一种可定制文本的声纹验证方法及系统与流程
本发明涉及声纹识别技术领域,尤其涉及一种可定制文本的声纹验证方法及系统。
背景技术:
随着人工智能时代的到来,越来越多的领域开始使用人工智能来辅助办公提高生产力。其中声纹识别就是人工智能领域不可或缺的一部分。声纹识别在银行的应用范围也是十分广泛,可以运用在呼叫中心作为用户的身份验证以及搭建声纹黑名单。其实固定文本识别,则是声纹识别中关键的一部分。目前固定文本识别,只能做到固定某一个词,或某一句话来做语音识别。类似于市面上已经存在的“小爱同学”等唤醒词,若说错则会导致验证失败。但这样的技术会导致用户体验过于枯燥,无法为用户提供个性化的定制。当用户是用固定文本识别时,所有用户都必须使用服务提供方所设置的关键词。如:“小爱同学”,“芝麻开门”等之类的词语或语句。当声纹识别系统接收到用户语音时,将会同时判断声纹及内容。当且仅当两者同时通过时,声纹识别系统才会让用户通过。
因此,目前的固定文本识别技术,在无意间抹杀了用户选择的权力,无法为用户提供个性化的定制需求。从而降低用户对产品的使用体验。
技术实现要素:
本发明所要解决的技术问题是针对上述现有技术的不足提供一种可定制文本的声纹验证方法及系统,从而可以更好的满足用户个性化的定制需求,进而提高对产品的使用体验感。
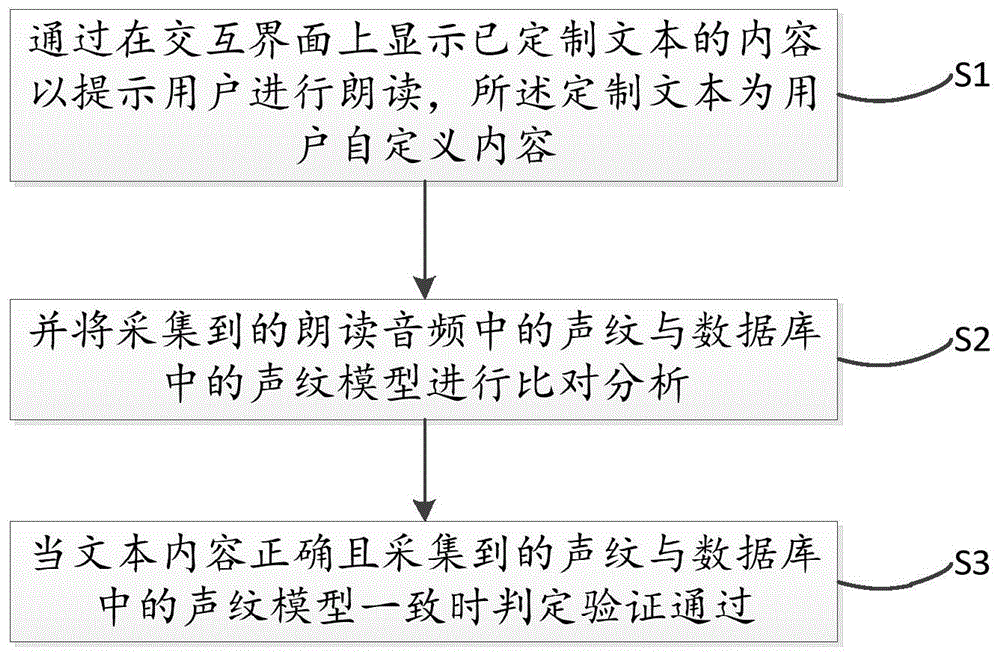
为实现上述目的,本发明提供一种可定制文本的声纹验证方法,所述方法包括:
s1,通过在交互界面上显示已定制文本的内容以提示用户进行朗读,所述定制文本为用户自定义内容;
s2,并将采集到的朗读音频中的声纹与数据库中的声纹模型进行比对分析;
s3,当文本内容正确且采集到的声纹与数据库中的声纹模型一致时判定验证通过。
优选的,所述用户自定义内容为用户根据需要所设计的词语或语句。
优选的,所述声纹模型存入数据库时与对应的用户自定义内容建立联系。
优选的,所述声纹模型为通过提取用户的语音声纹特征为其建立的声纹模型。
为实现上述目的,本发明还提供一种可定制文本的声纹验证系统,所述系统包括:
提示单元,通过在交互界面上显示已定制文本的内容以提示用户进行朗读,所述定制文本为用户自定义内容;
比对单元,并将采集到的朗读音频中的声纹与数据库中的声纹模型进行比对分析;
验证单元,当文本内容正确且采集到的声纹与数据库中的声纹模型一致时判定验证通过。
优选的,所述用户自定义内容为用户根据需要所设计的词语或语句。
优选的,所述声纹模型存入数据库时与对应的用户自定义内容建立联系。
优选的,所述声纹模型为通过提取用户的语音声纹特征为其建立的声纹模型。
通过本方案可以满足用户的个性化需求,该方案在用户第一次声纹入库时,会在用户交互界面上让用户输入自己想要定制的词语或语句。用户输入后,依照自己输入的内容朗诵。在声纹识别系统接收到用户的语音之后,会进行内容识别。判断用户朗诵的内容是否为用户输入内容。如果两者一致则将声纹入库,并将该语句记录。在用户使用阶段,系统会将记录好的语句,呈现在用户交互界面上,以提示用户。当用户用声纹进行验证的时候,声纹识别系统将会同时进行内容识别及声纹识别,当两者全部通过时则验证通过。因此,本发明的具有以下优点:
1、提高用户体验,满足用户个性化定制的需求;
2、提升产品多样性,利于产品推广。
附图说明
图1为本发明一实施例提供的可定制文本的声纹验证方法的流程图;
