聚类包括,根据所述多个段中与每个唯一识别符关联的关联段的均值说话人识别信息之间的相关性,将所述多个块中的所有块的多个段中的经识别段分配到最终说话人。
58.在一个实施例中,一种固定的有形介质,所述固定的有形介质在由计算系统执行时执行包括以下项的步骤在平台模块接收音频文件以及将所述音频文件划分为多个块。所述步骤还包括将所述多个块的每个实例发送到语音服务模块。所述步骤还包括对所述多个
块的每个实例进行语音到文本转换。所述步骤还包括将所述多个块的每个实例的文本返回到所述平台模块。所述步骤还包括在所述平台模块合并所述多个块的每个实例的文本,以产生音频文件转录。所述步骤还包括将所述音频文件和所述多个块发送到分割聚类模块。所述步骤还包括对所述多个块执行第一次分割聚类,以产生多个分割聚类块。所述步骤还包括对所述多个分割聚类块和所述音频文件执行第二次分割聚类,以产生经分割聚类的音频文件。所述步骤还包括合并所述音频文件转录和所述经分割聚类的音频文件,以产生最终转录。
59.在许多实施例中,系统的一部分被提供在包括微处理器的器件中。本文所述系统和方法的各种实施例可以完全或部分地在软件和/或固件中实现。该软件和/或固件可以呈被容纳在非暂时性计算机可读存储介质中或其上的指令的形式。随后,这些指令可以由一个或多个处理器读取和执行,以实现本文所述操作的性能。这些指令可以呈任何合适的形式,例如但不限于,源代码、编译代码、解释代码、可执行代码、静态代码、动态代码等。这种计算机可读介质可以包括任何有形的非暂时性介质,用于以一种或多种计算机可读的形式存储信息,例如但不限于,只读存储器(rom);随机存取存储器(ram);磁盘存储介质;光存储介质;闪存等。
60.本文所述系统和方法的实施例可以在各种系统中实施,包括但不限于,智能手机,平板电脑,笔记本电脑以及计算设备和云计算资源的组合。例如,部分操作可以在一个设备中进行,而其它操作可以在远程位置处进行,例如远程服务器或服务器。例如,数据的收集可以在智能手机处进行,而数据分析可以在服务器或云计算资源中进行。任何单个计算设备或计算设备的组合可以执行所描述的方法。
61.尽管在前述详细描述中已经详细描述了具体的实施例,但本领域技术人员将理解,可以根据公开的总体教导及其广泛的发明概念的基础上发展出对这些细节的各种修改和替代方案。因此,应理解,本公开的范围并不限于本文所公开的特定示例和实施例,而是旨在涵盖权利要求及其任何和所有等价物所定义的精神和范围内的修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1