一种面向语音识别系统的音乐嵌入攻击防御方法与流程
本发明涉及一种基于gan的音乐嵌入语音识别系统攻击防御方法。
背景技术:
目前,深度学习已经被广泛应用于图像识别、语音识别、数据生成等领域。生成式对抗网络是深度学习领域常用的模型之一,通过生成模型和判别模型的相互博弈学习可以输出较好的结果。
基于深度学习的语音识别系统为人们的日常生产生活带来了极大的便利,但同时也容易受到隐藏的攻击,通过在原有音频中添加人耳不能发觉的扰动,可以使得音频的转录结果发生改变,若攻击者精心设计扰动使得生成的对抗样本转录为目标短语,将极有可能损害使用者的个人隐私甚至人身安全。
目前已有的语音识别攻击方法主要分为白盒攻击和黑盒攻击。黑盒攻击方法在未知模型内部参数的情况下,利用启发式算法计算得到最优扰动,使添加对抗扰动后的音频与原始音频的差异尽可能小且能够转录成目标短语。白盒攻击方法需要在了解模型内部参数的情况下通过反向传播算法计算梯度并更新模型参数。另外,攻击者还通过添加不在人耳识别频率范围内的噪声实现攻击。由于麦克风等设备的非线性,这些噪声在经过麦克风后能够被语音识别系统识别,并转录成相应的短语。常用的语音识别防御方法有对抗训练,通过将对抗样本加入训练数据集重训练模型使得模型具备防御对抗样本的能力,由于上述攻击方法是对特定的音频添加干扰,需要对大量的音频处理生成相应对抗样本,所需的计算量较大。
技术实现要素:
本发明要克服现有技术的上述缺点,提供一种基于生成式对抗网络(generativeadversarialnetwork:gan)的音乐嵌入语音识别攻击防御方法。
本发明通过音频生成网络生成音乐音频,并且使用语音识别模型得到生成音频的转录结果,利用转录结果与目标短语之间的损失以及判别器的输出结果建立目标函数来优化生成网络,使得生成的对抗音频能够不被人耳所识别且转录为目标短语。
为实现上述发明目的,本发明提供以下技术方案:
利用生成模型生成音乐音频;
利用语音识别模型得到生成音乐音频的转录结果;
利用判别器判别样本为生成的对抗样本或真实音乐样本,使得生成的对抗样本不失真;
所述音频生成模型、判别模型和语音识别模型通过以下模型训练体系训练得到,所述模型训练体系包括:
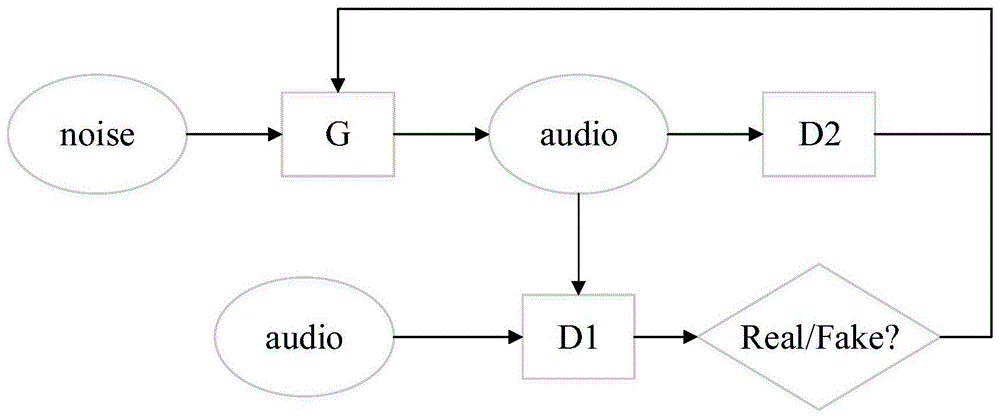
音频生成网络(generator:g),用于生成音乐音频,其输入为一定长度的噪声矩阵;
音频判别网络(discriminator1:d1),其输入为正常音乐音频和生成音乐音频,输出为对正常音乐音频和生成音乐音频的判定结果,用于判别音频的真实性,使得生成的音乐音频能够保持音乐的基本特征,不被人耳发觉;
语音识别模型(discriminator2:d2),其输入为音频生成模型生成的音乐音频,输出为音频转录结果和当前转录结果与目标短语的损失值;
本发明的一种面向语音识别系统的音乐嵌入攻击防御方法,具体过程为:
(1)数据集准备及预处理:采集实验需要的语音音频,分为预训练数据集和用于生成对抗样本的扰动数据集,并对数据集进行裁剪等预处理;
(2)训练语音识别模型:利用语音数据集对语音识别模型进行训练,并用测试数据集进行测试,使其能够达到预设的识别准确率;
(3)预训练生成对抗网络:预训练音频生成网络g、音频判别网络d1,得到生成网络和判别网络的初始参数;
(4)重训练:固定音频生成网络g的参数,训练更新音频判别网络d1的参数;固定音频判别网络d1的参数,训练更新音频生成网络g的参数,按照上述过程交替迭代训练音频生成网络g和判别网络d1,直到达到设定的迭代次数。训练好的音频生成网络g即为音频生成模型,训练好的音频判别网络d1即为音频判别模型;
(5)生成对抗样本;
(6)对抗训练:将生成的对抗样本加入训练数据集中,再次训练语音识别模型,使其具有防御对抗样本的能力。
该基于gan的音乐嵌入语音识别攻击防御方法具有的效果为:可以生成隐藏有语音指令的音乐音频,该音频通过语音识别系统可以转录成目标短语。同时,通过对抗训练后的语音识别系统能够防御隐藏有语音指令音乐音频的攻击。通过这种方法可以提高信息的安全性,保护用户的个人隐私和人身安全。
与现有技术相比,本发明具有以下有益效果:
1、本发明生成的对抗样本可以实现对语音识别系统的攻击,且能够不被人耳所辨识;
2、本发明生成的对抗样本将扰动添加到音乐中,在每次播放音乐的过程中都可能实现攻击,具有较好的传播性和较大的安全隐患,通过对抗训练提高语音识别系统的防御能力具有较高的实际意义。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术中所需要使用的附图做简单的介绍。
图1为本发明中模型训练体系的结构示意图;
图2为本发明实施例的方法流程示意图;
具体实施方式
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