图2为本发明一实施例提供的可定制文本的声纹验证系统的结构框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
以下结合实施例详细阐述本发明的内容。
参照图1所示,为本发明一实施例提供的一种可定制文本的声纹验证方法的流程图。所述方法包括:
s1,通过在交互界面上显示已定制文本的内容以提示用户进行朗读,所述定制文本为用户自定义内容;
s2,并将采集到的朗读音频中的声纹与数据库中的声纹模型进行比对分析;
s3,当文本内容正确且采集到的声纹与数据库中的声纹模型一致时判定验证通过。
优选的,所述用户自定义内容为用户根据需要所设计的词语或语句。
优选的,所述声纹模型存入数据库时与对应的用户自定义内容建立联系。
优选的,所述声纹模型为通过提取用户的语音声纹特征为其建立的声纹模型。
本方案解决了当前固定文本识别,用户无法自由定制文本的问题。用户个性化体验作为提升用户体验最为关键的一部分,在固定文本识别中被忽视。声纹识别之所以需用固定文本,是因为声纹识别在短语音自由文本的状态下,识别准确率不高。固定文本通过固定住语音的内容,从而提高识别率。这个识别率的提升主要依赖于,用户在声纹建模入库时所说的内容与用户之后用来验证身份所有的内容一致。因此声纹识别系统无需剔除音频中的语义信息,直接进行声纹特征提取,从而提高识别准确率。本方案维持了短语音声纹识别的准确性,同时又满足了用户的个性化需求。
另外,本发明还提供一种可定制文本的声纹验证系统,参照图2所示,为本发明一实施例提供的可定制文本的声纹验证系统的结构框图。
所述系统包括:
提示单元,通过在交互界面上显示已定制文本的内容以提示用户进行朗读,所述定制文本为用户自定义内容;
比对单元,并将采集到的朗读音频中的声纹与数据库中的声纹模型进行比对分析;
验证单元,当文本内容正确且采集到的声纹与数据库中的声纹模型一致时判定验证通过。
优选的,所述用户自定义内容为用户根据需要所设计的词语或语句。
优选的,所述声纹模型存入数据库时与对应的用户自定义内容建立联系。
优选的,所述声纹模型为通过提取用户的语音声纹特征为其建立的声纹模型。
在用户声纹建模入库阶段,用户按照自己的需求,设置词语或语句,并念诵词语或语句的内容。在声纹识别系统接收到用户的音频之后,先进行内容识别,并将识别出的内容与用户输入的文本对应。如果文本和识别出的内容一致,对此段音频进行特征提取(即建模)并将其入库,并将文本记录并与对应的声纹模型建立联系。
在用户使用声纹识别系统验证声纹时,声纹识别系统将会在用户交互界面上显示用户声纹建模时所输入的文本作为提示。此时用户可以念诵自己个性化定制的文本。当声纹识别系统接收到用户音频时,同时进行内容识别以及声纹识别。当两者同时通过时,则声纹识别系统则会判定是用户本人。
本发明即保留了固定文本提高声纹识别系统识别准确率的优点,同时又满足了用户个性化定制自己文本的需求。通过本发明能显著提高用户对产品的体验,满足用户的个性化需求。同时产生趣味性,用户可以根据个人的想象力,定制一些有意思的语句,这为前提产品的推广起到了宣传的作用。
上述实施例中的实施方案可以进一步组合或者替换,且实施例仅仅是对本发明的优选实施例进行描述,并非对本发明的构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域中专业技术人员对本发明的技术方案作出的各种变化和改进,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!