参照图1-图2,一种面向语音识别系统的音乐嵌入攻击防御方法包括以下步骤:
(1)数据集准备及预处理:采集实验所需的音乐音频,分为预训练数据集和用于生成对抗样本的扰动数据集,对采集所得的音乐音频进行裁剪并处理成数据流格式;
(2)训练语音识别模型:利用处理得到的音乐音频数据集对语音识别模型进行训练,使得模型能够具有识别歌词的能力,并利用测试数据集对语音识别模型测试,若未达到预设的识别准确率则重新训练语音识别模型;
(3)预训练生成对抗网络:预训练音频生成网络g、音频判别网络d1,得到生成网络和判别网络的初始参数;
该音乐音频生成模型和音乐音频判别模型是利用如图1所示的模型训练体系获得的,具体的模型训练体系包括三个模块:分别为音频生成网络g、音频判别网络d1、语音识别模型d2。
音频生成网络g生成音乐音频,即通过输入一个噪声矩阵可以获得一个音频矩阵;音频生成网络g是由lstm单元和全连接层构成的神经网络,原始的输入矩阵为[1,n],n表示采样时间点个数,矩阵中的每个值表示每个采样点的采样值;
音频判别网络d1判别正常的音乐音频和生成的音乐音频,定义正常音乐音频的类标为1,生成音乐音频的类标为0,通过判别网络的损失反馈更新音频生成网络g的参数,使该生成网络生成的音频更接近真实音乐音频;音频判别网络d1主要由全连接层构成,输出为0-1之间的一个数表示判别结果,判别结果越接近1表示生成的音频更接近正常音乐音频,判别结果越接近0则表示生成的音频虚假性较高,容易被人耳识别;
语音识别模型d2识别音乐音频中的歌词,即将音乐音频转录成对应的文字。语音识别模型首先通过特征提取获得音频的mfcc特征向量,特征提取的具体过程如下:
step1:对音频矩阵进行预加重,并以40ms为一帧进行分割,相邻帧之间重叠160个采样点,使得相邻帧之间保持内容上的关联性。
step2:将分割后的每帧音频通过傅里叶变换得到对应的频谱,并在频谱上进行倒谱分析,即通过对频谱进行离散余弦变换获取第2-13个系数作为梅尔倒谱系数。
step3:计算梅尔倒谱系数的一阶差分和能量值,与12维的梅尔倒谱系数构成26维的特征向量,特征向量大小[batch_size,n_frames,26],其中batch_size表示每一批次中的样本数量,n_frames表示音频的帧数;
其中,语音识别模型d2主要由dnn和双向rnn网络构成,识别模型的输出为每帧被识别为不同字符的概率。
语音识别模型的输出作为语言模型的输入,通过贪心算法搜索得到最可能被识别的字符序列,并得到最终转录结果;
(4)重训练生成对抗网络:重训练包括固定音频生成网络g的参数,更新音频判别网络d1的参数以及固定音频判别网络d1的参数,更新音频生成网络g的参数两个过程,重训练的具体过程如下;
step1:固定音频生成网络g和语音识别模型d2的参数,将真实音乐音频、生成的音乐音频作为音频判别网络d1的输入训练音频判别网络d1,提高判别网络判别虚假生成音频和真实音乐音频的能力;
step2:固定音频判别网络d1和语音识别模型d2的参数,将噪声矩阵作为音频生成网络g的输入,根据音频判别模型和语音识别模型的损失更新音频生成模型g的参数,使其生成的音乐音频更加接近正常音乐音频,能够不被人耳辨别其虚假性;
step3:重复step1、step2交替迭代训练音频生成网络g和判别网络d1,直到达到设定的迭代次数训练停止,训练好的音频生成网络g为音频生成模型,音频判别网络d1为音频判别模型;
训练过程中音频生成网络和判别网络的目标函数分别如式(1)、(2)所示:
其中,xg表示音频生成网络g生成的音乐音频,xmusic表示真实音乐音频;pdata表示真实音频的分布,pg表示音频生成网络g的输出分布,d1(xmusic)和d1(xg)分别表示音频判别网络d1对真实音乐音频xmusic和生成音乐音频xg的判别结果;
音频生成网络目标函数的第一项衡量了生成音频与真实音频之间的差距,第二项利用ctc-loss来衡量当前生成音频与目标短语之间的距离,目标函数的值越小,表示生成的音频越接近真实音频,且转录结果与目标短语越相近;
(5)生成对抗样本:利用训练好的生成对抗网络生成能够转录为目标短语的对抗样本,同时确保对抗样本能够保持音乐的基本特性,不被人耳辨识;
(6)对抗训练:将步骤(5)中得到的对抗样本加入到预训练数据集中,重新训练语音识别模型,得到能够防御对抗样本攻击的语音识别模型.
本发明采用生成对抗网络,在不了解语音识别模型内部参数的情况下,能够生成使语音识别模型转录为目标短语的对抗样本,并将对抗样本用于对抗训练,提高语音识别模型防御对抗样本的能力。本发明生成的对抗样本转录为目标短语的前提下,不被人耳辨识,具有较高的隐秘性。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!